Linux内核工作队列workqueue详解
1. Linux内核工作队列
在Linux内核中,工作队列是一种异步处理机制,用于延迟执行一些需要在进程上下文中执行的任务。工作队列通常由内核模块或驱动程序使用,以避免在中断上下文中执行长时间运行的操作。
如果中断需要执行的任务很多,就需要分为上半部和底半部,上半部就是中断发生的中断服务函数,在这里需要尽可能执行快,以免影响系统其他中断的处理,底半部发生在不久的将来,用来处理中断中未完成的耗时多的工作。
上半部在中断上下文,下半部在进程上下文。工作队列就是底半部机制的其中一种。本质上一种代码推迟执行的机制。
- 代码推迟到工作队列,可以享有进程上下文的所有好处
- 工作队列可以被调度,也可以睡眠
2. 工作队列的优点
使用工作队列的一个主要优点是避免在中断上下文中执行长时间运行的操作。中断上下文应该尽可能短暂,以免影响系统的响应性和稳定性。使用工作队列可以将长时间运行的操作延迟到稍后的时间执行,从而避免在中断上下文中执行。
另一个优点是工作队列可以在多个CPU上并行执行任务。这可以提高系统的吞吐量和响应性。
总之,工作队列是Linux内核中一种非常有用的异步处理机制。它可以帮助内核模块和驱动程序避免在中断上下文中执行长时间运行的操作,并提高系统的吞吐量和响应性。
3. 内核自带的工作队列
3.1 初始化
静态方法:
DECLARE_WORK(work,work_fn);
动态方法:
INIT_WORK(work,work_fn)
所谓静态就是在编译时候就得到了work_struct的空间,跟随着ko,会增大ko的大小,最后被放到内存上。
所谓的动态就是在运行时候才得到了work_srtuct的空间,这时候是在堆上,本质上也是在内存上。
3.2 调度work_struct 到workqueue
schedule_work(struct work_struct *work)
schedule_work_on(int cpu, struct work_struct *work)
一个work可以被调度到系统的任意一个CPU,也可以被调度在指定的CPU,这就是以上两个API的区别。
3.3 取消一个work_struct
cancel_work(struct work_struct *work);
cancel_work_sync(struct work_struct *work);
取消一个work的时候,有可能他正在进行,如果需要等待它执行完,可以使用cancel_work_sync,等待其执行完毕再取消.
3.4 强制work的执行
可能有多种原因,当你想work执行的那一刻,工作队列正在执行别的work或者在睡眠,那么你的work不能如期执行,这时候可以强制让work执行。
一个工作队列上是可以有多个work的,当然也可以针对一个工作队列来强制执行上面的多个work,使用flush_scheduled_work和flush_workqueue。flush_scheduled_work不带参数,特指system_wq,这是一个系统自带的工作队列。
flush_work(struct work_struct *work);
flush_scheduled_work()
flush_workqueue(struct workqueue_struct *_wq)
4. 自定义工作队列
4.1 创建工作队列
struct workqueue_struct *create_workqueue(name)
struct workqueue_struct *create_singlethread_workqueue(name)
4.2 销毁工作队列
void destroy_workqueue( struct workqueue_struct * );
4.3 调度work_struct 到自定义workqueue
int queue_work( struct workqueue_struct *wq, struct work_struct *work );
int queue_work_on( int cpu, struct workqueue_struct *wq, struct work_struct *work );
queue_work会先提交到当前CPU,如果这个CPU出现故障,则会转移给别的CPU
queue_work_on直接指定在哪个CPU上面执行work
5. Demo
#include 触发方式如下:
insmod test.ko
dmesg -n8
echo 1 > /dev/wqtest //内核自带的wq
echo 2 > /dev/wqtest //自定义wq
如下图所示:

使用top查看cpu,可以发现运行在我们定义的cpu2上面:

6. 初始化代码过程
kernel在启动过程中,会初始化工作队列这个基础设施,通过两个函数:workqueue_init_early和workqueue_init,分别是第一和第二阶段的工作队列初始化。
/*init/main.c*/
start_kernel()
...
workqueue_init_early();
...
arch_call_rest_init();
rest_init();
kernel_init();
kernel_init_freeable();
workqueue_init();
6.1 workqueue_init_early
DEFINE_PER_CPU_SHARED_ALIGNED 是一个宏定义,用于声明和定义一个使用 per-CPU 共享对齐的变量。在 Linux 内核中,per-CPU 变量是一种特殊类型的变量,每个 CPU 都有一份独立的拷贝。这样可以避免多个 CPU 之间的竞争和同步开销,提高系统性能。
DEFINE_PER_CPU_SHARED_ALIGNED(type, var);
其中:
- type 是要声明的变量的数据类型。
- var 是要声明的变量名。
6.1.1.1 定义worker_pool
/* the per-cpu worker pools */
static DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools);
可以看到上面定义了的类型是struct worker_pool []的,名字是cpu_worker_pools的变量,每个CPU都会有这样的数组,NR_STD_WORKER_POOLS是2,当前内核决定的。
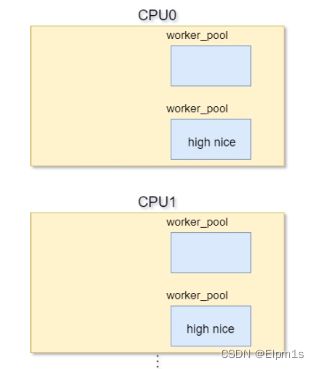
6.1.1.2 初始化work_poll
workqueue_init_early对每个CPU的两个work_pool初始化,赋予不同的nice值,分别是0和-20
/* initialize CPU pools */
for_each_possible_cpu(cpu) {
struct worker_pool *pool;
i = 0;
for_each_cpu_worker_pool(pool, cpu) {
BUG_ON(init_worker_pool(pool));
pool->cpu = cpu;
cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
pool->attrs->nice = std_nice[i++];
pool->node = cpu_to_node(cpu);
/* alloc pool ID */
mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
mutex_unlock(&wq_pool_mutex);
}
}
6.1.1.3 创建系统自带的工作队列
使用alloc_workqueue()创建系统自带的多个工作队列。system_wq 、system_highpri_wq 、system_long_wq 、system_unbound_wq 、system_freezable_wq 、system_power_efficient_wq 、system_freezable_power_efficient_wq 都是全局的工作队列,供各个驱动模块使用,各有不同的特点。
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
以上可以看到创建不同的系统工作队列的时候用到了不同的flag,如WQ_HIGHPRI。
下面举例子alloc_workqueue创建”events“工作队列。系统在全局维护了一个工作队列的链表,所有创建的工作队列都要加入到这里被组织管理
/*kernel/workqueue.c*/
static LIST_HEAD(workqueues); /* PR: list of all workqueues */
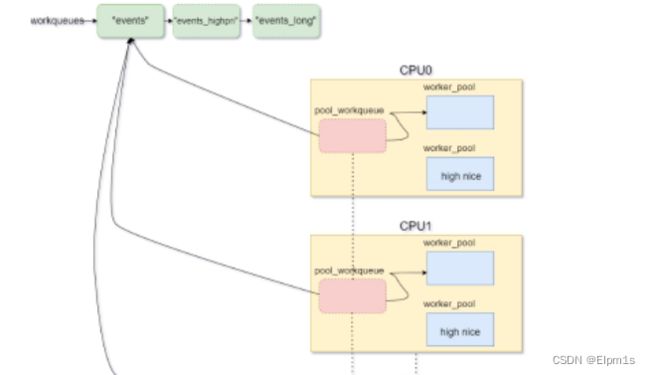
以上是创建完workqueue后的样子,仅仅列出了“events”工作队列。可以看到workqueue被全局链表workqueues组织起来。
这里出现了一个新的对象pool_workqueue,是worker_pool和workqueue的中介。“events”没有标志WQ_UNBOUND,因此它的pool_workqueue中介都是per-cpu的,又因为没有WQ_HIGHPRI标志,所有中介给workqueue找的worker_pool都是normal的而非-20 nice的。这些结论很重要,这就已经决定了这三者的关系不会再改变。
最终这个阶段工作队列就已经完成了系统工作队列的初始化,但是我们还没看到帮我们执行work的worker线程。
6.2 workqueue_init
遍历workqueues链表,凡是带有WQ_MEM_RECLAIM标志的工作队列,都会为其分配一个rescuer(救援)线程,线程名字就是工作队列的名字,但是系统自带的工作队列全都没有rescuer线程。
对在线的CPU ,per-cpu的worker_pool都创建woker,这里出现新的对象worker。worker表示一个执行work的线程。创建的worker是worker_pool的一部分。这里只对在线的CPU里面worker_pool创建worker,根据worker_pool的nice值,决定worker的名称。
if (pool->cpu >= 0)
snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
pool->attrs->nice < 0 ? "H" : "");
else
snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
if (IS_ERR(worker->task))
goto fail;
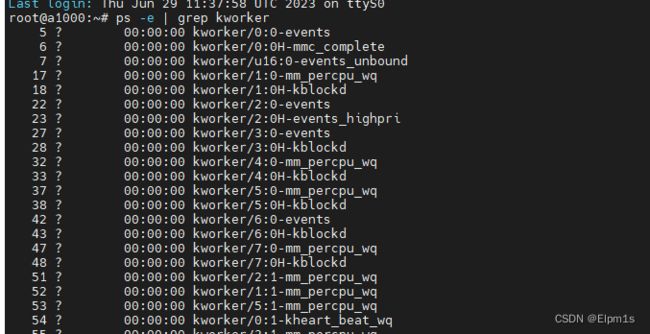
由代码可以看出,有 ‘H’的代表高优先级的worker,有‘u’的代表是ubound的worker

到这里为止,整个工作队列系统呈现这样子。创建的worker会进入idle,worker.nr_idle表示现在有多少个worker在idle。现在我们所有的kwoker都处于idle状态,还没有work提交,也没有work能执行。
通过线程池(worker_pool)绑定的cpu信息(struct worker_pool的cpu成员)可以知道该pool是per-CPU还是unbound,对于per-CPU线程池,pool->cpu是大于等于0的。对于对于per-CPU线程池,其worker线程的名字是kworker/cpu:worker id,如果是high priority的,后面还跟着一个H字符。对于unbound线程池,其worker线程的名字是kworker/u pool id:worker id。
上面还可以看到又的worker带有u开头的,那表示ubound worker,表示不会固定在某个CPU执行
7. 提交work的过程
一个work带有一个执行函数,驱动们提交work是提交到workqueue,但是最后却是挂载到找到的work_pool的链表上面。
当驱动们使用schedule_work()提交一个work到 “events”工作队列,即系统自带的system_wq。
static inline bool schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
static inline bool schedule_work_on(int cpu, struct work_struct *work)
{
return queue_work_on(cpu, system_wq, work);
}
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
{
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
}
可以看到,所有面向驱动们的接口都是内联函数,最终使用的是queue_work_on()提交一个work,当驱动们没有指定CPU的时候,这个work就是WORK_CPU_UNBOUND的,定义是CPU的个数。
work最终需要找到的是worker_pool,因此要先找到pool_workqueue也就是中介。以下是执行逻辑
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
...
/* pwq which will be used unless @work is executing elsewhere */
if (wq->flags & WQ_UNBOUND) {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
} else {
if (req_cpu == WORK_CPU_UNBOUND)
cpu = raw_smp_processor_id();
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
}
...
}
判断你的工作队列是否是UNBOUND的,因为system_wq是在创建的时候是没有指定flag的,走第二个分支,再判断有没有给这个work指定CPU,没有指定的话,会选择当前提交work时候的CPU,也就是本地CPU。再根据这个CPU找到pool_workqueue,找到了中介就找到了worker_pool,就是因为是per-cpu的。整个逻辑就是用户知道提交到的工作队列,就找到了其下的所有pool_workqueue,再根据CPU确定是哪个pool_workqueue,进而就知道了work_pool。
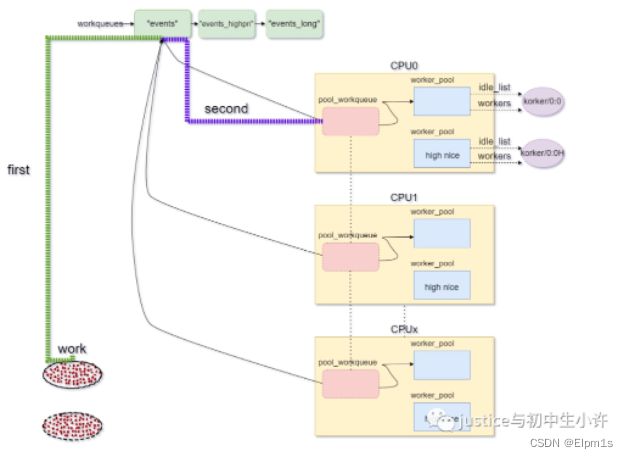
当找到了worker_pool,就会使用这个线程池的线程worker来执行我们的work,我们的work可能不止提交一次,那么如果再次提交work就会倾向于使用先前的worker_pool和pool_workqueue。下面是处理的逻辑
last_pool = get_work_pool(work);
if (last_pool && last_pool != pwq->pool) {
struct worker *worker;
raw_spin_lock(&last_pool->lock);
worker = find_worker_executing_work(last_pool, work);
if (worker && worker->current_pwq->wq == wq) {
pwq = worker->current_pwq;
} else {
/* meh... not running there, queue here */
raw_spin_unlock(&last_pool->lock);
raw_spin_lock(&pwq->pool->lock);
}
} else {
raw_spin_lock(&pwq->pool->lock);
}
最后work会加入到worker_pool的worklist链表,这时候work处于pengding状态,处于pending状态的work不会重复挂入workqueue,如果这时候所有worker都处于idle状态的话,那么就需要唤醒一个worker,线程池worker_pool.nr_running表示所有worker都在idle啦,没人干活啦。
/*kernel/workqueue.c*/
worklist = &pwq->pool->worklist;
static void insert_work(struct pool_workqueue *pwq, struct work_struct *work,
struct list_head *head, unsigned int extra_flags)
{
struct worker_pool *pool = pwq->pool;
...
list_add_tail(&work->entry, head);
...
if (__need_more_worker(pool))
wake_up_worker(pool);
}

以上就是提交work的流程,最终就是把work挂接到线程池worker_pool的worklist链表,同时至少这个worker_pool保证有一个woker处于running状态。
8. 执行work的过程
work已经存在于线程池的worklist链表了,现在就等待一个线程把他们取出来一个个执行。先前在初始化的时候已经保证了per-cpu的woker_pool至少有了一个idle woker。
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
所有的worker都使用一个内核线程函数worker_thread(),主要执行逻辑
/*kernel/workqueue.c*/
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work);
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
从worker_pool的worklist链表头中摘下一个work,执行process_one_work(worker,work),直到所有的work被处理完
/*kernel/workqueue.c*/
worker->current_work = work;
worker->current_func = work->func;
worker->current_pwq = pwq;
work_data = *work_data_bits(work);
worker->current_color = get_work_color(work_data);
strscpy(worker->desc, pwq->wq->name, WORKER_DESC_LEN);
list_del_init(&work->entry);
...
worker->current_func(work);
...