ElasticSearch: Search API 查询用法详解
Search API
ElasticSearch 为了搜索提供了一些原始的 API,主要是有两大类
- URL Search
URL Search 类似 http 的get请求,是将请求参数放到 URL 中,比如之前使用的查询文档的接口 get index/_doc/1?pretty - Request Body Search
是以JSON的格式去请求参数,有些类似 http 的 post 请求,是将参数封装在请求体中,这种格式更加符合我们的使用期望,查询场景以及满足的查询条件也丰富。
URL Search
请求格式是 curl -XGET ip地址/索引/文档类型/_search?q=查询字段:查询条件
- 在url 中拼接 “q” 跟着要查询的条件
- 查询条件格式为:查询字段:查询值 (key:value 格式)
curl -XGET http://localhost:9200/kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie
比如上边这个查询语义为 查询 customer_first_name 为 Eddie 的文档
Request Body Search
- 在请求体中以JSON方式标注查询条件
- 支持 POST 与 GET
请求格式是 curl -XPOST ip地址/索引/文档类型/_search -H ‘Content-Type:application/json’ -d ‘请求内容’
curl -XPOST http://localhost:9200/kibana_sample_data_ecommerce/_search -H 'Content-Type:application/json' -d
'{
"query": {
"match": {
"customer_first_name": "Eddie"
}
}
}'
比如上边这个查询语义为 查询 customer_first_name 为 Eddie 的文档
_search API 查询返回的结果
- took 本次查询花费的时间
- timed_out 是否超时
- _shards 找了几个分片
- total 符合条件的文档总数
- 里层的 hits 查询结果集,默认前十个
- _index 索引
- _type 文档类型
- _id 文档id
- _score 相关性算分
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 100,
"relation" : "eq"
},
"max_score" : 3.8400407,
"hits" : [
{
"_index" : "kibana_sample_data_ecommerce",
"_type" : "_doc",
"_id" : "MXjM93MBubpWmoaWdDeo",
"_score" : 3.8400407,
"_source" : {
"category" : [
"Men's Clothing"
],
"currency" : "EUR",
"customer_first_name" : "Eddie",
"customer_full_name" : "Eddie Underwood",
"customer_gender" : "MALE",
"customer_id" : 38,
"customer_last_name" : "Underwood"
}
}
}
对于搜索来说,用户关注的是当前搜索的结果内容多少是相关的以及多少无关的内容返回回来,_score 就是这样的一个文档与当前搜索条件相关度的一个评分,这个值越高相关度越高搜索结果排名越靠前。
URL Search 详解
url 方式的查询,有很多的查询条件是可以设置的,比如下边这个
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
这条语句指定了查询字段、排序方式以及分页大小和超时时间等参数。
- q 指定查询语句
- df 为默认字段,不指定时,会对所有字段进行查询
- sort 排序 / from size 指定分页
- profile 可以查看查询时如何执行的
DisjunctionMaxQuery 泛查询
url 的范查询,其实就是不指定字段只指定查询值去查询,也就是只指定 q 后边的值,这个查询默认会扫描整个文档的所有字段,只要满足 2012 的值都会被搜索出来。
#泛查询,正对_all,所有字段
GET /movies/_search?q=2012
注意: 指定 profile 可以查看本次查询的执行详细情况(相当于 explain 执行计划)。
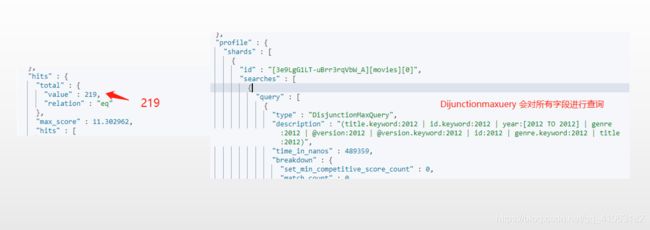
可以看到结果是共有 219个文档,查看profile,发现用的是 DisjunctionMaxQuery 查询方式,这个查询方式会将所有字段都进行筛选一遍,在description 中也有描述。
指定字段查询
url 的指定字段查询,其实就是在范查询的基础上指定了只查询一个字段,实现方式是在url 请求中跟上df 参数指定所要查询的字段。
#通过df指定字段查询
GET /movies/_search?q=2012&df=title
{
"profile":"true"
}
#第二种指定字段查询
GET /movies/_search?q=title:2012
{
"profile":"true"
}

这个结果只会去查询 title 字段中匹配 2012 条件的文档。
TermQuery
term query 其实就是词项匹配查询,比如 Beautiful Mind 这个文本,使用 term 查询,ElasticSearch 会将它拆分成两个词项,Beautiful 与 Mind ,结果只要满足其中一个就可以。
查询语法,在 q 后边的查询条件不加双引号就是 term查询。
注意:在指定term 查询的时候,如果是多个条件需要用到分组的概念,() 这种在ElasticSearch 中就是一个分组,在括号内的查询条件表示是一个分组。
#使用df
GET /movies/_search?q=Beautiful Mind&df=title
{
"profile":"true"
}
# 第二种方式 使用括号将查询条件括起来
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
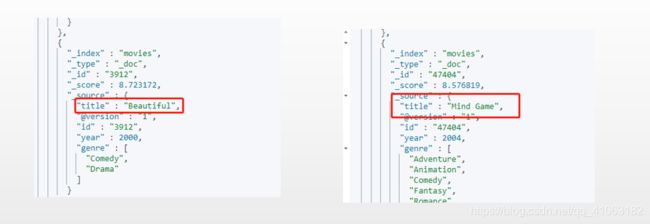
这个查询会去找既符合 Beautiful 又符合 Mind 的。
Phrase Query
Phrase Query 其实就是文本精确匹配,还是比如 Beautiful Mind 这个文本,ElasticSearch 会在查询寻时把他当成是一个完整的查询条件来查询,不会去分词。
查询语法,在 q 后边的查询条件加上双引号就是 Phrase 查询。
#使用引号,Phrase查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}

可以看出来,只查到了一条记录。
布尔操作
有时候,我们需要制定一个查询条件是 与 的关系还是 或 的关系,这个时候可以使用布尔操作来进行条件的拼接。
注意:布尔操作的标识符必须大写
- AND 或者是字符 &&
- OR 或者是字符 ||
- NOT 或者是字符 !
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful ! Mind)
{
"profile":"true"
}
上边这个查询语义表示 查找 title 中包含 Beautiful 字段的并且 不包含 MInd。
分组操作
除了使用布尔操作之外,我们还可以使用一些特殊符号来表示 包含于不包含这种语义。
- ‘ + ’ 表示must
- ‘ - ’ 表示must_not
# 查找美丽心灵
GET /movies/_search?q=title:(+Beautiful -BMind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful %2BMind)
{
"profile":"true"
}
上边这个查询语义表示 查找 title 中包含 Beautiful 字段的并且 不包含 MInd。%2B 在URl 中表示 '-’,是经过decode编码的。
范围查询
我们在查询一个数字类型的字段时,有时候希望可以范围查询,ElasticSearch 也是支持范围查询的。
- [] 表示闭区间,边界值也会覆盖
#范围查询 ,区间写法
GET /movies/_search?q=title:beautiful AND year:[ 2013 TO 2014 ]
{
"profile":"true"
}
算数符号查询
想指定返回查询,还可以使用算数符号来表示
- year:>2010
- year:<=2010
#范围查询,算数符号
GET /movies/_search?q=year:<=2010
{
"profile":"true"
}
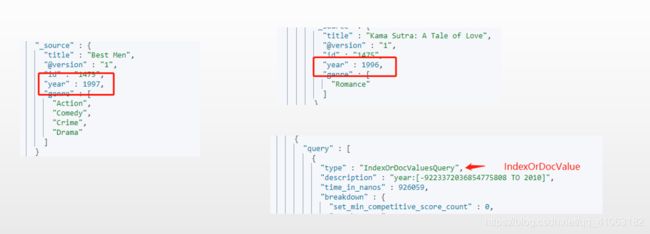
这个查询条件的语义是查找 年份小于等于 2010年的电影,可以见到结果中的年份全部都小于 2010.
通配符查询
ElasticSearch 还支持通配符的方式去模糊查询,比如 b*,就是查询所有开头为b的文档。
- ?代表一个字符
-
- 代表 0-多个字符
#通配符查询
GET /movies/_search?q=title:b*
{
"profile":"true"
}
近似查询
有些时候我们不知道某个单词的拼写是否会出错,那么我们可以使用近似查询来保证一定的容错率。在查询条件后边加上 ‘~ 数字’ 这种格式,那么就表示允许匹配单词字母误差不超过数字个数的文档。
- title:beautifl~1 表示 单词字母误差在 1 个字母范围内的结果都可以。
//模糊匹配&近似度匹配
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}
GET /movies/_search?q=title:"Lord Rings"~2
{
"profile":"true"
}

如果是Phrase查询的话,那么数字表示两个单词之间可以相差几个单词。比如如上结果,在Lord Rings中相隔了两个单词的文档也被查找出来了。
Request Body Search 详解
URl 的请求方式是不推荐使用的,毕竟他操作起来比较繁琐,查询ElasticSearch 一般使用的是 Request Body Search,通过 JSON的方式,走查询 DSL 的语法来查询API。
查询所有文档
ignore_unavailable=true 可以忽略尝试访问不存在的索引“404_idx”导致的报错。
POST /movies,404_idx/_search?ignore_unavailable=true
{
"profile": true,
"query": {
"match_all": {}
}
}

match_all 这个语句的查询语义是查找所有的文档,可以看到统计出了所有的文档。
分页
可以再 Request Body 加上 from、size 参数来控制分页.
注意:分页越往后成本越大。
- from 起始位置
- size 查询文档数量
POST /movies/_search
{
"from":10,
"size":20,
"query":{
"match_all": {}
}
}
sort 排序
我们可以再 Request Body 中指定按照那个字段进行排序
- desc 降序
- asc 升序
#对年份进行排序
POST movies/_search
{
"sort":[{"year":"asc"}],
"query":{
"match_all": {}
}
}
_source 查询返回字段过滤
我们有时候可能只需要文档中的某几个字段的值,并不需要将整个文档都拉下来增加网络开支,这个时候我们可以在 _source 中指定我们想要返回的字段。
#source filtering
POST movies/_search
{
"_source":["title","year"],
"query":{
"match_all": {}
}
}

我们可以看到结果中只返回了 title,year 的值。
脚本字段
有时候我们不只是单纯的获取一个字段的值,我们可能是想要对这个字段的值进行一些运算之后再获取值,ElasticSearch 提供了一个API 属性来计算返回的值,通过 painless 脚本来计算值。
注意:如果是text文本的值是不能通过脚本字段来直接获取的。
#脚本字段
GET kibana_sample_data_ecommerce/_search
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source": "doc['order_date'].value+'---'+doc['customer_id'].value"
}
}
},
"query": {
"match_all": {}
}
}
这个查询的语义是 将order_data 的值与 customer_id 的值相加。

match 查询
match 查询会对搜索条件进行分词然后查询。
POST movies/_search
{
"query": {
"match": {
"title": "last christmas"
}
}
}
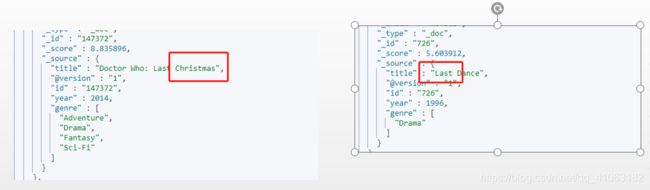
当然,我们还可以指定查询的布尔操作等属性,是通过 operator 去实现的,不过只支持 AND 与 OR。
- AND
- OR
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "last christmas",
"operator": "and"
}
}
}
}
短语搜索 Phrase
Request Body Search 的 PhraseQuery 方式是通过 match_phrase 查询来搞得。
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love",
"slop": 1
}
}
}
}
slop 的作用类似近似查询, ~ 1 ,表示中间有一个值可以模糊。