韩顺平Java自学笔记 集合
一。集合的概述
1.集合的好处与理解
数组存储数据的灵活性不够。
集合的好处

2。集合的框架图
idea的diagram怎么用
Collection的实现子类
很重要(方便理解集合整体架构)
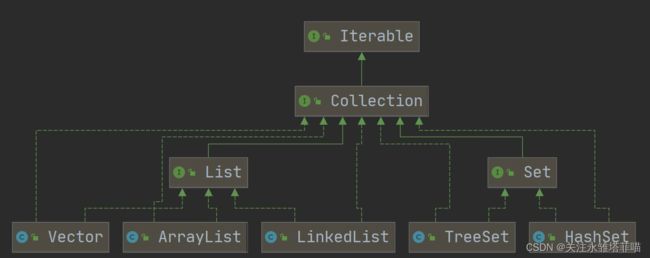
解读:单列集合
在集合当中放的是单独的一个数据。List和Set都是单列集合
Map接口及其常用的实现子类
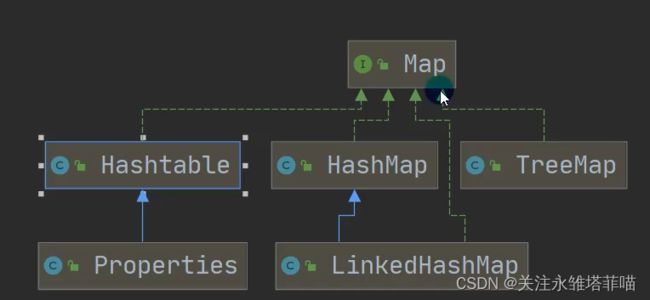
解读:双列集合
在集合当中放的是键值对。存放的为K-V数据。
代码
package com.collection;
import java.util.ArrayList;
import java.util.HashMap;
public class Collection_ {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
// 放一个数据为单列集合
arrayList.add("jack");
arrayList.add("tom");
HashMap hashMap = new HashMap();
// 放两个数据,为双列集合
hashMap.put(1,"北京");
hashMap.put(2,"上海");
}
}
二.Collection接口
1.Collection接口和常用方法
选用他的实现子类来讲解接口当中的方法

代码
package com.collection;
import java.util.ArrayList;
public class CollectionMethod {
public static void main(String[] args) {
ArrayList执行结果
List = [jack, 10, true]
List = [10]
false
1
false
List = []
List = [红楼梦, 水浒传, 三国演义, 西游记]
true
List = [聊斋]
2.元素的遍历
迭代器迭代
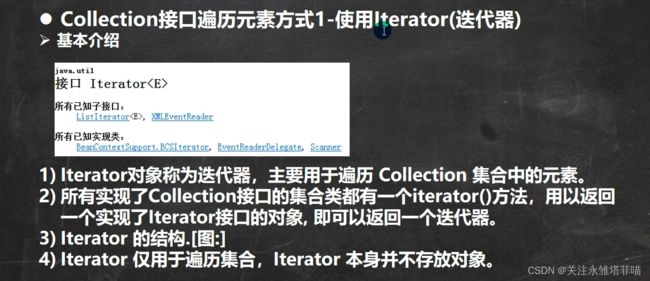
迭代器的原理

如果next没有元素,执行方法会出现异常
使用迭代器进行遍历
package com.collection;
import java.util.ArrayList;
import java.util.Iterator;
public class CollectionIterator {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add(new Book("小李飞刀","古龙",10));
arrayList.add(new Book("三国演义","罗贯中",20));
arrayList.add(new Book("红楼梦","曹雪芹",30));
System.out.println("数组 = "+arrayList);
// 现在希望能够遍历集合
// 1.得到迭代器
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
// 返回的是Object类 编译类型是Object运行类型是什么类型就是什么类型
Object next = iterator.next();
System.out.println(next);
// 教大家一个快捷键itit
}
// 当退出while循环后,游标不能再向下走了iterator已经指向了最后的元素。
// 如果希望再次遍历,要重置迭代器 再创建一个新的迭代器就好了
iterator = arrayList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
class Book{
private String name;
private String author;
private double price;
public Book() {
}
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
执行结果
数组 = [Book{name='小李飞刀', author='古龙', price=10.0}, Book{name='三国演义', author='罗贯中', price=20.0}, Book{name='红楼梦', author='曹雪芹', price=30.0}]
Book{name='小李飞刀', author='古龙', price=10.0}
Book{name='三国演义', author='罗贯中', price=20.0}
Book{name='红楼梦', author='曹雪芹', price=30.0}
Book{name='小李飞刀', author='古龙', price=10.0}
Book{name='三国演义', author='罗贯中', price=20.0}
Book{name='红楼梦', author='曹雪芹', price=30.0}
使用增强for循环进行遍历
代码
package com.collection;
import java.util.ArrayList;
public class CollectionFor {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add(new Book("小李飞刀","古龙",10));
arrayList.add(new Book("三国演义","罗贯中",20));
arrayList.add(new Book("红楼梦","曹雪芹",30));
// 直接使用增强for循环,不仅能用于集合,还可以用于数组。 底层依旧是迭代器 可以理解为一个简化版的迭代器
for (Object o : arrayList) {
System.out.println(o);
}
}
}结果
Book{name='小李飞刀', author='古龙', price=10.0}
Book{name='三国演义', author='罗贯中', price=20.0}
Book{name='红楼梦', author='曹雪芹', price=30.0}
课堂练习

代码
package com.collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class CollectionTest {
public static void main(String[] args) {
// ArrayList实现了List所以可以这样写,接口讲过
List list = new ArrayList();
list.add(new Dog(10,"小黑狗"));
list.add(new Dog(11,"大狼狗"));
// 使用增强for循环
for (Object o : list) {
System.out.println(o);
}
// 使用迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
}
}
}结果
Dog{age=10, name='小黑狗'}
Dog{age=11, name='大狼狗'}
Dog{age=10, name='小黑狗'}
Dog{age=11, name='大狼狗'}
三.List接口及常用方法
1.List接口介绍
类图
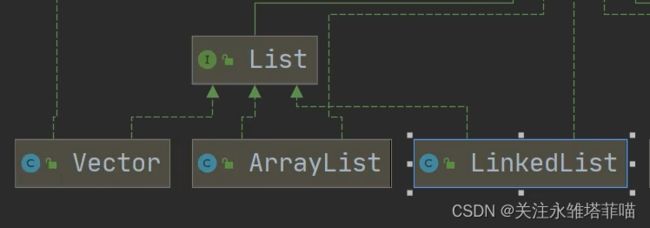
基本介绍
创建一个List集合对象
package com.list;
import java.util.ArrayList;
public class List_ {
public static void main(String[] args) {
ArrayList list = new ArrayList();
// list集合是有顺序的,及添加顺序与输出的顺序是一致的 并且其中的元素是可以重复的
list.add("小明");
list.add("小红");
list.add("小白");
list.add("小牛");
list.add("小杨");
// 支持索引索引从0开始
System.out.println("list = "+list);
System.out.println("list(0) = "+list.get(0));
// list接口的实现类还有很多,只是有些老师没有讲 实现的方法也有很多
}
}
结果
list = [小明, 小红, 小白, 小牛, 小杨]
list(0) = 小明
2.List接口的方法
代码
package com.list;
import java.util.ArrayList;
import java.util.List;
public class ListMethod {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
// 在指定的位置插入元素
list.add(1,"韩顺平");
System.out.println("list = "+list);
// 再指定的位置将所有的元素插进去
ArrayList list1 = new ArrayList();
list1.add("林黛玉");
list1.add("秦可卿");
list.addAll(1,list1);
System.out.println("list = "+list);
// 返回这个对象在集合当中首次出现的地方
System.out.println(list.indexOf("林黛玉"));
// 返回在集合当中最后出现的位置
list.add("韩顺平");
System.out.println(list.lastIndexOf("韩顺平"));
// 移除指定位置的元素 并返回此元素
list.remove(0);
System.out.println("list = "+list);
// 替换指定位置的元素 如果不存在报异常
list.set(0,"黛玉");
System.out.println("list = "+list);
// 返回从一处到另一处的子集合 前闭后开
List list2 = list.subList(0, 3);
System.out.println(list2);
}
}结果
list = [张三丰, 韩顺平, 贾宝玉]
list = [张三丰, 林黛玉, 秦可卿, 韩顺平, 贾宝玉]
1
5
list = [林黛玉, 秦可卿, 韩顺平, 贾宝玉, 韩顺平]
list = [黛玉, 秦可卿, 韩顺平, 贾宝玉, 韩顺平]
[黛玉, 秦可卿, 韩顺平]
3.课堂练习

代码
package com.list;
import java.util.ArrayList;
import java.util.Iterator;
public class ListExercise {
public static void main(String[] args) {
ArrayList list = new ArrayList();
for (int i=0;i<12;i++){
list.add("hello"+i);
}
System.out.println("list = "+list);
list.set(1,"韩顺平教育");
System.out.println(list.get(4));
list.remove(6);
System.out.println("list = "+list);
list.set(6,"红楼梦");
System.out.println("list = "+list);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}结果
list = [hello0, hello1, hello2, hello3, hello4, hello5, hello6, hello7, hello8, hello9, hello10, hello11]
hello4
list = [hello0, 韩顺平教育, hello2, hello3, hello4, hello5, hello7, hello8, hello9, hello10, hello11]
list = [hello0, 韩顺平教育, hello2, hello3, hello4, hello5, 红楼梦, hello8, hello9, hello10, hello11]
hello0
韩顺平教育
hello2
hello3
hello4
hello5
红楼梦
hello8
hello9
hello10
hello11
4.三种list遍历方式的汇总

代码
package com.list;
import java.util.*;
public class ListFor {
public static void main(String[] args) {
// 三种数据的存储的方法都是可以的 因为都是List的实现的子类
// ArrayList list = new ArrayList();
// List list = new Vector();
List list = new LinkedList();
list.add("林黛玉");
list.add("薛宝钗");
list.add("王熙凤");
list.add("秦可卿");
list.add("贾元春");
//使用迭代器进行遍历
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
System.out.println("====增强for循环=====");
for (Object o : list) {
System.out.println(o);
}
System.out.println("=====普通for循环=====");
for (int i =0 ;i结果
林黛玉
薛宝钗
王熙凤
秦可卿
贾元春
=========
林黛玉
薛宝钗
王熙凤
秦可卿
贾元春
==========
林黛玉
薛宝钗
王熙凤
秦可卿
贾元春
5.练习题2
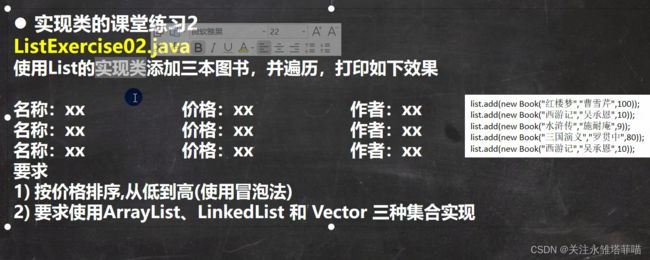
代码
package com.list;
import java.util.ArrayList;
import java.util.List;
public class ListExercise1 {
public static void main(String[] args) {
List arrayList = new ArrayList();
arrayList.add(new Book1("小李飞刀","古龙",10));
arrayList.add(new Book1("三国演义","罗贯中",40));
arrayList.add(new Book1("红楼梦","曹雪芹",30));
for (Object o : arrayList) {
System.out.println(o);
}
// 进行冒泡排序
sort(arrayList);
System.out.println("===排序后====");
for (Object o : arrayList) {
System.out.println(o);
}
}
// 使用冒泡进行排序
public static void sort(List list){
int size = list.size();
// 一共进行size-1轮比较
for (int i=0;ibook11.getPrice()){
list.set(j,book11);
list.set(j+1,book1);
}
}
}
}
}
class Book1{
private String name;
private String author;
private double price;
public Book1() {
}
public Book1(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "名称:\t\t" +
name +
" 作者:\t\t" + author +
" 价格:\t\t" + price ;
}
}
运行结果
名称: 小李飞刀 作者: 古龙 价格: 10.0
名称: 三国演义 作者: 罗贯中 价格: 40.0
名称: 红楼梦 作者: 曹雪芹 价格: 30.0
===排序后====
名称: 小李飞刀 作者: 古龙 价格: 10.0
名称: 红楼梦 作者: 曹雪芹 价格: 30.0
名称: 三国演义 作者: 罗贯中 价格: 40.0
冒泡排序C语言版
ArrayList的注意事项

代码
package com.collection;
import java.util.ArrayList;
public class CollectionDetail {
public static void main(String[] args) {
// 是线程不安全的 多线程不建议使用
ArrayList list = new ArrayList();
// 空对象也是可以放进去的
list.add(null);
list.add("小王");
System.out.println(list);
}
}
运行结果
[null, 小王]
线程不安全的原因
什么是线程安全
最直观的是没有synchronized关键字修饰
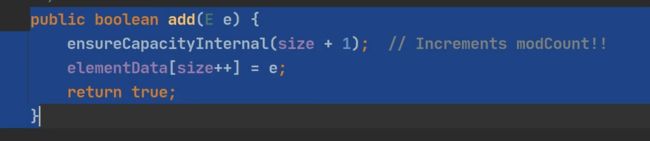
Array List的底层代码逻辑分析
扩容的解析

transient表示短暂的,瞬时的,表示改代码不会被序列化
什么是序列化 https://blog.csdn.net/weixin_45858542/article/details/121871998?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166113686516782246490800%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166113686516782246490800&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121871998-null-null.142%5Ev42%5Epc_rank_34_queryrelevant25,185%5Ev2%5Econtrol&utm_term=%E5%BA%8F%E5%88%97%E5%8C%96&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_45858542/article/details/121871998?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166113686516782246490800%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166113686516782246490800&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121871998-null-null.142%5Ev42%5Epc_rank_34_queryrelevant25,185%5Ev2%5Econtrol&utm_term=%E5%BA%8F%E5%88%97%E5%8C%96&spm=1018.2226.3001.4187
底层代码执行示意图
Map的详解
Map与set的原理大同小异,只是set当中的v是默认常量。
Map接口的常用类型(jdk8版本的)
代码
package com.map_;
import java.util.HashMap;
import java.util.Map;
public class Map_ {
public static void main(String[] args) {
// 1.用于保存存在映射关系的元素 K-V
// 2.Map当中的K与V可以是任意的引用类型对象,会封装到HashMap$Node对象当中
// 3.Map当中的K是不可以重复的,原因和HashSet一样
// 4.Map当中的V可以重复
// 5.Map当中的K和V都可以是null但是K为null只能有一个。
// 6.常用的K类型为String
Map map = new HashMap();
map.put("no1","韩顺平");
map.put("no2","张无忌");
map.put("no2","光头强");//当有相同的k时,就会对v进行替换。
map.put(null,null);
map.put(null,"小明");
// 通过get方法,传入对应的K,会得到Value.
System.out.println(map.get("no2"));
System.out.println("Map = "+map);
}
}
运行结果
光头强
Map = {no2=光头强, null=小明, no1=韩顺平}
双列元素,底层依旧是HashMap,存放没有顺序。
会封装到HashMap$Node对象当中
key是不可以重复的,与HashSet一样,当V重复时,会对v进行替换,V是可以重复的。以k来判断存储的元素是不是一样的。k与v一对一对应,通过k找到v。
transient关键字
源码,追进去,进行分析。
数据真正存放的位置还是HashMap$Node当中,Map接口提供的操作Key与Value的方法,操作的都是引用,存放Key引用的集合为Set,存放Value引用的集合为Collection。
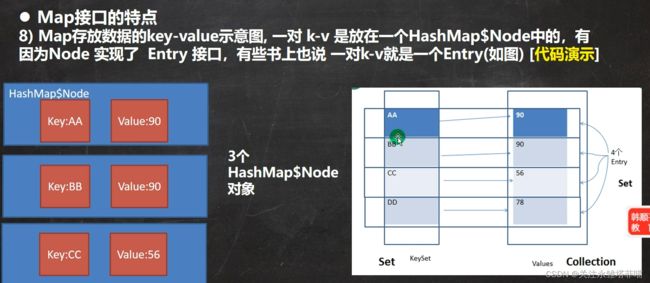
代码
package com.map_;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapSource {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1","韩顺平");
map.put("no2","张无忌");
map.put(new Car(),new Person());
//老韩解读
// 1.最后K-V数据放到HashMap$Node的Node当中了
// 2.方便程序源码遍历创建了EntrySet集合 存放的元素为Entry,而Entry当中包含了K-V。Entry当中的K-V是指向了Node当中
// 的K-V而不是复制了一份。
// 3.EntrySet实现的存放的实际类型来时HashMap$Node因为Node是Map.entry的实现类
// 4.Map.Entry提供了两个重要的方法,getKey和getValue来获得K和V
Set set = map.entrySet();
System.out.println(set.getClass());
for (Object o : set) {
Map.Entry entry = (Map.Entry) o;
System.out.println(entry.getKey()+"-"+entry.getValue());
}
// 具体是什么类型可以通过class来获得
Set set1 = map.keySet();
System.out.println(set1.getClass());
Collection values = map.values();
System.out.println(values.getClass());
}
}
class Car{
}
class Person{}运行结果
class java.util.HashMap$EntrySet
no2-张无忌
no1-韩顺平
[email protected]_.Person@4554617c
class java.util.HashMap$KeySet
class java.util.HashMap$Values
Map接口和常用方法

代码
package com.map_;
import java.util.HashMap;
import java.util.Map;
public class MapMethod {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超",new Book("",100));
map.put("邓超","孙俪"); //会进行替换
map.put("宋喆","马蓉");
map.put("王宝强","马蓉");
map.put("刘令博",null);
map.put(null,"刘亦菲");
map.put("鹿晗","关晓彤");
// 根据键来删除对应关系remove
map.remove(null);
System.out.println("map = "+map);
// 根据K来得到V,get
Object val = map.get("鹿晗");
System.out.println(val);
// 根据size来获得元素的个数
System.out.println(map.size());
// 判断个数是否为0
System.out.println(map.isEmpty());
// 对键值对进行清空
map.clear();
System.out.println("map = "+map);
// 判断键是否存在 还有同样的判断值的方法
map.put("hsp","关晓彤");
System.out.println(map.containsKey("hsp"));
}
}
class Book{
private String name;
private int num;
public Book(String name, int num) {
this.name = name;
this.num = num;
}
}
运行结果
map = {邓超=孙俪, 宋喆=马蓉, 刘令博=null, 王宝强=马蓉, 鹿晗=关晓彤}
关晓彤
5
false
map = {}
true
Map接口的六种遍历方式
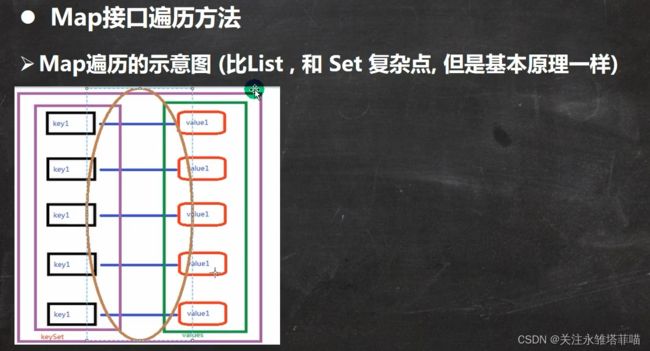
三种遍历方式,和存储的结构有关系

一种通过Set取Key,一种通过Collection取Value,一种通过Entry来取K-V。

代码
package com.map_;
import java.util.*;
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超","孙俪"); //会进行替换
map.put("宋喆","马蓉");
map.put("王宝强","马蓉");
map.put("刘令博",null);
map.put(null,"刘亦菲");
map.put("鹿晗","关晓彤");
// 取出所有Key的值再通过key取出所有的value
Set set = map.keySet();
// (最简单)增强for循环
for (Object key : set) {
System.out.println(key +"-"+map.get(key));
}
System.out.println("=====使用迭代器 第一种====");
// 通过迭代器
Iterator iterator = set.iterator();
while (iterator.hasNext()){
Object key = iterator.next();
System.out.println(key +"-"+map.get(key));
}
System.out.println("=======取出所有的value 增强for 第二种========");
// 一次性取出所有的V
Collection values = map.values();
for (Object value : values) {
System.out.println(value);
}
// Collection都可以用values
System.out.println("=======取出所有的value 迭代器 第三种========");
Iterator iterator1 = map.values().iterator();
while (iterator1.hasNext()) {
Object value = iterator1.next();
System.out.println(value);
}
// 通过EntrySet来获得
Set set1 = map.entrySet();
System.out.println("=======使用EntrySet 的增强for循环,第三种========");
for (Object o : set1) {
Map.Entry map1 = (Map.Entry) o;
System.out.println(map1.getKey()+"-"+map1.getValue());
}
System.out.println("=======迭代器 第四种========");
// 此时迭代器当中的类型是Node -》Entry
Iterator iterator2 = set1.iterator();
while (iterator2.hasNext()) {
Object next = iterator2.next();
// 将得到的Object转型为Entry
Map.Entry map1 = (Map.Entry) next;
System.out.println(map1.getKey()+"-"+map1.getValue());
}
}
}运行结果
邓超-孙俪
宋喆-马蓉
刘令博-null
null-刘亦菲
王宝强-马蓉
鹿晗-关晓彤
===============
邓超-孙俪
宋喆-马蓉
刘令博-null
null-刘亦菲
王宝强-马蓉
鹿晗-关晓彤
=======取出所有的value 增强for========
孙俪
马蓉
null
刘亦菲
马蓉
关晓彤
=======取出所有的value 迭代器========
孙俪
马蓉
null
刘亦菲
马蓉
关晓彤
=======使用EntrySet 的增强for循环,第三种========
邓超-孙俪
宋喆-马蓉
刘令博-null
null-刘亦菲
王宝强-马蓉
鹿晗-关晓彤
=======迭代器========
邓超-孙俪
宋喆-马蓉
刘令博-null
null-刘亦菲
王宝强-马蓉
鹿晗-关晓彤
课堂练习

代码实现
package com.map_;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapExercise {
public static void main(String[] args) {
Map map = new HashMap();
map.put(1,new Emp("jack",100000,1));
map.put(2,new Emp("tom",1000,1));
map.put(3,new Emp("milan",12000,1));
// 使用KeySet 进行遍历
System.out.println("======第一种遍历方式======");
Set set = map.keySet();
for (Object key: set) {
Emp emp = (Emp) map.get(key);
if (emp.getSal()>10000){
System.out.println(emp);
}
}
// 使用EntryMap 进行遍历
System.out.println("======第二种遍历方式======");
Set set1 = map.entrySet();
Iterator iterator = set1.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
// 得到Entry对象
Map.Entry map1 = (Map.Entry) next;
// Entry对象的values的值为Emp
Emp emp = (Emp) map1.getValue();
if (emp.getSal()>10000){
System.out.println(emp);
}
}
}
}
class Emp{
private String name;
private double sal;
private int age;
public Emp(String name, double sal, int age) {
this.name = name;
this.sal = sal;
this.age = age;
}
public Emp() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "emp{" +
"name='" + name + '\'' +
", sal=" + sal +
", age=" + age +
'}';
}
}
结果
======第一种遍历方式======
emp{name='jack', sal=100000.0, age=1}
emp{name='milan', sal=12000.0, age=1}
======第二种遍历方式======
emp{name='jack', sal=100000.0, age=1}
emp{name='milan', sal=12000.0, age=1}
体现了一种包装的思想,包装到emp当中包装到了map当中,再包装到Entry当中
HashMap知识点小结

关于第五条的源码解释:如果添加相同的key则v会进行替换,下面会解释对比的原理。
HashMap的底层以及源码解析
放到table数组的那个位置,是根据hashcode的值随机的进行分配的

HashSet的底层是HashMap,所以扩容机制是相同的,树的查询效率是非常的高的
关于HashMap的详解https://blog.csdn.net/woshimaxiao1/article/details/83661464?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166203910716782248570342%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166203910716782248570342&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-83661464-null-null.142%5Ev44%5Epc_rank_34_queryrelevant25&utm_term=hashmap&spm=1018.2226.3001.4187链接内容节选:
数组:数据的存储方式,一段连续的储存空间。查找当中存储的元素。1.制定下标查找。2.通过给定的值进行查找,要逐个比较数组元素,时间复杂度O(n)。对于有序的算法,可以利用算法来进行优化,如:则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用(具体可以去看数据结构)即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n),链表利于增删不利于查找。
哈希表:哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
HashMap增加元素
package com.map_;
import java.util.HashMap;
public class HashMapSource {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java",10);
map.put("java",20);
map.put("php",10);
System.out.println("map = "+map);
// 源码的执行
/*
1.执行HashMap构造器
初始化加载因子0.75
HashMap$Node[] table = null
2.执行put方法 调用方法执行key的hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
3.执行putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i; //辅助变量
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值所对应的table的索引位置Node,如果为null直接加入K-V,
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k; //辅助变量
//用于判断key的是否相同 hash相同外加equals的比较结果为真,或者节点当中的key的值与加入的key的值相同,就进行覆盖处理
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) //如果当前的Node已经是红黑树了,那就按照红黑树的方式处理
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//Node后面是链表,做如下处理
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //便利到末尾也没有找到相同的元素就直接将新的元素加到最末尾
p.next = newNode(hash, key, value, null);
//如果他的链表个数大于8那么就进行树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果链表当中有相同的元素,就对原有的元素进行覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换key对应的value
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //每增加一个Node就进行size++用来判断是否应该扩容
if (++size > threshold) //大于临界值就进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
4.树扩容的代码分析
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
//如果tab为空,或者tab的长度小于64,那么就进行扩容,扩容是二倍扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
//下面才是树化的代码,书化对应的是剪枝,当红黑树当中的元素小于8时,将红黑树变成链表。
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode hd = null, tl = null;
do {
TreeNode p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
*/
}
}
判断元素是否相同,关键在于key属性的两方面的比较,一方面是equals的结果,一方面是hashcode的值。
HashMap树化和扩容

代码
package com.map_;
import java.util.HashMap;
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
for (int i =0 ;i<=12;i++){
map.put(new A(i),"hello");
}
System.out.println("map = "+map);
}
}
class A{
private int num;
public A(int num) {
this.num = num;
}
@Override
public String toString() {
return "A{" +
"num=" + num +
'}';
}
@Override
//所有A对象的hashcode的值都一样
public int hashCode() {
return 100;
}
}因为hashcode的值都一样,所以都加到table的一个Node节点上面了,当链表的长度大于8的时候不会树化,而是会对table进行扩容,table默认初始化的值为16,直至table>64时,Node上面长度超过8的链表才会树化。
table小于64

链表未进行树化
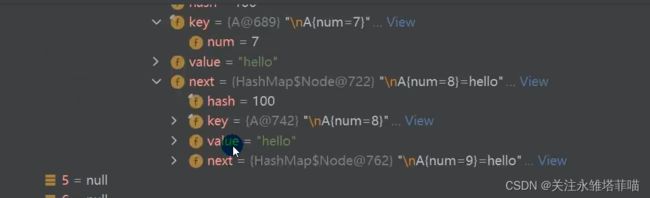
当table>64并且链表的长度>8的时候 Node变为了TreeNode

table的的长度是有阈值的,最后会变成树
对代码进行一些修改,不进行树化,单纯的看看如何扩容
package com.map_;
import java.util.HashMap;
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
for (int i =0 ;i<=12;i++){
// 基本类型数字的Node存放是比较均匀的,比引用类型均匀
map.put(i,"hello");
}
map.put("aaaa","bbbb");
System.out.println("map = "+map);
}
}
class A{
private int num;
public A(int num) {
this.num = num;
}
@Override
public String toString() {
return "A{" +
"num=" + num +
'}';
}
@Override
//所有A对象的hashcode的值都一样
public int hashCode() {
return 100;
}
}结果仅进行table的扩容,没有进行树化
Hashtable类的详解
Hashtable为什么不使用驼峰命名法,版本遗留问题,版本太早,当时没有强制要求使用驼峰命名法。
1.Hashtable的使用

Hashtablede初始table大小为11,临界值依旧是table长度*0.75
package com.map_;
import java.util.Hashtable;
public class HashTable_ {
public static void main(String[] args) {
Hashtable hashTable = new Hashtable();
hashTable.put("john",100);
hashTable.put("lucy",100);
hashTable.put("lic",100);
hashTable.put("lic",88);
hashTable.put("1",1);
hashTable.put("2",1);
hashTable.put("3",1);
hashTable.put("4",1);
hashTable.put("5",1);
hashTable.put("6",1);
hashTable.put("7",1);
System.out.println(hashTable);
}
}
扩容是原来的长度*2+1
源代码
properties类
基本介绍

配置文件,用来修改程序当中的一些关键的属性,比如密码,用户名,方便修改。
读取配置文件https://www.cnblogs.com/xudong-bupt/p/3758136.html案例
package com.map_;
import java.util.Properties;
public class Properties_ {
public static void main(String[] args) {
Properties properties = new Properties();
/*基本的使用方法*/
// 添加数据
// 教继承的是Has和Hashtable所以K和V都不能是null
properties.put("join",1);
properties.put("tom",2);
// properties.put("abc",null); 会出现空指针异常
properties.put("lucy",100);
// 当key相同的时候,会进行替换
properties.put("lic",88);
properties.put("lic",885);
System.out.println(properties);
// 获取数据
System.out.println(properties.get("lic"));
// 删除数据
System.out.println(properties.remove("lic"));
System.out.println(properties);
// 修改数据 使用相同的key就可以了
properties.put("join",10);
System.out.println(properties);
}
}
结果
{tom=2, lic=885, join=1, lucy=100}
885
885
{tom=2, join=1, lucy=100}
{tom=2, join=10, lucy=100}
实际开发当中集合的使用
1.选择是单列还是双列
是一组对象还是一组键值对
如何理解集合的有序与无序https://blog.csdn.net/chen_wwww/article/details/105402079
TreeSet的使用
可以传入构造器
TreeSet的底层是TreeMap

代码
package com.map_;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSet_ {
public static void main(String[] args) {
// TreeSet treeSet = new TreeSet();
// 当我们使用的是无参构造器的时候,仍然是无序的,我们应该自定义他的比较方法,要使用到匿名的内部类,指定排序的规则
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 调用String的比较方法,比较的是ascll吗的值
// return ((String) o1).compareTo(((String) o2));
// 按照String的长度来进行排序
return ((String)o1).length()-((String)o2).length();
}
});
treeSet.add("jack");
treeSet.add("韩顺平");
treeSet.add("sp");
treeSet.add("a");
System.out.println(treeSet);
// 1.将将构造器比较对象,传给了TreeSet底层的TreeMap的this.Comparator属性
// 2.在进行元素添加的时候 ,会执行
/*
*
if (cpr != null) { //cpr是我们的匿名内部类的对象
do {
parent = t;
// 动态绑定到我们的匿名内部类
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
// 对Value进行覆盖,如果两个值相等的话 TreeSet内部的数据结构是Tree
return t.setValue(value);
} while (t != null);
}
* */
}
}
代码结果
[a, sp, 韩顺平, jack]
TreeMap源代码解读
源码
package com.map_;
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMap_ {
public static void main(String[] args) {
// 默认的构造器也是无序的 有默认的比较器,看首字母的ascll值来进行排序
// TreeMap treeMap = new TreeMap();
// 实现了比较器之后的方法
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 按照字符串的ascll进行排序
// return ((String)o1).compareTo(((String)o2));
// 按照字符串的长度来进行解析 相等长度的字符串会被替换 key没有被替换,但是Value被替换了
return ((String)o1).length()-((String)o2).length();
}
});
treeMap.put("jack","杰克");
treeMap.put("tom","汤姆");
treeMap.put("kristina","科儒斯缇娜");
treeMap.put("smith","史密斯");
System.out.println(treeMap);
/*
* 对于源码的解析
* 1。构造器,传入comparator
* 2,。调用put方法
* 第一次添加 将K,V封装到Entry对象当中,放到root当中
* Entry t = root;
* if (t == null) {
compare(key, key); // type (and possibly null) check
//用来检测放入的元素是否为null
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
* 2.以后添加
*Comparator cpr = comparator;
if (cpr != null) {
do { //遍历所有的key
parent = t;
cmp = cpr.compare(key, t.key); //动态绑定匿名内部类
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value); //如果发现绑定的key和原有的key相同就不进行替换
} while (t != null);
}
* */
}
}
运行结果
{tom=汤姆, jack=杰克, smith=史密斯, kristina=科儒斯缇娜}
Collection工具类
工具类提供的方法一
代码
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Collections_ {
public static void main(String[] args) {
// 创建ArrayList集合进行测试
ArrayList list = new ArrayList();
list.add("smith");
list.add("tom");
list.add("king");
list.add("milan");
list.add("A");
list.add("B");
System.out.println(list);
// 使用reverse对list当中的数据进行反转
Collections.reverse(list);
System.out.println(list);
// shuffle方法对数组进行随机的排序 每执行一次,进行一次数组的随机排序
// Collections.shuffle(list);
// System.out.println(list);
// sort根据元素的自然顺序进行升序的排列 按照字符串的大小首字母(ASCLL表)来进行排序
Collections.sort(list);
System.out.println(list);
// 传入一个匿名的内部类,按照自己写得方法进行排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 可以加入校验代码尽心排序
if(o1 instanceof String);
// 根据字符串的长度进行排序
return ((String)o1).length()-((String)o2).length();
}
});
// 长度相同的化吗,是根据Ascll进行排序的 因为允许重复 所以说长度想相同的不会被替换掉
System.out.println(list);
// swap(List,int i,int j)将List集合i处的元素和j(从零开始算起)处的元素进行交换 元素不存在:IndexOutOfBoundsException会出现索引越界异常
Collections.swap(list,2,3);
System.out.println(list);
}
}
运行结果
[smith, tom, king, milan, A, B]
[B, A, milan, king, tom, smith]
[A, B, king, milan, smith, tom]
[A, B, tom, king, milan, smith]
[A, B, king, tom, milan, smith]
工具类提供的方法二

代码
package com.collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Collections1_ {
public static void main(String[] args) {
// 创建ArrayList集合进行测试
ArrayList list = new ArrayList();
list.add("smith");
list.add("tom");
list.add("king");
list.add("milan");
list.add("milan");
list.add("milan");
list.add("A");
list.add("B");
list.add("z");
// 非int类型的字符串不能直接转化为int类型
// max给定自然排序元素当中最大的元素
System.out.println(list);
System.out.println(Collections.max(list));
// 返回长度对大的,根据指定的方法来进行排序
Object max = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).length() - ((String) o2).length();
}
});
// 当长度一样的话,返回的是首字母Ascll值最大的
System.out.println(max);
// min方法和max方法的使用方式都是一样的
// frequency返回元素出现的次数
int milan = Collections.frequency(list, "milan");
System.out.println(milan);
// copy方法,可以将一个集合复制到另一个集合当中 直接复制会有数组越界异常 一定要对数组进行初始化赋值 集合的大小不一样使用的copy方法不一样
ArrayList list1 = new ArrayList();
for(int i=0;i运行结果
[smith, tom, king, milan, milan, milan, A, B, z]
z
smith
3
[smith, tom, king, milan, milan, milan, A, B, z]
[smith, tom, king, 米莉安, 米莉安, 米莉安, A, B, z]
课后总结
本章难度较大,内容较多。多听几遍,写一下思维导图。
HomeWork课后作业
HomeWork01
要求

代码
package com.homework;
import java.util.ArrayList;
public class HomeWork1 {
public static void main(String[] args) {
News news = new News("新冠确诊病例超千万,数百万印度教徒铺横河“圣浴”引起民众担忧");
News news1 = new News("男子想起两个月前捕捉的鱼还在往兜里,捞起一看赶紧放生。");
ArrayList list = new ArrayList();
list.add(news);
list.add(news1);
int size = list.size();
for (int a =size-1 ; a>=0;a--){
News o = (News) list.get(a);
System.out.println(processTitle(o.getTitle()));
}
}
public static String processTitle(String title){
if (title ==null){
return "";
}
if (title.length()>15){
return title.substring(0,15)+"....";
}else {
return title;
}
}
}
class News{
private String content;
private String title;
public News(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
@Override
public String toString() {
return "News{ title=" + title +
'}';
}
}运行结果
男子想起两个月前捕捉的鱼还在往....
新冠确诊病例超千万,数百万印度....
HomeWork02

代码
package com.homework;
import java.util.ArrayList;
import java.util.Iterator;
public class HomeWork2 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
Car car = new Car("宝马", 400000);
Car car1 = new Car("宾利", 5000000);
// 使用add添加元素
list.add(car);
list.add(car1);
System.out.println(list);
// 使用remove移除元素
list.remove(car);
System.out.println(list);
// 使用contains查看元素是否存在
System.out.println(list.contains(car));
// 使用size获取元素的个数
System.out.println(list.size());
// 使用isEmpty判断元素是否为空
System.out.println(list.isEmpty());
// 使用clear进行清空
list.clear();
System.out.println(list);
// 创建一个新的数组
ArrayList list1 = new ArrayList();
list1.add(car);
list1.add(car1);
// 使用addAll添加多个元素
list.addAll(list1);
System.out.println(list);
// 使用containsAll来查询多个元素是否存在
System.out.println(list.containsAll(list1));
// 使用removeAll来移除多个元素
list.removeAll(list1);
System.out.println(list);
// 使用增强 for和 迭代器来进行遍历
for (Object o : list1) {
System.out.println(o);
}
Iterator iterator = list1.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
}
}
}
class Car{
private String name;
private int price;
public Car(String name, int price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void setPrice(int price) {
this.price = price;
}
public int getPrice() {
return price;
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
运行结果
[Car{name='宝马', price=400000}, Car{name='宾利', price=5000000}]
[Car{name='宾利', price=5000000}]
false
1
false
[]
[Car{name='宝马', price=400000}, Car{name='宾利', price=5000000}]
true
[]
Car{name='宝马', price=400000}
Car{name='宾利', price=5000000}
Car{name='宝马', price=400000}
Car{name='宾利', price=5000000}
HomeWork03
要求
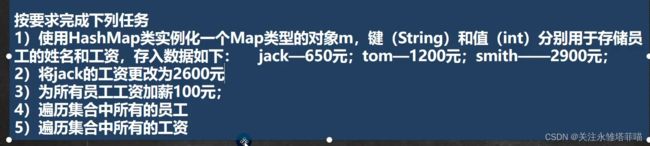
代码
package com.homework;
import java.util.*;
public class HomeWork03 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("jack",650);
map.put("tom",1200);
map.put("smith",2900);
// 回顾操作Map的基本方法
map.put("jack",2600);
System.out.println(map);
Set set = map.keySet();
for (Object o : set) {
map.put(o,(Integer)map.get(o)+100);
}
System.out.println(map);
// 遍历 可以回顾Map的六种遍历方法和原理
Set set1 = map.entrySet();
Iterator iterator = set1.iterator();
while (iterator.hasNext()) {
Map.Entry next = (Map.Entry) iterator.next();
System.out.println(next.getKey()+"-"+next.getValue());
}
System.out.println("==================");
Collection values = map.values();
for (Object value : values) {
System.out.println("工资="+value);
}
}
}运行结果
{tom=1200, smith=2900, jack=2600}
{tom=1300, smith=3000, jack=2700}
tom-1300
smith-3000
jack-2700
工资=1300
工资=3000
工资=2700
HomeWork04
简答题

代码
package com.homework;
import java.util.TreeSet;
public class HomeWork04 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("jsp");
treeSet.add("king");
treeSet.add("king"); //加入不了是因为字符串的compareTo方法比较的是内容
System.out.println(treeSet);
}
}运行结果
[jack, jsp, king, tom]
HomeWork05

什么是动态绑定https://blog.csdn.net/weixin_42247720/article/details/80450238?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166245695516782388043141%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166245695516782388043141&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-80450238-null-null.142^v46^pc_rank_34_queryrelevant25&utm_term=%E5%8A%A8%E6%80%81%E7%BB%91%E5%AE%9A&spm=1018.2226.3001.4187
代码
package com.homework;
import java.util.TreeSet;
public class HomeWork05 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(new Person());
}
}
// 不实现接口,会报类型转换异常,因为TreeSet的底层会进行接口类型转换
class Person implements Comparable {
@Override
public int compareTo(Object o) {
return 0;
}
}HomeWork06
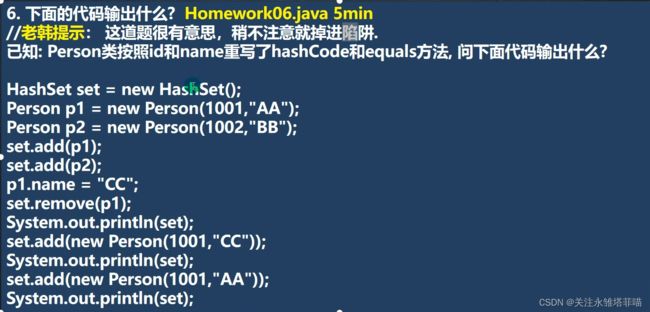
代码
package com.homework;
import java.util.HashSet;
import java.util.Objects;
public class HomeWork06 {
public static void main(String[] args) {
// 前提是你重写了Hashcode方法
HashSet hashSet = new HashSet();
Person p1 = new Person(1001, "小王");
Person p2 = new Person(1002, "小明");
hashSet.add(p1);
hashSet.add(p2);
// 只能在这里进行删除之后就删除不了p1了,删除p1会打歪
// System.out.println(hashSet.remove(p1));
p1.setName("小张");
// 显示删除失败,因为重写了hashcode方法,修改属性之后hashcode也就变了,寻找不到最开始的p1的位置了
System.out.println(hashSet.remove(p1));
// 可以加进去,因为这个位置的hashcode是没有人站的,p1的hashcode虽然改变了,但是位置没有移动
hashSet.add(new Person(1001, "小张"));
System.out.println(hashSet);
// 也可以加进去,因为当进行对比遍历的会后,p1假冒的是小张,小王家住了小张。
// 对比是根据hash和equals对比的,p1当中的是小张,所以hashcode不一样,不会覆盖
hashSet.add(new Person(1001, "小王"));
System.out.println(hashSet);
// 再加就不行了,还是四个元素
hashSet.add(new Person(1001, "小王"));
System.out.println(hashSet);
// 现在remove小王是失败的 打的失小张家,因为p1冒充了小张。
System.out.println(hashSet.remove(p1));
System.out.println(hashSet);
}
}
class Person{
private int id;
private String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object object) {
if (this == object) return true;
if (object == null || getClass() != object.getClass()) return false;
Person person = (Person) object;
return id == person.id &&
name == person.name;
}
// 通过类当中的属性来计算hash
@Override
public int hashCode() {
return Objects.hash(id, name);
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name=" + name +
'}';
}
}
运行结果
false
[Person{id=1001, name=小张}, Person{id=1001, name=小张}, Person{id=1002, name=小明}]
[Person{id=1001, name=小张}, Person{id=1001, name=小张}, Person{id=1001, name=小王}, Person{id=1002, name=小明}]
[Person{id=1001, name=小张}, Person{id=1001, name=小张}, Person{id=1001, name=小王}, Person{id=1002, name=小明}]
true
[Person{id=1001, name=小张}, Person{id=1001, name=小王}, Person{id=1002, name=小明}]
HomeWork07

最终总结,集合类之间的关系和使用环境还不太了解,多涉及。