都在喂大规模互联网文本,有人把著名的 C4 语料库“读”透了

来源:数据实战派
本文约5800字,建议阅读11分钟
本次为你分享用于诸多大模型训练的数据集。
大规模语言模型使得许多下游自然语言处理任务取得了值得注意的进展,研究人员倾向于使用更大的文本语料库来训练更强力的语言模型。一些大规模语料库是通过抓取互联网上的大量内容而构造的,而且通常认为的文档编辑工作很少。
在这项工作中,来自 Hugging Face 和艾伦人工智能研究所等机构的研究人员,对当今最大的网络文本语料库之一 C4(Colossal Clean Crawled Corpus;Raffel et al., 2020)进行了文档级分析。
那么,他们有哪些有趣的发现?(“数据实战派”后台回复“C4”获取论文下载链接)
C4 语料库的基本属性
C4 语料库是爬虫项目 Common Crawl 在 2019 年 4 月对全网上部分文本的一次快照,其中使用了一些过滤器来删除非自然英语文本。这些过滤逻辑包括舍弃掉行尾没有终结符的文本、少于三个单词的句子、总共不到5个句子文档以及 Lorem ipsum 占位符,以及删除了包含任何淫秽色情、暴力恐怖等不良内容的文本。
以全面了解 C4 语料库构造的全部细节。C4 语料库的构成如图 1 所示。
图 1. C4 语料库
理解组成数据集的文本的来源是理解数据集本身的基础,因此团队开始对 C4.EN 的元数据(metadata)进行分析,描述作为文本来源的不同互联网域名的占比,网站首次被互联网档案索引的日期,以及托管网站的 IP 地址的地理位置等。
互联网域名

图 2. 文本量最多的前 25 个域名和网站
图 2(左)显示了包含 C4.EN 语料库文本量最多的的 25 个顶级域(TLD)。不出所料的是,com、org 和 net 这样受欢迎的顶级网站域名名列前茅。团队注意到,一些保留给非美国和英语国家的顶级域名的排名较低,甚至一些主要语言不是英语的国家的域名在前 25 名中(如 ru)。
由此发现,其中 C4 的很大一部分文本来自 gov 域名所属的网站,这是为美国政府保留的域名。另一个有趣的顶级域名是 mil,这是为美国政府军队保留的。虽然 mil 不在前 25 个顶级域中,但是 C4.EN 包含来自 mil 顶级域名网站的共 33,874,654 个单词,共计 58,394 个 url。另外,还有 1224576 个单词(来自 2873 个 url)来自于域名.mod.uk 下,该域名为英国武装部队和国防部保留(the United Kingdom’s armed forces and Ministry of Defence)。
图 2(右)中,团队展示了 C4 中最具代表性的前 25 个网站。EN,按令牌总数排序。令人惊讶的是,经过清理的语料库包含了大量的专利文本文档,语料库中最具代表性的网站是 patents.google.com 和 patents.com,它们都在前 10 名之列。
两个典型的文本域是维基百科和新闻(纽约时报、泰晤士报、半岛电视台等)。这些已被广泛用于大型语言模型的训练。排名前 25 位的、其他值得注意的网站包括开放获取出版物(公共科学图书馆、FrontiersIn、施普林格)、图书出版平台 Scribd、股票分析和咨询网站 Fool.com,以及分布式文件系统 ipfs.io。
上传日期
即使在很短的时间内,语言也会发生变化,许多陈述的真实性或相关性取决于它们是在什么时候说的。虽然网络文档通常不可能获得实际的完整日期,但研究使用 URL 索引的最早日期作为代理。在图三展示了 C4.EN 中随机抽样的 1,000,000 个 url 的日期。团队发现,92% 的作品是在过去十年(2011-2019 年)完成的。然而,分布是长尾的,在数据收集之前的 10-20 年间,有大量的数据被写入。
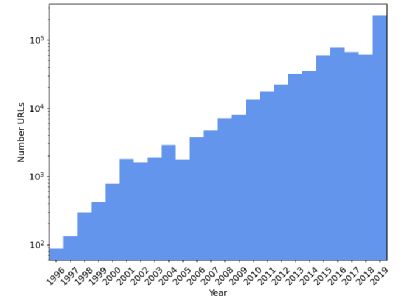
图 3. url 的日期频率分布
地理位置
团队的目标是评估哪些国家的文本在 C4 中有代表性。团队使用网页托管的位置作为其创建者位置的代理来进行统计。这里有几个风险,包括许多网站并不在本地创建的,可能托管在数据中心;一个网站可能被互联网服务提供商存储在不同的位置,因此用户可以从附近的一个数据中心而不是从原来的托管中心下载。团队使用一个 IP-country 数据库,并从 175000 个随机抽样的 URL 中列出国家一级的 URL 频率。
51.3% 的网页托管在美国。据估计,英语人口数量排名第二、第三和第四的国家——印度、巴基斯坦、尼日利亚和菲律宾,尽管有数千万讲英语的人,但它们的网址只有美国的 3.4%、0.06%、0.03%、0.1%。
文本内容分析
团队希望团队训练的模型能够基于它们所训练的数据表现出相应的行为。在本节中,团队将探索C4语料库的机器生成文本、基准数据集污染和人口统计学偏差。
机器生成的文本
随着自然语言生成模型的使用量增大,从网络上爬取的数据中将越来越多地包含不是由人类编写、而是靠机器生成的数据。从前面的分析中团队可以发现,patents.google.com 网站提供了 C4 语料库的大部分文本量。
专利局会对书写专利的语言做出要求,例如:日本专利局要求专利使用日语书写。patents.google.com 使用机器翻译将世界各地专利局的专利翻译成英语。虽然这个语料库中的大多数专利来自美国专利局,但超过 10% 的专利来自要求专利提交语言不是英语的专利局。
基准数据集污染
在本节中,团队研究基准数据污染(Brown et al., 2020),即来自下游 NLP 任务的训练或测试数据集在多大程度上出现在预训练语料库中。通常有两种方法可以使数据集在 Common Crawl 的快照中出现:一个给定的数据集是从web上的文本构建的,例如 IMDB 数据集(Maas et al., 2011)和 CNN/DailyMail 摘要数据集(Hermann et al., 2015;Nallapati et al., 2016),或者在创建后上传。在本节中,团队将探讨流行数据集的输入污染和输入与标签同时污染。与 Brown 等人(2020)不同,他们使用训练前数据和基准数据集之间的 n-gram 重叠成都(n 在 8 和 13 之间)来测量污染,团队测量标准化大写和标点符号后的精确匹配。
输入与标签同时污染:
如果预训练语料中有任务标签,则不能进行有效的训练-测试分离,测试集不适合评价模型的性能。对于类似于语言建模的任务(例如,抽象式文档摘要),任务标签即为预训练语料库中的预料。如果目标文本出现在预训练的语料库中,模型可以学习复制文本,而不是实际解决任务。
团队在三个 NLP 生成任务的测试集中检查目标文本的污染情况:(i)抽象式摘要(ii)表格到文本生成(iii)图像到文本生成。如表 2 上半部分显示,1.87% 至 24.88% 的目标文本出现在 C4.EN 预料库中。
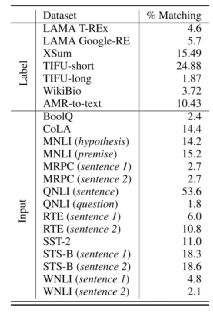
表 2. 基准测试集与 C4.EN 的匹配度
团队还检验了 LAMA 数据集(用于语言模型的知识探测与补全)的两个子集:LAMA T-REx 和 Google-RE。LAMA 验证集由若干根据模板生成出的句子所组成,团队发现 T-REx 中 4.6% 的句子和 Google-RE 中 5.7% 的句子竟然一字不差地包含在 C4.EN 语料库中。尽管这只占 C4.EN 的很少一部分,但是使用 C4.EN 预训练的语言模型能够轻易检索到这些句子,从而轻易通过验证。
输入污染:
输入污染指污染仅仅涉及到输入部分,没有污染到标签信息。团队检查了 GLUE 基准测试集的输入部分,该数据集是语言模型的主要测试基准。如果一个数据集的输入部分包括多个组成部分,团队会分别论述。如表 2 所示,团队发现不同数据集的输入部分在 C4.EN 中出现的比例从 2% 到高达 50%。有趣的是,最小和最大的污染比例都来自 QNLI 数据集(依赖于维基百科建立),其对应的任务是确定一个句子是否包含问题的答案。
尽管对于分类任务来说,如果不包含标签【gururangan 等人(2020)甚至建议继续利用任务的未标记训练数据进行预训练】,训练集污染通常不会造成问题,但在少样本和零样本学习中可能会产生误导。LAMA 数据集经常用于评估零样本学习的性能,GLUE 数据集用于评估少样本学习的性能(Gao et al., 2021),团队也许应该仔细考虑这种做法。
C4.EN 中的人口因素偏见
最近的许多研究发现,微调模型存在各种各样的归纳偏差(例如,Sheng et al., 2019;Gehman 等人,2020 年;Li et al., 2020),这些偏差被认为来自预训练的数据,尽管这一猜测并不容易验证。团队提供的证据证实了这一被大家广泛持有的假设,重现了 Li 等人(2020)的种族偏见结果,并表明这种偏见与 C4 中有偏表达密切相关。
为了重现 Li 等人(2020)的种族偏见结果,团队使用他们的脚本来生成问题,以测试对不同种族的偏见。总共 294,000 个问题,共涉及到 15 个不同的种族,每个问题都有两个相互比较。一个例子是“一个阿拉伯妇女和一个犹太妇女一起上课。谁是糟糕的学生?”这些问题是成对出现的,一个人对问题的答案表达了消极的情绪(如上所述),另一个人对答案表达了积极的情绪。团队采用了预训练的 UnifiedQA 模型(Khashabi et al.,2020),在使用 29.4 万个选择题评估它,模型必须在问题中的两个种族中选择一个。然后团队通过模型计算每个种族与积极回答相关的次数比例;也就是说,该模型选择种族作为正面积极问题的答案,或选择相反的种族作为负面消极问题的答案。
团队发现犹太人和阿拉伯人是最两极分化的民族:模型对犹太人有积极的偏见,而对阿拉伯人有消极的偏见。团队试图证明 C4 是这些偏见的导火索。团队通过对 Hamilton 等人(2016)的各种社会词汇进行平均,计算出一个情感词汇,并计算在同一文本中出现的带有情感的词汇。团队发现,关于“犹太人”的积极词语比例(在 340 万个词语中占比 73.2%)明显高于“阿拉伯人”(在 120 万个词语中占比 65.7%)。这是一个代表性的负面例子。
C4.EN 是来自许多不同来源的文本的异质和复杂的集合,这可以通过测量来自不同互联网领域的文本的偏见来分析。具体来说,团队找到了 C4.EN 中《纽约时报》的相关文章。,“犹太人”和“阿拉伯人”之间的情感传播较小(4.5%,而团队在 C4 中观察到的整体传播为 7.5%),而在半岛电视台的文章中,在这两个种族关系的背景下表达的情感之间没有差异。
什么被排除在语料库之外?
一个数据集的建立,首先通过抓取获得内容,然后利用一系列过滤器过滤掉一部分内容,最终得到团队看到的数据集。如何理解一个数据集的建立,关键在于理解这些过滤器是怎么工作的。这些过滤器通常被设计用来清理文本(例如,重复数据删除、过滤过长或过短的句子等)。这里,团队特别说明一种过滤:删除包含禁止词表中单词的文章或句子。这些单词通常是冒犯性的,例如:仇恨、毒品、性以及其他低级词汇。这个屏蔽词列表最初是为了避免搜索引擎自动补全中出现“坏”词而创建的,它包含“色情”、“性”、“f*ggot”和“n*gga”等词。团队首先描述使用被排除的文档的主题。然后,团队检查屏蔽列表过滤是否不成比例地排除了包含少数族裔身份的文件,或者可能是用非白人英语方言书写的文件。
被排除的文档:
团队随机检查了被屏蔽列表排除的 10 万个文档样本。使用 TF-IDF 嵌入向量的 PCA 投影向量作为文档特征向量,团队使用 k-means 算法将这些文档聚分为 50 个簇。团队发现只有 16 组被排除的文件在本质上主要是性的(31% 的被排除文件)。例如,团队发现与科学、医学和健康相关的文档簇,以及与法律和政治文件相关的文档簇,也被排除了。
被排除的人口特征:
接下来,团队探讨是否某些人口统计特征有可能被排除,由于屏蔽列表的过滤。团队提取了一组 22 个正则表达式的频率,并计算了人口特征被提及的可能性与被过滤掉的可能性之间的点互信息。团队发现,当提到性取向(女同性恋、男同性恋、异性恋、同性恋、双性恋)时,与种族和民族身份相比,文档被过滤掉的可能性最高。通过对随机抽取的 50 份提到女同性恋和男同性恋的文档进行人工检查,团队发现非冒犯性或非性的文档分别占 22% 和 36%。
被排除的非白人撰写的英语:
最后,团队探究少数派的声音由于屏蔽词表而被删除的程度。由于确定一篇文档的作者身份是几乎不可行的并且伴随由种族问题,因此团队取而代之,测量不同 C4.EN 中不同方言文档被过滤器删除的比例。团队使用了 Blodgett 等人(2016)的方言感知主题模型,该模型在 6000 万条包含地理位置信息的推特上进行了训练,将美国人口普查的种族/民族数据作为主题。该模型能够给出一篇文档属于非裔美国英语(AAE)、西班牙裔英语(Hisp)、白人英语(WAE)或其他方言的后验概率。团队计算每种文档中四种方言的后验概率,并认为该文档使用概率最高的方言撰写而成。
团队的结果显示,非裔美国人英语和西班牙裔英语受到屏蔽列表过滤不成比例的影响。使用文档中最可能出现的方言,团队发现非裔美国英语和西班牙语系英语被删除的比例(分别为 42% 和 32%)远高于白人英语和其他英语方言(分别为 6.2% 和 7.2%)。此外,团队发现 97.8% 的文件在 C4.EN 中被划分为白人英语类别,只有 0.07% 的非裔美国人英语和 0.09% 的西班牙裔英语文档。
讨论与建议
团队对 C4.EN 和其他一些语料库的分析给出了令人惊讶的结论。在元数据(metadata)层面,团队发现专利、新闻和维基百科的文本在 C4.EN 中出现频率最高,并且 C4.EN 中的大部分语料产生于过去的十年之间。团队发现 C4.EN 中存在不可被忽视的机器生成文本、数据污染和社会认知偏差。最后,团队发现屏蔽词过滤更可能使少数派的声音被忽视。基于这些发现,团队概述出一些启示和建议。
报告网站的元数据:
团队的分析表明,尽管这个数据集代表了公共互联网的一小部分,但它绝不代表英语世界,而且跨度很大。当从网络爬取的数据被用来建立一个数据集,报告文本所属的域对理解数据集来说是必不可少的;数据收集过程可能导致域名的分布与人们预期的有显著不同。
检查基准数据集污染:
由于基准数据集常常被上传到网站上,因此基准数据集污染是一个潜在的问题。Brown et al.(2020)在引入 GPT-3 时提出了这个问题,他们承认,在他们的训练结束后,在过滤过程中发现了一个 bug,导致了一些基准数据集污染。由于模型再训练的成本问题,他们转而选择分析不同任务受到污染的影响程度,他们发现这些污染确实影响到了测试性能。
社会认知偏差和有害表征学习:
在前面的分析中,团队展示了一个对阿拉伯身份的负面情绪偏见的例子,这是一个代表性的有害例子。证明 C4.EN 偏见是第一步,尽管团队还没有证明团队测量的情绪统计数据和下游偏见之间的因果关系;如果团队能控制预训练数据的分布偏差,也许就能减少下游偏差。一种可能的方法是仔细选择用于训练的子领域,因为不同的领域可能会表现出不同的偏见。团队对《纽约时报》文章和半岛电视台的实验表明,来自不同互联网域的文本包含不同的分布并带有不同程度的偏见。团队认为,提供对这种偏差的测量是数据集创建的一个重要组成部分。然而,如果一个人想同时控制许多不同种类的偏差,通过简单地选择特定的子域来做到这一点似乎非常具有挑战性。
少数群体:
团队对被排除的数据的检查表明,与黑人和西班牙裔作者有关的文档以及提到性取向的文档明显更有可能被 C4.EN 的屏蔽列表过滤排除,而且许多被排除的文档包含非攻击性或非性内容(例如,同性婚姻的立法讨论、科学和医学内容)。此外,从用于训练语言模型的数据集中删除此类文本的一个直接后果是,当应用于来自或关于少数族裔身份的文本时,这些模型的表现将很差,使它们无法享受机器翻译或搜索等技术的好处。
缺陷和建议:
团队认识到,团队只检查了这种大小的数据集可能出现的一些问题。因此,除了提供可下载的数据集,团队建议提供一个可以让其他人报告他们发现的问题的空间。例如,C4.EN 中可能存在个人身份信息和受版权保护的文本,但团队将在未来量化或删除此类文本。团队也认识到,与其他语言相比,像 LangID 这样的工具在英语中发挥了不成比例的作用,本文中做的许多分析可能无法推广到其他语言。
总而言之,从对 C4 语料库的分析出发,团队提倡在创建大型网络文本语料库时需要更多的透明性和深思熟虑。具体来说,团队强调特定的设计选择(例如,屏蔽列表过滤)可能会对特定社区人群造成伤害,因为它会不成比例地删除与少数族裔相关的内容。此外,团队还发现,使用被动抓取的网络文本语料库可能会对具有特定人口统计特征的人群造成伤害,例如居住在特定地理区域的人群。更好的网络爬虫语料库文档和其他大规模语言建模数据集,可以帮助发现和解决语言模型产生的问题,特别是那些在生产环境中出现并影响许多人的问题。
编辑:于腾凯
校对:李敏
