八、kotlin的高阶函数
theme: Chinese-red
高阶函数
是什么?
一种以另一个函数为参数、返回值或两者兼顾的函数叫高阶函数


函数类型
整数类型, 可以存放整数, 字符串类型可以存放字符串, 而函数类型则可以存放函数引用
首先, 函数是虚拟的存在, 所以没有类型, 也没有对象
但是我们可以将函数的参数列表和返回值类型归纳为一种实化类型
只要有了实化类型, 就会有对应的对象
val sum: (Int, Int) -> Int = { x, y -> x + y }
val action: () -> Unit = { println(42) }
var canResultNull: (Int, Int) -> Int? = { null }
var funOrNull: ((Int, Int) -> Int)? = null
上面(Int, Int) -> Int 和 () -> Unit 就是函数类型
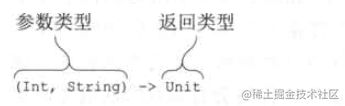
记住
函数类型是 以小括号包裹参数用->隔离参数和返回值, 搞懂这个非常重要,比如:
(Int) -> (Int) -> Char表示 参数是Int返回值是(Int) -> Char函数类型。还可以这样:
((Int) -> Int) -> Char, 参数是((Int) -> Int)函数类型, 返回值是Char
函数类型的参数名称
fun performRequest(url: String, callback: (Int, String) -> Unit) {
// ...
}
fun performRequest(url: String, callback: (code: Int, content: String) -> Unit) {
// ...
}
看两个区别:
(1) callback: (Int, String) -> Unit
(2) callback: (code: Int, content: String) -> Unit
除了参数带上名字外, 其实本质上没有区别
参数的名字只不过是为了代码的可读性
调用作为参数的函数
fun twoAndThree(operator: (Int, Int) -> Int) {
val result = operator(2, 3)
println("The result is ${result}")
}
实现一个简化版的 filter
private fun String.myFilter02(predicate: Char.() -> Boolean): String {
val sb = StringBuilder()
this.forEach {
if (predicate(it)) {
sb.append(it)
}
}
return sb.toString()
}
private fun String.myFilter01(predicate: (Char) -> Boolean): String {
val sb = StringBuilder()
this.forEach {
if (predicate(it)) {
sb.append(it)
}
}
return sb.toString()
}
fun main() {
val str: String = "abc123"
println(str.myFilter01 { it in 'a'..'z' })
println(str.myFilter02 { this in 'a'..'z' })
}
函数类型默认参数
private fun String.filter(predicate: (Char) -> Boolean = { it in 'a'..'z' }) {
// ...
}
返回函数的函数
根据某些条件判断返回不同的逻辑(函数引用 + 函数参数栈)
enum class Delivery {
STANDARD, EXPEDITED
}
class Order(val itemCount: Int)
fun getShippingCostCalculator(delivery: Delivery): (Order) -> Double {
if (delivery == Delivery.EXPEDITED) {
return {order -> 6 + 2.1 * order.itemCount }
}
return { order -> 1.2 * order.itemCount }
}
fun main() {
val calculator = getShippingCostCalculator(Delivery.EXPEDITED)
println(calculator(Order(3)))
}
返回函数保存了
函数引用 + 函数栈帧, 看下面的代码:
fun sum(a: Int, b: Int): Int {
return a + b
}
fun myFun(a: Int, b: Int): () -> Int {
return { sum(a, b) }
}
fun main() {
// mFun 保存了函数引用和函数参数栈帧
val mFun = myFun(20, 39)
// 所以在这里会输出为 59, 因为它有栈帧, 保存了 a = 20, b = 39
val i = mFun()
println(i) // 59
}
lambda 的使用场景之一: 去除重复代码
Shaw因为旅游喜欢上了地理,然后他建了一个所有国家的数据库。作为一名程序员,他设计了一个CountryApp类对国家数据进行操作。Shaw偏好欧洲的国家,于是他设计了一个程序来获取欧洲的所有国家。
data class Country(
val name:String,
val continent: String,
val population: Int
)
class CountryApp {
fun filterCountries(countries: List<Country>): List<Country> {
val list = mutableListOf<Country>()
for (country in countries) {
if (country.continent == "EU") {
list.add(country)
}
}
return list
}
}
调用它:
val countrues = listOf(x, y, z)
val countryApp = CountryApp()
countryApp.filterCountries(countries)
但是这么写存在很大的问题,该功能只针对欧洲。太过于具体了,需要抽象
第一次改造的代码:
fun filterCountries(countries: List<Country>, continent: String): List<Country> {
val list = mutableListOf<Country>()
for (country in countries) {
if (country.continent == continent) {
list.add(country)
}
}
return list
}
调用它:
val countrues = listOf(x, y, z)
val countryApp = CountryApp()
countryApp.filterCountries(countries, "EU")
之后多了个需求,需要取到大于某人数的国家
fun filterCountries(countries: List<Country>, continent: String, population: Int): List<Country> {
val list = mutableListOf<Country>()
for (country in countries) {
if (country.continent == continent && country.population > population) {
list.add(country)
}
}
return list
}
调用它:
val countrues = listOf(x, y, z)
val countryApp = CountryApp()
countryApp.filterCountries(countries, "EU", 10_000_000)
总结下需要改的地方在:
-
函数
filterCountries需要添加参数,并且在函数体内需要添加响应的落实 -
调用方需要添加多少人数
好恶心
那我们把这些变化封装了吧
class CountryTest {
companion object {
fun isEuropeanBigCountry(country: Country): Boolean {
return country.continent == "EU" && country.population > 10_000_000
}
}
}
调用它:
val countryApp = CountryApp()
val countryList = countryApp.filterCountries(listOf(
Country("zhazha", "EU", 10_000_101),
Country("heihei", "EU", 10_000_102),
Country("hoho", "EU", 10_000_103)), "EU", 10000000)
for (country in countryList) {
println(country)
}
但带来个新的问题
fun isEuropeanBigCountry(country: Country): Boolean {
return country.continent == "EU" && country.population > 10_000_000
}
country要set哪些字段?
再改
fun filterCountries(countries: List<Country>, countryTest: CountryTest): List<Country> {
val list = mutableListOf<Country>()
for (country in countries) {
if (countryTest.isEuropeanBigCountry()) {
list.add(country)
}
}
return list
}
data class CountryTest(
val continent: String,
val population: Int
) {
fun isEuropeanBigCountry(): Boolean {
return continent == "EU" && population > 10_000_000
}
}
调用它:
val countryApp = CountryApp()
val countryList = countryApp.filterCountries(listOf(
Country("zhazha", "EU", 10_000_101),
Country("heihei", "EU", 10_000_102),
Country("hoho", "EU", 10_000_103)), CountryApp.CountryTest("EU", 10000000))
for (country in countryList) {
println(country)
}
等下, 还能再优化:
算了, 已经成java式"过度优化"(瞎吉儿"优化")了
CountryTest类可以使用Builder模式封装
但…
这算优化么? 还是那么多文件需要修改…
不过也算优化吧, 把需要修改的文件和主逻辑的文件区分开来, 到时候修改不会影响到主逻辑
越优化越复杂…
此时, 我们可以考虑使用 lambda
fun filterCountries(countries: List<Country>, filter: Country.() -> Boolean): List<Country> {
val list = mutableListOf<Country>()
for (country in countries) {
if (country.filter()) {
list.add(country)
}
}
return list
}
val countryApp = CountryApp()
val countryList = countryApp.filterCountries(listOf(
Country("zhazha", "EU", 10_000_101),
Country("heihei", "EU", 10_000_102),
Country("hoho", "EU", 10_000_103))
) {
this.continent == "EU" && this.population > 10_000_000
}
for (country in countryList) {
println(country)
}
非常的 nice
Function类型
kotlin设计了Function0、Function1。。。到Function22来兼容 java 的lambda表达式
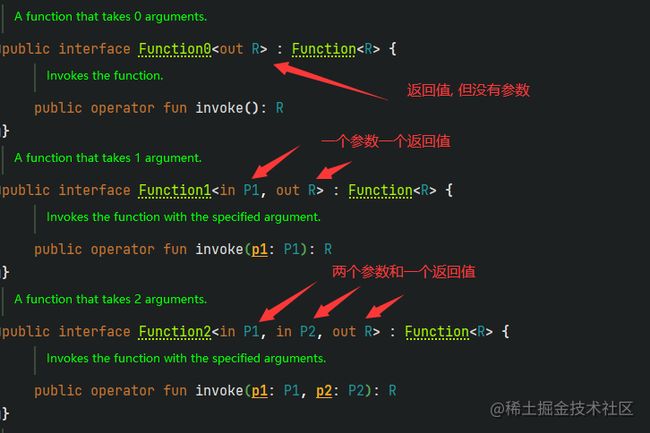
Function0表示 0 个参数,一个返回值
Function1表示 1 个参数,一个返回值
Function22表示 22 个参数,一个返回值
出现这种情况的原因是,kotlin支持使用函数做参数或者返回值,java 中只能用 函数式接口 实现传递函数类型参数,所以 java 的函数式接口需要转化成 Function0 ~ 22 ,同时 kotlin中的函数也需要借助 Function 系列接口代替翻译成 java 的函数式接口
fun foo(int: Int): () -> Unit = {
println(int)
}
fun main() {
listOf(1, 2, 3).forEach {
foo(it).invoke()
}
}
这里的 foo 函数的返回值如果翻译成 java 就是 Function0
public static final Function0<Unit> foo(int n) {
return new Function0<Unit>(n){
final int $int;
{
this.$int = $int;
super(0);
}
public final void invoke() {
System.out.println(this.$int);
}
};
}
柯里化 风格
fun sum(x: Int)= { y: Int ->
{z: Int -> x + y + z}
}
sum(1)(2)(3)
fun curryingLike(content: String, block: (String) -> Unit) {
block(content)
}
fun main() {
curryingLike("look like currying stycle") {content ->
println(content)
}
}
fun <A, B> Array<A>.corresponds(that: Array<B>, p: (A, B) -> Boolean): Boolean {
val i = this.iterator()
val j = that.iterator()
while (i.hasNext() && j.hasNext()) {
if (!p(i.next(), j.next())) {
return false
}
}
return !i.hasNext() && !j.hasNext()
}
val a = arrayOf(1, 2, 3)
val b = arrayOf(2, 3, 4)
a.corresponds(b) { x, y ->
x + 1 == y
}
a.corresponds(b) { x, y ->
x + 2 == y
}
内联函数, 消除 lambda 带来的代价
是什么?
内联函数, 主要的功能是一处内联, 到处(调用处)粘贴(函数体)
功能和 c语言的宏定义很像, 主要就是在调用到内联函数的位置, 直接把内联函数体拷贝过去, 然后去掉该函数的名称和作用域(也就是 {} 括号)
同时, 内联函数还可以把传入的已经调用的 lambda 参数也给内联了
记住是已经 传入的并且已经调用了的lambda表达式才能内联
记住是已经 传入的并且已经调用了的lambda表达式才能内联
记住是已经 传入的并且已经调用了的lambda表达式才能内联
inline fun f(param: () -> Unit) {
println("inline function")
param()
return
}
fun main() {
f { println("lambda") }
}
反编译后:
String var1 = "inline function";
System.out.println(var1);
String var4 = "lambda";
System.out.println(var4);
传入的对象无法内联
注意只有 传入的已经被调用的 lambda 参数才可以内联, 如果传入的是一个对象则不可以内联对象, 看下面这段代码:
fun main() {
val v: () -> Unit = { println("lambda") }
f(v)
}
反编译后的java源码是这样:
Function0 v = (Function0)null.INSTANCE;
String var2 = "inline function";
System.out.println(var2);
v.invoke();
发现了没有?
Function0 v = (Function0)null.INSTANCE;这个v就是前面的变量, 该 lambda 表达式已经变成了对象
编译器遇到内联函数的大体处理步骤
原始代码:
inline fun f(param: () -> Unit): Int {
println("inline function")
param()
return Random(100).nextInt()
}
fun main() {
println("进入 f 函数之前: ")
val v = f { println("lambda") }
println("v = $v")
println("进入 f 函数之后")
}
- 把函数体的lambda表达式内联掉
inline fun f(param: () -> Unit): Int {
println("inline function")
println("lambda") // 内联 lambda 表达式
return Random(100).nextInt()
}
- 把函数体拷贝到调用该内联函数的位置, 把 内联函数的
return处理下
记住是 内联函数的
return, 不是lambda的return
记住是 内联函数的return, 不是lambda的return
记住是 内联函数的return, 不是lambda的return
fun main() {
println("进入 f 函数之前: ")
println("inline function")
println("lambda") // 内联 lambda 表达式
val v = Random(100).nextInt()
println("v = $v")
println("进入 f 函数之后")
}
至此, 完成内联函数的内联大致过程, 其中还有在内联过程中如果遇到实参传递形参时怎么处理没搞, 会在后续讲
注意到
return了么? 如果inline真的是直接拷贝内联函数体代码到调用处, 代码肯定会直接返回, 而不是 执行println("进入 f 函数之后"), 但实际上, 它执行了.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MRSxweal-1656299795610)(https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/3539442d4dbe4dd586d70ec859e7380b~tplv-k3u1fbpfcp-watermark.image?)]
我们把代码改成f{ println("lambda") }:
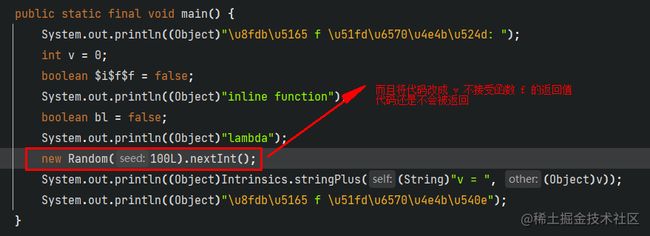
调用函数的返回值不会被内联函数直接内联到调用出, 而是去除 return 关键字, 再把 return 后面的代码拷贝过来, 如果有变量接受返回值, 就直接赋值给返回值
记住是调用函数哦, 不是被 内联函数函数类型表达式参数 的 return 表达式
需要注意内联函数类型参数的return
inline fun f(param: () -> Unit): String {
println("inline function")
param()
return "有返回值"
}
fun main() {
val f = f {
println("lambda")
return
}
println(f)
}
inline function
lambda

如果这段代码没有return的话
val f = f {
println("lambda")
}
println(f)
输出的将会是:
inline function
lambda
有返回值
有return的话:
val f = f {
println("lambda")
return // 这段代码没有 return
}
println(f)
代码将会是下面这样:
fun main() {
val f = f {
println("inline function")
println("lambda")
return // 这里直接返回了, 后面的 有返回值 不会再赋值给变量f
"有返回值"
}
println(f) // "有返回值"
}
所以返回的"有返回值"没有传递给变量f, 在后面的println(f)不会打印出"有返回值"这几个字
记住这和前面内联函数返回值不同, 这是内联函数参数的返回值
内联函数的返回将会被去掉
return赋值给变量或者凭空执行内联函数参数的返回值将会不经过处理, 直接原封不动的拷贝过去
为什么要引入内联函数?
答: 让内联函数中的
lambda参数不再创建对象
看代码:
fun f(param: () -> Unit) {
println("inline function")
param()
}
fun main() {
println("进入 f 函数之前: ")
f { println("lambda") }
println("进入 f 函数之后")
}
反编译后会发现 f { println("lambda") } 这段代码变成 f((Function0)null.INSTANCE); 看到没???
lambda 表达式创建了个对象, 这是一次损耗
在 kotlin 中 类似 f 函数这种参数有函数类型的高阶函数有很多很多, 每次传递 lambda 到这些高阶函数中都需要创建一个对象, 太损耗性能了, 所以不得不引用内联函数这项功能
前面说过, 有了内联函数, 调用内联函数的位置将被替换成内联函数的函数体, 这样就少创建了个 { println("lambda") } 对象
有什么缺点?
答: 缺点很明显, 内联函数只针对有函数类型参数的函数内联, 主要的目的为了防止 lambda 多创建的 对象, 但如果内联函数的函数体比较大, 且函数调用的位置比较多, 则会造成字节码大量膨胀, 影响 apk 包的大小
所以通常内联函数都比较短小, 特别是项目对 app 大小有严格要求的情况下, 更需要注意
高阶函数控制流
kotlin中的非内联lambda不允许显示的使用return(它不需要, 只要返回值放在表达式末尾就是返回值), 而内联的lambda表达式可以显示的使用return, 但返回的是外部调用它的函数, 内联lambda的return会穿透一层作用域
lambda 返回最后一行的值
fun running(a: Int, b: Int, funcType: (Int, Int) -> Int) = funcType(a, b)
fun main() {
running(10, 20) {x: Int, y: Int ->
x + y
}
}
上面这种返回方式和下面这种一样
fun main () {
running(10, 20, fun(x: Int, y: Int) {
return x + y
})
}
内联函数的非局部返回
看似是局部(
lambda)的return, 其实是调用lambda函数的return
lambda内的
return会穿透一层作用域
inline fun running(a: Int, b: Int, funcType: (Int) -> Int) {
funcType(a + b)
}
fun main() {
println("调用之前: ")
// 下面这种方式是错误的, return it 返回的是 main 函数
running(10, 20) {
println(it)
return it // 这就是 非局部返回
}
println("调用之后")
}
上面的
return it就是非局部返回, 返回的main函数
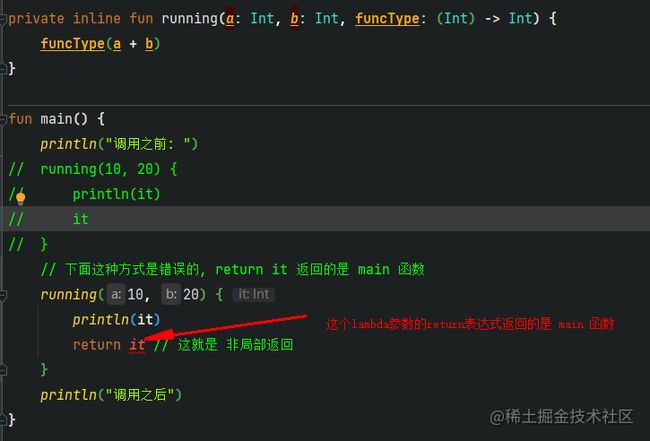
所以上面的提示就是让你修改 main 函数的返回值

我们可以给 return 表达式一个标签return @running it, 返回的是running函数
noinline用于未调用的lambda函数类型参数
防止照抄内联函数参数的参数名称到 main 函数中, 导致无法识别的问题
比如:
fun main() {
println("zhazha")
return funcType02; // 这能不报错?
}
它在下面是 running 函数的 参数名funcType02: (Int) -> Unit

此时我们可以添加noinline 关键字
inline fun running(funcType01: (String) -> Unit, noinline funcType02: (Int) -> Unit) {
funcType01("zhazha")
return funcType02
}
fun main() {
running({ println(it) }, { println(it * 10) })
}

注意, 如果内联函数的 lambda 参数没有被调用, 最好使用使用 noinline 的话, 否则将会变成这样:

crossinline 的使用场景
主要用于
函数参数lambda参数的lambda作为函数体内另一个函数调用时使用, 说白了就是间接调用
fun interface MyRunnable {
fun myF()
}
inline fun running(a: Int, b: Int, crossinline funcType: (Int, Int) -> Int) {
MyRunnable {
// 在作用域的作用域内使用
println(funcType(a, b))
}.myF()
}
fun main() {
running(10, 20) { x, y ->
x + y
}
}
crossinline 需要配合 inline 的使用, 主要用于函数类型参数, 防止函数类型参数传递的是 lambda 函数体时, 间接调用使用, 如果该间接调用lambda内有return, 该修饰符能够防止非局部返回出现, 导致函数穿透一层作用域返回 running 函数
上面的
noinline和crossinline都不用我们去学, 等到报错,ide会提醒, 并修复的
lambda中的局部返回
带标签的return是什么?
类似于 for 循环中的 break
val list = arrayListOf(Person("a", 1), Person("b", 2), Person("c", 3))
for (person in list) {
if (person.name == "b") {
break
}
println(person)
}
list.forEach {
if (it.name == "b") {
return@forEach
}
println(it)
}
list.forEach label@ {
if (it.name == "b") {
return@label
}
println(it)
}
上面这三种方式功能都差不多
标签是 标签 + @ 标注在 lambda 表达式之前 标签@{ /* lambda */ }
使用的时候是 return + @ + 标签 中间没有空格, 这是返回
带标签的 this
和前面一样, 对 lambda 做标签 标签@ , 然后在使用的时候可以 this@标签.xxxx
println(StringBuilder().apply sb@ {
listOf(1, 2, 3).apply {
this@sb.append(this.toString())
}
})
[email protected]的appendIDEA无法智能提示, 需要我们主动手写
匿名函数使用的是 局部返回
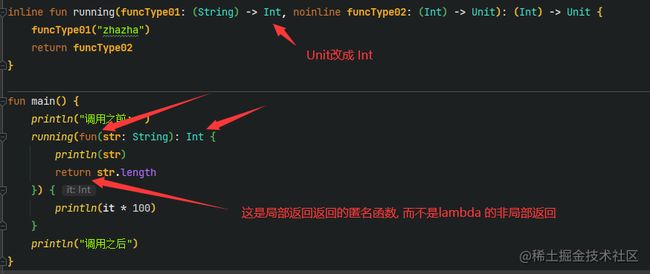
inline fun running(funcType01: (String) -> Int, noinline funcType02: (Int) -> Unit): (Int) -> Unit {
println(funcType01("zhazha"))
return funcType02
}
fun main() {
println("调用之前: ")
running(fun(str: String): Int {
println(str)
return str.length
}) {
println(it * 100)
}
println("调用之后")
}
if (it.name == “b”) {
return@forEach
}
println(it)
}
list.forEach label@ {
if (it.name == “b”) {
return@label
}
println(it)
}
上面这三种方式功能都差不多
标签是 `标签 + @` 标注在 `lambda` 表达式之前 `标签@{ /* lambda */ }`
使用的时候是 `return + @ + 标签` 中间没有空格, 这是返回
#### 带标签的 this
和前面一样, 对 `lambda` 做标签 `标签@` , 然后在使用的时候可以 `this@标签.xxxx`
```kotlin
println(StringBuilder().apply sb@ {
listOf(1, 2, 3).apply {
[email protected](this.toString())
}
})
[email protected]的appendIDEA无法智能提示, 需要我们主动手写
匿名函数使用的是 局部返回
inline fun running(funcType01: (String) -> Int, noinline funcType02: (Int) -> Unit): (Int) -> Unit {
println(funcType01("zhazha"))
return funcType02
}
fun main() {
println("调用之前: ")
running(fun(str: String): Int {
println(str)
return str.length
}) {
println(it * 100)
}
println("调用之后")
}
[外链图片转存中…(img-8Q7MAHop-1656299795624)]
匿名函数在之前的章节中学习过, 这里就不做详解了