I/O多路复用(转接)
I/O多路复用(转接)
- 从阻塞I/O到非阻塞I/O再到I/O多路复用
- select
- poll
- epoll
从阻塞I/O到非阻塞I/O再到I/O多路复用
所谓复用,指的是一个线程能够被多个socket连接复用,个人觉得理解这个复用对这个知识的掌握很重要。
阻塞I/O:服务器端socket创建、绑定之后会进入到监听状态。一旦客户端有连接请求,就新建一个socket用于数据传输。如果对应套接字的读缓冲区中有数据,便去读取数据,没有数据就阻塞,多线程。
非阻塞I/O:和阻塞I/O的策略不同,不管对应socket的读缓冲区是否有数据,读方法都会返回一个值,使得程序继续往下推进,多线程。
I/O多路复用:一个线程同时监听多个读缓冲区的文件描述符,当有数据的时候再去做相应的数据操作。
这三种方法,即从阻塞I/O到非阻塞I/O再到I/O多路复用,它们一定是后一个比前一个性能高的嘛? 先给出答案,不是,具体选用哪种方法得看自己的场景。
多线程本身并不能提高效率,因为他反而会在一定程度上降低CPU运算效率(特别是在线程数远远大于CPU核心数时),多线程的好处在于异步,避免一个线程在等待其他资源时,cpu空闲。
多线程采用阻塞I/O策略时,如果多个线程等不到数据,它们会一直被阻塞,线程可用数少了,可用线程数变少。非阻塞IO本身不会提高速度,只是他在一定程度上能够降低并发数,从而提高CPU效率。 这是从阻塞I/O到非阻塞I/O。
IO 多路复用这么强,如果把业务开发全部改造成这种模型是不是性能会大幅度提升?实则不然,IO 多路复用的优势是使用更少的线程处理更多的连接,例如 Nginx,网关,这种可能需要处理海量连接转发的服务,它们就非常适合使用 IO 多路复用。IO 多路复用并不能让你的业务系统提速,但是它可以让你的系统支撑更多的连接。
所以,千万别认为:非阻塞I/O就比阻塞I/O强,I/O多路复用就比阻塞或者非阻塞I/O强!!要不然就会陷入我的怪圈,绕一天。
在知道折三种I/O的区别之后,我们可以去了解I/O多路复用的三种实现方法:select、poll、epoll。
select
主旨思想:
- 首先要构建一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
- 系统调用,监听该列表中的文件描述符,知道这些描述符中的一个或者多个进行I/O操作时,该函数才返回。这个函数是阻塞的。
- 在返回时,它只告诉进程有多少描述符要进行I/O操作。
看看相应的API对这个实现方法会有更深的理解:
#include 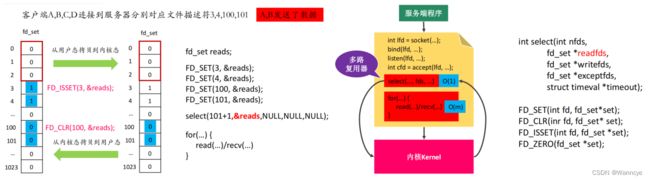
这个图说的就是:
主旨思想:
- 首先要构建一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
- 系统调用,监听该列表中的文件描述符,知道这些描述符中的一个或者多个进行I/O操作时,该函数才返回。这个函数是阻塞的。
- 在返回时,它只告诉进程有多少描述符要进行I/O操作。
有这么一个流程,他就有对应的缺点:
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时,会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时,也很大
- select支持的文件描述符数量太小了,只有1024
- fds集合不能重用,每次都需要重置(拷贝进内核之后,内核会对标识位进行修改并返回。如果是没有修改的标识位置0,再次拷入内核的时候,就不再监听该文件描述符了。所以需要重置。)
poll
poll是基于select做出的改进,解决了select的集合不能重用。最主要是定义了一个结构体:
#include 例如,读缓冲区来数据了,就可以修改revents来对用户进行通知。对应poll的API:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
- 参数:
- - fds : 是一个struct pollfd 结构体数组,这是一个需要检测的文件描述符的集合
- - nfds : 这个是第一个参数数组中最后一个有效元素的下标 + 1
- - timeout : 阻塞时长
- - - 0 : 不阻塞
- -1 : 阻塞,当检测到需要检测的文件描述符有变化,解除阻塞
- >0 : 阻塞的时长
- - 返回值: -1 : 失败 >0(n) : 成功,n表示检测到集合中有n个文件描述符发生变化
关于事件的参数列表如下;

select和poll的原理很像,只是解决了文件描述符表能否重用的问题,就不过多解释了。
epoll
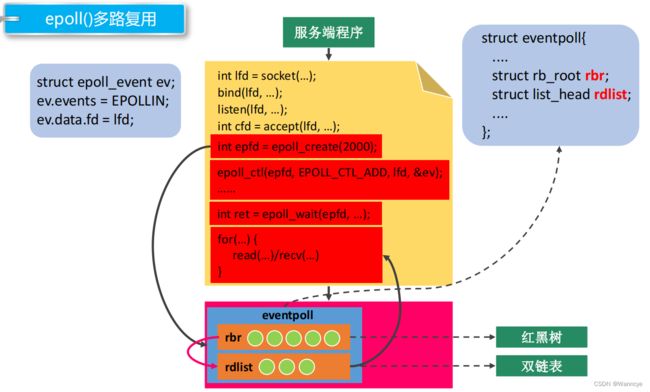
epoll在poll的基础上做出改进,解决了select的大多数问题,效率很高。最重要的也是一个结构体:
struct eventpoll{
....
struct rb_root rbr;
struct list_head rdlist;
....
};
文件描述符表采用红黑树来存储,只存放需要监听的文件描述符。红黑树提高了查询效率,只存放需要监听的文件描述符让遍历的次数减少。
发生改变的文件描述符采用双链表存储。不仅能返回多少个文件描述符发生了变化,还能告诉用户哪些文件描述符发生了变化。用户再遍历这些变化的文件描述符时可以不像select那样遍历到最大值,只需要遍历发生改变的文件描述符。
而且,epoll会创建一个在内核的属于自己的文件描述符来管理其他文件描述符,这样又避免了文件描述符表从用户态到内核态的拷贝。
怎么说,加粗的都是优点。优点多的就离谱。
记录一下epoll的API:
// 创建一个新的epoll实例。在内核中创建了一个数据,这个数据中有两个比较重要的数据,
// 一个是需要检 测的文件描述符的信息(红黑树),还有一个是就绪列表,存放检测到数据发送
// 改变的文件描述符信息(双向 链表)。
int epoll_create(int size);
- 参数:
- size : 目前没有意义了。随便写一个数,必须大于0
- 返回值:
- -1 : 失败
- >0 : 文件描述符,操作epoll实例的
// 对epoll实例进行管理:添加文件描述符信息,删除信息,修改信息
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- 参数:
- - epfd : epoll实例对应的文件描述符
- - op : 要进行什么操作
- EPOLL_CTL_ADD: 添加
- EPOLL_CTL_MOD: 修改
- EPOLL_CTL_DEL: 删除
- - fd : 要检测的文件描述符
- - event : 检测文件描述符什么事情
// 检测函数
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
- 参数:
- - epfd : epoll实例对应的文件描述符
- - events : 传出参数,保存了发送了变化的文件描述符的信息
- - maxevents : 第二个参数结构体数组的大小
- - timeout : 阻塞时间
- - 0 : 不阻塞
- - -1 : 阻塞,直到检测到fd数据发生变化,解除阻塞
- - > 0 : 阻塞的时长(毫秒)
- - 返回值:
- - 成功,返回发送变化的文件描述符的个数 > 0
- - 失败 -1