Spark sql Expression的deterministic属性
在sql语句中,除了select、from等关键字以外,其他大部分元素都可以理解为expression,比如:
select a,b from testdata2 where a>2这里的 a,b,>,2都是expression
Expression的deterministic属性
Expression类中有个基本属性deterministic:

这个属性是用来标记表达式是否为确定性的,即每次执行eval函数的输出是否都相同。如果在固定输入值的情况下返回值相同,该标记为true;如果在固定输入值的情况下返回值是不确定的,则说明该expression是不确定的,deterministic参数应该为false。
这个是啥意思呢?
举个例子:
select a,b from testdata2 where a>2 and rand()>0.1上面的代码中,rand表达式就是不确定的(因为对于一个固定的输入值的查询,rand得出的结果是随机的),其它不确定的还有 randn,SparkPartitionID等表达式。
这个属性有啥用呢?
该属性对于算子树优化中判断谓词能否下推等很有必要,举个例子:
确定的表达式在谓词下推优化中的表现
select a,b from (select a,b from testdata2 where a>2) tmp where b>3
优化前LogicalPlan:

优化后LogicalPlan:

上面a>2 和b>3 中,a和b都是确定的,因此可以合并下推。
不确定的表达式在谓词下推优化中的表现
select a,b from (select a,b from testdata2 where a>2 ) tmp where rand()>0.1
优化前LogicalPlan:
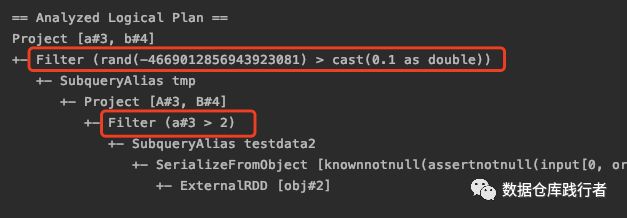
优化后LogicalPlan:

由于rand是非确定性的,因此不能做下推优化。
这个属性是怎么赋值的呢?
Expression默认是确定性的
lazy val deterministic: Boolean = children.forall(_.deterministic)
一个叶子节点的 expressions 的deterministic属性默认是true(叶子节点没有children,因此children.forall(_.deterministic) 即Nil.forall(_.deterministic) 返回true),即默认是确定性的。
Nondeterministic不确定性接口
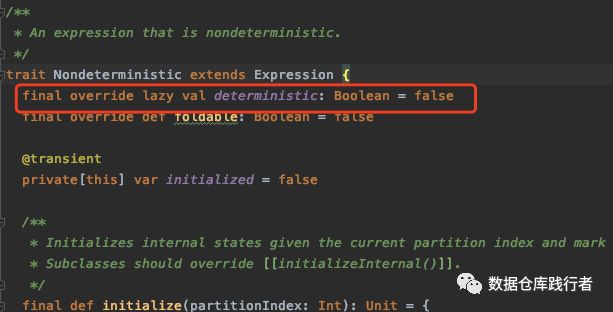
Nondeterministic是个不确实性表达式的接口,Nondeterministic继承Expression,重写deterministic属性,默认给false。
非确定性的表达式rand,SparkPartitionID 都会直接或者间接的继承Nondeterministic,从而继承Nondeterministic的deterministic为false的属性
自定义函数表达式
自定义函数时,比如udaf函数,需要继承 UserDefinedAggregateFunction:

重写deterministic函数,标记自己开发的函数表达式是确定性的还是非确定性的。
Hey!
我是小萝卜算子
在成为最厉害最厉害最厉害的道路上
很高兴认识你
推荐阅读:
json_tuple一定比 get_json_object更高效吗?
with as 语句真的会把查询的数据存内存嘛?
SparkSql LogicalPlan的resolved变量
Spark sql 生成PhysicalPlan(源码详解)
一文搞懂 Maven 原理
AstBuilder.visitTableName详解
从一个sql任务理解spark内存模型
Spark sql规则执行器RuleExecutor(源码解析)
spark sql解析过程中对tree的遍历(源码详解)
一文搞定Kerberos
哈哈,露个脸
你真的了解Lateral View explode吗?--源码复盘