MySQL-1(12000字详解)
一:数据库的引入
数据库在我们以后工作中是一个非常常用的知识,数据库用来存储数据,但是有些同学可能就会疑惑了,存储数据用文件就可以了,为什么还要弄个数据库呢?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
数据库存储介质:
- 磁盘
- 内存
为了解决上述问题,专家们设计出更加利于管理数据的软件——数据库,它能更有效的管理数据。数据库可以提供远程服务,即通过远程连接来使用数据库,因此也称为数据库服务器。
数据可以存储在内存和外存两种介质中。这两种存储介质在性能、容量和可靠性等方面有着不同的特点和限制。
-
内存存储(主存):
- 特点:内存是计算机的主要工作区域,数据可以被快速读取和写入。它是临时存储数据的地方,当计算机关机或断电时,内存中的数据将丢失。
- 优点:内存的读写速度非常快,可以迅速访问和操作数据。
- 缺点:内存的容量较小,一般为几十GB至几百GB,因此无法长期存储大量的数据。此外,内存中的数据在断电或重新启动后会丢失。
-
外存存储(辅助存储):
- 特点:外存储器通常是硬盘、固态硬盘(SSD)或网络存储等,它们用于长期存储数据。外存的读写速度相对较慢。
- 优点:外存储器的容量通常较大,可以存储大量的数据并且数据不会因为断电而丢失。
- 缺点:相对于内存来说,外存储器的读写速度较慢,读写数据需要一定的时间。
二:如何启动MySQL数据库
1:首先我们打开运行

接着搜索services.msc
找到MySQL,并右键启动

接着打开cmd
输入命令:
mysql -u root -p
注意:没有分号
接着输入密码
这就成功开启了
接着就可以使用了
三:数据库基础
3.1 数据库操作
3.1.1显示所有数据库
我们可以在cmd中通过
- show databases;
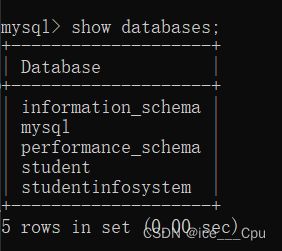
这个,命令来显示mysql中所有的数据库(是有s的),如图所示:
注意:"5 rows in set"是指查询结果集中有5行数据。"0.01 sec"表示查询所花费的时间,以秒为单位。这个信息告诉你查询返回了5行数据,并且查询的执行时间是0.01秒。
通过这个命令我们就可以知道我们目前有5个库,其中information_schema、mysql和performance_schema是MySQL本身就存在的三个库。它们是系统默认创建的,用于存储和管理数据库的元数据信息、权限信息和性能统计数据。
student和studentinfosystem是我自己创建的数据库,不是MySQL系统默认存在的。
3.2创建一个数据库
在cmd中,我们可以通过这个命令创建一个mysql数据库:
- create database 数据库名;
注意:mysql是不区分大小写的,所以:
- CREATE DATABASE 数据库名;
这个命令也可以使用
数据库的命名和java变量命名一样,但是如果你就是非要用关键字作为数据库的名字,那么你可以用反引号把数据库名字引起来
并且创建数据库的时候,不能和已有的数据库名字重复
使用结果如图所示:

接着我们再显示一下数据库,查看一下现存的数据库有哪些:

可以看出我们已经成功创建了一个ice数据库
下面还有其他形式的创建方式:
1:如果系统没有 db_test2 的数据库,则创建一个名叫 db_test2 的数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS db_test2;
2:如果系统没有 db_test 的数据库,则创建一个使用utf8mb4字符集的 db_test 数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS db_test CHARACTER SET utf8mb4;
我们可以把 character set 合并为 charset
对于不同的字符集,表示一个汉字所需要的字节数一般不同,比如在GBK下,一个汉字的表示需要2个字节,二在UTF8下,一个字节的表示需要3个字节,如果不指定字符集的话,会使用默认的字符集(拉丁文),很可能插入中文失败,我们一般使用UTF8字符集
3.3选中数据库
既然我们现在已经会创建了数据库了,那么我们该如何去使用一个数据库呢?
在cmd中,我们通过这个命令来选中数据库:
- use 数据库名;
在mysql数据库中,要想对这个数据库进行操作,你需要先选中这个数据库,选中这个数据库后,才能进行后续的操作
我们可以通过这个命令来选中不同的数据库,如图所示:
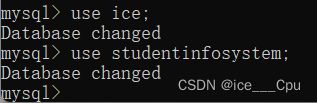
在MySQL中,当你切换到一个不同的数据库时,会显示"Database changed"的提示。这意味着你已经成功切换到了指定的数据库,可以开始执行与该数据库相关的操作了。
3.4 删除数据库
在mysql中,如果我们对已经不需要的数据库进行删除,那么我们该如何删除这个数据库呢?在mysql中,我们通过这个命令删除数据库:
- drop database 数据库名;
如图所示:
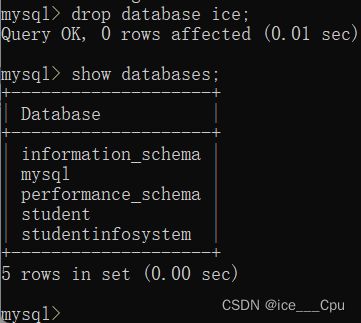
注意:删库的操作是非常危险的,请谨慎使用,
3.2 mysql常用数据类型:
因为SQL比java更古老一点,所以有些类型可能会没有存在的必要
3.2.1 数值类型:
分为整型和浮点型:
| 数据类型 | 大小 | 对应java类型 |
|---|---|---|
| BIT[ (M) ] | M指定位数,默认为1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte |
| SMALLINT | 2字节 | Short |
| INT | 4字节 | Integer |
| BIGINT | 8字节 | Long |
| FLOAT(M, D) | 4字节 | Float |
| DOUBLE(M,D) | 8字节 | Double |
| DECIMAL(M,D) | M/D最大值+2 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | BigDecimal |
在java中,float和double存储浮点数会存在误差,decimal采用类似于字符串的存储方式保存,所以decimal对于浮点数的存储没有误差,但是decimal存储空间大,计算速度慢
对于上述的数值类型我们可以指定为无符号类型,但是不建议使用,无符号类型有很大的缺陷
在 MySQL 中,DECIMAL(M,D) 和 NUMERIC(M,D) 是用于存储固定精度的十进制数的数据类型。它们在定义上是相同的,具有相同的用途和行为。
这里是它们的异同:
-
别名:DECIMAL 和 NUMERIC 是互相可替代的别名。MySQL 允许使用它们来表示相同的数据类型。
-
M 和 D 的含义:在 DECIMAL(M,D) 和 NUMERIC(M,D) 中,M 和 D 分别表示总位数(即精度)和小数位数(即标度)。
- 总位数(M):表示该数字可以包含的总位数(包括整数和小数位)。
- 小数位数(D):表示该数字可以包含的小数位数。
举例来说,DECIMAL(5,2) 可以存储最大为 5 位数的数字,其中有 2 位为小数位。例如,123.45 就可以存储在 DECIMAL(5,2) 数据类型中。
- 存储空间:DECIMAL 和 NUMERIC 的存储空间取决于指定的 M 和 D 值。它们的存储是根据需要动态调整的,以适应存储在列中的实际数据。
DECIMAL(M,D) 和 NUMERIC(M,D) 本质上是相同的,都用于存储固定精度的十进制数。它们的区别仅在于名称。
3.2.2 字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| VARCHAR (SIZE) | 0-65,535 | 可变长度字符串 | String |
| TEXT | 0-65,535 | 长文本数据 | String |
| MEDIUMTEXT | 0-16 777 215 | 中等长度文本数据 | String |
| BLOB | 0-65,535 | 二进制形式的长文本数据 | byte[] |
varchar中的size指定的是最大长度,单位是字符
eg:varchar(10)表示最大存储10个字,并且这种存储是动态存储的
3.2.3 日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| DATETIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换。 | java.util.Date、java.sql.Timestamp |
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换。 | java.util.Date、java.sql.Timestamp |
时间戳:以1970年1月1日0时0分为基础,计算当前时刻和基准时候的 秒数/毫秒 之差
3.3 表的操作
在学习表的操作之前,我们需要了解一下什么是表,简单来说,就是表存在于数据库中,数据库中有多个表,这些表之间相互独立且彼此隔离。
可以用一个简单的图来示例它们之间的关系:
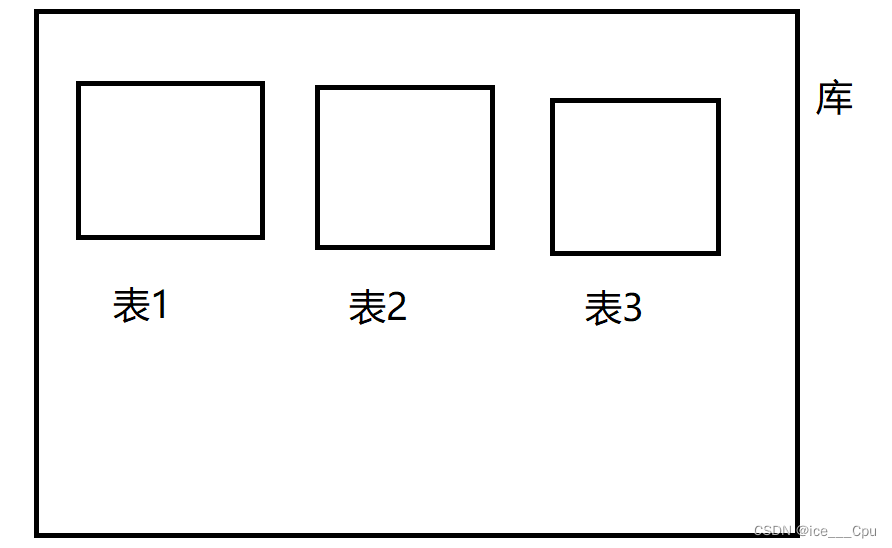
在对表进行任何操作前,都要先选中这个表所在的数据库
3.3.1 描述表
在mysql中,我们可以通过这个命令来查看表的结构:
- desc 表名;
如图所示:

3.3.2 创建表
在mysql中,我们通过这个命令来创建一个表:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
);
下面通过一个示例讲解:
create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2),
resume text
);
在mysql中,使用 comment关键字来添加注释,注释的内容需要用单引号引起来,并且comment只能在创建表的时候使用,我们还可以在SQL中使用“- -空格+描述”来表示注释说明,我们更推荐用 - -空格作为注释
下面我再来讲解一下上面的命令:
这是一个在 MySQL 数据库中创建名为 “stu_test” 的表的示例代码。
-
id int: 这是一个整数型字段,用于存储学生的 ID。 -
name varchar(20) comment '姓名': 这是一个最大长度为 20 的字符串型字段,用于存储学生的姓名。注释 ‘姓名’ 是对该字段的描述。 -
password varchar(50) comment '密码': 这是一个最大长度为 50 的字符串型字段,用于存储学生的密码。注释 ‘密码’ 是对该字段的描述。 -
age int: 这是一个整数型字段,用于存储学生的年龄。 -
sex varchar(1): 这是一个最大长度为 1 的字符串型字段,用于存储学生的性别。 -
birthday timestamp: 这是一个日期时间型字段,用于存储学生的生日。它的数据类型为 TIMESTAMP,可以存储日期和时间。 -
amout decimal(13,2): 这是一个数字型字段,用于存储学生的金额。它的数据类型为 DECIMAL(13,2),表示可以存储最大 13 位数,其中 2 位为小数部分。 -
resume text: 这是一个文本型字段,用于存储学生的简历。它的数据类型为 TEXT,可以存储较大的文本数据。
通过这个示例代码,我们可以在 MySQL 数据库中创建一个名为 “stu_test” 的表,并定义包含上述字段的表结构。
下面是对这个表的描述:
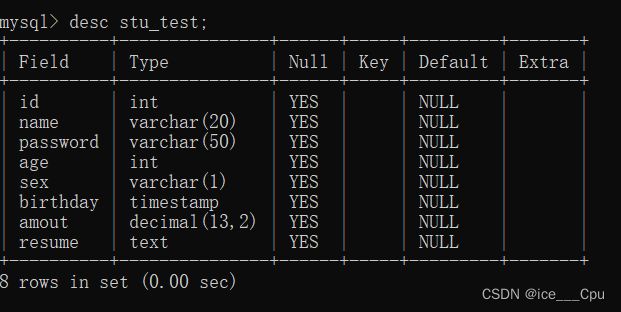
3.3.3显示所有表
我们如果要先查看一个数据库中有哪些表的话,我们可以使用这个命令进行查看:
- SHOW TABLES;
如图所示:
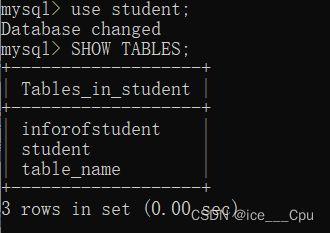
3.3.4 删除表
对于一个表的删除,我们可以使用下面的这个命令
-- 删除 stu_test 表
drop table stu_test;
-- 如果存在 stu_test 表,则删除 stu_test 表
drop table if exists stu_test;
请注意,删表和删库的操作都是很危险的,删除操作是不可逆的,所以在执行该命令之前,要确保你真的想要删除该表
3.4 表的增删查改(CRUD)
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写。
3.4.1 增加表中的数据
首先我们先创建一个表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT,
sn INT comment '学号',
name VARCHAR(20) comment '姓名',
qq_mail VARCHAR(20) comment 'QQ邮箱'
);
接着我们就可以在这个表中增加数据了:
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');
这是两个 MySQL 的 单行数据全列插入语句,用于向名为 student 的表中插入数据。每个 INSERT 语句插入了一行数据。
第一个 INSERT 语句插入了以下数据:
- 学生编号: 100
- 学生学号: 10000
- 学生姓名: 唐三藏
- 学生密码: NULL(空值)
第二个 INSERT 语句插入了以下数据:
- 学生编号: 101
- 学生学号: 10001
- 学生姓名: 孙悟空
- 学生密码: ‘11111’
当然,我们还可以把这两个语句合并成一个语句:
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL), (101, 10001, '孙悟空', '11111');
这就是多行数据 + 全列插入
我们可以将 insert into 合并为 into
这样就将两条 SQL 插入语句合并为一条使用,这样我们就同时把这两个数据新增到student这个表中了,对于一次新增n个数据和n次,一次新增一个数据来说,一次新增n个数据的效率会更高
3.4.1.1 多行数据 + 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
这条插入语句的意思是往 student 表中插入两条记录,分别是 id: 102, sn: 20001, name: ‘曹孟德’,以及 id: 103, sn: 20002, name: ‘孙仲谋’。
我们还可以只指定 id 和 name两列进行插入
3.4.2 在表中查询数据
首先我们创建一个表,并在表中新增一些数据:
-- 创建考试成绩表
DROP TABLE IF EXISTS exam_result;
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
3.4.2.1 全列查询
-- 通常情况下不建议使用 * 进行全列查询,因为
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。(索引待后面课程讲解)
SELECT * FROM exam_result;
SELECT * FROM exam_result; 是一条 SQL 查询语句,用于从 exam_result 表中检索所有的数据记录。* 是通配符,表示选择所有的列。而 FROM exam_result 表示从名为 exam_result 的表中进行数据检索。
如图所示:

3.4.2.2 指定列查询
-- 指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam_result;
通过这个命令,我们就可以看想要看见的列
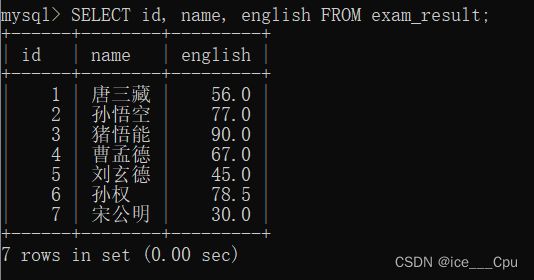
3.4.2.3查询字段为表达式
下面是示例语句
-- 表达式不包含字段
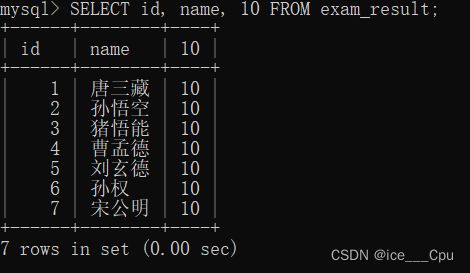
SELECT id, name, 10 FROM exam_result;
-- 表达式包含一个字段
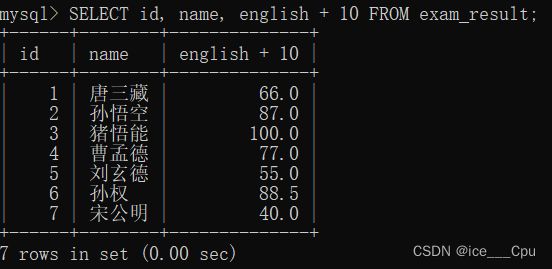
SELECT id, name, english + 10 FROM exam_result;
-- 表达式包含多个字段
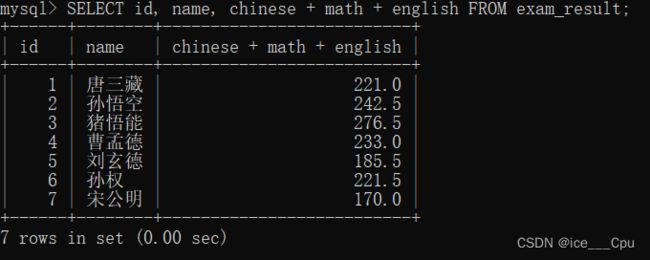
SELECT id, name, chinese + math + english FROM exam_result;
下面我们对这三个语句进行解释:
- SELECT id, name, 10 FROM exam_result;
这是一个简单的 SQL 查询语句,用于从 exam_result 表中选择 id、name 和 10 这三个列的数据。这个查询会返回 exam_result 表中每一行的 id 和 name 列的值,并且 10 这个常量值会被作为第三列返回,因为在查询中没有指定该列的别名。
如图所示:
- SELECT id, name, english + 10 FROM exam_result;
这个 SQL 查询语句是用来从 exam_result 表中选择 id、name 和 english 列的值,并且对 english 列的值加上 10。
换句话说,这个查询将返回 id、name 和 english 列的值,而 english 列的值将在原有值的基础上增加 10。注意,english中的数据并没有发生改变
如图所示:
- SELECT id, name, chinese + math + english FROM exam_result;
这个 SQL 查询语句的意思是从 exam_result 表中选择 id、name 和 chinese + math + english 的总分,并显示在结果集中。通常情况下,语句中的 + 符号用于执行数值的加法操作,所以它将会对 chinese、math 和 english 列的值进行相加,然后将结果作为一个新的列显示在结果集中。
如图所示:
3.4.2.4 别名
在mysql中,我们可以对字段进行重命名,在mysql中也叫别名,字段是,下面是一个示例语句:
字段 as 别名
这是别名的的一般形式,将字段重命名为别名
SELECT id, name, chinese + math + english AS 总分 FROM exam_result;
-- as可以省略,所以也可以写成
SELECT id, name, chinese + math + english 总分 FROM exam_result;
虽然as可以省略,但是并不建议省略as,因为省略了as,语句的可读性会差一点,
这两个个 SQL 查询语句是从 “exam_result” 表中选择 “id”、“name” 和 "chinese + math + english " 列,并给 “chinese + math + english” 列的总和起了一个别名 “总分”。
它的作用是获取"exam_result"表中每个学生的id、name和语文、数学和英语成绩的总和。结果集将包含这三个列,并在最后还会包含一个名为 “总分” 的列,显示每个学生的三科成绩总和。
如图所示:

如果你需要再对id重命名的话,你可以:
SELECT id AS aftid, name, chinese + math + english AS 总分
FROM exam_result;
3.4.2.5 去重
在mysql中,我们使用DISTINCT(distinct)关键字对某列数据进行去重,示例语句如下:
SELECT DISTINCT math FROM exam_result;
这个 SQL 查询语句的意思是从 “exam_result” 表中选择不重复的数学成绩(“math” 列)。它会返回该列中所有不重复的数学成绩值。
注意:distinct保留第一个出现的值,去除掉第一个重复出现的值
3.4.2.6 排序
在mysql中,我们通过ORDER BY进行排序(采用的是并归排序),下面是示例语句:
-- 查询同学姓名和 qq_mail,按 qq_mail 排序显示
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT name, qq_mail FROM student ORDER BY qq_mail;
SELECT name, qq_mail FROM student ORDER BY qq_mail DESC;
通过这两个查询语句,我们可以获取 “student” 表中 “name” 和 “qq_mail” 列的数据,并按照 “qq_mail” 列的升序或降序进行排序。
注意:NULL 数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面
我们还可以使用表达式及别名排序:
-- 查询同学及总分,由高到低
SELECT name, chinese + english + math FROM exam_result ORDER BY chinese + english + math DESC;
-- 等价于
SELECT name, chinese + english + math as total FROM exam_result ORDER BY total DESC;
我们还可以对多个字段进行排序,排序优先级随书写顺序:
-- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, english, chinese;
如果math的值相同了,那么再按照英语的排序规则(升序还是降序)再根据值进行排序,如果英语的值也一样,那么按照语文的值再进行比较
3.4.2.7 条件查询
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
下面说说like的使用方法:
-
匹配开头和结尾的模式:
- 查找以"abc"开头的记录:
SELECT * FROM 表名 WHERE 列名 LIKE 'abc%' - 查找以"xyz"结尾的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '%xyz'
- 查找以"abc"开头的记录:
-
匹配任意单个字符的模式:
- 查找第一个字母为任意字符,第二个字母为"o"的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '_o%'
- 查找第一个字母为任意字符,第二个字母为"o"的记录:
-
匹配多个字符的模式:
- 查找包含"def"的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '%def%' - 查找以"a"开头,且长度为4个字符的记录:
SELECT * FROM 表名 WHERE 列名 LIKE 'a___'
- 查找包含"def"的记录:
-
匹配特定字符集的模式:
- 查找以"a"、“b” 或 “c” 开头的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '[abc]%' - 查找以"a"、“b” 或 “c” 结尾的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '%[abc]'
- 查找以"a"、“b” 或 “c” 开头的记录:
-
使用转义字符的模式:
- 查找以"%“或”_"字符开头的记录:
SELECT * FROM 表名 WHERE 列名 LIKE '\%%' ESCAPE '\\'
- 查找以"%“或”_"字符开头的记录:
总结:
- %:代表0个或者n个字符
- _ :代表任意1个字符
请注意,LIKE运算符是区分大小写的,如果需要进行不区分大小写的匹配,可以使用LOWER()或UPPER()函数将查询条件和列值转换为小写或大写。
下面是关于比较运算符一些要注意的地方:
- null和其他数值进行运算,结果还是null
- null结果在条件中的话,那就相当于false了
比如null == null 的结果还是null 而不是true
条件运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
我们通过where子句和条件表达式,就可以完成条件查询了,eg:
select * from eaxm_result where english < 60;
通过这个我们就可以查询到在eaxm_result这个表中,英语分数小于60的记录了。
注意:
- WHERE条件可以使用表达式,但不能使用别名。
- AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
以下是一些搭配where和条件表达式使用的语句:
-- 查询英语不及格的同学及英语成绩 ( < 60 )
SELECT name, english FROM exam_result WHERE english < 60;
-- 查询语文成绩好于英语成绩的同学
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
-- 查询总分在 200 分以下的同学
SELECT name, chinese + math + english 总分 FROM exam_result WHERE chinese + math + english < 200;
-- 查询语文成绩大于80分,且英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 and english > 80;
-- 查询语文成绩大于80分,或英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 or english > 80;
-- 注意加括号,and的优先级比or高
SELECT * FROM exam_result WHERE (chinese > 80 or math>70) and english > 70;
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
-- 使用 AND 也可以实现
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
-- 使用 OR 也可以实现
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99;
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
-- 查询 qq_mail 已知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL;
-- 查询 qq_mail 未知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NULL;
3.4.2.8 分页查询
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
案例:按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 6;
3.4.3 修改表中的数据
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
案例:
-- 将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
在修改中,如果不写where条件,那么修改就是针对所有行进行的
3.4.4 删除表中的数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
案例:
-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
注意:在mysql中,如果delete后面不跟where,也没有limit,那么删除的是整张表的数据,这和删表无异,表中的数据都没了,只不过这张表还在而已
四:重点内容总结
新增:
-- 单行插入
insert into 表(字段1, ..., 字段N) values (value1, ..., value N);
-- 多行插入
insert into 表(字段1, ..., 字段N) values
(value1, ...),
(value2, ...),
(value3, ...);
查询:
-- 全列查询
select * from 表
-- 指定列查询
select 字段1,字段2... from 表
-- 查询表达式字段
select 字段1+100,字段2+字段3 from 表
-- 别名
select 字段1 别名1, 字段2 别名2 from 表
-- 去重DISTINCT
select distinct 字段 from 表
-- 排序ORDER BY
select * from 表 order by 排序字段
-- 条件查询WHERE:
-- (1)比较运算符 (2)BETWEEN ... AND ... (3)IN (4)IS NULL (5)LIKE (6)AND (7)OR (8)NOT
select * from 表 where 条件
修改:
update 表 set 字段1=value1, 字段2=value2... where 条件
删除:
delete from 表 where 条件