Java:Nginx使用
目录
- 一、nginx目录结构
- 二、nginx常用的命令
- 三、nginx配置文件
-
- 第一部分:全局块
- 第二部分:events块
- 第三部分:http块
-
- (1) http全局块
- (2) server 块
-
- (1) location指令说明
- 四、Nginx配置实例-负载均衡
-
- 实现效果
- 准备工作
- 在nginx的配置文件中进行负载均衡的配置
- nginx分配服务器策略
-
- 轮询(默认)
- weight
- ip_hash
- fair(第三方)
- 其他参数
- 五、Nginx.conf配置详解
-
- gzip模块相关
一、nginx目录结构
- conf
- html
- logs
- sbin
二、nginx常用的命令
(1)启动命令
在/usr/local/nginx/sbin目录下执行 ./nginx
(2)关闭命令
在/usr/local/nginx/sbin目录下执行 ./nginx -s stop
(3)重新加载命令
在/usr/local/nginx/sbin目录下执行 ./nginx -s reload
三、nginx配置文件
(1)路径
/usr/local/nginx/conf/nginx.conf
(2)文件内容:(去掉所有以 # 开头注释内容)
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80; # nginx的端口
server_name localhost; # 服务名
location / { # 当前路径(项目根目录)
root html; # root根目录 指向 html目录
index index.html index.htm; # html文件夹下具体的文件名
# proxy_pass http://127.0.0.1:8080; # 当前路径进行代理,指向proxy_pass的网址
}
error_page 500 502 503 504 /50x.html; #
location = /50x.html {
root html;
}
}
}
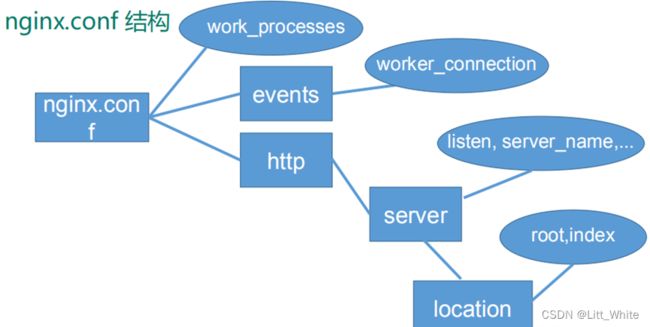
根据上述文件,我们可以很明显的将 nginx.conf 配置文件分为三部分:
第一部分:全局块
范围:从配置文件开始到 events 块之间的内容。
作用:主要会设置一些影响nginx 服务器整体运行的配置指令。
例如:配置运行 Nginx 服务器的用户(组)、允许生成的 worker process 数,进程 PID 存放路径、日志存放路径和类型以及配置文件的引入等
例如,第一行配置的
worker_processes 1;
这是 Nginx 服务器并发处理服务的关键配置,worker_processes 值越大,可以支持的并发处理量也越多,但是会受到硬件、软件等设备的制约。
第二部分:events块
范围:events代码块内里的内容。
作用:主要影响 Nginx 服务器与用户的网络连接。
例如:是否开启对多 work process 下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 work process 可以同时支持的最大连接数等。
例如,
worker_connections 1024;。表示:每个 worker_processes支持的最大连接数为 1024.
第三部分:http块
范围:http代码块内里的内容。
作用:代理、缓存和日志定义等绝大多数功能和第三方模块的配置都在这里。
注意:http 块也可以包括 http全局块、server 块。
(1) http全局块
http全局块配置的指令包括:文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。
(2) server 块
1、这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的,该技术的产生是为了节省互联网服务器硬件成本。
2、每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
3、而每个 server 块也分为全局 server 块,以及可以同时包含多个location 块。
- 全局 server 块
最常见的配置是本虚拟机主机的监听配置和本虚拟主机的名称或IP配置。- location 块
一个 server 块可以配置多个 location 块。
这块(server 块)的主要作用是基于 Nginx 服务器接收到的请求字符串
(例如 server_name/uri-string),对虚拟主机名称(也可以是IP别名)之外的字符串(例如 前面的 /uri-string)进行匹配,对特定的请求进行处理。地址定向、数据缓存和应答控制等功能,还有许多第三方模块的配置也在这里进行。
(1) location指令说明
该指令用于匹配 URL。
注意:
- location /directory/ {}
/directory/,directory是文件夹名,后面带“/”,是指匹配的是directory目录下的所有文件- location /file.html {}
file.html,后面不带“/”,是指匹配具体的文件
语法如下:
1、= :用于不含正则表达式的 uri 前,要求请求字符串与 uri 严格匹配,如果匹配成功,就停止继续向下搜索并立即处理该请求。
2、~:用于表示 uri 包含正则表达式,并且区分大小写。
3、~*:用于表示 uri 包含正则表达式,并且不区分大小写。
4、^~:用于不含正则表达式的 uri 前,要求 Nginx 服务器找到标识 uri 和请求字符串匹配度最高的 location 后,立即使用此 location 处理请求,而不再使用 location 块中的正则 uri 的请求字符串做匹配。
5、/:普通的url路径注意:
1、如果 uri 包含正则表达式,则必须要有 ~ 或者 ~* 标识。
2、优先级:=>^~>~和~*>/
Demo案例
Location区段匹配示例
location = / { //精确匹配,优先级最高
# 只匹配 / 的查询.
[ configuration A ]
}
location / { //普通匹配,优先级低
# 匹配任何以 / 开始的查询,但是正则表达式与一些较长的字符串将被首先匹配。
[ configuration B ]
}
location ^~ /images/ { //反正则,优先于正则匹配
# 匹配任何以 /images/ 开始的查询并且停止搜索,不检查正则表达式。
[ configuration C ]
}
location ~* \.(gif|jpg|jpeg)$ { // ~*正则匹配,不区分大小写,优先级高于普通匹配
# 匹配任何以gif, jpg, or jpeg结尾的文件,但是所有 /images/ 目录的请求将在Configuration C中处
理。
[ configuration D ]
}
各请求的处理如下例:
http://192.168.140.110:9000/ ---------------- A
http://192.168.140.110:9000/documents/document.html ---------------- B
http://192.168.140.110:9000/images/1.gif ---------------- C
http://192.168.140.110:9000/documents/1.jpg ---------------- D
四、Nginx配置实例-负载均衡
实现效果
浏览器地址栏输入地址 http://192.168.6.100/edu/index.html,负载均衡效果,将请求平均分配到8080和8081两台服务器上。
准备工作
(1)准备两台tomcat服务器,一台8080,一台8081
(2)在两台tomcat里面webapps目录中,创建名称是edu文件夹,在edu文件夹中创建页面index.html(让index.html内容不一样,查看效果),用于测试
在nginx的配置文件中进行负载均衡的配置
upstream称为上游服务器,即真实处理请求的业务服务器。

nginx分配服务器策略
随着互联网信息的爆炸性增长,负载均衡(load balance)已经不再是一个很陌生的话题,顾名思义,负载均衡即是将负载分摊到不同的服务单元,既保证服务的可用性,又保证响应足够快,给用户很好的体验。
轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
weight
weight代表权重,默认为1,权重越高被分配的客户端越多
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 例如:
upstream server_pool{
server 192.168.5.21 weight=1;
server 192.168.5.22 weight=2;
server 192.168.5.23 weight=3;
}
ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。例如:
upstream server_pool{
ip_hash;
server 192.168.5.21:80;
server 192.168.5.22:80;
}
fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。例如:
upstream server_pool{
server 192.168.5.21:80;
server 192.168.5.22:80;
fair;
}
其他参数

五、Nginx.conf配置详解
#安全问题,建议用nobody,不要用root.
#user nobody;
#worker数和服务器的cpu数相等是最为适宜
worker_processes 2;
#work绑定cpu(4 work绑定4cpu)
worker_cpu_affinity 0001 0010 0100 1000
#work绑定cpu (4 work绑定8cpu中的4个) 。
worker_cpu_affinity 0000001 00000010 00000100 00001000
#error_log path(存放路径) level(日志等级) path表示日志路径,level表示日志等级,
#具体如下:[ debug | info | notice | warn | error | crit ]
#从左至右,日志详细程度逐级递减,即debug最详细,crit最少,默认为crit。
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
#这个值是表示每个worker进程所能建立连接的最大值,所以,一个nginx能建立的最大连接数,应该是worker_connections * worker_processes。
#当然,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections * worker_processes,
#如果是支持http1.1的浏览器每次访问要占两个连接,
#所以普通的静态访问最大并发数是: worker_connections * worker_processes /2,
#而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/4。
#因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
worker_connections 1024;
#这个值是表示nginx要支持哪种多路io复用。
#一般的Linux选择epoll, 如果是(*BSD)系列的Linux使用kquene。
#windows版本的nginx不支持多路IO复用,这个值不用配。
use epoll;
# 当一个worker抢占到一个链接时,是否尽可能的让其获得更多的连接,默认是off 。
multi_accept on; //并发量大时缓解客户端等待时间。
# 默认是on ,开启nginx的抢占锁机制。
accept_mutex off; //master指派worker抢占锁
}
http {
#当web服务器收到静态的资源文件请求时,依据请求文件的后缀名在服务器的MIME配置文件中找到对应的MIME Type,再根据MIME Type设置HTTP Response的Content-Type,然后浏览器根据Content-Type的值处理文件。
include mime.types; #/usr/local/nginx/conf/mime.types
#如果 不能从mime.types找到映射的话,用以下作为默认值-二进制
default_type application/octet-stream;
#日志位置
access_log logs/host.access.log main;
#一条典型的accesslog:
#101.226.166.254 - - [21/Oct/2013:20:34:28 +0800] "GET /movie_cat.php?year=2013 HTTP/1.1" 200 5209 "http://www.baidu.com" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MDDR; .NET4.0C; .NET4.0E; .NET CLR 1.1.4322; Tablet PC 2.0); 360Spider"
#1)101.226.166.254:(用户IP)
#2)[21/Oct/2013:20:34:28 +0800]:(访问时间)
#3)GET:http请求方式,有GET和POST两种
#4)/movie_cat.php?year=2013:当前访问的网页是动态网页,movie_cat.php即请求的后台接口,year=2013为具体接口的参数
#5)200:服务状态,200表示正常,常见的还有,301永久重定向、4XX表示请求出错、5XX服务器内部错误
#6)5209:传送字节数为5209,单位为byte
#7)"http://www.baidu.com":refer:即当前页面的上一个网页
#8)"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; #.NET CLR 3.0.30729; Media Center PC 6.0; MDDR; .NET4.0C; .NET4.0E; .NET CLR 1.1.4322; Tablet PC 2.0); 360Spider": agent字段:通常用来记录操作系统、浏览器版本、浏览器内核等信息
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#开启从磁盘直接到网络的文件传输,适用于有大文件上传下载的情况,提高IO效率。
sendfile on; //大文件传递优化,提高效率
#一个请求完成之后还要保持连接多久, 默认为0,表示完成请求后直接关闭连接。
#keepalive_timeout 0;
keepalive_timeout 65;
#开启或者关闭gzip模块
#gzip on ; //文件压缩,再传输,提高效率
#设置允许压缩的页面最小字节数,页面字节数从header头中的Content-Length中进行获取。
#gzip_min_lenth 1k;//超过该大小开始压缩,否则不用压缩
# gzip压缩比,1 压缩比最小处理速度最快,9 压缩比最大但处理最慢(传输快但比较消耗cpu)
#gzip_comp_level 4;
#匹配MIME类型进行压缩,(无论是否指定)"text/html"类型总是会被压缩的。
#gzip_types types text/plain text/css application/json application/x-javascript text/xml
#动静分离
#服务器端静态资源缓存,最大缓存到内存中的文件,不活跃期限
open_file_cache max=655350 inactive=20s;
#活跃期限内最少使用的次数,否则视为不活跃。
open_file_cache_min_uses 2;
#验证缓存是否活跃的时间间隔
open_file_cache_valid 30s;
upstream myserver{
# 1、轮询(默认)
# 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
# 2、指定权重
# 指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
#3、IP绑定 ip_hash
# 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
#4、备机方式 backup
# 正常情况不访问设定为backup的备机,只有当所有非备机全都宕机的情况下,服务才会进备机。当非备机启动后,自动切换到非备机
# ip_hash;
server 192.168.161.132:8080 weight=1;
server 192.168.161.132:8081 weight=1 backup;
#5、fair(第三方)公平,需要安装插件才能用
#按后端服务器的响应时间来分配请求,响应时间短的优先分配。
#6、url_hash(第三方)
#按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
# ip_hash;
server 192.168.161.132:8080 weight=1;
server 192.168.161.132:8081 weight=1;
#fair
#hash $request_uri
#hash_method crc32
}
server {
#监听端口号
listen 80;
#服务名
server_name 192.168.161.130;
#字符集
#charset utf-8;
#location [=|~|~*|^~] /uri/ { … }
# = 精确匹配
# ~ 正则匹配,区分大小写
# ~* 正则匹配,不区分大小写
# ^~ 关闭正则匹配
#匹配原则:
# 1、所有匹配分两个阶段,第一个叫普通匹配,第二个叫正则匹配。
# 2、普通匹配,首先通过“=”来匹配完全精确的location
# 2.1、 如果没有精确匹配到, 那么按照最大前缀匹配的原则,来匹配location
# 2.2、 如果匹配到的location有^~,则以此location为匹配最终结果,如果没有那么会把匹配的结果暂存,继续进行正则匹配。
# 3、正则匹配,依次从上到下匹配前缀是~或~*的location, 一旦匹配成功一次,则立刻以此location为准,不再向下继续进行正则匹配。
# 4、如果正则匹配都不成功,则继续使用之前暂存的普通匹配成功的location.
#不是以波浪线开头的都是普通匹配。
location / { # 匹配任何查询,因为所有请求都以 / 开头。但是正则表达式规则和长的块规则将被优先和查询匹配。
#定义服务器的默认网站根目录位置
root html;//相对路径,省略了./ /user/local/nginx/html 路径
#默认访问首页索引文件的名称
index index.html index.htm;
#反向代理路径
proxy_pass http://myserver;
#反向代理的超时时间
proxy_connect_timeout 10;
proxy_redirect default;
}
#普通匹配
location /images/ {
root images ;
}
# 反正则匹配
location ^~ /images/jpg/ { # 匹配任何以 /images/jpg/ 开头的任何查询并且停止搜索。任何正则表达式将不会被测试。
root images/jpg/ ;
}
#正则匹配
location ~*.(gif|jpg|jpeg)$ {
#所有静态文件直接读取硬盘
root pic ;
#expires定义用户浏览器缓存的时间为3天,如果静态页面不常更新,可以设置更长,这样可以节省带宽和缓解服务器的压力
expires 3d; #缓存3天
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
gzip模块相关
http {
#开启或者关闭gzip模块
#gzip on ; //文件压缩,再传输,提高效率
#设置允许压缩的页面最小字节数,页面字节数从header头中的Content-Length中进行获取。
# gzip_min_lenth 1k;//超过该大小开始压缩,否则不用压缩
# gzip压缩比,1 压缩比最小处理速度最快,9 压缩比最大但处理最慢(传输快但比较消耗cpu)
#gzip_comp_level 4;
#匹配MIME类型进行压缩,(无论是否指定)"text/html"类型总是会被压缩的。
#gzip_types types text/plain text/css application/json application/x-javascript text/xml
}