大数据——Spark Streaming中的Window(窗口)操作和Spark Streaming结合SparkSQL
Spark Streaming中的Window(窗口)操作
- 窗口函数
-
- Window(windowLength, slideInterval)
- countByWindow(windowLength,slideInterval)
- countByValueAndWindow(windowLength,slideInterval, [numTasks])
- reduceByWindow(func, windowLength,slideInterval)
- reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
- reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
- transform
- SparkStreaming结合SparkSQL结合使用
窗口函数
窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个可配置的速率向前移动窗口,根据窗口函数的具体内容,分别对当前窗口中的这一波数据采取某个对应的操作算子。
需要注意的是窗口长度和窗口移动速率需要是batch time的整数倍。
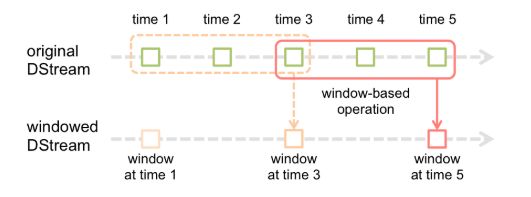
Window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
//输入
-------
java
scala
-------
java
scala
-------
//输出
-------
java
scala
-------
java
scala
java
scala
-------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
//该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
object SparkWindowDemo1 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).map((_,1)).window(Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608637736000 ms
-------------------------------------------
-------------------------------------------
Time: 1608637740000 ms
-------------------------------------------
-------------------------------------------
Time: 1608637744000 ms
-------------------------------------------
(java,1)
(scala,1)
-------------------------------------------
Time: 1608637748000 ms
-------------------------------------------
(java,1)
(scala,1)
(java,1)
(scala,1)
-------------------------------------------
Time: 1608637752000 ms
-------------------------------------------
(java,1)
(scala,1)
-------------------------------------------
Time: 1608637756000 ms
-------------------------------------------
countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数
注:需要设置checkpoint
//输入
-------
java
-------
java
scala
-------
//输出
------
1
------
3
------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
//返回指定长度窗口中的元素个数。
object SparkWindowDemo2 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
streamingContext.checkpoint("checkpoint2")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup3")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[Long] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).map((_,1)).countByWindow(Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608639456000 ms
-------------------------------------------
-------------------------------------------
Time: 1608639460000 ms
-------------------------------------------
1
-------------------------------------------
Time: 1608639464000 ms
-------------------------------------------
3
-------------------------------------------
Time: 1608639468000 ms
-------------------------------------------
2
-------------------------------------------
Time: 1608639472000 ms
-------------------------------------------
0
-------------------------------------------
Time: 1608639476000 ms
-------------------------------------------
0
countByValueAndWindow(windowLength,slideInterval, [numTasks])
统计当前时间窗口中元素值相同的元素的个数(wordcount)
注:需要设置checkpoint
//输入
-----------
java
-----------
java
scala
-----------
//输出
---------
(java,1)
---------
(java,2)
(scala,1)
---------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
//统计当前时间窗口中元素值相同的元素的个数
object SparkWindowDemo3 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
streamingContext.checkpoint("checkpoint3")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup4")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[(String, Long)] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).countByValueAndWindow(Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608639846000 ms
-------------------------------------------
-------------------------------------------
Time: 1608639850000 ms
-------------------------------------------
(java,1)
-------------------------------------------
Time: 1608639854000 ms
-------------------------------------------
(java,2)
(scala,1)
-------------------------------------------
Time: 1608639858000 ms
-------------------------------------------
(java,1)
(scala,1)
-------------------------------------------
Time: 1608639862000 ms
-------------------------------------------
reduceByWindow(func, windowLength,slideInterval)
在调用DStream上首先去窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce
//输入
----------
java
----------
java
spark
----------
//输出
----------
java
----------
java:java:spark
----------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo4 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
streamingContext.checkpoint("checkpoint4")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup5")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[String] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).reduceByWindow(_+":"+_,Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608720860000 ms
-------------------------------------------
-------------------------------------------
Time: 1608720864000 ms
-------------------------------------------
java
-------------------------------------------
Time: 1608720868000 ms
-------------------------------------------
java:java:spark
-------------------------------------------
Time: 1608720872000 ms
-------------------------------------------
java:spark
-------------------------------------------
Time: 1608720876000 ms
-------------------------------------------
reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
reduceByKeyAndWindow的数据源是基于该DStream的窗口长度汇总的所有数据进行计算。该操作有一个可选的并发数参数
//输入
----------
java
-----------
java
scala
-----------
//输出
-----------
(java,1)
-----------
(java,2)
(scala,1)
-----------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo5 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
streamingContext.checkpoint("checkpoint5")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup6")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).map((_,1)).reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608721078000 ms
-------------------------------------------
-------------------------------------------
Time: 1608721082000 ms
-------------------------------------------
(java,1)
-------------------------------------------
Time: 1608721086000 ms
-------------------------------------------
(java,2)
(scala,1)
-------------------------------------------
Time: 1608721090000 ms
-------------------------------------------
(java,1)
(scala,1)
-------------------------------------------
Time: 1608721094000 ms
-------------------------------------------
reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的
//输入
----------
java
-----------
java
spark
-----------
//输出
----------
(java,1)
----------
(java,2)
(spark,1)
----------
(java,0)
(spark,0)
----------
代码展示:
package nj.zb.kb09.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo6 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(2))
streamingContext.checkpoint("checkpoint6")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup7")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(line=>line.value().toString.split("\\s+")).map((_,1)).reduceByKeyAndWindow((a:Int,b:Int)=>a+b,(a:Int,b:Int)=>a-b,Seconds(8),Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608722110000 ms
-------------------------------------------
-------------------------------------------
Time: 1608722114000 ms
-------------------------------------------
(java,1)
-------------------------------------------
Time: 1608722118000 ms
-------------------------------------------
(java,2)
(spark,1)
-------------------------------------------
Time: 1608722122000 ms
-------------------------------------------
(java,1)
(spark,1)
-------------------------------------------
Time: 1608722126000 ms
-------------------------------------------
(java,0)
(spark,0)
-------------------------------------------
Time: 1608722130000 ms
-------------------------------------------
(java,0)
(spark,0)
transform
Transform操作是返回一个新的RDD的操作,比如map()和filter().调用转换操作时,不会立即执行.Spark会在内部记录下索要求执行的操作的相关信息,直到action操作触发时,才开始执行真正的计算
//输入
----------
java scala spark scala java
----------
java spark hello world java
----------
//输出
----------
((scala,20201223 19:51:00),2)
((java,20201223 19:51:00),2)
((spark,20201223 19:51:00),1)
----------
((java,20201223 19:51:10),2)
((world,20201223 19:51:10),1)
((spark,20201223 19:51:10),1)
((hello,20201223 19:51:10),1)
----------
代码展示:
package nj.zb.kb09.window
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo7 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(10))
streamingContext.checkpoint("checkpoint7")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup8")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[((String, String), Int)] = kafkaStream.transform((rdd, timestamp) => {
val format = new SimpleDateFormat("yyyyMMdd HH:mm:ss")
val time: String = format.format(timestamp.milliseconds)
val value: RDD[((String, String), Int)] = rdd.flatMap(x => x.value().split("\\s+")).map(x => ((x, time), 1)).reduceByKey((x,y)=>x+y).sortBy(x=>x._2,false)
value
})
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果展示:
-------------------------------------------
Time: 1608724250000 ms
-------------------------------------------
-------------------------------------------
Time: 1608724260000 ms
-------------------------------------------
((scala,20201223 19:51:00),2)
((java,20201223 19:51:00),2)
((spark,20201223 19:51:00),1)
-------------------------------------------
Time: 1608724270000 ms
-------------------------------------------
((java,20201223 19:51:10),2)
((world,20201223 19:51:10),1)
((spark,20201223 19:51:10),1)
((hello,20201223 19:51:10),1)
-------------------------------------------
Time: 1608724280000 ms
-------------------------------------------
SparkStreaming结合SparkSQL结合使用
Flume+Kafka+SparkStreaming已经发展为一个比较成熟的实时日志收集与计算架构,利用Kafka,既可以支持将用于离线分析的数据流到HDFS,又可以同时支撑多个消费者实时消费数据,包括SparkStreaming。然而,在SparkStreaming程序中如果有复杂业务逻辑的统计,使用Scala代码实现起来比较困难,也不易于别人理解。但如果在SparkStreaming中也是用SQL来做统计分析,是不是就简单很多呢。
//输入
----------
hello java scala java spark scala
----------
java java scala hello world spark spark spark
----------
//输出
----------
[hello,1]
[scala,2]
[spark,1]
[java,2]
----------
[hello,1]
[scala,1]
[spark,3]
[world,1]
[java,2]
----------
代码展示:
package nj.zb.kb09.window
import java.text.SimpleDateFormat
import nj.zb.kb09.window.SQLContextSingleton.instance
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SQLContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo8 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamKafkaSource")
val streamingContext = new StreamingContext(sparkConf,Seconds(10))
streamingContext.checkpoint("checkpoint8")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.100:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup9")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"),kafkaParams))
val numStream: DStream[Row] = kafkaStream.transform(rdd => {
val sqlContext: SQLContext = SQLContextSingleton.getInstance(rdd.sparkContext)
import sqlContext.implicits._
val words: RDD[String] = rdd.flatMap(_.value().toString.split("\\s+"))
val tuple2RDD: RDD[(String, Int)] = words.map((_, 1))
tuple2RDD.toDF("name", "cn").createOrReplaceTempView("tbwordcount")
val frame: DataFrame = sqlContext.sql("select name,count(cn) from tbwordcount group by name")
/*val dataSet: Dataset[Unit] = frame.map(row => {
val name: String = row.getAs[String]("name")
val count: Long = row.getAs[Long]("cn")
})
dataSet.rdd*/
frame.rdd
})
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
object SQLContextSingleton{
@transient private var instance:SQLContext=_
def getInstance(sparkContext: SparkContext):SQLContext={
synchronized(if(instance==null){
instance= new SQLContext(sparkContext)
}
)
instance
}
}
结果展示:
-------------------------------------------
Time: 1608724910000 ms
-------------------------------------------
-------------------------------------------
Time: 1608724920000 ms
-------------------------------------------
[hello,1]
[scala,2]
[spark,1]
[java,2]
-------------------------------------------
Time: 1608724930000 ms
-------------------------------------------
-------------------------------------------
Time: 1608724940000 ms
-------------------------------------------
[hello,1]
[scala,1]
[spark,3]
[world,1]
[java,2]
-------------------------------------------
Time: 1608724950000 ms
-------------------------------------------