ElasticSearch与Kibana在linux的下载安装及使用
一丶ElasticSearch的下载安装
1.解压jar包
![]()
tar -zxvf es.tar -C /opt/module
2.配置elasticsearch.yml文件
#1. 集群名称,同一集群名称必须相同
cluster.name: my-es
#2. 单个节点名称, 各个节点名称不能相同
node.name: node-1
#3. 关闭内存自检查
bootstrap.memory_lock: false
bootstrap.system_call_filter: false #这个是需要额外添加的
#4.网络iP更改: host更改为当前机器IP地址, port保持9200端口就可以
network.host: linux101
http.port: 9200
#5.自发现配置:新节点向集群报到的主机名
discovery.zen.ping.unicast.hosts: ["linux101", "linux102","linux103"]
3.如果内存不够,可以去配置jvm.options这个文件
-Xms512m
-Xmx512m
Es安装出现的问题情况,及解决:
================================
一丶 can not run elasticsearch as root
es为了安全性,不能使用root用户启动
解决:
groupadd es # 添加用户组
useradd es -g es -p password
chown es:es -R es文件夹/ # -R 处理指定目录以及其子目录下的所有文件
chmod u+w /etc/sudoers #给这个文件增加写权限
vim /etc/sudoers #进行修改该文件
root ALL=(ALL) ALL
es ALL=(ALL) ALL #添加这一行,es我的用户名称
su es #切换为es用户
bin/elasticsearch #启动命令
================================
二丶max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
解决:
原因
系统允许 Elasticsearch 打开的最大文件数需要修改成 65536
解决
sudo vim /etc/security/limits.conf
添加内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
注意:“*” 不要省略掉,需要在每个集群节点上都进行配置
三丶max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决:
原因
一个进程可以拥有的虚拟内存区域的数量。
解决
sudo vim /etc/sysctl.conf
在文件最后添加一行
vm.max_map_count=262144
即可永久修改
注意: 完成第二和第三和第四问题修改之后,需要重启机器才能生效
====================================
四丶max number of threads [1024] for user [judy2] likely too low, increase to at least [4096] (CentOS7.x 不用改,centos6出现此问题)
原因
允许最大线程数修该成 4096
解决
sudo vim /etc/security/limits.d/20-nproc.conf
修改如下内容
* soft nproc 1024
修改为
* soft nproc 4096
================================
五丶with the same id but is a different node instance
原因:
这个问题出现的原因是为了方便,我们往其他节点上配置的时候,直接进行拷贝,如果第一个节点上已经产生了数据,就会出现这个错误
解决:
在elasticsearch的data文件夹下,删除掉nodes即可,重新启动,启动成功
================================
二丶Kibana的下载安装
概述:
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作,我们这里主要用于Elasticsearch的代码开发,比如我们的Elasticsearch的访问方式是以Resultful风格进行交互的,我们可以通过浏览器来进行查询等操作,以可以通过linux的curl 命令来进行访问查询,当然也可以使用postman工具来进行访问,我们这里推荐的方式是Kibana来访问,也可以做可视化
下载:
1.解压安装包
tar -zxvf kibanaxxx.tar.gz -C /opt/module
2.进入到config目录下修改配置kibana.yml
#授权远程访问
server.host: "0.0.0.0"
#指定ElasticSearch地址(可以有多个)
elasticsearch.hosts: ["http://linux101:9200","http://linux102:9200","http://linux103:9200"]
#默认端口访问5601
3.启动与关闭
后台启动:
nohup bin/kibana &
查看是否启动成功: 因为kibana是node.js写的,出现下面界面成功!
![]()
启动成功之后,就可以通过网页进行访问了: http://linux101:5601/
关闭kibana:
netstat -tunlp |grep 5601 #查看出所对应的端口号
kill 1869 # 杀死进程
4.中文分词器
因为默认的中文分词器就是通过一个一个的字进行分词的,根本就没法使用,我们推荐使用IK分词器
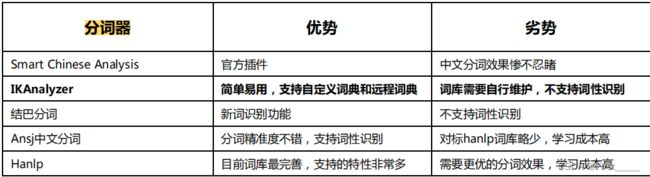
IK分词器的安装:
下载地址:
elasticsearch-ik的zip文件下载
在kibana的plugins目录下创建ik文件夹,将elasticsearch-analysis-ik-6.6.0.zip文件进行解压到plugins/ik文件下:
#解压:
unzip elasticsearch-analysis-ik-6.6.0.zip -d /opt/module/kibana/plugins/ik
##重启kibana即可
#可以使用下面命令查看效果
# ik的简单分词
GET /_analyze
{
"text": "我是中国人",
"analyzer": "ik_smart"
}
#ik的复杂分词
GET /_analyze
{
"text": "我是中国人",
"analyzer": "ik_max_word"
}
ElasticSearch的Ik自定义词库扩展:
这个目录下就是我们Ik的本地词库:
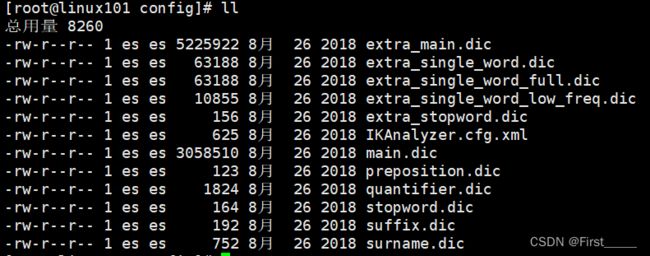
如果我们需要扩展的话,我们就需要创建一个文件,并将词汇导入,并且配置IKAnalyzer.cfg.xml文件:
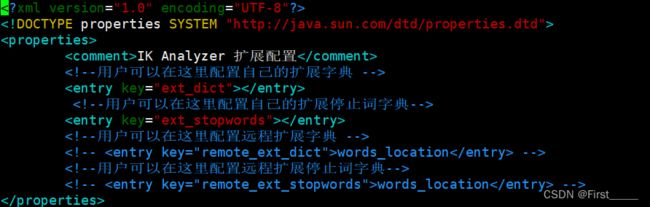
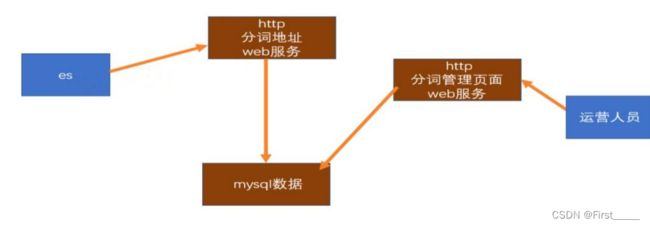
为了方便词库的扩展,我们也可以写java接口扩展远程字典,或者使用nginx扩展:
思路流程图如下:
ElasticSearch查询用到的例子:
#(7.0之前默认分区为5个,副本1 )
#(7.0之后默认分区为1个,副本1 )
#查询各个节点的状态
GET /_cat/nodes?v
#查询集群的健康状态
GET _cat/health?v
#创建索引, 也可以不创建索引,如果不创建,添加document的时候,会自动创建索引
#创建索引movie_index
PUT /movie_index
#查看索引
GET /movie_index
# 查询各个索引的状态
GET /_cat/indices?v
# 查询某个索引的分片情况
GET /_cat/shards/movie_index
# 删除索引movie_index
DELETE /movie_index
#添加文档 PUT /索引名/类型名/文档 id
PUT /movie_index/movie/1
{ "id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
] }
#根据文档id查看文档
GET /movie_index/movie/1
#查看该索引的所有文档
GET /movie_index/_search
#根据id删除文档
DELETE /movie_index/movie/3
#=======================查询语法==========================
#分词查询语法
GET /movie_index/_search
{
"query": {
"match": {
"name": "operation red sea"
}
}
}
#按照短语查询(相当于 like %短语%)
GET /movie_index/_search
{
"query": {
"match_phrase": {
"name": "red"
}
}
}
#使用term 精准搜索匹配(text类型必须使用keyword,其他的不用使用)
GET /movie_index/_search
{
"query": {
"term": {
"name":"operation red sea"
}
}
}
#使用fuzzy关键词进行容错匹配(名称写错也没事,但是不能错的离谱)
GET /movie_index/_search
{
"query": {
"fuzzy": {
"name": "operation"
}
}
}
#过滤--先匹配,再过滤=====================================
GET /movie_index/_search
{
"query": {
"match": {
"name": "operation"
}
},
"post_filter": {
"term": {
"actorList.id": 2
}
}
}
#过滤--匹配过滤同时进行(速度快,must下面可以有多个查询条件)
GET /movie_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "operation"
}
},
{
"term": {
"doubanScore":"8.5"
}
}
],
"filter": {
"term": {
"actorList.id": "2"
}
}
}
}
}
#过滤-- 范围过滤 (doubanScore在8-8.5之间的,两侧范围闭区间)
GET /movie_index/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 8,
"lte": 8.5
}
}
}
}
# 排序========================================
GET /movie_index/_search
{
"query": {
"match": {
"name": "operation"
}
},
"sort": [
{
"order": "asc"
}
}
]
}
# 分页查询 (展示前两条记录)
GET /movie_index/_search
{
"query": {
"match": {
"name": "operation"
}
},
"from": 0,
"size": 2
}
# 指定查询字段
GET /movie_index/_search
{
"_source": ["name","id"]
}
# 字段高亮显示 (也可以自定义)
GET /movie_index/_search
{
"query": {
"match": {
"name": "red"
}
},
"highlight": {
"fields": {"name":{}},
"pre_tags": "前面",
"post_tags": "后面"
}
}
# 聚合操作======================================
#term:精准匹配 terms:聚合操作,相当于groupby
# aggs 就是聚合操作
#1.(查询每个演员参演的作品个数)
GET /movie_index/_search
{
"aggs": {
"groupbyDataMy": {
"terms": {
"field": "actorList.name.keyword",
"size": 10
}
}
}
}
#2. 查询每个演员参演的作品的平均评分,并进行排序
# 在aggs里面聚合之后,再使用avg
GET /movie_index/_search
{
"aggs": {
"groupByDataMy": {
"terms": {
"field": "actorList.name.keyword",
"size": 10,
"order": {
"avg_data": "desc"
}
},
"aggs": {
"avg_data": {
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
# ================分词器================
# ik的简单分词
GET /_analyze
{
"text": "我是中国人",
"analyzer": "ik_smart"
}
#ik的复杂分词
GET /_analyze
{
"text": "我是中国人",
"analyzer": "ik_max_word"
}