OpenCV防抖实践及代码解析笔记
视频防抖是指用于减少摄像机运动对最终视频的影响的一系列方法。摄像机的运动可以是平移(比如沿着x、y、z方向上的运动)或旋转(偏航、俯仰、翻滚)。
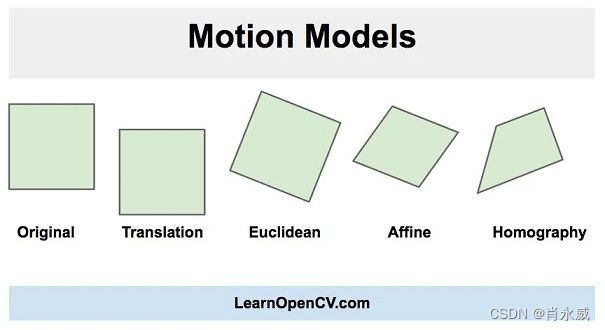
正如你在上面的图片中看到的,在欧几里得运动模型中,图像中的一个正方形可以转换为任何其他位置、大小或旋转不同的正方形。它比仿射变换和单应变换限制更严格,但对于运动稳定来说足够了,因为摄像机在视频连续帧之间的运动通常很小。
1. 识别抖动
寻找帧之间的移动,这是算法中最关键的部分。我们将遍历所有的帧,并找到当前帧和前一帧之间的移动。欧几里得运动模型要求我们知道两个坐标系中两个点的运动。但是在实际应用中,找到50-100个点的运动,然后用它们来稳健地估计运动模型。
特征跟踪首先需要识别出易跟踪的特征,光滑的区域不利于跟踪,而有很多角的纹理区域则比较好。OpenCV有一个快速的特征检测器goodFeaturesToTrack,可以检测最适合跟踪的特性。
我们在前一帧中找到好的特征,就可以使用Lucas-Kanade光流算法在下一帧中跟踪它们。它是利用OpenCV中的calcOpticalFlowPyrLK函数实现的。
接着估计运动,我们已经找到了特征在当前帧中的位置,并且我们已经知道了特征在前一帧中的位置。所以我们可以使用这两组点来找到映射前一个坐标系到当前坐标系的刚性(欧几里德)变换。这是使用函数estimateRigidTransform完成的。
# 检测前一帧的特征点
prev_pts = cv2.goodFeaturesToTrack(prev_gray,
maxCorners=200,
qualityLevel=0.01,
minDistance=30,
blockSize=3)
# 读下一帧
success, curr = cap.read()
if not success:
break
# 转换为灰度图
curr_gray = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
# 计算光流(即轨迹特征点)
curr_pts, status, err = cv2.calcOpticalFlowPyrLK(
prev_gray, curr_gray, prev_pts, None)
# 检查完整性
assert prev_pts.shape == curr_pts.shape
# 只过滤有效点
idx = np.where(status == 1)[0]
prev_pts = prev_pts[idx]
curr_pts = curr_pts[idx]
# 找到变换矩阵
# 只适用于OpenCV-3或更少的版本吗
# m = cv2.estimateRigidTransform(prev_pts, curr_pts, fullAffine=False)
m, inlier = cv2.estimateAffine2D(prev_pts, curr_pts, )
2. 计算帧之间的平滑运动
在前面的步骤中,我们估计帧之间的运动并将它们存储在一个数组中。我们现在需要通过叠加上一步估计的微分运动来找到运动轨迹。
轨迹计算,在这一步,我们将增加运动之间的帧来计算轨迹。我们的最终目标是平滑这条轨迹,可以很容易地使用numpy中的cumsum(累计和)来实现。
计算平滑轨迹,我们计算了运动轨迹。所以我们有三条曲线来显示运动(x, y,和角度)如何随时间变化。
平滑任何曲线最简单的方法是使用移动平均滤波器(moving average filter)。顾名思义,移动平均过滤器将函数在某一点上的值替换为由窗口定义的其相邻函数的平均值。
def movingAverage(curve, radius):
window_size = 2 * radius + 1
# 定义过滤器
f = np.ones(window_size) / window_size
# 为边界添加填充
curve_pad = np.lib.pad(curve, (radius, radius), 'edge')
# 应用卷积
curve_smoothed = np.convolve(curve_pad, f, mode='same')
# 删除填充
curve_smoothed = curve_smoothed[radius:-radius]
# 返回平滑曲线
return curve_smoothed
def smooth(trajectory):
smoothed_trajectory = np.copy(trajectory)
# 过滤x, y和角度曲线
for i in range(3):
smoothed_trajectory[:, i] = movingAverage(
trajectory[:, i], radius=SMOOTHING_RADIUS)
return smoothed_trajectory
计算平滑变换
到目前为止,我们已经得到了一个平滑的轨迹。在这一步,我们将使用平滑的轨迹来获得平滑的变换,可以应用到视频的帧来稳定它。
这是通过找到平滑轨迹和原始轨迹之间的差异,并将这些差异加回到原始的变换中来完成的。
# 使用累积变换和计算轨迹
trajectory = np.cumsum(transforms, axis=0)
# 创建变量来存储平滑的轨迹
smoothed_trajectory = smooth(trajectory)
# 计算smoothed_trajectory与trajectory的差值
difference = smoothed_trajectory - trajectory
# 计算更新的转换数组
transforms_smooth = transforms + difference
3. 将平滑的摄像机运动应用到帧中
现在我们所需要做的就是循环帧并应用我们刚刚计算的变换。如果我们有一个指定为(x, y, θ \theta θ),的运动,对应的变换矩阵是:
T = [ c o s θ − s i n θ x s i n θ c o s θ y ] T=\begin{bmatrix} cos\theta & -sin \theta & x\\ sin \theta & cos \theta & y \end{bmatrix} T=[cosθsinθ−sinθcosθxy]
# 从新的转换数组中提取转换
dx = transforms_smooth[i, 0]
dy = transforms_smooth[i, 1]
da = transforms_smooth[i, 2]
# 根据新的值重构变换矩阵
m = np.zeros((2, 3), np.float32)
m[0, 0] = np.cos(da)
m[0, 1] = -np.sin(da)
m[1, 0] = np.sin(da)
m[1, 1] = np.cos(da)
m[0, 2] = dx
m[1, 2] = dy
# 应用仿射包装到给定的框架
frame_stabilized = cv2.warpAffine(frame, m, (w, h))
# Fix border artifacts
frame_stabilized = fixBorder(frame_stabilized)
# 将框架写入文件
frame_out = frame_stabilized
out.write(frame_out)
修复边界伪影
当我们稳定一个视频,我们可能会看到一些黑色的边界伪影。这是意料之中的,因为为了稳定视频,帧可能不得不缩小大小。我们可以通过将视频的中心缩小一小部分(例如4%)来缓解这个问题。
下面的fixBorder函数显示了实现。我们使用getRotationMatrix2D,因为它在不移动图像中心的情况下缩放和旋转图像。我们所需要做的就是调用这个函数时,旋转为0,缩放为1.04(也就是提升4%)。
def fixBorder(frame):
s = frame.shape
# 在不移动中心的情况下,将图像缩放4%
T = cv2.getRotationMatrix2D((s[1] / 2, s[0] / 2), 0, 1.04)
frame = cv2.warpAffine(frame, T, (s[1], s[0]))
return frame
4. 实践代码
代码来自[1]
import numpy as np
import cv2
def movingAverage(curve, radius):
window_size = 2 * radius + 1
# 定义过滤器
f = np.ones(window_size) / window_size
# 为边界添加填充
curve_pad = np.lib.pad(curve, (radius, radius), 'edge')
# 应用卷积
curve_smoothed = np.convolve(curve_pad, f, mode='same')
# 删除填充
curve_smoothed = curve_smoothed[radius:-radius]
# 返回平滑曲线
return curve_smoothed
def smooth(trajectory):
smoothed_trajectory = np.copy(trajectory)
# 过滤x, y和角度曲线
for i in range(3):
smoothed_trajectory[:, i] = movingAverage(
trajectory[:, i], radius=SMOOTHING_RADIUS)
return smoothed_trajectory
def fixBorder(frame):
s = frame.shape
# 在不移动中心的情况下,将图像缩放4%
T = cv2.getRotationMatrix2D((s[1] / 2, s[0] / 2), 0, 1.04)
frame = cv2.warpAffine(frame, T, (s[1], s[0]))
return frame
# 尺寸越大,视频越稳定,但对突然平移的反应越小
SMOOTHING_RADIUS = 50
# 读取输入视频
cap = cv2.VideoCapture('video1.mp4')
# 得到帧数
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(n_frames)
# exit()
# #我们的测试视频可能读错了1300帧之后的帧
# n_frames = 1300
# 获取视频流的宽度和高度
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 获取每秒帧数(fps)
fps = cap.get(cv2.CAP_PROP_FPS)
# 定义输出视频的编解码器
#fourcc = cv2.VideoWriter_fourcc(*'MJPG')
#fourcc = cv2.VideoWriter_fourcc('M','P','4','V')
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
# 设置输出视频
out = cv2.VideoWriter('video1_1.mp4', fourcc, fps, (w, h))
#out = cv2.VideoWriter('video_out.avi', fourcc, fps, (2 * w, h)) # 2*w用于前后对比
# 读第一帧
_, prev = cap.read()
# 将帧转换为灰度
prev_gray = cv2.cvtColor(prev, cv2.COLOR_BGR2GRAY)
# 预定义转换numpy矩阵
transforms = np.zeros((n_frames - 1, 3), np.float32)
for i in range(n_frames - 2):
# 检测前一帧的特征点
prev_pts = cv2.goodFeaturesToTrack(prev_gray,
maxCorners=200,
qualityLevel=0.01,
minDistance=30,
blockSize=3)
# 读下一帧
success, curr = cap.read()
if not success:
break
# 转换为灰度图
curr_gray = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
# 计算光流(即轨迹特征点)
curr_pts, status, err = cv2.calcOpticalFlowPyrLK(
prev_gray, curr_gray, prev_pts, None)
# 检查完整性
assert prev_pts.shape == curr_pts.shape
# 只过滤有效点
idx = np.where(status == 1)[0]
prev_pts = prev_pts[idx]
curr_pts = curr_pts[idx]
# 找到变换矩阵
# 只适用于OpenCV-3或更少的版本吗
# m = cv2.estimateRigidTransform(prev_pts, curr_pts, fullAffine=False)
m, inlier = cv2.estimateAffine2D(prev_pts, curr_pts, )
# 提取traslation
dx = m[0, 2]
dy = m[1, 2]
# 提取旋转角
da = np.arctan2(m[1, 0], m[0, 0])
# 存储转换
transforms[i] = [dx, dy, da]
# 移到下一帧
prev_gray = curr_gray
print("Frame: " + str(i) + "/" + str(n_frames) +
" - Tracked points : " + str(len(prev_pts)))
# 使用累积变换和计算轨迹
trajectory = np.cumsum(transforms, axis=0)
# 创建变量来存储平滑的轨迹
smoothed_trajectory = smooth(trajectory)
# 计算smoothed_trajectory与trajectory的差值
difference = smoothed_trajectory - trajectory
# 计算更新的转换数组
transforms_smooth = transforms + difference
# 将视频流重置为第一帧
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
# 写入n_frames-1转换后的帧
for i in range(n_frames - 2):
# 读下一帧
success, frame = cap.read()
if not success:
break
# 从新的转换数组中提取转换
dx = transforms_smooth[i, 0]
dy = transforms_smooth[i, 1]
da = transforms_smooth[i, 2]
# 根据新的值重构变换矩阵
m = np.zeros((2, 3), np.float32)
m[0, 0] = np.cos(da)
m[0, 1] = -np.sin(da)
m[1, 0] = np.sin(da)
m[1, 1] = np.cos(da)
m[0, 2] = dx
m[1, 2] = dy
# 应用仿射包装到给定的框架
frame_stabilized = cv2.warpAffine(frame, m, (w, h))
# Fix border artifacts
frame_stabilized = fixBorder(frame_stabilized)
# 将框架写入文件
#frame_out = cv2.hconcat([frame, frame_stabilized]) # 合并前后对比视频
frame_out = frame_stabilized
# 如果图像太大,调整它的大小。
if (frame_out.shape[1] > 1920):
frame_out = cv2.resize(
frame_out, (frame_out.shape[1] / 2, frame_out.shape[0] / 2))
#cv2.imshow("Before and After", frame_out)
#cv2.waitKey(10)
out.write(frame_out)
# 发布视频
cap.release()
out.release()
# 关闭窗口
cv2.destroyAllWindows()
5. OepnCV相关知识点
常见视频编码参数
VideoWriter_fourcc()常见的编码参数
参数列表
cv2.VideoWriter_fourcc(‘M’, ‘P’, ‘4’, ‘V’)
MPEG-4编码 .mp4 可指定结果视频的大小
cv2.VideoWriter_fourcc(‘X’,‘2’,‘6’,‘4’)
MPEG-4编码 .mp4 可指定结果视频的大小
cv2.VideoWriter_fourcc(‘I’, ‘4’, ‘2’, ‘0’)
该参数是YUV编码类型,文件名后缀为.avi 广泛兼容,但会产生大文件
cv2.VideoWriter_fourcc(‘P’, ‘I’, ‘M’, ‘I’)
该参数是MPEG-1编码类型,文件名后缀为.avi
cv2.VideoWriter_fourcc(‘X’, ‘V’, ‘I’, ‘D’)
该参数是MPEG-4编码类型,文件名后缀为.avi,可指定结果视频的大小
cv2.VideoWriter_fourcc(‘T’, ‘H’, ‘E’, ‘O’)
该参数是Ogg Vorbis,文件名后缀为.ogv
cv2.VideoWriter_fourcc(‘F’, ‘L’, ‘V’, ‘1’)
该参数是Flash视频,文件名后缀为.flv
cv2.VideoWriter写入为空或打不开的解决方案
一定要用video.release()方法关闭文件。
参考:
[1]. 默凉. opencv-python 视频流光去抖、实时去抖. CSDN博客. 2022.10
[2]. AI算法与图像处理. OpenCV实现视频防抖技术. 知乎. 2020.09