MySQL 8.0参考手册-第三章 “教程”
最近在学习MySQL,看官方的教材,顺带翻译一遍。
原文档在这:
https://dev.mysql.com/doc/refman/8.0/en/tutorial.html
这是完全公开的资料,我想,翻译一下应该不会有什么版权问题,如有,请联系我删除。
这个章节通过使用mysql客户端程序创建和使用一个简单的数据库,为您提供了MySQL的一个教程介绍。mysql(有时也被叫做“终端监视器”或直接叫“监视器”)是一个交互式程序,它让你能够连接到MySQL服务器、运行查询语句并看到结果。mysql也可以使用批处理模式。你可以把查询语句提前放在一个文件中,然后让mysql去执行文件的内容。我们在教程中将两种方式都用到了。
如要查看mysql提供的选项清单,可以使用–help选项调用它。
shell> mysql --help
这个章节默认你的机器上已经安装好了mysql,并且已经有了一个可以连接的MySQL服务器。如果并没有的话,请联系你的MySQL管理员。(如果你就是管理员,你需要查阅这个手册的相关部分,如第五章-MySQL服务器管理)。
这个章节描述了配置和使用一个数据库的整个过程。如果你只想访问一个现有的数据库,可能你会想跳过描述怎么创建数据库和其中的数据表的部分。
由于这个章节本质上是一个教程,我们隐去了很多细节。想进一步了解的话请查阅手册的相关部分。
文章目录
- 连接及断连服务器
- 输入查询
- 创建和使用一个数据库
-
- 创建和选择一个数据库
- 创建一个数据表
- 加载数据到数据表
- 从数据表中提取信息
-
- 选择所有数据
- 选择特定的行
- 选择特定的列
- 为行排序
- 日期计算
- 处理NULL值
- 模式匹配
- 统计行数
- 使用不止一个表
- 获得关于数据库和数据表的信息
- 以批处理模式使用mysql
- 常见查询的示例
-
- 一个列的最大值
- 某列值为最大的行
- 每组的最大列
- 包含特定列的组最大值的行
- 使用用户定义的变量
- 使用外键
- 在两个键上搜索
- 计算每天的访问量
- 使用AUTO_INCREMENT
- 结合Apache来使用MySQL
连接及断连服务器
为了连接到服务器,通常需要你在调用mysql时提供一个MySQL用户名以及很可能还要一个密码。如果服务器不是运行在你现在登录的这台机器上的话,你还需要指定一个主机名。联系你的管理员来获得你连接时要用到的连接参数(即,要用什么主机、用户名和密码)。一旦你搞明白了参数,就应该能够像这样子连接服务器:
shell> mysql -h host -u user -p
Enter password: ********
host和user分别代表你的MySQL服务器所运行在的主机名以及你的MySQL账号的用户名。替代为你的配置的对应值。********则代表你的密码;当mysql显示 Enter password: 提示符时输入它。
如果一切顺利,你应该会看到一些紧跟着提示符 mysql> 的介绍信息:
shell> mysql -h host -u user -p
Enter password: ********
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 25338 to server version: 8.0.21-standard
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
mysql> 提示符是告诉你,mysql已经等待好你输入SQL语句了。
如果你是在与MySQL所运行在的同一台机器上登录的,你可以忽略host,简单的像这样子就好:
shell> mysql -u user -p
如果,当你尝试登录时获得了如ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/tmp/mysql.sock’ (2),这样的错误消息,这意味着MySQL服务器daemon(Unix)或service (Windows)不在运行中。联系管理员或者看第二章,安装和更新MySQL中对应于你的操作系统的部分。
如果在登录时遇到了其他问题,见章节B.4.2,“使用MySQL程序时的常见错误”。
一些MySQL设施允许用户以匿名(无名字)用户的方式来连接运行在本地主机上的服务器。如果你的机器上是这样的情况,你应该能够不带任何选项地调用mysql。
shell> mysql
当你连接成功后,你可以通过在 mysql> 提示符输入 QUIT (或者 \q )来在任意时间断开连接。
mysql> QUIT
Bye
在Unix上,你也可以通过按Control+D来断开连接。
后面章节的大部分例子默认你已经连上了服务器。mysql> 提示符就表明这个意思。
输入查询
确定你已经如前面部分所述的那样连接到了服务器。它本身不会选择使用任何数据库,但这没有问题。在这个时候,更重要的是搞明白怎么提交查询,而不是直接就跳到创建表、往表加载数据以及从表提取数据。这个章节描述了输入查询的基本原则,使用一些你可以使用的查询来熟悉 mysql 的工作方式。
这里是一条简单的查询,它让服务器告诉你它的版本号和当前的日期。在 mysql> 提示符后面输入如下内容,并按回车:
mysql> SELECT VERSION(), CURRENT_DATE;
+-----------+--------------+
| VERSION() | CURRENT_DATE |
+-----------+--------------+
| 5.8.0-m17 | 2015-12-21 |
+-----------+--------------+
1 row in set (0.02 sec)
mysql>
这个查询表明了关于mysql的这些事情:
- 一个查询通常由一条SQL语句后面再跟一个分号组成。(有一些例外情况可以没有分号。前面提到的QUIT就是一个。之后我们会提到其他的。)
- 当你提交一条查询时,mysql将其发送给服务器来执行,并展示结果,然后打印另一个 mysql> 提示符来表明它已经准备好接收另一条查询了。
- mysql以表格形式(行和列)来展示查询的输出。第一行包含列的标签。后面的行是查询结果。通常,列标签是你从数据库表格提取出来的列的名字。如果你在提取的是一个表达式的值,而不是一个表列(就像刚刚那个示例那样),mysql会把列标签标记为表达式本身。
- mysql会展示返回了多少行,以及查询执行了多长时间,这会让你对服务器的性能有一个粗略的概念。这个值是不精确的,因为它是壁钟时间(而不是CPU或机器时间),受到许多因素的影响,如服务器负载和网络延迟。(简而言之,这行“rows in set”有时不会展示在这章后面的示例中。)
关键词是不区分大小写的。以下查询是等价的:
mysql> SELECT VERSION(), CURRENT_DATE;
mysql> select version(), current_date;
mysql> SeLeCt vErSiOn(), current_DATE;
这是另一条查询。它表明你可以将mysql用作一个简单的计算器:
mysql> SELECT SIN(PI()/4), (4+1)*5;
+------------------+---------+
| SIN(PI()/4) | (4+1)*5 |
+------------------+---------+
| 0.70710678118655 | 25 |
+------------------+---------+
1 row in set (0.02 sec)
到目前为止展示的查询都是相对较短的单行语句。你甚至可以在单行中输入多个语句。只要在每一个语句后面用分号来结束就行:
mysql> SELECT VERSION(); SELECT NOW();
+-----------+
| VERSION() |
+-----------+
| 8.0.13 |
+-----------+
1 row in set (0.00 sec)
+---------------------+
| NOW() |
+---------------------+
| 2018-08-24 00:56:40 |
+---------------------+
1 row in set (0.00 sec)
一个查询并不需要将所有内容都写在一行,所以需要写好多行的很长的查询并没有问题。mysql是通过查找结尾的分号来确定你的语句在哪里结束的,而不是通过输入行的结尾。(换句话说,mysql接受任意格式的输入:它收集输入的行但却不执行,直到它看到分号。)
这是一条简单的多行语句:
mysql> SELECT
-> USER()
-> ,
-> CURRENT_DATE;
+---------------+--------------+
| USER() | CURRENT_DATE |
+---------------+--------------+
| jon@localhost | 2018-08-24 |
+---------------+--------------+
在这个例子中,要注意提示符是怎么从mysql> 在你输入多行查询的第一行后变为 -> 的。这就是mysql表明它还没看到一条完整的语句并正在等待剩下的部分的方式。提示符是你的朋友,因为它提供有价值的反馈。如果你好好利用这反馈,你就总是能意识到mysql正在等待什么。
如果你决定你不想要执行一个正在输入中的查询,通过输入 \c 来取消它:
mysql> SELECT
-> USER()
-> \c
mysql>
这里,我们同样注意下提示符。它在你输入 \c 后切换回了 mysql>,这提供了反馈,表明mysql准备好一个新的查询了。
以下表格了每一个你可能看到的提示符,并总结了它们在说mysql处于什么状态。
| 提示符 | 含义 |
|---|---|
| mysql> | 准备好接受新的查询 |
| -> | 等待多行查询的下一行 |
| '> | 等待下一行,等待补全一个以单引号(’)起始的字符串。 |
| "> | 等待下一行,等待补全一个以双引号(")起始的字符串。 |
| `> | 等待下一行,等待补全一个以反撇号(`)起始的标识符。 |
| /*> | 等待下一行,等待补全一个以 /* 起始的注释。 |
多行语句通常是在你想要提交一条单行查询,但却忘了末尾的分号时意外出现的。这种情况下,mysql等待更多的输入:
mysql> SELECT USER()
->
如果你发生了这个情况(你以为你已经输入了一条语句,但是唯一的答复是一个 -> 提示符),最可能的情况是 mysql 正在等待分号。如果你没有注意到提示符的话,你也许会坐在那一会,然后才会意识到要做什么。输入一个分号来完成语句,然后 mysql 会执行它:
mysql> SELECT USER()
-> ;
+---------------+
| USER() |
+---------------+
| jon@localhost |
+---------------+
’> 和 "> 提示符会在字符串收集期间出现(另一种表明MySQL正在等待补全一个字符串的方式)。在MySQL中,你可以写由 ’ 或 " 字符包围的字符串(比如,‘hello’ 或 “goodbye”),并且mysql允许你输入横跨多行的字符串。当你看到 '> 或 "> 提示符时,这意味着你刚输入了一个包含由 ’ 或 " 字符起始的字符串的行,但是还没有输入匹配的引号来结束字符串。这通常表明你不小心漏掉了一个引号字符。比如:
mysql> SELECT * FROM my_table WHERE name = 'Smith AND age < 30;
'>
如果你输入这条SELECT语句,然后按回车并等待结果,什么也不会发生。然后你就会思考,为什么这个查询要花这么长的时间,然后就注意到 '> 提示符提供的线索。它告诉你, mysql 希望看到一个未结束的字符串的剩余部分。(你看到了语句中的错误了么?字符串 'Smith 遗漏了第二个单引号。)
这时候,你应该做什么?最简单的方式是取消查询。但是,在这种情况下你不能仅仅打一个\c,因为 mysql 会把它解释为字符串的一部分并进行收集。实际上你应该输入封闭用的引号字符(这样 mysql 就知道你已经结束了字符串了),然后输入 \c:
mysql> SELECT * FROM my_table WHERE name = 'Smith AND age < 30;
'> '\c
mysql>
提示符变回 mysql> ,这表明 mysql 准备好接受新的查询。
`> 提示符类似于 '> 和 "> 提示符,但是是在表明你开始了但却还没补全一个反撇引号的标识符。
认得 '> 、 "> 和 `> 的含义十分重要,因为如果你错误地输入了一个未结束的字符串,你输入的任何后续的行看上去都像被mysql忽略了—包括包含 QUIT 的行。这可能会让人十分困惑,特别是当你不知道你需要先提供结束引号,才能够取消当前查询时。
注意
从这以后的多行语句在书写时不会有附属的(->或其他)提示符,这是为了便于你复制黏贴并尝试语句。
创建和使用一个数据库
一旦你知道了怎么输入SQL语句,你就准备好访问一个数据库了。
假设你的家(你的menagerie(动物园))里有许多宠物,你想要维护关于它们的多种类型的信息。你可以创建一些表来存放你的数据并将相关信息加载给它们。然后你就可以通过从表中提取数据来回答关于你的动物们的不同类型的问题。这个章节会给你展示怎么执行以下操作:
- 创建一个数据库
- 创建一个表
- 加载数据到表中
- 以多种方式从表中提取数据
- 使用多个表
动物园 数据库(刻意地)很简单,但是很容易就可以想象到现实世界中一些会用到类似数据库的情形。比如,这样一个数据库可能会被一个农民用于跟踪家畜的状态,或被一个兽医用于患者记录。以下章节中使用的menagerie数据库可以从MySQL网站上下载,其中包含一些查询和示例数据,https://dev.mysql.com/doc/上提供tar和Zip格式的压缩文件。
使用SHOW语句来搞明白目前服务器上存在哪些数据库。
mysql> SHOW DATABASES;
+----------+
| Database |
+----------+
| mysql |
| test |
| tmp |
+----------+
mysql数据库里描述了用户访问权限。test数据库通常是用来给用户尝试各种玩意的工作区。
这语句在你的机器上展示出来的数据库列表可能会有所不同;如果您没有SHOW DATABASES权限,则SHOW DATABASES不会显示您没有权限的数据库。详见章节13.7.7.14,“SHOW DATABASES语句”
如果存在test数据库,试着使用它:
mysql> USE test
Database changed
USE和QUIT一样,不需要分号。(如果你乐意的话,你也可以用分号来结束这个语句,这无伤大雅)。USE语句还有另一个很特别的地方:它必须写为单行。
你可以在test数据库中实验后面的示例(如果你已经访问了它),但是你在这数据库里创建的任何东西都可能被任意其他访问这数据库的人删除。因为这个原因,你很可能应该问问你的MySQL管理员,请求许可来使用一个你自己的数据库。假设你想要访问你的menagerie(动物园)数据库。管理员需要执行像这样的一条语句:
mysql> GRANT ALL ON menagerie.* TO 'your_mysql_name'@'your_client_host';
其中,your_mysql_name是赋予你的MySQL用户名,your_client_host是你连接到服务器的那台主机。
创建和选择一个数据库
如果管理员在为你设置许可时帮你创建了数据库的话,那你就直接可以用它了。否则,你需要自己创建它:
mysql> CREATE DATABASE menagerie;
在Unix下,数据库名字是大小写敏感的(不像SQL关键词),所以你必须总是用menagerie来指代你的数据库,而不能是Menagerie、MENAGERIE或其他变体。对于表名也是这样的。(在Windows下并没有这回事,当然你还是得在一个给定查询中用同样的字母大小写来指代数据库和数据表。但是由于许多原因,推荐的最佳实践是使用与创建数据库时所使用的相同的字母大小写。)
注意:
如果当你试图创建数据库时获得了如 ERROR 1044 (42000): Access denied for user ‘micah’@‘localhost’ to database ‘menagerie’ 这样的错误,这说明你的用户账户没有做这个事情所需的权限。和你的管理员讨论一下,或者查阅章节6.2,“访问控制及账号管理”。
创建一个数据库后并不会自动选择它来使用;你必须明确地选择它。为了让menagerie变成当前数据库,使用这个语句:
mysql> USE menagerie
Database changed
你的数据库仅仅需要创建一次,但是你必须在每次开始一个mysql会话时选择它来用。你可以提交一条USE语句来选择它,如示例所示。另外,你还可以当你从命令行中调用mysql程序时就选择数据库。只需要在所有你可能需要提供的连接参数后面指定它的名字。比如:
shell> mysql -h host -u user -p menagerie
Enter password: ********
重要:
命令中的menagerie并不是你的密码。如果你想要在命令中的-p选项后直接提供你的密码,必须中间不带空格(比如, -ppassword而不是-p password) 。但是,并不推荐直接在命令行中直接提供密码,因为这等于直接把密码暴露给了其他登录到你机器上的用户。
注意:
你可以随时使用 SELECT DATABASE() 来查看当前正在使用的数据库。
创建一个数据表
创建数据库十分简单,但是这时它是空的,SHOW TABLES就告诉了你这件事。
mysql> SHOW TABLES;
Empty set (0.00 sec)
难的部分是决定你的数据库的结构:你需要什么表,以及每一个表中应该有哪些列。
你想要一个表,这个表中包含你的每个宠物的一条记录。这个表可以叫做pet,它起码应该包含每个动物的名字。因为光一个名字的话十分无趣,表里头应该再包含其他信息。比如,如果你家里不只一个人有宠物,你也许想要列出每个动物的所有者。你也许还想要记录一些基本的描述信息,如物种和性别。
那年龄呢?这也许很有用,但将它存在数据库里并不是一个好选择。年龄会随着时间而变化,这意味着你得经常更新你的记录。实际上,存一个固定值更好,比如出生日期。这样,每当你需要年龄时,你可以通过将当前日期减去出生日期来计算获得。MySQL提供日期计算的功能,所以这并不难。不存储年龄而存储日期还有其他好处:
- 你可以将数据库用于如生成即将过生日的宠物的备忘录。(如果你认为这类查询有点蠢,请注意,在商业数据库中,可能会需要为当月或当周过生日的人发出生日祝贺,这是同类问题。)
- 你可以相对于任意日期来计算年龄,而不只是当前日期。比如,如果你在数据库中存储了死亡日期,你可以很简单地计算当一个宠物死亡时它多少岁。
你还能想到pet表中其他很有用的信息类型,但是目前指出的那些已经足够了:名字、拥有者、物种、性别、生日和死亡日期。
使用CREATE TABLE语句来指定你的表的布局:
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
VARCHAR是name(名字)、owner(拥有者)和species(物种)列的一个好选择,因为这些列的值的长度会变化。列定义中的长度并不需要一样,不必都是20。一般地,你可以从1到65535中挑一个长度,对你来说最合理的那个。如果你选错了,用着用着发现你需要更长的字段,可以用MySQL提供的ALTER TABLE语句。
有很多值类型可以用来代表动物记录中的性别,比如 ‘m’ 和 ‘f’,或者比如也可以是 ‘male’ 和 ‘female’。使用单个字符 ‘m’ 和 ‘f’ 是最简单的。
为birth和death列使用DATE数据类型是显然的。
一旦你已经创建了一个数据表,SHOW TABLE应该会产生一些输出:
mysql> SHOW TABLES;
+---------------------+
| Tables in menagerie |
+---------------------+
| pet |
+---------------------+
要验证你的数据表是按你所希望的那样创建的话,可以使用DESCRIBE语句。
mysql> DESCRIBE pet;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
你可以在任何时候使用DESCRIBE,比如,当你忘了表的列名或类型时。
想了解更多关于MySQL数据类型的信息的话,详见章节11,数据类型。
加载数据到数据表
创建好数据表之后,你需要填充它。可以使用LOAD DATA和 INSERT语句。
假设你的宠物记录长如下这个样子。(可以看到,MySQL的日期格式为 ‘YYYY-MM-DD’,这可能和你的习惯不太一样。)
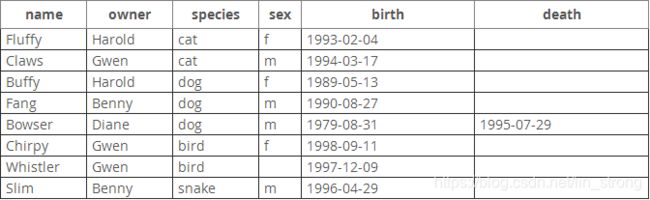
由于一开始是一张空的表,填充它的最一个简单的方法是创建一个文本文件,在其中为你的每一个动物创建一行,然后用单条语句加载文件的内容到数据表中。
你可以创建一个pet.txt文件,文件中每个记录一行,每个值用tab键分隔,以CREATE TABLE语句中给出的列顺序放置。对于丢失的值(比如未知性别或还活着的动物不知死亡日期),你可以使用NULL值。在文本文件中表示NULL值时,使用 \N(反斜杠,大写的N)。比如,Whistler这只鸟的记录看起来像这样(值之间的空格是单个tab字符):
Whistler Gwen bird \N 1997-12-09 \N
为了加载文本文件pet.txt到pet数据表中,使用这条语句:
mysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet;
如果你是在Windows上创建的文件,编辑器很可能使用 ‘\r\n’ 作为行的结束,如果是这样的话,你应该使用这条语句:
mysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet LINES TERMINATED BY '\r\n';
(在运行macOS系统的苹果设备上,很可能是使用 ‘\r’ 作为行的结束。)
如果你想要的话,你可以在LOAD DATA语句中明确地指定列值分隔符和行结束符,但是默认值是tab和 \n。这些足够语句合适地读取pet.txt文件了。
如果语句执行失败了,很可能你的MySQL配置默认不启用本地文件功能。详见 章节 6.1.6,“LOAD DATA LOCAL的安全问题” 以解决这个问题。
当你想要一条条地添加记录时,INSERT语句就特别有用了。在它的最简单形式中,你为每一个列提供对应值,按照CREATE TABLE语句中给出的列的顺序。假设Diane得到了一个新仓鼠,名叫“Puffball”。你可以像这样使用一条INSERT语句来添加一条新纪录:
mysql> INSERT INTO pet VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
这里,字符串和日期的值使用引号引起来的字符串给出。同样的,在INSERT语句中,你可以直接插入NULL来代表一个丢失的值。不像在使用LOAD DATA时使用 \N。
从这个例子中,你可以看出,使用许多INSERT语句会比使用单条LOAD DATA语句要多打好多字。
从数据表中提取信息
SELECT语句用于从数据表中拉取信息。这个语句的通常形式是:
SELECT what_to_select
FROM which_table
WHERE conditions_to_satisfy;
what_to_select指定你想要看什么。可以是列的清单,或者使用 * 指定“所有列”。which_table指定你想要从哪个表提取数据。WHERE短句是可选的。如果给出了的话,conditions_to_satisfy用于指定行要满足的一个或多个条件以筛选或检索。
选择所有数据
最简单形式的SELECT从一个数据表中提取所有东西:
mysql> SELECT * FROM pet;
+----------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+--------+---------+------+------------+------------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Fang | Benny | dog | m | 1990-08-27 | NULL |
| Bowser | Diane | dog | m | 1979-08-31 | 1995-07-29 |
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
| Slim | Benny | snake | m | 1996-04-29 | NULL |
| Puffball | Diane | hamster | f | 1999-03-30 | NULL |
+----------+--------+---------+------+------------+------------+
当你想要看看整个表,比如当你刚装载最初的数据集时,这个形式的SELECT十分有用。比如,你可能突然想到Bowser的生日看起来不对。查阅最初的文件后,你发现正确的出生年份应该是1989而不是1979。
有至少两个方法修复它:
- 编辑文件pet.txt来改正错误,然后清空数据表后再加载它,使用DELETE和LOAD DATA:
mysql> DELETE FROM pet;
mysql> LOAD DATA LOCAL INFILE 'pet.txt' INTO TABLE pet;
然而如果你这样做了,你就必须重新输入Puffball的记录。
- 使用UPDATE语句来仅仅修复错误的记录:
UPDATE pet SET birth = '1989-08-31' WHERE name = 'Bowser';
UPDATE仅仅修改有问题的记录,不需要你重新加载整个表。
选择特定的行
如前面部分所示,提取整张表特别简单。只要忽略SELECT语句的WHERE短句就好。但是典型情况下你不会想要看到整张表,特别是当它变的很大后。你通常会更想回答一个特定的问题,这种情况下你会指定一些你想要的约束。让我们看看一些能够回答的关于你的宠物的选择问题。
你可以选择选择你表格中的特定行。比如,如果你想要确认下你对Bowser的生日的修改,可以像这样选择Bowser的记录:
mysql> SELECT * FROM pet WHERE name = 'Bowser';
+--------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+-------+---------+------+------------+------------+
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+-------+---------+------+------------+------------+
这个输出确认了被正确地记录为1989而不是1979了。
字符串比较通常是大小写不敏感的,所以你可以指定名字为 ‘bowser’ 、‘BOWSER’ 之类的。查询结果是一样的。
你可以对任何列指定条件,不见得是name。比如,如果你想要知道哪些动物是在1998及以后出生的,测试birth列:
mysql> SELECT * FROM pet WHERE birth >= '1998-1-1';
+----------+-------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+-------+
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Puffball | Diane | hamster | f | 1999-03-30 | NULL |
+----------+-------+---------+------+------------+-------+
你可以结合多个条件,比如,定位到雌性的狗:
mysql> SELECT * FROM pet WHERE species = 'dog' AND sex = 'f';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
前面的查询使用了AND逻辑运算符。还有一个OR运算符:
mysql> SELECT * FROM pet WHERE species = 'snake' OR species = 'bird';
+----------+-------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+-------+
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
| Slim | Benny | snake | m | 1996-04-29 | NULL |
+----------+-------+---------+------+------------+-------+
AND和OR是可以混用的,尽管AND比OR有更高的优先级。如果你同时使用两个运算符,建议使用括号来明确地表达出条件的组合方式:
mysql> SELECT * FROM pet WHERE (species = 'cat' AND sex = 'm')
OR (species = 'dog' AND sex = 'f');
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
选择特定的列
如果你不想看到你的表格的整个行,那就列出你感兴趣的列,用逗号分隔。比如,如果你想要知道你的动物是什么时候生的,那就选择name和birth列:
mysql> SELECT name, birth FROM pet;
+----------+------------+
| name | birth |
+----------+------------+
| Fluffy | 1993-02-04 |
| Claws | 1994-03-17 |
| Buffy | 1989-05-13 |
| Fang | 1990-08-27 |
| Bowser | 1989-08-31 |
| Chirpy | 1998-09-11 |
| Whistler | 1997-12-09 |
| Slim | 1996-04-29 |
| Puffball | 1999-03-30 |
+----------+------------+
为了搞明白谁拥有宠物,使用这个查询:
mysql> SELECT owner FROM pet;
+--------+
| owner |
+--------+
| Harold |
| Gwen |
| Harold |
| Benny |
| Diane |
| Gwen |
| Gwen |
| Benny |
| Diane |
+--------+
你可以注意到,这个查询只是简单地从每个记录中提取出owner列,其中有一些值出现了超过一次。为了最小化输出,通过添加关键字DISTINCT来消除重复的输出记录。
mysql> SELECT DISTINCT owner FROM pet;
+--------+
| owner |
+--------+
| Benny |
| Diane |
| Gwen |
| Harold |
+--------+
你可以使用WHERE短句来结合行选择与列选择。比如,为了只得到狗和猫的出生日期,使用这个查询:
mysql> SELECT name, species, birth FROM pet
WHERE species = 'dog' OR species = 'cat';
+--------+---------+------------+
| name | species | birth |
+--------+---------+------------+
| Fluffy | cat | 1993-02-04 |
| Claws | cat | 1994-03-17 |
| Buffy | dog | 1989-05-13 |
| Fang | dog | 1990-08-27 |
| Bowser | dog | 1989-08-31 |
+--------+---------+------------+
为行排序
你也许已经注意到了,在前面的例子中,结果行以非特定的顺序展示。通常当查询输出的行以某些有意义的方式排序的时候,会更加容易检查。为了排序结果,使用ORDER BY短句
这个例子是动物的生日,以日期来排序:
mysql> SELECT name, birth FROM pet ORDER BY birth;
+----------+------------+
| name | birth |
+----------+------------+
| Buffy | 1989-05-13 |
| Bowser | 1989-08-31 |
| Fang | 1990-08-27 |
| Fluffy | 1993-02-04 |
| Claws | 1994-03-17 |
| Slim | 1996-04-29 |
| Whistler | 1997-12-09 |
| Chirpy | 1998-09-11 |
| Puffball | 1999-03-30 |
+----------+------------+
在字符类型的列上进行的排序—如同其他比较操作—通常是以大小写不敏感的方式进行的。这意味着,当被排序的项的值不看大小写完全一样的话,它们的顺序是未定义的。你可以通过使用BINARY来强制进行大小写敏感的排序,像这样:ORDER BY BINARY col_name。
默认是升序排列,即越小的值排越前面。要以相反的顺序(降序)排序的话,在你用于排序的列名后加上DESC关键字:
mysql> SELECT name, birth FROM pet ORDER BY birth DESC;
+----------+------------+
| name | birth |
+----------+------------+
| Puffball | 1999-03-30 |
| Chirpy | 1998-09-11 |
| Whistler | 1997-12-09 |
| Slim | 1996-04-29 |
| Claws | 1994-03-17 |
| Fluffy | 1993-02-04 |
| Fang | 1990-08-27 |
| Bowser | 1989-08-31 |
| Buffy | 1989-05-13 |
+----------+------------+
你可以在多个列上进行排序,并且你可以以不同的方向排序不同的列。比如,要先以升序排序动物的类型,然后在同个动物类型内以降序排序出生日期(越年轻的动物放越前面),使用以下查询:
mysql> SELECT name, species, birth FROM pet
ORDER BY species, birth DESC;
+----------+---------+------------+
| name | species | birth |
+----------+---------+------------+
| Chirpy | bird | 1998-09-11 |
| Whistler | bird | 1997-12-09 |
| Claws | cat | 1994-03-17 |
| Fluffy | cat | 1993-02-04 |
| Fang | dog | 1990-08-27 |
| Bowser | dog | 1989-08-31 |
| Buffy | dog | 1989-05-13 |
| Puffball | hamster | 1999-03-30 |
| Slim | snake | 1996-04-29 |
+----------+---------+------------+
DESC关键字只应用于直接从属的那个列名(birth);它不影响species列的排序。
日期计算
MySQL提供了许多你可以用于日期计算的功能,比如,计算年龄或提取日期的某部分。
为了算出每个宠物有多少岁,使用TIMESTAMPDIFF()功能。它的参数是:你希望结果以什么单位返回,要做差值计算的两个日期。以下演示了,查询每个宠物的生日、当前日期和按年份表示的年龄。使用了 别名(age) 来让最终输出的列标签更加有意义。
mysql> SELECT name, birth, CURDATE(),
TIMESTAMPDIFF(YEAR,birth,CURDATE()) AS age
FROM pet;
+----------+------------+------------+------+
| name | birth | CURDATE() | age |
+----------+------------+------------+------+
| Fluffy | 1993-02-04 | 2003-08-19 | 10 |
| Claws | 1994-03-17 | 2003-08-19 | 9 |
| Buffy | 1989-05-13 | 2003-08-19 | 14 |
| Fang | 1990-08-27 | 2003-08-19 | 12 |
| Bowser | 1989-08-31 | 2003-08-19 | 13 |
| Chirpy | 1998-09-11 | 2003-08-19 | 4 |
| Whistler | 1997-12-09 | 2003-08-19 | 5 |
| Slim | 1996-04-29 | 2003-08-19 | 7 |
| Puffball | 1999-03-30 | 2003-08-19 | 4 |
+----------+------------+------------+------+
查询起了作用,但是如果排了序,输出结果就可以看起来更舒服些。这可以通过添加一个 ORDER BY name 短句来以名字排序结果。
mysql> SELECT name, birth, CURDATE(),
TIMESTAMPDIFF(YEAR,birth,CURDATE()) AS age
FROM pet ORDER BY name;
+----------+------------+------------+------+
| name | birth | CURDATE() | age |
+----------+------------+------------+------+
| Bowser | 1989-08-31 | 2003-08-19 | 13 |
| Buffy | 1989-05-13 | 2003-08-19 | 14 |
| Chirpy | 1998-09-11 | 2003-08-19 | 4 |
| Claws | 1994-03-17 | 2003-08-19 | 9 |
| Fang | 1990-08-27 | 2003-08-19 | 12 |
| Fluffy | 1993-02-04 | 2003-08-19 | 10 |
| Puffball | 1999-03-30 | 2003-08-19 | 4 |
| Slim | 1996-04-29 | 2003-08-19 | 7 |
| Whistler | 1997-12-09 | 2003-08-19 | 5 |
+----------+------------+------------+------+
想要使用age而不是name来排序输出结果的话,改一下ORDER BY短句就好:
mysql> SELECT name, birth, CURDATE(),
TIMESTAMPDIFF(YEAR,birth,CURDATE()) AS age
FROM pet ORDER BY age;
+----------+------------+------------+------+
| name | birth | CURDATE() | age |
+----------+------------+------------+------+
| Chirpy | 1998-09-11 | 2003-08-19 | 4 |
| Puffball | 1999-03-30 | 2003-08-19 | 4 |
| Whistler | 1997-12-09 | 2003-08-19 | 5 |
| Slim | 1996-04-29 | 2003-08-19 | 7 |
| Claws | 1994-03-17 | 2003-08-19 | 9 |
| Fluffy | 1993-02-04 | 2003-08-19 | 10 |
| Fang | 1990-08-27 | 2003-08-19 | 12 |
| Bowser | 1989-08-31 | 2003-08-19 | 13 |
| Buffy | 1989-05-13 | 2003-08-19 | 14 |
+----------+------------+------------+------+
可以用一个类似的查询来确定已死动物的寿命。你通过检查death的值是否是NULL来确定哪些动物死了。然后,对于那些是非NULL值的,计算death与birth之间的差值:
mysql> SELECT name, birth, death,
TIMESTAMPDIFF(YEAR,birth,death) AS age
FROM pet WHERE death IS NOT NULL ORDER BY age;
+--------+------------+------------+------+
| name | birth | death | age |
+--------+------------+------------+------+
| Bowser | 1989-08-31 | 1995-07-29 | 5 |
+--------+------------+------------+------+
这个查询写的是death IS NOT NULL而不是death <> NULL,这是由于NULL是一个特殊值,不能使用通常的比较运算符来比较。在后面会讨论这事。见章节3.3.4.6,“处理NULL值”。
那如果你想要知道哪一个动物在下一个月生日呢?对于这类计算,年和日是无关紧要的;你仅仅想要提取birth列的月份部分。MySQL提供了许多用来提取日期某部分的函数,如YEAR()、MONTH()和DAYOFMONTH()。MONTH() 适用于现在的需求。为了看看它是怎么工作的,运行一个简单的查询来展示birth和MONTH(birth)的值。
mysql> SELECT name, birth, MONTH(birth) FROM pet;
+----------+------------+--------------+
| name | birth | MONTH(birth) |
+----------+------------+--------------+
| Fluffy | 1993-02-04 | 2 |
| Claws | 1994-03-17 | 3 |
| Buffy | 1989-05-13 | 5 |
| Fang | 1990-08-27 | 8 |
| Bowser | 1989-08-31 | 8 |
| Chirpy | 1998-09-11 | 9 |
| Whistler | 1997-12-09 | 12 |
| Slim | 1996-04-29 | 4 |
| Puffball | 1999-03-30 | 3 |
+----------+------------+--------------+
查找次月生日的动物也很简单。建设当前是四月。month值就是4,你可以像这样查询出生在五月的动物:
mysql> SELECT name, birth FROM pet WHERE MONTH(birth) = 5;
+-------+------------+
| name | birth |
+-------+------------+
| Buffy | 1989-05-13 |
+-------+------------+
如果当前月份是十二月的话会稍微复杂点。你不能仅仅加一到月份数字(12)上,这样是在查询出生在13月的动物,根本就没有这个月份。你应该查询出生在一月的动物。
你可以写一个无论当前是几月都能正常工作的查询。 DATE_ADD()使你能够在给定日期上增加一个时间间隔。如果你在CURDATE()的值上增加一个月,然后使用MONTH()提取月份部分,就能得到需要的月份:
mysql> SELECT name, birth FROM pet
WHERE MONTH(birth) = MONTH(DATE_ADD(CURDATE(),INTERVAL 1 MONTH));
另一种完成同样任务的方法是先对当前月份使用取模函数(MOD)来当月份为12月时变为0,然后直接加1:
mysql> SELECT name, birth FROM pet
WHERE MONTH(birth) = MOD(MONTH(CURDATE()), 12) + 1;
MONTH()返回一个1到12间的数字。 MOD(something,12)返回一个0到11间的数字。所以加号得在 MOD()后面,否则我们会得到11月到1月。
如果计算中使用了无效的月份,计算会失败并产生警告:
mysql> SELECT '2018-10-31' + INTERVAL 1 DAY;
+-------------------------------+
| '2018-10-31' + INTERVAL 1 DAY |
+-------------------------------+
| 2018-11-01 |
+-------------------------------+
mysql> SELECT '2018-10-32' + INTERVAL 1 DAY;
+-------------------------------+
| '2018-10-32' + INTERVAL 1 DAY |
+-------------------------------+
| NULL |
+-------------------------------+
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------+
| Warning | 1292 | Incorrect datetime value: '2018-10-32' |
+---------+------+----------------------------------------+
处理NULL值
在你掌握它之前,NULL可能会带给你惊吓。概念上,NULL指的是“一个丢失的未知值”,它相对于其他值有着特殊的待遇。
为了测试NULL,使用 IS NULL和 IS NOT NULL操作符,如下所示:
mysql> SELECT 1 IS NULL, 1 IS NOT NULL;
+-----------+---------------+
| 1 IS NULL | 1 IS NOT NULL |
+-----------+---------------+
| 0 | 1 |
+-----------+---------------+
你不能使用如 =或<或<>这样的算术比较运算符来测试NULL。要验证的话,试试以下查询:
mysql> SELECT 1 = NULL, 1 <> NULL, 1 < NULL, 1 > NULL;
+----------+-----------+----------+----------+
| 1 = NULL | 1 <> NULL | 1 < NULL | 1 > NULL |
+----------+-----------+----------+----------+
| NULL | NULL | NULL | NULL |
+----------+-----------+----------+----------+
由于对NULL进行任何算术比较的结果还是NULL,你不能从这样的比较中获得任何有意义的结果。
在MySQL中,0或NULL的意思是假,任何其他东西都是真。布尔运算符的默认真值是1。
NULL的特殊待遇就是为什么在前面的部分中,需要使用death IS NOT NULL而不是death <> NULL来确定哪一个动物已经去世了。
在GROUP BY中,两个NULL值被认为相等。
当在进行ORDER BY时,如果你使用的是ORDER BY … ASC,NULL值被排在最前面,而ORDER BY … DESC则反之。
处理NULL时的一个常见的错误是以为不可能插入0或空字符串到一个定义为NOT NULL的列中,但其实是可以的。它们实际上是值,而NULL的意思是“没有值”。你可以如下这样使用IS [NOT] NULL来验证这事:
mysql> SELECT 0 IS NULL, 0 IS NOT NULL, '' IS NULL, '' IS NOT NULL;
+-----------+---------------+------------+----------------+
| 0 IS NULL | 0 IS NOT NULL | '' IS NULL | '' IS NOT NULL |
+-----------+---------------+------------+----------------+
| 0 | 1 | 0 | 1 |
+-----------+---------------+------------+----------------+
因此完全可能插入0或空字符串到一个NOT NULL列中,因为它们实际上NOT NULL。见章节 B.4.4.3,“NULL值的问题”。
模式匹配
MySQL提供标准SQL模式匹配,以及一种基于扩展的正则表达式的模式匹配形式,类似于Unix工具vi、grep和sed中使用的那些。
SQL模式匹配 使你能够使用 _ 来匹配任何单个字符,使用 % 来匹配任意数量的字符(包括没有字符)。在MySQL中,SQL模式默认是大小写不敏感的。这里展示了一些例子。当你使用SQL模式时,别使用 = 或者 <>。使用LIKE或NOT LIKE比较运算符来替代它们。
要找到名字以b开头的:
mysql> SELECT * FROM pet WHERE name LIKE 'b%';
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
要找到名字以fy结尾的:
mysql> SELECT * FROM pet WHERE name LIKE '%fy';
+--------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+-------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+--------+--------+---------+------+------------+-------+
要找到名字包含w的:
mysql> SELECT * FROM pet WHERE name LIKE '%w%';
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
要找到名字包含正好五个字符的,使用五个 _ 模式字符就好:
mysql> SELECT * FROM pet WHERE name LIKE '_____';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
MySQL提供的另一个类型的模式匹配使用了扩展的正则表达式。当你要匹配这种类型的模式时,使用REGEXP_LIKE() 函数(或者REGEXP 或RLIKE运算符,它们是REGEXP_LIKE() 的同义词)。
下面列出了扩展的正则表达式的一些特性:
- . 匹配所有单字符。
- 一个字符类 […] 匹配括号中的任何字符。比如,[abc] 匹配 a、b或c。要表明一个字符范围,使用扩折号。[a-z] 匹配任意字母,而 [0-9] 匹配任意数字。
- *匹配0或任意个前面的东西。比如,x* 匹配任意数量的x字符,[0-9]*匹配任意数量的数字, .*匹配任意数量的任何东西。
- 如果被测试的值有任意部分匹配,那正则表达式就匹配成功。(这和LIKE模式匹配不同,在LIKE模式匹配中,只有当整个值都匹配了才成功。)
- 如要锚定一个模式,也就是必须匹配开头或结尾的话,要在模式的开头使用 ^ 或在结尾使用 $。
为了示范扩展的正则表达式的工作方式,我们把先前的LIKE查询使用REGEXP_LIKE()重写一遍。
要找到名字以b开头的,使用 ^ 来匹配名字的开头:
mysql> SELECT * FROM pet WHERE REGEXP_LIKE(name, '^b');
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1979-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
为了强迫一个正则表达式大小写敏感,要使用一个大小写敏感collation,或使用BINARY关键字来使得其中一个字符串为二进制字符串,或者指定c模式控制字符。这些每一个查询都只匹配名字开头是小写字母b的:
SELECT * FROM pet WHERE REGEXP_LIKE(name, '^b' COLLATE utf8mb4_0900_as_cs);
SELECT * FROM pet WHERE REGEXP_LIKE(name, BINARY '^b');
SELECT * FROM pet WHERE REGEXP_LIKE(name, '^b', 'c');
要找到名字包含w的,使用这个查询:
mysql> SELECT * FROM pet WHERE REGEXP_LIKE(name, 'w');
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
由于正则表达式只要在值中任意位置出现就会匹配,在上面的查询中不需要像SQL模式中一样在模式的两边放通配符。
要找到名字包含正好五个字符的,使用 ^ 和 $ 来匹配名字的开头和结尾,中间再放五个 . 就好:
mysql> SELECT * FROM pet WHERE REGEXP_LIKE(name, '^.....$');
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
你也可以使用 {n} (“重复n次”)操作符来重写前面的查询:
mysql> SELECT * FROM pet WHERE REGEXP_LIKE(name, '^.{5}$');
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
要查看关于正则表达式的更多语法信息,见章节 12.7.2,“正则表达式”。
统计行数
数据库经常要回答这样一个问题,“某个表中的某个特定类型数据出现了多少次?”例如,你可能想要知道你有多少宠物,或者每个主人有多少宠物,或者你也许想要对你的宠物进行多种类型的普查。
统计你有多少宠物等价于问题“pet表中有多少行?”,因为每个宠物有一行记录。COUNT(*)统计行数,所以统计你的宠物的查询长这个样子:
mysql> SELECT COUNT(*) FROM pet;
+----------+
| COUNT(*) |
+----------+
| 9 |
+----------+
前面你查询过拥有宠物的人的名字。如果你想要看看每个主人有多少只宠物,也可以使用COUNT(*):
mysql> SELECT owner, COUNT(*) FROM pet GROUP BY owner;
+--------+----------+
| owner | COUNT(*) |
+--------+----------+
| Benny | 2 |
| Diane | 2 |
| Gwen | 3 |
| Harold | 2 |
+--------+----------+
上面的查询使用了GROUP BY来为每个owner分组记录。联合使用COUNT(*)与GROUP BY有助于你分析多分组数据的特性。下面的例子展示了其他进行动物普查的方法。
每种物种的动物数量:
mysql> SELECT species, COUNT(*) FROM pet GROUP BY species;
+---------+----------+
| species | COUNT(*) |
+---------+----------+
| bird | 2 |
| cat | 2 |
| dog | 3 |
| hamster | 1 |
| snake | 1 |
+---------+----------+
每个性别的动物数量:
mysql> SELECT sex, COUNT(*) FROM pet GROUP BY sex;
+------+----------+
| sex | COUNT(*) |
+------+----------+
| NULL | 1 |
| f | 4 |
| m | 4 |
+------+----------+
(在这个输出中,NULL表示性别未知的。)
每个动物加性别的动物数量:
mysql> SELECT species, sex, COUNT(*) FROM pet GROUP BY species, sex;
+---------+------+----------+
| species | sex | COUNT(*) |
+---------+------+----------+
| bird | NULL | 1 |
| bird | f | 1 |
| cat | f | 1 |
| cat | m | 1 |
| dog | f | 1 |
| dog | m | 2 |
| hamster | f | 1 |
| snake | m | 1 |
+---------+------+----------+
当你使用COUNT(*)时你不需要提取整个表。比如,在前面的查询中,如果只查询狗和猫的话,就像这样:
mysql> SELECT species, sex, COUNT(*) FROM pet
WHERE species = 'dog' OR species = 'cat'
GROUP BY species, sex;
+---------+------+----------+
| species | sex | COUNT(*) |
+---------+------+----------+
| cat | f | 1 |
| cat | m | 1 |
| dog | f | 1 |
| dog | m | 2 |
+---------+------+----------+
或者,如果你只想查询那些性别已知的动物的每种性别的数量:
mysql> SELECT species, sex, COUNT(*) FROM pet
WHERE sex IS NOT NULL
GROUP BY species, sex;
+---------+------+----------+
| species | sex | COUNT(*) |
+---------+------+----------+
| bird | f | 1 |
| cat | f | 1 |
| cat | m | 1 |
| dog | f | 1 |
| dog | m | 2 |
| hamster | f | 1 |
| snake | m | 1 |
+---------+------+----------+
如果你在select COUNT(*)值时加上了其他列,则必须在后面的GROUP BY短句中给出那些列,否则会发生以下事情:
- 如果启用了ONLY_FULL_GROUP_BY SQL模式,会发生一个错误:
mysql> SET sql_mode = 'ONLY_FULL_GROUP_BY';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT owner, COUNT(*) FROM pet;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression
#1 of SELECT list contains nonaggregated column 'menagerie.pet.owner';
this is incompatible with sql_mode=only_full_group_by
- 如果未启用ONLY_FULL_GROUP_BY,查询会将所有行都当做一个分组,但是每个列给的值是不确定的。服务器可以从任意行提取值:
mysql> SET sql_mode = '';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT owner, COUNT(*) FROM pet;
+--------+----------+
| owner | COUNT(*) |
+--------+----------+
| Harold | 8 |
+--------+----------+
1 row in set (0.00 sec)
同样看看章节 12.20.3,“MySQL对GROUP BY的处理”。要查阅更多关于COUNT(expr)行为以及相关优化的信息,见章节12.20.1,“聚合(GROUP BY)函数描述”。
使用不止一个表
pet表维护你拥有的宠物的信息。如果你想要记录更多关于它们的信息,比如有生之年发生的重大事件,像有人来看某宠物啦或者啥时候哪个宠物产仔了,你将会需要另一张表。这张表应该长什么样子呢?它应该包含以下信息:
- 宠物名,这样你才能知道每个事件是哪个宠物的。
- 日期,这样就知道事件的发生时间
- 一个描述事件的字段
- 一个事件类型字段,如果你想要能够标识事件的话。
因此,event表的 CREATE TABLE语句可能长这个样子:
mysql> CREATE TABLE event (name VARCHAR(20), date DATE,
type VARCHAR(15), remark VARCHAR(255));
我们准备好pet表后,最简单的加载初始表的方法就是创建一个包含以下信息的,用tab分隔符的文本文件。
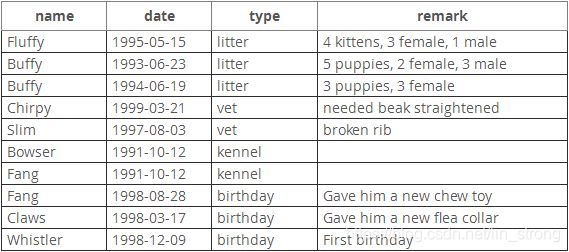
像这样加载记录:
mysql> LOAD DATA LOCAL INFILE 'event.txt' INTO TABLE event;
基于你已经在pet表上学习到的那些查询语句,你应该会提取event表中的记录了,原则上是一样的。但是有时候光靠一个event表是不够回答你想要知道的问题的。
假设你想知道每只宠物的产仔年龄。我们在前面已经学习过了怎么根据两个日期计算年龄。母亲的产仔日期在event表中,但是要计算她在产仔日期时的年龄,你需要它的出生日期,而出生日期存储在pet表中。也就是说这个查询需要同时用到两个表:
mysql> SELECT pet.name,
TIMESTAMPDIFF(YEAR,birth,date) AS age,
remark
FROM pet INNER JOIN event
ON pet.name = event.name
WHERE event.type = 'litter';
+--------+------+-----------------------------+
| name | age | remark |
+--------+------+-----------------------------+
| Fluffy | 2 | 4 kittens, 3 female, 1 male |
| Buffy | 4 | 5 puppies, 2 female, 3 male |
| Buffy | 5 | 3 puppies, 3 female |
+--------+------+-----------------------------+
这条查询有以下知识点:
- FROM短句联合了两个表,因为查询需要从两个表中一起拉取信息。
- 当要结合(联合)多个表的信息时, 你需要指定一个表中的记录要怎么匹配另一个表中的。这很简单,它们都有一个name列。这个查询使用ON短句来基于name的值来匹配两个表中的记录。
这个查询使用一个INNER JOIN来结合表。INNER JOIN使得当且仅当当两个表中的行都满足ON短句中指定的条件时,才会出现在结果中。在这个例子中,ON短句指定pet表中的name列必须匹配event表中的name表。如果一个名字出现在了一个表中,但没出现在另一张表中,行就不会出现在结果中,因为ON短句中的条件失败了。 - 由于name列同时出现在了两张表中,你必须在指定这个列的时候直接指定是哪个表中的这列。这是通过将表名前缀在列名前实现的。
你不需要使用两个不同的表来执行联合操作。有时,如果你想要比较同一个表中的不同记录时,表自己联合自己也很有用。比如,为了找到你的宠物中的繁殖对,你可以联合pet表自己来找到一对对雌雄都活着的同种类物种:
mysql> SELECT p1.name, p1.sex, p2.name, p2.sex, p1.species
FROM pet AS p1 INNER JOIN pet AS p2
ON p1.species = p2.species
AND p1.sex = 'f' AND p1.death IS NULL
AND p2.sex = 'm' AND p2.death IS NULL;
+--------+------+-------+------+---------+
| name | sex | name | sex | species |
+--------+------+-------+------+---------+
| Fluffy | f | Claws | m | cat |
| Buffy | f | Fang | m | dog |
+--------+------+-------+------+---------+
在这个查询中,我们为表名指定别名以引用列,并保持每个列引用与哪个表实例的关联。
获得关于数据库和数据表的信息
要是你忘记了数据库或数据表的名字,或者忘了某个表的结构呢?(比如,它的列名是啥?)MySQL通过一些提供关于数据库和数据表信息的语句来解决这个问题。
你之前已经见识过了SHOW DATABASES,它会列出服务器管理的数据库。想要搞清楚现在选择的是哪个数据库的话,使用DATABASES()功能:
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| menagerie |
+------------+
如果你还没选择任何数据库,结果是NULL。
为了搞清楚默认数据库包含什么表(比如,当你不确定表的名字时),使用这条语句:
mysql> SHOW TABLES;
+---------------------+
| Tables_in_menagerie |
+---------------------+
| event |
| pet |
+---------------------+
这条语句的输出的列的名字总是Tables_in_db_name,其中db_name是数据库的名字。详见章节 13.7.7.37, “SHOW TABLES语句”。
如果你想要知道一个表的结果, DESCRIBE就很有用了;它会展示一个表每一列的信息:
mysql> DESCRIBE pet;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
Field指明列名,Type是列的数据类型,NULL表明是否这列可以包含NULL值,Key表明是否列被索引了,Default指明列的默认值。Extra展示关于列的特别信息:如果一个列是由AUTO_INCREMENT选项创建的,值会是auto_increment而不是空的。
DESC是DESCRIBE的缩写形式。详见章节13.8.1,“DESCRIBE 语句”。
你可以使用SHOW CREATE TABLE语句来获得获取创建一个现存表的必要的CREATE TABLE语句。详见章节13.7.7.22,“SHOW CREATE TABLE语句”。
如果你在一个表上有索引,SHOW INDEX FROM tbl_name会产生关于它们的信息。详见章节13.7.7.22,“SHOW INDEX 语句”。
以批处理模式使用mysql
在前面的章节中,你交互式地使用mysql,输出语句,然后看到结果。其实也可以以批处理模式使用mysql。要批处理的话,把你想要运行的语句放在一个文件中,然后告诉mysql去从文件中读输入:
shell> mysql < batch-file
如果你是再Windows下运行的mysql,并且文件中有一些会导致问题的特殊字符,你可以这样做:
C:\> mysql -e "source batch-file"
如果你需要在命令行中指定连接参数,命令可能看起来这个样:
shell> mysql -h host -u user -p < batch-file
Enter password: ********
当你用这种方式使用mysql时,你是在创建一个脚本文件,然后执行脚本。
如果你想要脚本即使在一些语句产生错误时仍然继续执行,你应该使用 –force命令行选项。
为什么要使用脚本?这里给出一些原因:
- 如果你要重复性地运行一个查询(每天或每周那样),把它写成一个脚本可以让你省得每次都重新输一遍。
- 你可以通过复制黏贴脚本文件后进行简单的修改,来根据旧的查询改出个新的。
- 当你在开发一个查询,特别是多行语句或多行语句序列时,批处理特有用。如果你出错了,你不需要重新输一遍全部东西。只用编辑下你的脚本文件来修正错误,然后让mysql再次执行它。
- 如果你有一个会产生很多输出的查询,你可以用一个分页程序来查看输出,而不是直接看它从你的屏幕上从头滚动到尾:
shell> mysql < batch-file | more
- 你可以把输出捕获到一个文件中以预备进一步处理:
shell> mysql < batch-file > mysql.out
- 你可以把你的脚本分发给其他人,这样他们也可以运行这些语句。
- 一些场合不允许交互式地使用,比如,当你使用cron(一个定时运行程序)运行一个查询时。在这种情况下,你必须使用批处理模式。
默认输出格式在你以批处理或交互式运行mysql时是不同的,批处理时更简洁。比如,当mysql以交互式运行时,SELECT DISTINCT species FROM pet的输出长这个样子:
+---------+
| species |
+---------+
| bird |
| cat |
| dog |
| hamster |
| snake |
+---------+
在批处理下,输出长这个样:
species
bird
cat
dog
hamster
snake
如果你想要在批处理模式下获得交互式输出格式,使用mysql -t。如果要在输出中回显被执行的语句,使用 mysql -v。
你也可以通过使用source命令或者 \. 命令,在mysql提示符下使用脚本文件:
mysql> source filename;
mysql> \. filename
详见章节 4.5.1.5,“从文本文件中执行SQL语句”。
常见查询的示例
这里是使用MySQL来解决一些常见问题的示例。
一些例子使用shop表来为特定贸易商(经销商)保存每件商品(商品编号)的价格。假设每个贸易商对每个商品都有单个固定的价格,这样(article, dealer)就是记录的主键。
启动命令行工具mysql并选择一个数据库:
shell> mysql your-database-name
要创建和填充示例表,使用这些语句:
CREATE TABLE shop (
article INT UNSIGNED DEFAULT '0000' NOT NULL,
dealer CHAR(20) DEFAULT '' NOT NULL,
price DECIMAL(16,2) DEFAULT '0.00' NOT NULL,
PRIMARY KEY(article, dealer));
INSERT INTO shop VALUES
(1,'A',3.45),(1,'B',3.99),(2,'A',10.99),(3,'B',1.45),
(3,'C',1.69),(3,'D',1.25),(4,'D',19.95);
在提交这些语句后,表应该有以下内容:
SELECT * FROM shop ORDER BY article;
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 1 | A | 3.45 |
| 1 | B | 3.99 |
| 2 | A | 10.99 |
| 3 | B | 1.45 |
| 3 | C | 1.69 |
| 3 | D | 1.25 |
| 4 | D | 19.95 |
+---------+--------+-------+
一个列的最大值
“最大的商品号是多少?”
SELECT MAX(article) AS article FROM shop;
+---------+
| article |
+---------+
| 4 |
+---------+
某列值为最大的行
任务:找到最贵商品的编号、贸易商和价格。
使用子查询可以特轻松的完成这个任务:
SELECT article, dealer, price
FROM shop
WHERE price=(SELECT MAX(price) FROM shop);
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 0004 | D | 19.95 |
+---------+--------+-------+
另一个方案是使用LEFT JOIN,或通过价格降序排列所有行,然后使用MySQL专用的LIMIT短句获得第一行:
SELECT s1.article, s1.dealer, s1.price
FROM shop s1
LEFT JOIN shop s2 ON s1.price < s2.price
WHERE s2.article IS NULL;
SELECT article, dealer, price
FROM shop
ORDER BY price DESC
LIMIT 1;
注意:
如果有多个最贵商品,即每个价格都是19.95,LIMIT方案只会显示其中一个。
每组的最大列
任务:找到每个商品的最高价格。
SELECT article, MAX(price) AS price
FROM shop
GROUP BY article
ORDER BY article;
+---------+-------+
| article | price |
+---------+-------+
| 0001 | 3.99 |
| 0002 | 10.99 |
| 0003 | 1.69 |
| 0004 | 19.95 |
+---------+-------+
包含特定列的组最大值的行
任务:为每件商品找到价格最贵的贸易商(们)
这个问题可以使用像这样的子查询来解决:
SELECT article, dealer, price
FROM shop s1
WHERE price=(SELECT MAX(s2.price)
FROM shop s2
WHERE s1.article = s2.article)
ORDER BY article;
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 0001 | B | 3.99 |
| 0002 | A | 10.99 |
| 0003 | C | 1.69 |
| 0004 | D | 19.95 |
+---------+--------+-------+
前面的例子使用了一个相关子查询,这可能效率很低(见章节13.2.11.7, “关联子查询”)。另几种解决这问题的方法是在FROM短句中使用一个不相关子查询、使用LEFT JOIN或使用一个带窗口函数的Common table表达式。
不相关子查询:
SELECT s1.article, dealer, s1.price
FROM shop s1
JOIN (
SELECT article, MAX(price) AS price
FROM shop
GROUP BY article) AS s2
ON s1.article = s2.article AND s1.price = s2.price
ORDER BY article;
LEFT JOIN:
SELECT s1.article, s1.dealer, s1.price
FROM shop s1
LEFT JOIN shop s2 ON s1.article = s2.article AND s1.price < s2.price
WHERE s2.article IS NULL
ORDER BY s1.article;
LEFT JOIN方案的工作原理是当s1.price是最大值时,s2.price中没有更大值,因此对应的s2.article值为NULL。见章节13.2.10.2,“JOIN短句”。
带窗口函数的Common table表达式:
WITH s1 AS (
SELECT article, dealer, price,
RANK() OVER (PARTITION BY article
ORDER BY price DESC
) AS `Rank`
FROM shop
)
SELECT article, dealer, price
FROM s1
WHERE `Rank` = 1
ORDER BY article;
使用用户定义的变量
你可以使用MySQL用户变量来记住结果,这样就不用将它们存储在客户端上的临时变量中了(见 章节9.4,“用户定义变量”)。
例如,为了找到价格最高与最低的商品,你可以这样做:
mysql> SELECT @min_price:=MIN(price),@max_price:=MAX(price) FROM shop;
mysql> SELECT * FROM shop WHERE price=@min_price OR price=@max_price;
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 0003 | D | 1.25 |
| 0004 | D | 19.95 |
+---------+--------+-------+
注意:
可以在用户变量中存储数据库对象,如表或列,的名字,然后在SQL语句中使用它们;但是这要求使用一条prepared statement。详见 章节13.5,“prepared statement”。
使用外键
在MySQL中,InnoDB表支持检查外键约束。见章节15,InnoDB存储引擎,和章节1.8.2.3,“FOREIGN KEY约束差异”。
连接两个表并不需要有外键约束。对于InnoDB外的存储引擎,是有可能使用REFERENCES tbl_name(col_name)短句来定义一个列的,该短句没有实际效果,仅用作备注或注释,表明你当前定义的列要引用另一个表中的列的。当使用这个语法时,一定要意识到:
- MySQL不会执行任何形式的检查来保证col_name确实存在在tbl_name中(甚至tbl_name本身是否存在都不检查)。
- MySQL不会对tbl_name执行任何,如当你在你正定义的这个表上做某些事情时删除对应行,的行为;换句话说,这个句法不会导致任何ON DELETE或ON UPDATE行为。(尽管你可以在REFERENCES短句中带上ON DELETE或ON UPDATE短句,但它们会被忽略)。
- 这个语法会创建一个列;它不会创建任何类型的索引或键。
你可以使用这样创建的列作为联接列:
CREATE TABLE person (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
name CHAR(60) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE shirt (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
style ENUM('t-shirt', 'polo', 'dress') NOT NULL,
color ENUM('red', 'blue', 'orange', 'white', 'black') NOT NULL,
owner SMALLINT UNSIGNED NOT NULL REFERENCES person(id),
PRIMARY KEY (id)
);
INSERT INTO person VALUES (NULL, 'Antonio Paz');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', @last),
(NULL, 'dress', 'white', @last),
(NULL, 't-shirt', 'blue', @last);
INSERT INTO person VALUES (NULL, 'Lilliana Angelovska');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'dress', 'orange', @last),
(NULL, 'polo', 'red', @last),
(NULL, 'dress', 'blue', @last),
(NULL, 't-shirt', 'white', @last);
SELECT * FROM person;
+----+---------------------+
| id | name |
+----+---------------------+
| 1 | Antonio Paz |
| 2 | Lilliana Angelovska |
+----+---------------------+
SELECT * FROM shirt;
+----+---------+--------+-------+
| id | style | color | owner |
+----+---------+--------+-------+
| 1 | polo | blue | 1 |
| 2 | dress | white | 1 |
| 3 | t-shirt | blue | 1 |
| 4 | dress | orange | 2 |
| 5 | polo | red | 2 |
| 6 | dress | blue | 2 |
| 7 | t-shirt | white | 2 |
+----+---------+--------+-------+
SELECT s.* FROM person p INNER JOIN shirt s
ON s.owner = p.id
WHERE p.name LIKE 'Lilliana%'
AND s.color <> 'white';
+----+-------+--------+-------+
| id | style | color | owner |
+----+-------+--------+-------+
| 4 | dress | orange | 2 |
| 5 | polo | red | 2 |
| 6 | dress | blue | 2 |
+----+-------+--------+-------+
当以这种风格使用时,REFERENCES短句不会展示在SHOW CREATE TABLE或DESCRIBE的输出中:
SHOW CREATE TABLE shirt\G
*************************** 1. row ***************************
Table: shirt
Create Table: CREATE TABLE `shirt` (
`id` smallint(5) unsigned NOT NULL auto_increment,
`style` enum('t-shirt','polo','dress') NOT NULL,
`color` enum('red','blue','orange','white','black') NOT NULL,
`owner` smallint(5) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4
MyISAM表中也可以以这种方式在一个列定义中使用REFERENCES作为注释或“备忘录”。
在两个键上搜索
使用单个键的OR是良好优化的,就像处理AND时那样。
棘手的是使用OR来搜索两个不同的键的情况:
SELECT field1_index, field2_index FROM test_table
WHERE field1_index = '1' OR field2_index = '1'
上例会被优化。见章节8.2.1.3,“索引合并优化”。
你也可以通过使用一个UNION结合两个独立的SELECT语句输出来高效地解决这个问题。见章节13.2.10.3,“UNION短句”。
每个SELECT都只搜索一个键,可以被优化:
SELECT field1_index, field2_index
FROM test_table WHERE field1_index = '1'
UNION
SELECT field1_index, field2_index
FROM test_table WHERE field2_index = '1';
计算每天的访问量
下面示例了怎么使用位组函数来计算某用户每个月有多少天访问了一个网页。
CREATE TABLE t1 (year YEAR, month INT UNSIGNED,
day INT UNSIGNED);
INSERT INTO t1 VALUES(2000,1,1),(2000,1,20),(2000,1,30),(2000,2,2),
(2000,2,23),(2000,2,23);
示例表包含年月日值,每个都代表用户在那天访问了网页。为了确定每个月发生了多少非同天的访问,使用以下查询:
SELECT year,month,BIT_COUNT(BIT_OR(1<<day)) AS days FROM t1
GROUP BY year,month;
它会返回:
+------+-------+------+
| year | month | days |
+------+-------+------+
| 2000 | 1 | 3 |
| 2000 | 2 | 2 |
+------+-------+------+
这个查询计算了每个年月有多少不同的天出现在了表中,自动移除了冗余项。
使用AUTO_INCREMENT
AUTO_INCREMENT属性可以用于为新行生成一个唯一的标识:
CREATE TABLE animals (
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO animals (name) VALUES
('dog'),('cat'),('penguin'),
('lax'),('whale'),('ostrich');
SELECT * FROM animals;
它会返回:
+----+---------+
| id | name |
+----+---------+
| 1 | dog |
| 2 | cat |
| 3 | penguin |
| 4 | lax |
| 5 | whale |
| 6 | ostrich |
+----+---------+
没有给AUTO_INCREMENT列指定值,所以MySQL自动地赋值了序列号。你也可以明确地给这列赋值0来自动生成序列号,除非启用了NO_AUTO_VALUE_ON_ZERO模式。比如:
INSERT INTO animals (id,name) VALUES(0,'groundhog');
如果列声明为NOT NULL,也可以赋值NULL给这列来生成序列号,比如:
INSERT INTO animals (id,name) VALUES(NULL,'squirrel');
当你插入任何其他值到AUTO_INCREMENT列中时,列会设为那个值,序列会被重置,这样,下一个自动生成的值会是最大的列值+1。比如:
INSERT INTO animals (id,name) VALUES(100,'rabbit');
INSERT INTO animals (id,name) VALUES(NULL,'mouse');
SELECT * FROM animals;
+-----+-----------+
| id | name |
+-----+-----------+
| 1 | dog |
| 2 | cat |
| 3 | penguin |
| 4 | lax |
| 5 | whale |
| 6 | ostrich |
| 7 | groundhog |
| 8 | squirrel |
| 100 | rabbit |
| 101 | mouse |
+-----+-----------+
更新一个现有的AUTO_INCREMENT列也会重置AUTO_INCREMENT序列。
你可以使用LAST_INSERT_ID()SQL函数或mysql_insert_id()C API函数来提取最近产生的AUTO_INCREMENT值。这些函数是链接专用的,所以它们的返回值不会受到另一个正在执行插入操作的链接的影响。
为AUTO_INCREMENT列指定足够装下你可能用到的最大序列值的最小整型类型。当列达到数据类型的上限时,下一个产生序列号的尝试会失败。如果可以的话,使用UNSIGNED属性以获得更大的范围。比如,如果你使用了TINYINT,最大的可用序列号是127。而TINYINT UNSIGNED的最大是255。见章节11.1.2,“整数类型(精确值) - INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT, BIGINT” 来获得更多整型范围信息。
注意:
对于一个多行插入,LAST_INSERT_ID()和mysql_insert_id()实际上会返回首个插入行的AUTO_INCREMENT键。这使得在复制配置中,多行插入能够在其他服务器上被正确地重新产生。
为了以一个非1的值开始AUTO_INCREMENT,像这样在CREATE TABLE或ALTER TABLE中设置那个值:
mysql> ALTER TABLE tbl AUTO_INCREMENT = 100;
InnoDB笔记
对于特定于InnoDB的AUTO_INCREMENT用法信息,见章节 15.6.1.6,“InnoDB中的AUTO_INCREMENT处理 ”
MyISAM 笔记
对于MyISAM 表,你可以在一个多列索引中的附属列上指定AUTO_INCREMENT。在这种情况下,AUTO_INCREMENT 列的生成值会按MAX(auto_increment_column) + 1 WHERE prefix=given-prefix计算。这在当你想要把数据放进有序分组中时很有用。
CREATE TABLE animals (
grp ENUM('fish','mammal','bird') NOT NULL,
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (grp,id)
) ENGINE=MyISAM;
INSERT INTO animals (grp,name) VALUES
('mammal','dog'),('mammal','cat'),
('bird','penguin'),('fish','lax'),('mammal','whale'),
('bird','ostrich');
SELECT * FROM animals ORDER BY grp,id;
它会返回:
+--------+----+---------+
| grp | id | name |
+--------+----+---------+
| fish | 1 | lax |
| mammal | 1 | dog |
| mammal | 2 | cat |
| mammal | 3 | whale |
| bird | 1 | penguin |
| bird | 2 | ostrich |
+--------+----+---------+
在这个情况下(当AUTO_INCREMENT列是多列索引的一部分时),如果你删除了任意组中的最大AUTO_INCREMENT值的那行的话,AUTO_INCREMENT值被重用。这甚至在MyISAM表中也会发生,虽然在MyISAM表中通常不会重用AUTO_INCREMENT值。
- 如果AUTO_INCREMENT列是多列索引的一部分,MySQL使用以AUTO_INCREMENT列起始的索引来生成序列,如果有的话。比如,如果animals表包含索引 PRIMARY KEY (grp, id) 和 INDEX (id),MySQL在生成序列值时将忽略PRIMARY KEY。结果,每个表将只包含单个序列,而不是每个grp值各一个。
结合Apache来使用MySQL
有一些程序可以让您从MySQL数据库对用户进行身份验证,还可以让您将日志文件写入MySQL表中。
你可以修改Apache日志格式以使得MySQL可读,只要把以下放进Apache配置文件:
LogFormat \
"\"%h\",%{%Y%m%d%H%M%S}t,%>s,\"%b\",\"%{Content-Type}o\", \
\"%U\",\"%{Referer}i\",\"%{User-Agent}i\""
为了加载那种格式的一个日志文件到MySQL中,你可以使用一条像这样的语句:
LOAD DATA INFILE '/local/access_log' INTO TABLE tbl_name
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\'
应创建命名表,使其列与LogFormat行写入日志文件的列相对应。