leetcode汇总
一、题目汇总
1、快速幂算法
暴力 分治
二、涉及的c++语法
1、long long 类型 、很大的无符号
long long类型
unsigned long long
和uint64_t 作为标记
vector<vector<uint64_t>>dp(t.size() + 1, vector<uint64_t>(s.size() + 1, 0));
2、c++取绝对值
直接a=abs(a),不需要头文件
3、判断两者符号是否不同
用异或 int sign = (a > 0) ^ (b > 0) ? -1 : 1;
4、字符串一些函数
字符串反转和字符串开始结束位置
string s=“ssssdfaf”;
reverse(a.begin(), a.end()); 这两个表示反转的区间
字符串长度
int num=s.size();
字符串末尾添加元素
string ans;
ans.push_back((carry % 2) ? ‘1’ : ‘0’);
字符串清空内容
s.clear();
字符串添加一个字符
s.push_back(‘c’);
字符串删除最后一个字符
s.pop_back();
5、两数最大函数
int n = max(a.size(), b.size())
7、位运算>>=,<<=,&=,^=,|=

往一个数里扩充数可以直接 ans |= (1 << i);
8、vector容器
vector<int> v(10, 1);//创造一个容器,10个元素,初始化为1
vector<ListNode*> vec; //创建一个能存放链表节点的容器
vec.emplace_back(node); //在容器后面加入这个节点,此时这里是顺序存储的
vec[i]->next = nullptr;//这时可以用下标访问
第二个用途,vector容器元素是vecotor容器
vector<vector<string>> ans;
第三个 获得数组的最后元素
vector<int> s=[1,2,34,5];//声明一个数组
int a=s.back();//获得数组最后一个元素
s.pop_back();//弹出最后一个元素
第四个,初始化方法
int n = heights.size();
vector<int> left(n), right(n, n);//后者是初始化n个为n的数据
vector<int> a (v.begin(),v.begin()+1)//前闭后开?或者后面是数量?如果end(),因为太大,所以直接到最后?
第五个,vector的初始化
在class中,全局变量
vector<int>memo;
在得到个数以后,在函数中进行初始化
int climbStairs(int n) {
memo = vector<int>(n + 1, -1);
}
9、二分查找
1.从小到大
lower_bound(start,last,n) :返回第一个大于等于n的地址
upper_bound(start,last,n) :返回第一个大于n的地址
2.从大到小
lower_bound(start,last,n,greater()) :返回第一个小于等于n的地址
upper_bound(start,last,n,greater()) :返回第一个小于n的地址
注意是位置,也就是索引
10、强制转换
static_cast显示类型转换 或 强制类型转换。
强制转换使得编译器把一个对象(或者表达式)从它当前的类型转换成程序制定的类型
auto bound = lower_bound(sums.begin(), sums.end(), target);
ans = min(ans, static_cast((bound - sums.begin()) - (i - 1)));
由于bound是auto,不知道什么类型,因此这里来个强制转换
11、累加
#include11、unordered_set 哈希表
#include 注意上下两个的区别
6、unordered_map
需要引入头文件 #include < unordered_map >
用于存储键值和映射值组合成的元素的关联容器,并允许基于其键快速检索各个元素。
unordered_map
++freq[num];
unordered_map<string, vector<string>> mp;//声明了一个string键,vector类型的值的map
for (string& str : strs) {
string key = str;
std::sort(key.begin(), key.end());
mp[key].emplace_back(str);//mp[key]获得对应的vector,然后运用方法加入元素
}
第三点需要注意的是
键存在不存在不影响往里赋值

12、对链表的处理
将链表节点存储到vector中
vector<ListNode*> vec;//声明一个能存放节点的vecotor
while (node != nullptr) { //然后将元素存放到vecotor中 这里存放的是按顺序的
vec.emplace_back(node);
node = node->next;
}
vec[j]->next = vec[i]; //修改它的下个节点
vec[i]->next = nullptr; //赋为空值
13、对栈的操作
#include 14、随机数
“srand(time(NULL));”
这条指令的意思是利用系统时间来初始化系统随机数的种子值,使得每次运行由于时间不同产生而产生不同的随机数序列。
rand()是一个产生随机数的函数
srand()是一个设置随机数种子的函数
time(NULL)这个函数的返回值是作为srand函数的参数的,意思是以现在的系统时间作为随机数的种子来产生随机数
srand((unsigned)time(NULL));
int randomIndex = rand() % nums.size();
return nums[randomIndex];
15、sort函数
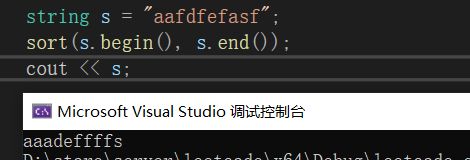
1)sort函数可对字母排序
string s="aafdfefasf";
sort(s.begin(), s.end());
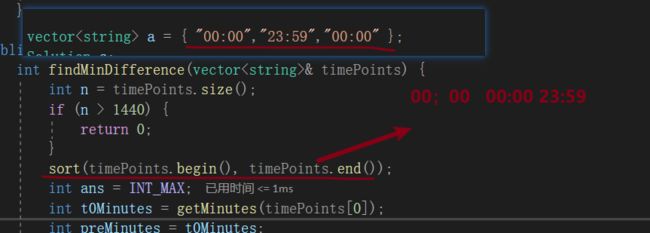
2)第二个用途:对时间字符串排序
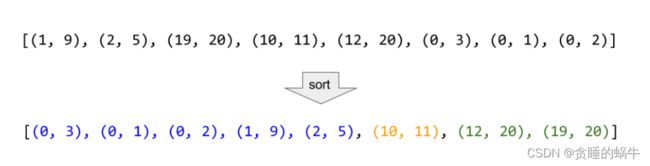
3)第三个用途:可以对二维数组进行排序
sort对二维数组进行排序是按照第一维度从小到大排的,如果第一维度数字一样,就看第二维度的数字哪个大。
vector<vector<int>> intervals = { {1, 3} ,{2, 6},{8, 10 }, {15, 1} };
sort(intervals.begin(), intervals.end());
4)重定义sort比较函数
对于传递进来的两个值,你函数只需要告诉我第一个参数,第二个参数这样排列对不对就完了,
举个例子,对于 a,b,我给你了,你告诉我先a后b是否对就行
我函数里如果这样a
比如2,4 2<4,那返回true就是这样排列,但如果修改为a>b,那就是降序排列了
下面是个复杂一点的
sort(arr1.begin(), arr1.end(), [&](int x, int y) {
if (rank.count(x)) {
return rank.count(y) ? rank[x] < rank[y] : true;
/*在哈希表里的会小一点
* 如果一个在哈希表里一个不在哈希表里,那么在哈希表里的大
* 传递了两个元素,第一个元素在哈希表,第二个元素不在哈希表,那么第二个元素大
* 传递两个元素,是想判断这两个哪个大,很显然第二个大,那么就返回true
* 如果两个都在哈希表里,那么比较哈希表键对应的值
* 两个元素,如果第一个大即rank[x] > rank[y],那么返回false
* 如果第二个大,那么返回true
*/
}
else {
return rank.count(y) ? false : x < y;
/* 如果第一个不在哈希表里,那么看第二个是否在哈希表里
* 如果第二个不在哈希表里,那就是看这两个谁大了
* 如果第二在哈希表里,由于在哈希表里的小,那么就返回false
*/
}
});

16、两两比较
从i=1开始,每次都是与前面一个元素比较
17、字符处理过程总结
1、将12:30字符串转换为类时间戳形式
获取字符与’0’相减获得值
(110+2)+(310+0)
(int(t[0] - '0') * 10 + int(t[1] - '0')) * 60 + int(t[3] - '0') * 10 + int(t[4] - '0');
2、to_string函数
to_string 函数:将数字常量转换为字符串
3、stoi函数
stoi(字符串,起始位置,2~32进制),将n进制的字符串转化为十进制。
int a = stoi("1010", 0, 2);//将string类型二进制的1010转换为十进制数
int b = stoi("1010", 0, 10);//将十进制的string类型转换为十进制
不带第二个和第三个参数默认转换成十进制
4、遍历每个字符
string="1,1,1,0,#,1,0"
for (auto& ch : data) {//遍历每个字符
if (ch == ',') {//如果字符为,不做处理
dataArray.push_back("");
}
else {//如果不为#,那么将其加入数组中
dataArray.back().push_back(ch);
}
}
5、int遍历每个字符
int i = 981;
while(i)
{
int n = 981%10;
i = i/10;
}
18、判断是否为数字
检测字符串是否只由数字组成
string s ="12345"
isdigit(s);
19、将字符串转换为数字
atoi(str)
20、队列
#include21、二叉树
1)二叉树数据结构
二叉树初始化代码
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
2)二叉树剪枝
使用递归,剪枝到终端仅需要让指针指向null即可
23、map
map对应java的TreeMap
#include < map >
std::map<std::string, int>myMap;
std::map<std::string, int>myMap{ {"C语言教程",10},{"STL教程",20} };//myMap 容器在初始状态下,就包含有 2 个键值对。
C++ STL map 类模板中对[ ]运算符进行了重载
mymap["Python教程"] = "http://c.biancheng.net/python/";//添加新键值对
mymap["STL教程"] = "http://c.biancheng.net/stl/";//修改键值对
cout << mymap["STL教程"] << endl; //获得值
迭代map
first代表键,second代表值
for (auto iter = mymap.begin(); iter != mymap.end(); ++iter) {
cout << iter->first << " " << iter->second << endl;
}
涉及到的二分查找
auto it = cale.lower_bound(end); //通过二分查找获得指针,这个指针指向一个键值对
if((--it)->second <= start){ //当前键值对的前一个元素的值小于一个变量
cale[start] = end;//更新键值对
}
24、使用红黑树的set
1、构造方法
set<string> st;//没有任何参数
set<string> st{"good", "bad", "medium"};//有三个参数
set<string> st2(st);//从st中拷贝到st2进行构造
2、增删改查
插入
st.insert("hhh");//插入单个元素
st.insert({"hhh", "wow"});//插入多个元素
删除
rec.erase("hhh");
25、最大最小堆priority_queue
1)基本用法
默认最大堆 : priority_queue big_heap
最小堆 : priority_queue
最小堆经常用来求取数据集合中 k 个值最大的元素,而最大堆经常用来求取数据集合中 k 个值最小的元素
priority_queue(),默认按照从小到大排列。所以top()返回的是最大值而不是最小值
empty( ) //判断一个队列是否为空
pop( ) //删除队顶元素
push( ) //加入一个元素
size( ) //返回优先队列中拥有的元素个数
top( ) //返回优先队列的队顶元素
2)自定义类型
pair数据类型
一个pair保存两个数据成员
创建一个pair类型数据时,必须提供两个类型名,表示数据成员对应的类型。
pair
pair<string, string> p1;
pair<string, string> p3 = {"heh", "dd"};//成员初始化
cout << p3.first << endl; // 访问first成员
自定义堆
priority_queue<Type, Container, Functional>
- Type 是数据类型
- Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector
- Functional 是比较的方式
例子1
struct cmp {
bool operator() (const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second; // 最小堆,从小到大排序
}
};
priority_queue<pair<int, int>, vector<pair<int, int>>, cmp> heap; //使用
数据类型为pari类型,第二个标明容器类型,第三个参数使用了cmp,在cmp中重载了比较方式,在比较方式里可以看到传递了两个pair,然后返回这个比较的bool结果
例子2
比较时使用的Lambda表达式,语法可以看下面
auto cmp = [&](const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.first + lhs.second < rhs.first + rhs.second;
};
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> heap(cmp);
引用传递方式传递了两个参数,忽略了返回值让编译器自己判断返回值类型
decltype被称作类型说明符,它的作用是选择并返回操作数的数据类型。
内置比较算法greater和less
greater和less是头文件< functional>
greater< int >()内置类型从大到小
less< int>()内置类型小大到大
那么这里可以 priority_queue
26、Lambda表达式
参考链接
Lambda表达式的定义语法
[函数对象参数](函数参数)修饰符->返回值类型{函数体};
1)[]函数对象参数
- 空:代表不捕获Lambda表达式外的变量;
- &:代表以引用传递的方式捕获Lambda表达式外的变量;
- =:代表以值传递的方式捕获Lambda表达式外的变量,即以const引用的方式传值;
- this:表示Lambda表达式可以使用Lambda表达式所在类的成员变量;
- a或=a:表示以值引用的方式传递变量 a a a,即const int a,在函数体内不可改变a的值;但是可以对Lambda表达式使用mutable修饰符修饰,使得函数对象参数可以进行赋值,但是该函数对象参数不是被修改为引用传递方式,下面进行细说;
- &a:表示以引用传递的方式传递变量 a ,在函数体内可以改变a的值;
- x,&y:x为值传递方式,y为引用传值方式;
- =,&x,&y:除x,y为引用传递方式以外,其他参数都为值传递方式进行传递;
- &,x,y:除x,y为值传递方式以外,其他参数都为引用传递方式进行传递;
2)函数参数
如果函数没有参数可以省略,省略后为
auto f = [] {
cout << "Hello" << '\n';
};
如果存在参数
auto f = [] (string s) {
cout << "Hello " << s << '\n';
};
3)修饰符
有两个修饰符,不用可以省略
- mutable 函数参数可以在函数体里改变但是不会影响到外面,相当于拷贝了一份
- exception 声明用于指定函数抛出的异常
4)返回值类型
没有可以省略,有也可以省略,Lambda表达式会自动推断返回值类型但是返回要返回一样的数据类型
5)函数体
可以为空,但是不能省略
27、一些处理方法
1)char拷贝到char
char* source = "abncdedf"这样写不会通过,可以在前面加上const
void copy_str(char* taget,const char* source) {
if (taget == NULL || source == NULL) return;
while (*source != '\0') {
*taget = *source;
taget++;
source++;
}
*taget = '\0';//但由于buf全为0也可以不加这个结束符
}
int main() {
const char* source = "abncdedf";
char buf[1024] = { 0 };
copy_str(buf, source);
cout << buf << endl;
}
28、二维数组STL表示
//初始化数组,n1+1个 vector,这个vector有n2+1个空间,即二维数组(n1+1)*(n2+1)
vector<vector<int>> dp(n1 + 1, vector<int>(n2 + 1));
//可以看到可以用变量
二维数组遍历,推荐横着遍历,考虑到二维数组本身是按照一维数组存储以及计算机缓存的运行机制,按照逐行遍历的方式效率更高点。
for (int i = 0; i < n1; ++i) {
for (int j = 0; j < n2; ++j) {
if (text1[i] == text2[j]) {
dp[i + 1][j + 1] = dp[i][j] + 1;
}
else {
dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);
}
}
}
29、有向图数据结构

unordered_map<string, vector<pair<string, double>>> graph;
for (int i = 0; i < equations.size(); ++i) {
graph[equations[i][0]].push_back({ equations[i][1], values[i] });
graph[equations[i][1]].push_back({ equations[i][0], 1 / values[i] });
}
30、四个方向上移动
//定义四个方向
vector<vector<int>> dires{ {0, 1}, {0, -1}, {1, 0}, {-1, 0} };
for (auto& d : dires) {
int row = i + d[0];
int col = j + d[1]; //行列得到移动后的坐标
//判断是否出界
if (row >= 0 && row < matrix.size() && col >= 0 &&
col < matrix[0].size() && matrix[row][col] > matrix[i][j]) {
........
31、最大值和最小值
#include32、幂次
pow(a,10)
即a的十次幂
list的vector类型
需要包含头文件
#include
ist<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
std::list<vector<int>>::iterator it = que.begin();
while (position--) { // 寻找在插入位置
it++;
}
que.insert(it, people[i]);
一些函数总结
1)max_element()函数
int ints[] = { 3,5,7,2,7,6,4 };
cout << "方法一最大值地址是" << max_element(ints, ints + 7) << endl;//这个时候获取元素的地址
cout << "方法二最大值的位置是" << *max_element(ints, ints + 7) << endl;//这个时候获取最大元素的值
vector<int> piles = { 1,3,5,4,2 };
int right = *max_element(piles.begin(), piles.end());//获取最大元素的值
2)move函数
C++ 标准库使用比如vector::push_back 等这类函数时,会对参数的对象进行复制,连数据也会复制.这就会造成对象内存的额外创建, 本来原意是想把参数push_back进去就行了,通过std::move,可以避免不必要的拷贝操作。
ans.push_back(move(ipAddr));
一些错误总结
1、使用#include < algorithm>的for_each函数,不能将获取迭代器放到函数里面

2、在求快乐数时,
while(n)
{
sum += n%10 * n%10;
n = n/10;
}
针对n%10不加()会出错,因为*的优先级大于%
22、一些有用技巧
1、在程序开头位置一些边界条件返回时,如果要返回vector,可以直接返回{}表示空,{1}表示返回1
2、如果想表示空指针,那么使用nullptr,而不是NULL。
3、递归如果想要使用数组,可以传入一个变量i的地址
int i = 0;
dfs(dataArray, i);//将这个变量的地址传入
TreeNode* dfs(vector<string>& strs, int& i) {//获取变量的地址
string str = strs[i];
i++;//这样便可以控制这个i,相当于全局变量
.......................
}
4、二分查找找mid时,mid = left + ((right - left) >> 1) 的写法比 mid = (left + right) / 2 好,因为 left + right 可能会溢出,同时位运算的效率更高; >> 1 作用相当于除二

5、需要判断奇偶与前后作比较时,即
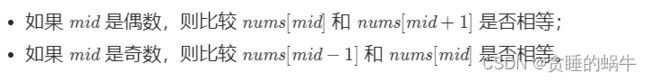
由于
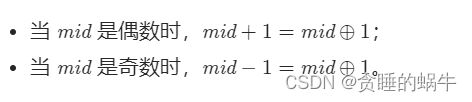
因此可以直接 if (nums[mid] == nums[mid ^ 1])
6、迭代器传递数组的开始指针和最后节点的下一个元素

7、do {} while(0)函数
do {
这是逻辑A
break;
这是逻辑B
这是逻辑C
return succes
} while(0)
回滚
do {} while(0)就类似goto语句,由于不让使用goto语句,可以用do {} while(0)代替,一旦使用了break,逻辑B和C就不再执行,跳到了后续操作上,出错break后,还可以执行后续操作。
8、&1判断奇偶
如果是奇数,其结果为1,偶数结果为false。
if ((newTar & 1) != 0 || newTar < 0) {
return 0;
}
9、字母异位词
判断两个单词是否相似只需要遍历一个单词,看看有多个位置的字母不一样就可以了
diff++
bool isAnagram(string& str1, string& str2) {
int diff = 0;
for (int k = 0; k < str1.size(); ++k) {
if (str1[k] != str2[k]) {
diff++;
}
if (diff > 2) {
return false;
}
}
return true;
}
10、数组两个for遍历
如果想要找某个最值或者某个值
初始让一个中间变量为-1
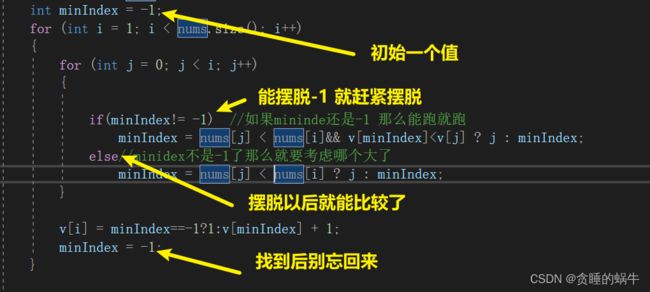
11、好处理方式
14
14、一般库函数实现的语言都是左闭右开原则,比如reverse(i,i+k)并不包含k
23、元组的使用
元组不能用 =
元组要包含头文件
将元组加入栈 加入时要加类型
stack<tuple<TreeNode*, int, vector<int>>> st;
st.push(tuple<TreeNode*, int, vector<int>> { root, root->val, { root->val }});
从栈中取出元组 ,用{}。
auto temp{ st.top() };
元组操作
auto temp{ st.top() };
TreeNode* nodeT = get<0>(temp);
int sumT = get<1>(temp);
vector<int> vT = get<2>(temp);
24 一些额外操作
1)栈里定义pair和添加元素
stack<pair<TreeNode*, int>> st;
st.push(pair<TreeNode*, int>(root, root->val));
pair<TreeNode*, int> node = st.top();
st.pop();
node.first
node.seconde//注意是点,并非->
2)栈里定义tuple元组和添加元素
stack<tuple<TreeNode*, int, vector<int>>> st;
st.push(tuple<TreeNode*, int, vector<int>> { root, root->val, { root->val }});
auto temp{ st.top() }; //弹出元素
TreeNode* nodeT = get<0>(temp); //下面三行是接收元素
int sumT = get<1>(temp);
vector<int> vT = get<2>(temp);
vector的end和back等,以及vector关于begin的拷贝,以及vector初始化的重新整理
end()是返回一个当前vector容器中末尾元素的迭代器,注意是迭代器,如果返回最后一个元素可以*end()-1,或者可以使用back()返回末尾元素的引用,也就是可以通过back() = 10来修改其元素
begin()是返回的第一个元素的迭代器,因此可以通过*begin()来返回第一个元素,同样的front()也是返回第一个元素的引用。
vector<int> v = { 1,2,3,4 };
vector<int> v { 1,2,3,4 }; //这种{}是直接指定元素,可以加= 也可以不加
vector<int> v2(v.begin(), v.begin() + 1); //名字后面带()是特殊的形式
vector<int> v3(100,9); 是初始化100个9
vector<int> v2(v.begin(), v.begin() + 1); 是根据迭代器来复制,前闭后开,这个也就仅仅复制一个元素
如果使用end() ,就将begin()记为下标为0
以将{0,1, 2, 3,4,5}为例,想分成两半,那么就[begin,begin+3) [begin+3,end()]

vecotr删除元素
可以通过data.pop_back();删除元素
对于其他元素,可以先swap替换到后面,然后再调用上面删除末尾方法
std::swap(std::begin(data)+1,std::end(data)-1);
unordered_map遍历
unordered_map<char,int> mp1;
for(auto p: mp1)
{
if(mp2[p.first] < p.second)
return false;
}
这里p不是指针,看其第一个元素啥的用.
也可以for (auto [key, value] : strVec)
这样直接出值了。
substr
s.substr(1,2)第一个参数为下标,第二个参数为长度,并不是left和right
unint32_t
控制台输入 00000000000000000000000000001011
这个东西就能接收这个 打印的时候输出1011