《计算机网络--自顶向下方法》第二章--应用层
2.1应用层协议原理
研发网络应用程序的核心是写出能够运行在不同的端系统和同构网络彼此通信的程序,将应用软件限制在端系统,从而促进大量的网络应用程序的迅速研发和部署。
2.1.1网络应用程序体系结构
应用程序的体系不同于网络的体系结构,应用程序体系结构(application architecture)由应用程序研发者设计,规定了如何在各种端系统上组织该应用程序。分为两种主流体系结构:客户-服务器体系结构(C/S),对等(P2P)体系结构。
客户-服务器体系结构:其中由有一个总是打开的主机称为服务器,它服务于来自许多其他称为客户的主机的请求。在一个客户-服务器应用中,常常会出现一台单独的服务器主机跟不上它所有客户请求的情况,因此出现了配备大量主机的数据中心,数据中心常被用于创建强大的虚拟服务器。
①利用这个体系结构,客户相互之间不直接通信
②该服务器具有固定的,周知的地址,该地址称为IP地址。
③服务器可扩展性差,当访问量到达一定量级,处理性能断崖性的下降
P2P体系结构:对位于数据中心的钻用服务器由最少的(或没有)依赖。应用程序在间断连接的主机对之间使用直接通信,这些主机对被称为对等方
①具有自拓展性,每个对等方会在请求文件产生工作负载的同时,也通过向其他对等方分发文件为系统增加服务能力
②P2P体恤结构具有成本效率,通常不需要庞大的服务器设施和服务器宽带
③参与的主机间歇性连接且可以改变IP地址,导致难以管理
混合体:
①Napster:
文件搜索:集中 主机在中心服务器上注册其资源,主机向中心服务器查询资源位置
文件传输:P2P 任意peer节点之间
②即时通信
在线检测:集中 当用户上线,向中心服务器注册其IP地址;用户与中心服务器联系,找寻在线好友位置
用户聊天:P2P
某些应用具有混合的体系结构,它结合了客户-服务器和P2P的元素 。对于许多即时讯息应用而言,服务器被用于跟踪用户的IP地址,但用户到用户的报文在用户主机之间直接发送,无需通过中间服务器。
2.1.2进程通信
进行通信的实际上是进程(process)而不是程序。一个进程可以被认为是运行在端系统中的一个程序。当多个进程运行在相同的端系统上时,他们使用进程间通信机制相互通信。
在两个不同端系统上的进程,通过跨越计算机网络交换报文(message)而相互通信。
1.客户和服务器进程
网络应用程序由成对的进程组成,这些进程通过网络互相发送报文。对于每对通信进程,将进程之一标识为客户,而另一个进程标识为服务器。在P2P文件共享系统中,一个进程可以既是客户又是服务器。
在一对进程之间的通信会话场景中,发起通信(即在该会话开始时发起与其他进程的联系)的进程被标识为客户,在会话开始时等待联系的进程是服务器。
2.进程与计算机网络之间的接口
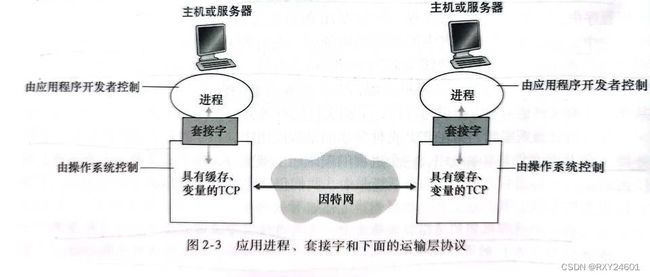
进程通过一个称为套接字(socket)的软件接口向网络发送报文和从网络接收报文。套接字是同一台主机内应用层与运输层之间的接口,套接字也被称为应用程序和网络之间的应用程序编程接口(Application Programming Interface,API) 。
应用程序开发者可以控制应用层的一切,但是对于运输层几乎没有控制权。对于运输层的控制权限仅限于:①选择运输层协议②设定几个运输层参数(比如最大缓存和最大报文段长度)
3.进程寻址
接受进程需要定义两种信息①主机的地址②在目的主机中指定接受进程的标识符 。在因特网中主机由其IP地址(IP address)标识。发送进程除了需要知道接收主机的IP地址,还需要接收主机上的接收套接字。通过目的地端口号(port number)来区分。
一个套接字结构是由一个IP地址和一个端口号构成的,IP是在网络层,端口是在传输层定义的。网络层确定的是数据包的源目IP地址,传输层确定端口号是数据包在接收主机上这个数据包应该交给哪个进程 。套接字的IP面向数据报,端口号面向进程。
Internet Assigned Numbers Authority (iana.org) http://www.iana.org/上面这个网站可以找到所有因特网标准协议的周知端口号。
http://www.iana.org/上面这个网站可以找到所有因特网标准协议的周知端口号。
| 端口号 | 服务 | 协议名称 |
| 21号端口 | FTP | 文件传输协议 |
| 23号端口 | Telnet | 远程登录协议 |
| 25号端口 | SMTP | 简单邮件传输协议 |
| 53号端口 | DNS | 域名服务器,主要用于域名解析 |
| 80号端口 | HTTP | 超文本传输协议 |
| 109号端口 | POP2 | 第二代简单邮局协议 |
| 110号端口 | POP3 | 第三代简单邮局协议 |
| 111号端口 | RPC | 远程过程调用协议 |
| 143号端口 | IMAP | 网络消息访问协议 |
| 161号端口 | SNMP | 简单网络管理协议 |
2.1.3可供应用程序使用的运输服务
为了确定运输层协议,通过四个方面对应用程序服务要求进行分类 :可靠数据传输、吞吐量、定时、安全性
1.可靠数据传输
可靠数据传输:协议确保应用程序的一段发送的数据正确,完全的交付给应用程序的另一端
2.吞吐量
吞吐量:发送进程能够像接收进程交付比特的速率 。具有吞吐量要求的应用程序被称为带宽敏感的应用。根据可用带宽多少利用可供使用的吞吐量的应用程序为弹性应用
3.定时
有些服务为了有效性而要求数据交付有严格的时间限制,定时以多种形式实现,由运输层协议提供定时保证。
4.安全性
运输协议能够为应用程序提供一种或多种的安全性服务。这种服务将在发送和接收进程之间提供机密性,以防该数据以某种方式在这两个进程之间被观察到。运输协议还能提供除了机密性之外的其他安全性服务,包括数据完整性和端点鉴别。
2.1.4因特网提供的运输服务
运输层提供的服务-需要穿过层间的信息:①层间接口必须要携带的信息,要传输的报文(对于本层来说是SDU);谁传的,我方的应用进程的标识 IP+TCP(UDP)端口;传给谁,对方的应用进程的标识 对方的IP+TCP(UDP)
因特网为应用程序提供了两个运输层协议,即UDP和TCP。
1.TCP服务
TCP服务模型包括面向连接服务和可靠数据传输服务。
| 应用 | 数据丢失 | 带宽 | 时间敏感 |
| 文件传输 | 不能丢失 | 弹性 | 不敏感 |
| 电子邮件 | 不能丢失 | 弹性 | 不敏感 |
| Web文档 | 不能丢失 | 弹性(几kbps) | 不敏感 |
| 因特网电话/视频会议 | 容忍丢失 | 音频(几kbps~1Mbps) 视频(10kbps~5Mbps) |
敏感,100ms |
| 流式存储音频/视频 | 容忍丢失 | 音频 视频 |
敏感,几秒 |
| 交互式游戏 | 容忍丢失 | 10kbps以下 | 敏感,100ms |
| 智能手机讯息 | 不能丢失 | 弹性 | 敏感 |
·面向连接的服务:①在应用层数据报文开始流动之前,TCP让客户和服务器互相交换运输层控制信息,这个过程被称为握手过程,让客户和服务器为大量分组交换准备②握手阶段后,一个TCP就在两个进程的套接字之间建立了,连接双方的进程可以在此连接上同时进行报文收发③当应用程序结束报文发送时,必须拆除该连接
·可靠的数据传送服务:通信进程能够依靠TCP,无差错、按适当顺序交付所有发送的数据。没有字节的丢失和冗余。
TCP协议还具有拥塞控制机制,这种服务不一定为通信进程带来直接好处,但是能为因特网带来整体好处。TCP的拥塞控制机制会抑制发送进程当网络出现拥塞时。
TCP安全
无论是TCP还是UDP都没有提供任何加密机制。为了避免被中间链路嗅探和发现,研发了TCP的加强版本,称为安全套接字层(Secure Sockets Layer,SSL)。SSL提供传统TCP所能做的一切,提供了关键的进程到进程的安全性服务,包括加密、数据完整性和端点鉴别。
SSL不是与TCP和UDP在相同层次上的第三种因特网运输协议,只是对TCP的加强,这种加强在应用层上实现
2.UDP服务
UDP是一种不提供不必要服务的轻量级运输协议,两个进程通信之前没有握手过程。UDP协议提供一种不可靠的数据传送服务,不保证该报文到达接收进程。
UDP不提供拥塞控制机制,UDP的发送端可以用它选定的任何速率向下层注入数据。
3.因特网运输协议所不提供的服务
因特网运输协议不提供吞吐量和定时。因特网能够为时间敏感应用提供服务,但不能提供任何定时或带宽保证。
| 应用 | 用户层协议 | 支撑的运输层协议 |
| 电子邮件 | SMTP [RFC 5321] | TCP |
| 远程终端访问 | Telnet [RFC 854] | TCP |
| Web | HTTP [RFC 2616] | TCP |
| 文件传输 | FTP [RFC 959] | TCP |
| 流式多媒体 | HTTP(如YouTube) | TCP |
| 因特网电话 | SIP [RFC 3261]、RTP [RFC 3550]、或专用的(如Skype) | UDP或TCP |
2.1.5应用层协议
应用层协议定义了运行在不同端系统上的应用程序进程如何相互传递报
1.交换的报文类型,例如请求报文和响应报文
2.各种报文类型的语法,如报文中的各个字段及这些字段是如何描述的
3.字段的语义,即这些字段中的信息的含义
4.确定了一个进程何时以及如何发送报文,对报文进行响应的规则
应用层协议只是网络应用的一部分,它是应用非常重要的一部分。应用层协议定义了运行在不同端系统上的应用程序进程如何相互传递报文。
2.2Web和HTTP
万维网WWW是World Wide Web的简称,也称为Web、3W等。WWW是基于客户机/服务器方式的信息发现技术和超文本技术的综合。WWW服务器通过超文本标记语言(HTML)把信息组织成为图文并茂的超文本,利用链接从一个站点跳到另个站点。这样一来彻底摆脱了以前查询工具只能按特定路径一步步地查找信息的限制

2.2.1HTTP概况
Web 的应用层协议是超文本传输协议(HyperText Transfer Protocl,HTTP),它是Web的核心。HTTP由一个客户程序和一个服务器程序组成。
Web页面(Web page)是由对象组成的。一个对象(object)只是一个文件,他们可以通过一个URL地址寻址。多数的Web页面含有一个HTML基本文件(base HTML file)以及几个引用对象。HTML基本文件通过对象的URL地址引用页面中的其他对象。每个URL地址由两部分组成:存放对象的服务器主机名和对象的路径名。
Web浏览器实现了HTTP的客户端,所以一般在Web环境中交替使用“浏览器”“用户”这两个术语。
Web服务器实现了HTTP的服务器端,它用于存储Web对象,每个对象由URL寻址。
例如:URL地址https://blog.csdn.net/RXY24601?spm=1000.2115.3001.5343,其中的www.blog.csdn.net就是主机名,RXY24601?spm=1000.2115.3001.5343就是路径名。
HTTP定义了Web客户向Web服务器请求Web页面的方式,以及服务器向客户传送Web页面的方式。HTTP采用TCP作为它的支撑传输协议。

在如上图所示的传输过程中,一旦用户向它的套接字接口发送了一个请求报文,这个报文就脱离了用户的控制,并且被TCP控制。TCP为HTTP提供可靠数据传输服务,这意味着客户进程发出的每个HTTP请求报文最终都能完整的到达服务器,同理服务器发出的每个HTTP响应报文也都能完整的到达用户。HTTP协议不用担心数据丢失的问题,也不关注TCP从网络的数据丢失和乱序故障中恢复的细节,处理数据丢失问题是TCP以及因特网协议栈低层的工作。
服务器向客户发发送被请求的文件,而不存储任何关于该客户的状态信息。HTTP协议是一个无状态协议(stateless protocol)。也就是说如果用户在短时间内多次请求同一对象,那么服务器就会多次发出响应报文,可以理解为连续点开同一个URL地址,那就会打开响应次数个网页。
2.2.2非持续连接和持续连接
客户和服务器在一个相当产给的时间范围内通信,客户发出一系列请求,服务器对每个请求进行响应。 对每一个请求和响应都经过一个单独的TCP发送,被称为非连续连接(non-persistent connection)。对所有的请求和响应经相同的TCP连接发送,被称为持续连接(persistent connection)。HTTP在默认方式下使用持续连接,然而HTTP客户和服务器也能配置成使用非持续连接。
1.采用非连续连接的HTTP
在非连续连接下,从服务器向用户传送一个Web页面的步骤:
假设页面含有1个HTML基本文件和10个JPG图形,并且这11个对象位于同一台服务器上。URLhttps://blog.csdn.net/RXY24601?spm=1000.2115.3001.5343
①HTTP客户进程在端口号80发起一个到服务器www.blog.csdn.net的TCP连接。客户上的套接字与服务器上的套接字通过TCP相连
②HTTP客户端通过它的套接字,向服务器发送一个HTTP请求报文。这个报文中包含URL的路径名/RXY24601?spm=1000.2115.3001.5343
③HTTP服务器进程通过它的套接字,接收了这个HTTP请求报文,从服务器的存储器(RAM或磁盘)中检索出对象www.blog.csdn.net/RXY24601?spm=1000.2115.3001.5343,并且在一个HTTP响应报文中封装这个对象,并且通过服务器的套接字经过TCP连接向客户端发送报文。
④HTTP服务器进程通知TCP断开这个TCP连接(事实上现在只是通知,还并未执行,之后当TCP确定客户端已经完整的接收到响应报文的时候,TCP连接才会实际断开)
⑤HTTP客户端接收响应报文,TCP连接关闭。客户端通过接收的报文指出封装的对象是一个HTML文件,客户端从响应报文中获取这个文件,并检查HTML文件中的内容,得到对10个JPG文件的引用
⑥对每一个引用的JPG图形对象重复前面4个步骤
浏览器收到该Web页面之后,就会向用户显示这个页面,不同的浏览器的显示方式也许不同。因为HTTP只规定客户端与服务器之间的通信协议,并不规定如何解释一个Web界面。
在非连续连接中,每个TCP连接只传输一个请求报文和一个响应报文。连接不为其他对象而持续。
往返时间(Round-Trip Time,RTT):指一个短分组从客户到服务器然后再返回客户所花费的时间。RTT包括分组传播时延,分组在路由器和交换机上的排队时延以及分组处理时延。

如图所示,第一次握手是客户向服务器发送一个TCP报文,第二次握手时服务器向客户返回一个TCP报文,第三次握手客户确认TCP并且向服务器发送HTTP请求报文。总的响应时间就是两个RTT加上服务器传输HTML文件的时间。
2.采用持续连接的HTTP
非连续连接的缺点:①必须为每一个请求的对象建立和维护一个全新的连接,导致用户和服务器都要分配TCP缓冲区和保持TCP变量。②每一个对象经受两个RTT的交付时延,即一个RTT用于创建TCP连接,另一个RTT用于请求和接收以一个对象。
采用持续连接时,服务器发送响应后保持该TCP连接打开,在相同的客户和服务器之间,后续的请求和响应报文能够通过相同的连接进行传送。如果一个连接经过一定的时间间隔仍未被使用,那么HTTP服务器就会关闭该连接。
2.2.3HTTP报文格式
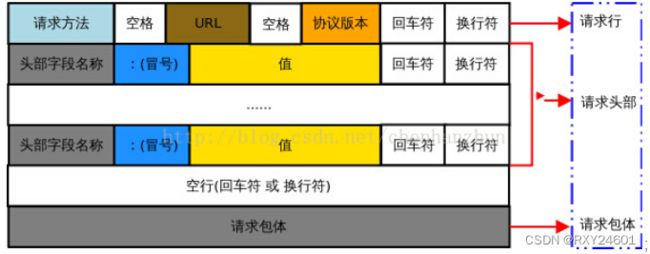
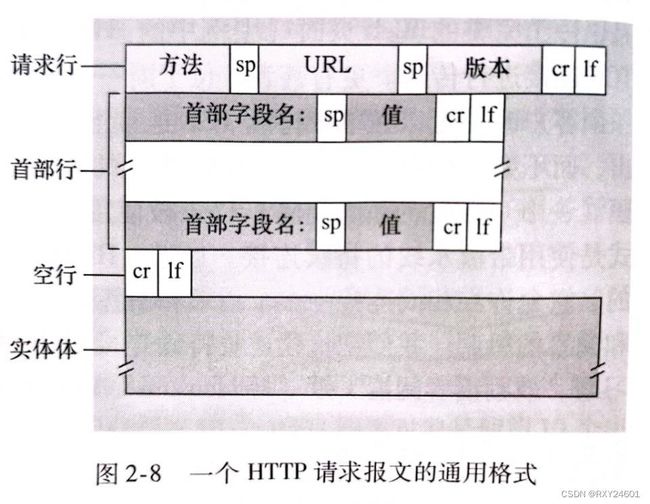
1.HTTP请求报文
请求报文由ASCLL文本书写,每行由一个回车和换行符结束。HTTP请求报文的第一行叫做请求行(request line),其后继的行叫作首部行(header line)。
请求行有三个字段:方法字段、URL字段和HTTP版本字段。
方法字段:包括GET、HEAD、PUT、POST、TRACE、OPTIONS、DELETE以及扩展方法,当然并不是所有的服务器都实现了所有的方法,部分方法即便支持,处于安全性的考虑也是不可用的
方法字段 GET
请求获取Request-URI所标识的资源
POST
在Request-URI所标识的资源后附加新的数据
HEAD
请求获取由Request-URI所标识的资源的响应消息报头
PUT
请求服务器存储一个资源,并用Request-URI作为其标识
DELETE
请求服务器删除Request-URI所标识的资源
TRACE
请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
OPTIONS
请求查询服务器的性能,或者查询与资源相关的选项和需求
URL字段:如果包含中文,浏览器会自动对中文字符进行编码之后再发送
HTTP版本字段:协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1
首部行
请求头
说明
Host
接受请求的服务器地址,可以是IP:端口号,也可以是域名
User-Agent
发送请求的应用程序名称
Connection
指定与连接相关的属性,如Connection:Keep-Alive
Accept-Charset
通知服务端可以发送的编码格式
Accept-Encoding
通知服务端可以发送的数据压缩格式
Accept-Language
通知服务端可以发送的语言
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
表示客户端可以接受的内容类型,多个值使用;分号隔开q=0.9 表示权重优先级,*/*表示可以接受任意类型内容
Content-Type: application/x-www-form-urlencoded
表单提交时才有可能出现,表示表单的数据类型,使用url编码,url编码 % 16位数
Upgrade-Insecure-Requests
告诉服务器,浏览器可以处理https协议
GET / somedir/page .html HTTP/1.1
Host: www . someschool.edu
Connection: close
User-agent: Mozilla/ 5.0
Accept-language: fr
如上左所示
请求行中①GET为方法字段②somedir/page.html为URL字段③HTTP/1.1为HTTP版本字段。
首部行中①Host:www.someschool.edu指明对象所在的主机,这个首部行提供的信息是由Web代理高速缓存需求的,所以即使有一条TCP连接了仍然需要②Connnect:close告诉服务器不使用持续连接,发送完被请求对象后就关闭该连接③User-agent:用来指明用户代理,即向服务器发送请求的浏览器的类型,这里的浏览器类型为Mozilla/5.0,即firefox火狐浏览器④Accept-language:fr表示用户想得到该对象的法语版本,如果没有该版本则发送默认版本
2.HTTP响应报文
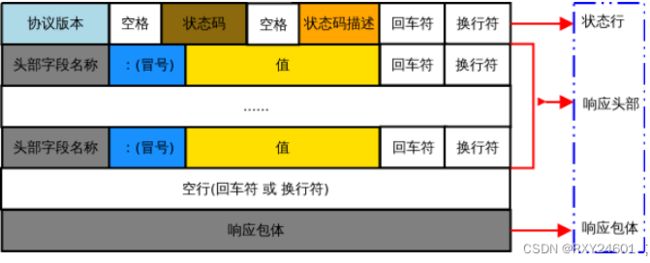
HTTP响应报文主要由状态行、首部行、实体体组成。实体体部分时报文的主要部分,包含所请求对象本身。
状态行有三个字段:协议版本字段、状态码和响应状态信息。
协议版本字段:表示服务器HTTP协议的版本
状态码:表示服务器发回的响应状态代码
状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
- 1xx:指示信息--表示请求已接收,继续处理。
- 2xx:成功--表示请求已被成功接收、理解、接受。
- 3xx:重定向--要完成请求必须进行更进一步的操作。
- 4xx:客户端错误--请求有语法错误或请求无法实现。
- 5xx:服务器端错误--服务器未能实现合法的请求
相应状态信息:表示状态代码的文本描述
首部行
与请求头部类似,为响应报文添加了一些附加信息
响应头
说明
Server
服务器应用程序软件的名称和版本
Content-Type
响应正文的类型(是图片还是二进制字符串)
Content-Length
响应正文长度
Content-Charset
响应正文使用的编码
Content-Encoding
响应正文使用的数据压缩格式
Content-Language
响应正文使用的语言
Expires: -1、Cache-control:no-cache、Pragma:no-cache
三个响应头一起使用, 表示禁止浏览器缓存当前页面. 每个浏览器厂商对认识的禁止头不同因此三个一起使用。
请求报文的响应
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/ html
(data data data data data ...)
对于上图所示的响应报文
状态行中:协议版本为HTTP/1.1,200表示响应成功,OK表示响应成功
首部行中:①Connection:close告诉用户发送完报文后讲关闭TCP连接②Date:表示服务器产生并发送该响应报文的日期和时间,这个时间不是对象创建或者最后修改的时间,而是服务器从文件系统中检索到该对象,并将其插入响应报文,并发送该响应报文的时间③Server:Apache表示该报文是由一台Apache Web服务器产生的,是基于CentOS的Linux系统,版本号为2.2.3④Last-Modified:表示对象创建或者最后修改的日期和时间。这对于即可能在本地用户也可能在网络缓存服务器上的对象缓存来说十分重要⑤Content-Length:表示被发送对象中的字节数⑥Content-Type:表示了实体体中的对象是HTML文本

2.2.4用户与服务器的交互:cookie
HTTP服务器是无状态的,但是一个Web网站通常都希望能识别用户,从而限制用户访问或者实现内容与用户的关联。因此使用cookie实现对用户的追踪。
cookie是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。
cookie有四个部件:
①在HTTP响应报文中的一个cookie首部行
②在HTTP请求报文中的一个cookie首部行
③在用户端系统中保留有一个cookie文件,并由用户的浏览器进行管理
④位于Web站点的一个后端数据库
| 属性项 | 属性项介绍 |
| NAME=VALUE | 键值对,可以设置要保存的 Key/Value,注意这里的 NAME 不能和其他属性项的名字一样 |
| Expires | 过期时间,在设置的某个时间点后该 Cookie 就会失效。修改expire项,可讲cookie的有效期延长 |
| Domain | 生成该 Cookie 的域名,如 domain="www.csdn.net"。修改domain项,可使用户能够访问不被授权的服务器项从而获得合法用户的信息 |
| Path | 该 Cookie 是在当前的哪个路径下生成的,如 path=/wp-admin/。修改path项,可使用户访问服务器上不被授权的内容 |
| Secure | 如果设置了这个属性,那么只会在 SSL 连接时才会回传该 Cookie |
举例来说, 一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。在这个文件夹里每一个文件都是一个由“名/值”对组成的文本文件,另外还有一个文件保存有所有对应的 Web 站点的信息。在这里的每个 Cookie 文件都是一个简单而又普通的文本文件。透过文件名, 就可以看到是哪个 Web 站点在机器上放置了Cookie(当然站点信息在文件里也有保存)
cookie的设置以及发送会经历四个步骤:客户端发送一个请求到服务器 -> 服务器发送一个HttpResponse响应到客户端,其中包含Set-Cookie的头部-> 客户端保存cookie,之后向服务器发送请求时,HttpRequest请求中会包含一个Cookie的头部 ->服务器返回响应数据

2.2.5Web缓存
Web缓存器(Web cache)也叫代理服务器(proxy server),它是能够代表初识Web服务器来满足HTTP请求的网络实体。Web服务器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的副本。Web缓存器又称为缓存代理服务器或者代理缓存,是存在于客户端和源服务器之间的一种中间服务器,这种代理服务器接收多个客户端的数据请求,属于公有缓存,这种缓存能大量减少多个客户端相同的资源请求,有效降低源服务器的负载压力。
客户端浏览器在显示一个完整网页前,需要去服务器获取一些必要的数据(js,css,image等),因为浏览器的数据处理和渲染速度很快,而通过网络传输的方式去服务器取数据的过程却很慢,所以页面显示出来前都有一段时间的白屏,如果每次打开相同的页面,获取相同的资源都要等待一段时间的白屏。如果把已经获取过的资源存在本地,下次用的时候就不用从服务器去取了,这样速度就要快很多了。这种机制便是web缓存。
客户通过Web缓存器请求HTTP对象的过程:
①浏览器创建一个到Web缓存器的TCP连接,并向Web缓存器中的对象发送一个HTTP请求②Web缓存器进行检查,查看本地是否存储了该对象的副本。如果有,Web缓存器就向客户浏览器用HTTP响应报文返回该对象③如果Web缓存器中没有该对象,缓存器就打开一个与该对象的初始服务器的TCP连接。由缓存器向初识服务器发送一个具有该对象的HTTP请求连接④Web缓存器接收该对象时,缓存器会在本地储存一个副本,并且通过用户与缓存器之间的TCP连接,向用户的浏览器通过HTTP的响应报文发送该副本。在这个过程中Web缓存器向用户发送报文时是服务器,接收初识响应报文时是客户
使用Web缓存器的原因:
- 降低延迟:缓存离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,呈现速度更快,网站就显得更灵敏。
- 降低网络传输:副本被重复使用,大大降低了用户的带宽使用,其实也是一种变相的省钱(如果流量要付费的话),同时保证了带宽请求在一个低水平上,更容易维护了。
- 能从整体上降低Web流量


内容分发网络(Content Distribution Network,CDN)在IP网络与Web缓存器的基础上,使内容传输更快、更稳定。
2.2.6条件GET方法
高速缓存在减少用户感受到的响应时间有很大作用,但是同时也出现了缓存器中存储的对象副本可能是陈旧的问题。因此HTTP中出现了条件GET(conditional GET)方法。
条件GET请求报文
- 请求报文中使用GET 方法;
- 请求报文中包含一个“If-Modified-Since:”首部行(浏览器端缓存页面数据的最后修改时间)。
条件GET方法操作方式:
①一个代理缓存器(proxycache)代表一个请求浏览器,向某 Web服务器发送一个请求报文:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
②该Web 服务器向缓存器发送具有被请求的对象的响应报文:
HTTP/1.1 200 OK
Date: Sat, 8 Oct 2011 15:39:29 Server: Apache/1.3.0 (unix)
Last-Modified: wed,7 sep 2011 09:23:24 Content-Type: image/gif
(data data data data data ...)
该缓存器在将对象转发到请求的浏览器的同时,也在本地缓存了该对象。重要的是,缓存器在存储该对象时也存储了最后修改日期。
③一个星期后,另一个用户经过该缓存器请求同一个对象,该对象仍在这个缓存器中。由于在过去的一个星期中位于Web服务器上的该对象可能已经被修改了,该缓存器通过发送一个条件GET执行最新检查。具体说来,该缓存器发送:
GET /fruit/kiwi.gif HTTP/1.1 Host: www.exotiquecuisine.com
If-Modified-since: wed, 7 sep 2011 09:23:24
If-Modified-Since的值正好等于一星期前服务器发送的响应报文中的Last-Modified的值。该条件GET报文告诉服务器,只有指定日期之后该对象被修改过,才发送该对象。
④ 假设该对象自2011年9月7日09:23:24后没有被修改。接下来,Web服务器向该缓存器发送一个响应报文:
HTTP/1.1304 Not Modified
Date: sat,150 ct 2011 15:39:29 server: Apache/1.3.0 (Unix)
( empty entity body)
作为对该条件GET 方法的响应,该Web服务器仍发送一个响应报文,但并没有在该响应报文中包含所请求的对象。包含该对象只会浪费带宽,并增加用户感受到的响应时间。值得注意的是在最后的响应报文中,状态行中为304 Not Modified,它告诉缓存器可以使用该对象,能向请求的浏览器转发它缓存的该对象副本。
2.3因特网中的电子邮件
电子邮件时一种一部通信媒介,与普通邮件相比,电子邮件更为快速并且易于分发,而且价格便宜。现代电子邮件具有许多强大的特性,包括具有附件、超链接、HTML格式文本和图片的报文。
因特网电子邮件系统分为三个主要组成部分:用户代理(user agent)、邮件服务器(mail server)、简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)
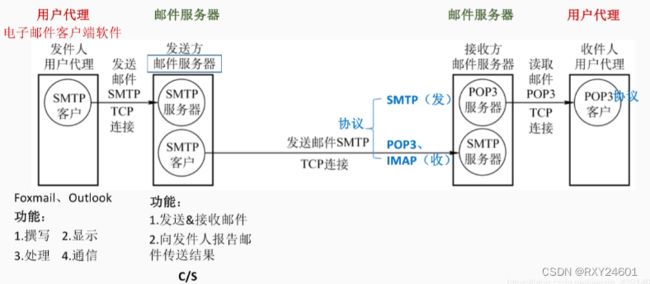
SMTP是因特网电子邮件中主要的应用层协议。它使用TCP可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件。
2.3.1SMTP
邮件发送过程
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。
SMTP命令 HELO 向服务器标识用户身份。发送者能欺骗,说谎,但一般情况下服务器都能检测到。 EHLO 向服务器标识用户身份。发送者能欺骗,说谎,但一般情况下服务器都能检测到。 MAIL FROM 命令中指定的地址是发件人地址 RCPT TO 标识单个的邮件接收人;可有多个 RCPT TO;常在 MAIL 命令后面。 DATA 在单个或多个 RCPT 命令后,表示所有的邮件接收人已标识,并初始化数据传输,以 CRLF.CRLF 结束 VRFY 用于验证指定的用户/邮箱是否存在;由于安全方面的原因,服务器常禁止此命令 EXPN 验证给定的邮箱列表是否存在,扩充邮箱列表,也常被禁用 HELP 查询服务器支持什么命令 NOOP 无操作,服务器应响应 OK RSET 重置会话,当前传输被取消 QUIT 结束会话
SMTP应答 220 服务就绪 221 服务关闭传输通道 250 请求命令完成 251 用户不是本地的,报文将被转发 354 开始邮件输入 450 邮箱不可使用 500 语法错误,不能识别命令 502 命令未实现 552 所请求的动作异常终止,存储位置超出 553 所请求的动作未发送,邮箱名不允许使用
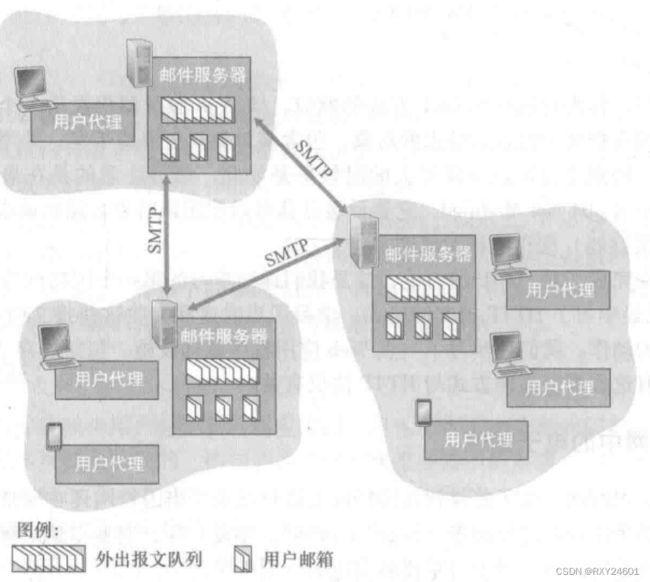
邮件服务器形成了电子邮件体系结构的核心。每个接收方在其中的某个邮件服务器上有一个邮箱(mailbox)。一个典型的邮件发送过程:从发送方的用户代理开始,传输到发送方的邮件服务器,再传输到接收方的邮件服务器,然后在这里被分发到接收方的邮箱中。
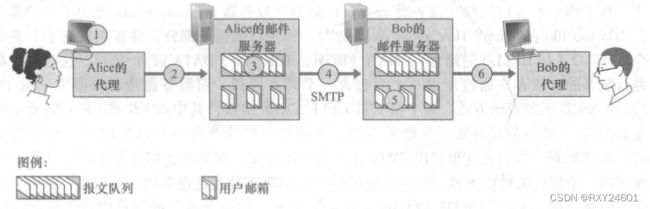
①发送方Alice调用用户代理并提供接收方Bob的邮箱地址,在用户代理上撰写待发送的报文,接着指示用户代理发送报文。②用户代理将Alice撰写的报文发送到Alice的邮件服务器,报文到达邮件服务器后将被分发到报文队列中。③运行在Alice的邮件服务器的SMTP客户端发现报文队列中的这个报文后将会创建一个到运行在Bob邮件服务器的SMTP服务器的TCP连接。④经过SMTP握手后,SMTP客户端通过TCP连接把报文发送出去。⑤在Bob的邮件服务器上,SMTP服务器接收到报文后,邮件服务器将报文放入Bob的邮箱里。⑥Bob有空时看到邮箱消息便调用用户代理查阅报文。
SMTP一般不使用中间邮件服务器发送邮件,即使这两个邮件服务器位于地球的两端也是这样。如果发送方服务器不能将该邮件发送给接收方服务器,那么发送方服务器将在一个报文队列中保存该高温,并不断尝试再次发送,如果一直没能成功,服务器就会删除该报文并且用电子邮件的方式通知发送方。这意味着邮件并不在中间的某个邮件服务器保留。
S: 220 hamburger. edu
C: HELO crepes. fr
S: 250Hello crepes. fr, pleased to meet you
C: MAIL FROM://向服务器报告发信人的邮箱与域名
S: 250 alice@ crepes. fr... Sender ok
C: RCPT TO:
S: 250 bobehamburger. edu... Recipient ok
C: DATA S:354 Enter mail, end with "."on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .//报文以只有一个“.”的行结束
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger. edu closing connection 如上为一个SMTP客户(C)与SMTP服务器(S)交换报文文本:
SMTP握手:
1.从客户端使用熟知端口号25建立与服务器的TCP连接,SMTP服务器向该客户送回应答码220,并且还为客户端提供了服务器的域名
2.客户端收到应答码后,发送HELO命令,启动客户端和服务器之间的SMTP会话。该客户端发送的HELO用来向服务器提供客户端的标识信息
3.服务器端回应应答码250,通知客户端:请求建立邮件服务会话已经实现
邮件报文撰写并发送:
1.客户用“MAIL FROM”向服务器报告发信人的邮箱与域名
2.服务器向客户回应应答码“250”,代表请求命令完成 1.客户用来自“向服务器报告发信人的邮箱与域名2.服务器向客户回应应答码”250的邮件,代表请求命令完成
3.客户用“RCPT TO”命令向服务器报告收信人的邮箱与域名4.服务器向客户回应应答码“250”,代表请求命令完成5.客户用“DTAT”命令对报文的传送进行初始化 3.客户用“rct to”命令向服务器报告收信人的邮箱与域名4.服务器向客户回应应答码“250”,代表请求命令完成
5.客户用“DTAT”命令对报文的传送进行初始化
6.服务器回应“354”,表示可以进行邮件输入了
7.客户用连续的行向服务器传送报文的内容,每行以两字符的行结束标识(CR与LF)终止。报文以只有一个“.”的行结束8.服务器向客户回应应答码“250”,代表请求命令完成
终止SMTP会话:
1.客户端发送“QUIT”命令
2.服务器收到命令后,回应应答码“221”,并结束会话
2.3.2SMTP与HTTP的对比
相同:
这两个协议都用于从一台主机向另一台主机传送文件。HTTP从Web服务器向Web客户传送文件;SMTP从一个邮件服务器向另一个邮件服务器传送文件。都使用持久性连接,命令和状态代码都是ASCLL码
不同:
①HTTP主要是一个拉协议(pull protocol)。在Web服务器上装载信息,用户通过HTTP向服务器拉取信息。TCP连接是由想接收文件的机器发起的。SMTP是一个推协议(push protocol),发送邮件服务器把文件推向接收邮件服务器。TCP连接是由发送该文件的机器发起的。
②SMTP要求每个报文采用7比特ASCLL码格式。HTTP不受限制。
③HTTP把每个对象封装到独立的响应消息中。SMTP将多个对象在由多个部分构成的消息中发送。
2.3.3邮件报文格式
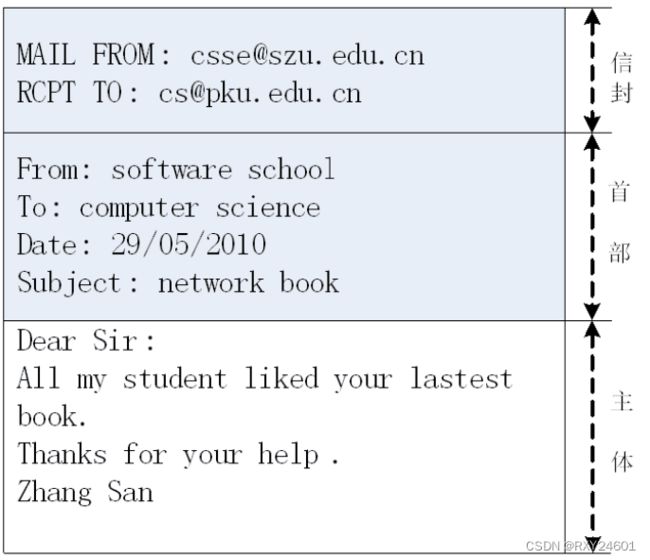
每一个典型的邮件报文都包含首部行和报文体。每个报文的首部行都会包含 From: 首部行和 To: 首部行。
注意下图信封中的内容属于SMTP握手协议中的一部分,而下面的首部行与报文体才是邮件报文自身的一部分
2.3.4邮件访问协议
SMTP是一个推协议,所以接收方用户需要从接收方服务器获得邮件报文时,必须借助其他的协议。
目前流行的邮件访问协议包括:第三版的邮局协议(Post Office Protocol—Version 3, POP3)、因特网邮件访问协议(Internet Mail Access Protocol, IMAP)以及 HTTP
1.POP3
邮局协议版本3 (Post Office Protocol - Version 3,POP3)。是TCP/IP协议族中的一员,由RFC1939 定义。本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。提供了SSL加密的POP3协议被称为POP3S。
POP3按照三个工作阶段进行工作:特许,事务处理,更新
①在第一个阶段(特许),用户代理发送(以明文形式)用户名和口令以鉴别用户。如下为特许阶段主要的两个命令
user
pass ②在第二个阶段(事务处理),用户代理取回报文;同时在这个阶段用户代理还能对报文做删除标记,取消报文删除标记,以及获取邮件的统计信息。用户代理通常被用户配置为:“下载并删除”和“下载并保留”两种模式。下载并删除的方式可能导致用户只能在第一次访问的机器上查询到邮件报文。
③在第三个阶段(更新),出现在用户发出QUIT指令之后,结束该POP3会话,此时邮件服务器删除那些呗标记为删除的报文
对于用户代理发出的指令,服务器会对每个命令作出回答。即+OK或-ERR
2.IMAP
因特网邮件访问协议(Internet Message Access Protocol,IMAP),它的主要作用是邮件客户端可以通过这种协议从邮件服务器上获取邮件的信息,下载邮件等。当前的权威定义是RFC3501。IMAP协议运行在TCP/IP协议之上,使用的端口是143。
它与POP3协议的主要区别是用户可以不用把所有的邮件全部下载,可以通过客户端直接对服务器上的邮件进行操作。
- POP3协议没有给用户提供任何创建远程文件夹并为报文指派文件夹的方法。IMAP实现了这个功能
- IMAP 的另一个重要特性是它具有允许用户代理获取报文组件(而不是全部)的命令
3.基于Web的电子邮件
只有邮件服务器之间使用 SMTP 协议,而在客户和服务器(发送方或接收方)之间使用 HTTP 协议。在这种服务中,用户代理就是普通的浏览器,用户和他远程邮箱之间的通信通过HTTP进行。
2.4DNS:因特网的目录服务
因特网上的主机可以有多个名字①主机名,比如www.csdn.com或者www.goole.com,这种名字更加被人接收,但几乎没提供任何关于主机在因特网中位置的信息②IP地址 ,一个IP地址由四个字节组成,并有着严格的层次结构。以121.7.106.83为例,每个字节都被句点分隔开,表示课0~255的十进制数字。当从左向右扫描这个IP地址时,会获得越来越具体的位置
2.4.1DNS提供的服务
域名系统(英文:Domain Name System,DNS)是将主机名到IP地址转换的目录服务。DNS是:①一个由分层的DNS服务器(DNS server)实现的分布式数据库②一个使得主机能够查询分布式数据库的应用层协议
DNS服务器通常云心整改BIND软件的UNIX机器。DNS协议运行在UDP上,使用53号端口
与http,FTP,SMTP协议一样,DNS协议是应用层协议,其原因在于:1. 使用客户-服务器模式运行在通信的端系统之间;2. 在通信的端系统之间通过下面的端到段运输协议来传送DNS报文。
DNS通常是由其他应用层协议所使用的,包括HTTP,SMTP和FTP,将用户提供的主机名解析为IP地址
1.主机名到IP地址的转换
如当浏览器请求一个URL www. someschool.edu/index. html页面时,①同一台用户主机上运行着DNS应用的客户端。②浏览器从上述URL中抽取出主机名www.someschool.edu,并将这台注记名传给DNS应用的客户端。③DNS客户向DNS服务器发送一个包含主机名的请求④DNS客户最终会收到一份回答报文,其中含有对应于该主机名的IP地址。⑤一旦浏览器接收到来自DNS的该IP地址,他能够向位于该IP地址的80端口的HTTP服务器进程发起一个TCP连接。
2.主机别名
通常有着复杂主机名的主机能用由一个或者多个别名,应用程序可以调用DNS来获得主机别名对应的规范主机名以及主机IP地址。如一台名为relay1. west-coast. enterprise. com的主机,可能还有两给名为enterprise. com和www. enterprise. com的主机别名。
3.邮件服务器别名
电子邮件应用程序可以调用DNS,对提供的主机名别名进行解析,以获得该主机的规范主机名及其IP地址。同时也允许一个公司的邮件服务器与Web服务器使用相同的主机名。
4.负载分配
DNS也用于在冗余的服务器之间进行负载分配。繁忙的站点(如baidu. com)被冗余分布在多台服务器上,具有多个IP地址。如当客户对映射到某地址集合的名字发出一个DNS请求时,该服务器用IP地址的整个集合进行响应,但在每次回答中循环这些地址次序。因为客户通常总是向IP地址排在最前面的服务器发送HTTP请求报文,所以DNS就在所有这些冗余的web服务器之间循环分配了负载。
2.4.2DNS工作机理概述
从用户主机调用应用程序的角度来看,DNS是一个提供简单、直接的转换服务的黑盒子。然而实际上,实现这个服务的黑盒子非常复杂,它由分布于全球的大量DNS服务器以及定义了DNS服务器与查询主机通信方式的应用层协议组成。
如果为单一DNS服务器:
①单点故障(a single point of failure)如果该DNS服务器瘫痪,则整个因特网随之瘫痪
②通信容量(traffic volume)单个DNS不得不处理所有的DNS查询
③远距离的集中式数据库(distant centralized database)会导致距离服务器较远位置的查询有严重的时延,中间也许还要经过低速和拥塞的链路
④维护(maintenance)单个DNS服务器将不得不为所有的因特网主机保留记录,会导致中央数据库庞大,还必须为新添加的主机频繁更新
1.分布式、层次数据库
分为三种DNS服务器:根DNS服务器、顶级域(Top-Level Domain,TLD)DNS服务器、权威DNS服务器
·根DNS服务器 有400多个根名字服务器遍及全世界。这些根名字服务器由13个不同的组织管理。根名字服务器提供TLD服务器的IP地址
·顶级域DNS服务器 对于每个顶级域(如com\org\net\edu\gov)和所有国家的顶级域(如uk\fr\ca\ip),都有TLD服务器(或服务器集群)。TLD服务器提供了权威DNS服务器的IP地址
·权威DNS服务器 在因特网上具有公共可访问主机的每个组织机构,必须提供公共可访问的DNS记录,这些记录将这些主机名字映射为IP地址。一个组织机构的权威DNS服务器要么存储着这些DNS记录,要么支付费用,让这些记录存储在服务提供商的权威DNS服务器中
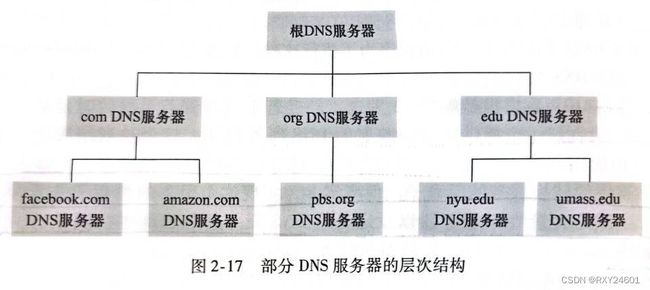
除了以上三种DNS服务器之外,还有本地DNS服务器,实质上并不属于服务器的层次结构,但是对DNS层次结构十分重要。

如上图,假设dns.nyu.edu想要是知道主机gaia.cs.umass.edu的IP地址。
①主机cse.nyu.edu向本地DNS服务器dns.nyu.edu发送一个DNS查询报文②本地DNS将该报文转发至根DNS服务器③本地DNS服务器注意到其有edu前缀,并向本地DNS服务器返回负责edu的TLD的IP地址列表④本地DNS服务器向负责edu前缀的TLD服务器之一发送查询报文⑤TLD注意到umass.edu的前缀,用权威DNS服务器的IP地址进行响应⑥本地服务器直接向dns.umass.edu重发查询报文⑦权威DNS服务器用gaia.cs.umass.edu的IP地址进行响应⑧最后由本地DNS服务器返回给请求主机
在本例中,为了获取一台主机名的映射,发送了8份DNS报文:4份查询报文和4份响应报文。
主机向本地域名服务器的查询一般都是采用递归查询,本地域名服务器向根域名服务器的查询的迭代查询。递归:客户端只发一次请求,要求对方给出最终结果。迭代:客户端发出一次请求,对方如果没有授权回答,它就会返回一个能解答这个查询的其它名称服务器列表,客户端会再向返回的列表中发出请求,直到找到最终负责所查域名的名称服务器,从它得到最终结果。
2.DNS缓存
DNS缓存:为了改善时延性能并减少在因特网删到处传输的DNS报文数量
因为在一个请求链中,当某DNS服务器接受一个DNS回答时,它能将映射缓存在本地存储器中,当下次有另一个对相同主机名的查询到达该DNS服务器时,该DNS服务器就能够提供所需要的IP地址,即使它不是该主机名的权威服务器。
2.4.3DNS记录和报文
共同实现DNS分布式数据库的所有DNS服务器存储了资源记录(Rescource Record,RR),RR提供了主机名到IP地址的映射。每个DNS回答报文包含了一条或多条资源记录。
资源记录是一个四元组:(Name,Value,Type,TTL)。其中Name和Value的值取决于Type
·TTL:是该记录的生存时间,决定了资源记录应当从缓存中删除的时间
·Type=A:则Name是主机名,Value是该主机名对应的IP地址。一条类型为A的资源记录提供了标准的主机名到IP地址的映射。比如(relay1.bar.foo.com,145.37.93.126,A)
·Type=NS:则Name是个域,而Value是个知道如果获取该域中主机IP地址和权威DNS服务器的主机名。比如(foo.com,dns.foo.com,NS)
·Type=CNAME:则Value是别名为Name的主机对应的规范主机名。该记录能够向查询的主机提供一个主机名对应的规范主机名。比如(foo.com,relay1.bar.foo.com,CNAME)获取一般服务器的规范主机名次采用CNAME记录
·Type=MX:则Value是别名为Name的邮件服务器的规范主机名。比如(foo.com,mail.bar.foo.com,MX)MX记录允许邮件服务器主机名具有简单的别名。获取邮件服务器的规范主机名采用MX记录
1.DNS报文
DNS具有查询和响应报文,并且查询和响应具有相同的格式。
1)前十二个字节是首部区域:
①标识符,DNS 报文的 ID 标识。对于请求报文和其对应的应答报文,该字段的值是相同的。通过它可以区分 DNS 应答报文是对哪个请求进行响应的。
②标志,指出该报文是查询报文(0)还是回答报文(1)
![]()
标志字段中每个字段的含义如下:
- QR(Response):查询请求/响应的标志信息。查询请求时,值为 0;响应时,值为 1。
- Opcode:操作码。其中,0 表示标准查询;1 表示反向查询;2 表示服务器状态请求。
- AA(Authoritative):授权应答,该字段在响应报文中有效。值为 1 时,表示名称服务器是权威服务器;值为 0 时,表示不是权威服务器。
- TC(Truncated):表示是否被截断。值为 1 时,表示响应已超过 512 字节并已被截断,只返回前 512 个字节。
- RD(Recursion Desired):期望递归。该字段能在一个查询中设置,并在响应中返回。该标志告诉名称服务器必须处理这个查询,这种方式被称为一个递归查询。如果该位为 0,且被请求的名称服务器没有一个授权回答,它将返回一个能解答该查询的其他名称服务器列表。这种方式被称为迭代查询。
- RA(Recursion Available):可用递归。该字段只出现在响应报文中。当值为 1 时,表示服务器支持递归查询。
- Z:保留字段,在所有的请求和应答报文中,它的值必须为 0。
- rcode(Reply code):返回码字段,表示响应的差错状态。当值为 0 时,表示没有错误;当值为 1 时,表示报文格式错误(Format error),服务器不能理解请求的报文;当值为 2 时,表示域名服务器失败(Server failure),因为服务器的原因导致没办法处理这个请求;当值为 3 时,表示名字错误(Name Error),只有对授权域名解析服务器有意义,指出解析的域名不存在;当值为 4 时,表示查询类型不支持(Not Implemented),即域名服务器不支持查询类型;当值为 5 时,表示拒绝(Refused),一般是服务器由于设置的策略拒绝给出应答,如服务器不希望对某些请求者给出应答。
③问题数,DNS 查询请求的数目
④回答RR数,DNS 响应的数目
⑤权威RR数,权威服务器的数目
⑥附加RR数,额外的记录数目(权威服务器对应 IP 地址的数目)
2)问题区域包含着正在进行的查询信息:
①名字字段,包含正在被查询的主机名字。一般为要查询的域名,有时也会是 IP 地址,用于反向查询。
②类型字段,指出有关该名字的正被询问的问题类型。DNS 查询请求的资源类型。通常查询类型为 A 类型,表示由域名获取对应的 IP 地址。
3)DNS报文中最后的三个字段,回答字段、授权字段和附加信息字段,均采用一种称为资源记录RR(Resource Record)的相同格式。这三个字段被称为资源记录部分,只存在DNS响应报文中
回答区域包含对最初请求的名字的资源记录;权威区域包含其他权威服务器的记录;附加区域包含了其他有帮助的记录;
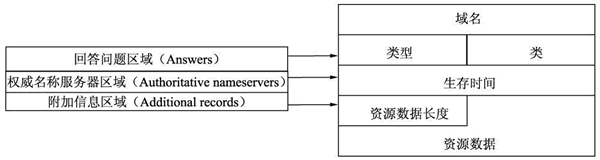
- 域名:DNS 请求的域名。
- 类型:资源记录的类型,与问题部分中的查询类型值是一样的。
- 类:地址类型,与问题部分中的查询类值是一样的。
- 生存时间:以秒为单位,表示资源记录的生命周期,一般用于当地址解析程序取出资源记录后决定保存及使用缓存数据的时间。它同时也可以表明该资源记录的稳定程度,稳定的信息会被分配一个很大的值。
- 资源数据长度:资源数据的长度。
- 资源数据:表示按查询段要求返回的相关资源记录的数据。
2.在DNS数据库中插入记录
①向登记注册机构提供两个权威DNS服务器的NS记录和A记录,并将其插入到TLD中
②将Web服务器的A记录和mail服务器的MX记录插入我的权威服务器中,如果Web服务器有多个IP地址,则每个IP地址对应一个A记录
2.5P2P文件分发
1.P2P体系结构的扩展性
设定:us表示服务器接入链路上的上载速率;ui表示第i对等方接入链路的上载速率;di表示了第i对等方接入链路的下载速率;F表示被分发的文件长度;N表示要获得的该文件符文的对等方的数量。
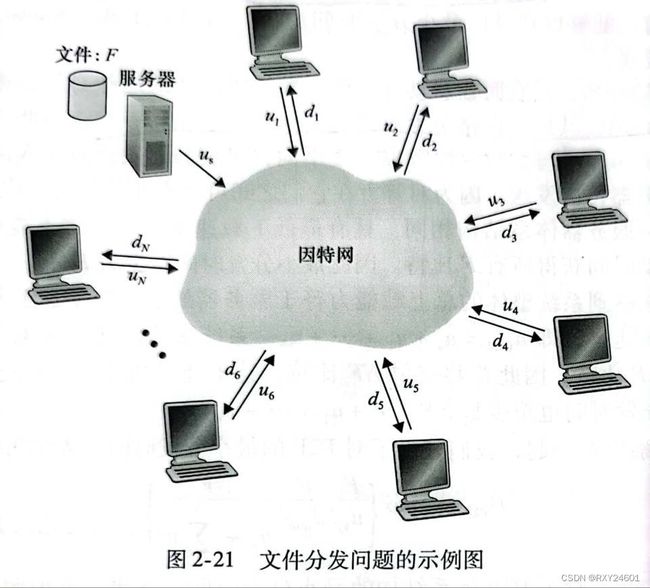
分发时间(distribution time)是所有N个对等方的到该文件符文所需要的时间
对于客户-服务器体系结构的分发时间:
这里用Dcs表示客户-服务器体系结构的分发时间。
- 服务器必须向N个对等方的每个传输该文件的一个副本。因此该服务器必须传输NF比特。因为该服务器的上载速率是us,分发该文件的时间必定是至少为NF/us。
- 令dmin表示具有最小下载速率的对等方的下载速率,即dmin=min{d1,dp,…,dN}。具有最小下载速率的对等方不可能在少于F/dmin秒时间内获得该文件的所有F比特。因此最小分发时间至少为F/dmin。
这里选取Dcs的下界为实际的分发时间。对足够大的N,客户-服务器分发时间由NF/us确定。所以,该分发时间随着对等方N的数量线性地增加
如果从某星期到下星期对等方的数量从1000增加了1000倍,到了100万,将该文件分发到所有对等方所需要的时间就要增加1000倍。
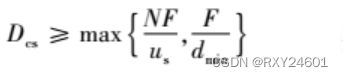
对于P2P体系结构的分发时间:
- 在分发的开始,只有服务器具有文件。为了使社区的这些对等方得到该文件,该服务器必须经其接入链路至少发送该文件的每个比特一次。因此,最小分发时间至少是F/us。(与客户-服务器方案不同,由服务器发送过一次的比特可能不必由该服务器再次发送,因为对等方在它们之间可以重新分发这些比特。)
- 与客户-服务器体系结构相同,具有最低下载速率的对等方不能够以小于F/dmin秒的分发时间获得所有F比特。因此最小分发时间至少为F/dmin。
- 最后,观察到系统整体的总上载能力等于服务器的上载速率加上每个单独的对等方的上载速率,即utotal=us+u1+…+uN。系统必须向这N个对等方的每个交付(上载)F比特,因此总共交付NF比特。这不能以快于utotal的速率完成。因此,最小的分发时间也至少是NF/(us+u1+…+uN)。
这里选取Dp2p的下界为实际的分发时间,其中假定所有的对等方具有相同的上载速率u
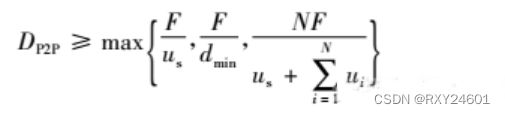
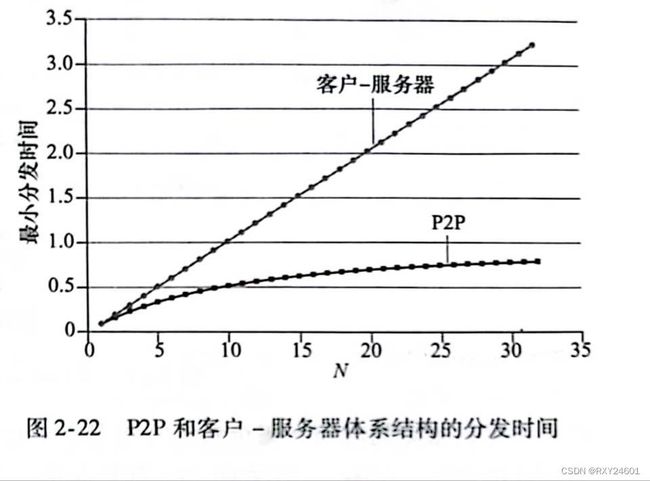
设置了F/u=1小时,us=10u,dmin≥us。因此,在一个小时中一个对等方能够传输整个文件,该服务器的传输速率是对等方上载速率的10倍,并且对等方的下载速率被设置得足够大,使之不会产生影响。
对于客户-服务器体系结构,随着对等方数量的增加,分发时间呈线性增长并且没有界。
对于P2P体系结构,最小分发时间不仅总是小于客户-服务器体系结构的分发时间,并且对于任意的对等方数量N,总是小于1小时。因此,具有P2P体系结构的应用程序能够是自扩展的。这种扩展性的直接成因是:对等方除了是比特的消费者外还是它们的重新分发者。
2.BitTorrent
比特流(BitTorrent)是一种内容分发协议。它采用高效的软件分发系统和点对点技术共享大体积文件(如一部电影或电视节目),并使每个用户像网络重新分配结点那样提供上传服务。
参与一个特定文件分发的所有对等方的集合被称为一个洪流(torrent)
一个洪流中对等方彼此下载等长度的文件块(chunk),典型的块长度为256kb
每个洪流具有一个基础设施节点,称为追踪器(tracker)。当一个对等方加入某洪流时,它向追踪器注册自己,并周期性的通知追踪器它仍在该洪流中。
分配器或文件的持有者将文件发送给其中一名用户,再由这名用户转发给其它用户,用户之间相互转发自己所拥有的文件部分,直到每个用户的下载都全部完成。这种方法可以使下载服务器同时处理多个大体积文件的下载请求,而无须占用大量带宽。下载的人越多,每个下载者将已经下载的数据提供给其他下载者下载,下载速度越快。
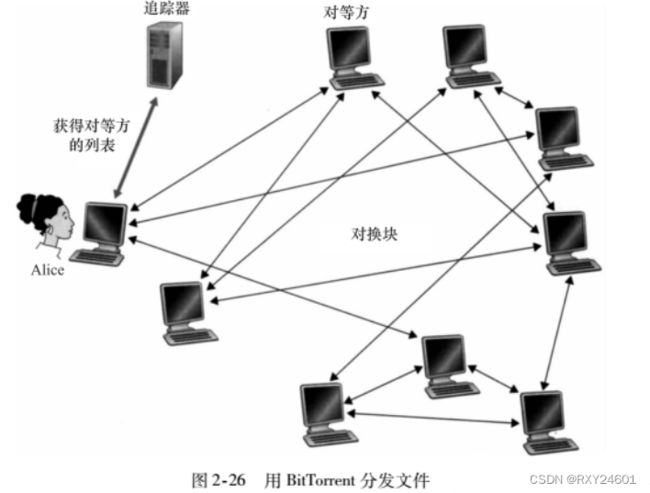
①新对等方RXY加入洪流,追踪器向其随机反馈当前洪流中的部分对等方
②RXY向追踪器反馈的所有对等方请求TCP连接,成功连接的对等方被称为"领近对等方"。之后这些对等方可能流逝,其他除了追踪器最开始反馈的对等方也会向RXY尝试建立TCP连接。所以一个对等方的邻近对等方随时间变化波动
③在任何给定的时间,每个对等方将具有来自该文件的块子集,并且不同的对等方具有不同的子集。RXY通过TCP连接周期性的向邻近对等方询问邻近对等方拥有的块列表。
④RXY通过最稀缺优先(rarest first)技术决定从邻近对等方获取那些块。最稀缺的块就是那些在她的邻居中副本数量最少的块。最稀缺优先技术:选择自己没有并且邻居中副本最少的块优先请求
⑤RXY通过对换算法决定向哪些跟自己请求块的邻居发送自己拥有的块。RXY通过持续监测自己接受比特的速率,选择自己以最高速率接收块的几个邻居。并根据速率不断更换使自己的邻居始终保持最高速率。这种效果使对等方能够以趋向于找到彼此的协调的速率上载。随机选择邻居也允许新的对等方得到块,因此它们能够具有对换的东西。
2.6视频流和内容分发网
2.6.1因特网视频
流式储存视频应用就是预先录制好的视频放置在服务器上,用户按需向这些服务器发送请求来观看视频。
视频时一系列的图形,通常是以一种恒定的速率来展现。一幅未压缩、数字编码的图像由像素阵列组成,其中每个像素是由一些比特编码来表示亮度和颜色。视频可以被压缩,用比特率来权衡视频质量,比特率越高、图像质量越好。
压缩生成一个视频的多个版本,也就是一个视频的不同分辨率
2.6.2HTTP流和DASH
1.HTTP流
在HTTP流中,视频只是存储在HTTP服务器中作为一个普通的文件,每个文件有一个特定的URL。流式视频应用程序周期性的从客户应用程序缓存中抓取帧,对这些帧解压缩并且在用户屏幕上展现。流式视频应用接收到视频就进行播放,同时缓存该视频后面部分的帧。
缺陷:所有客户接收到相同编码的视频
2.DASH
经HTTP的动态适应性流(Dynamic Adaptive Streaming over HTTP,DASH)。在DASH中视频编码为几个不同的版本,每个版本对应不同的比特率,客户动态的请求不同版本且长度为几秒的视频端数据块,把视频分割成一小段一小段, 通过HTTP协议进行传输,客户端得到之后进行播放
使用DASH后,每个视频版本存储在HTTP服务器中,每个版本都有一个不同的URL。
-
更为有效地将MPEG的媒体通过HTTP协议,以自适应、渐进式、下载或流的方式进行内容分发;
-
支持直播业务;
-
更为有效地利用传统的基于HTTP的CDN网络、代理Server或防火墙等网络基础部件;
-
支持与内容保护系统的结合,完成对内容的保护。
DASH最直观的使用就是在b站视频,从主页点进视频时会根据当前带宽决定最开始的视频分辨率,进入视频加载后就会开始播放,看视频的中途也可以随时更换清晰度,更换不同的清晰度中间需要一定的加载时间。 不同的清晰度就是同一个视频的不同比特率,通过不同的URL切换报文。
2.6.3内容分发网
建立单一的大规模数据中心:
①用户远离数据中心,服务器响应分组将跨越许多通信链路和ISP,如果中间任一链路吞吐量小于视频消耗速率,就会增加停滞时延。
②热门视频经过相同的通信链路发送很多次,浪费网络带宽。因特网视频公司因为重复发送相同的字节需要向ISP支付大量费用
③如果数据中心崩溃,全世界视频网络全部崩溃,不能分发任何视频流。
内容分发网:
内容分发网(Content Distribution Network,CDN)。CDN可以是专用CDN(private CDN),由内容提供商自己所有;也可以是第三方CDN(third-party CDN),为多个内容提供商分发内容
·节省骨干网带宽,减少带宽需求量;
·提供服务器端加速,解决由于用户访问量大造成的服务器过载问题;
·服务商能使用Web Cache技术在本地缓存用户访问过的Web页面和对象,实现相同对象的访·问无须占用主干的出口带宽,并提高用户访问因特网页面的相应时间的需求;
·能克服网站分布不均的问题,并且能降低网站自身建设和维护成本;
·降低“通信风暴”的影响,提高网络访问的稳定性。
CDN通常采用两种不同的服务器安置原则:
深入(Enter Deep):通过在遍及全球的接入ISP中部署服务器集群来深入ISP接入网中。选取多个位置大量布置集群,靠近端用户,通过减少端用户和CDN集群之间的链路和路由器数量,改善用户感受到的时延和吞吐量。
这种高度分布式的方法使得维护和管理集群的任务成为挑战。
邀请做客(Bring Home):通过在少量关键位置设置大集群来邀请到ISP做客,不是将集群放在接入ISP中,而是将CDN放在IXP(因特网交换点)中。
这种方法产生较低的维护和管理开销,但是对端用户以较高的时延和较低的吞吐量为代价。
1.CDN操作
当用户主机中的一个浏览器指令检索一个特定的视频,CDN会截获该请求从而①确定此时适合用于客户的CDN服务器集群②将客户的请求重新定向到该集群的某台服务器
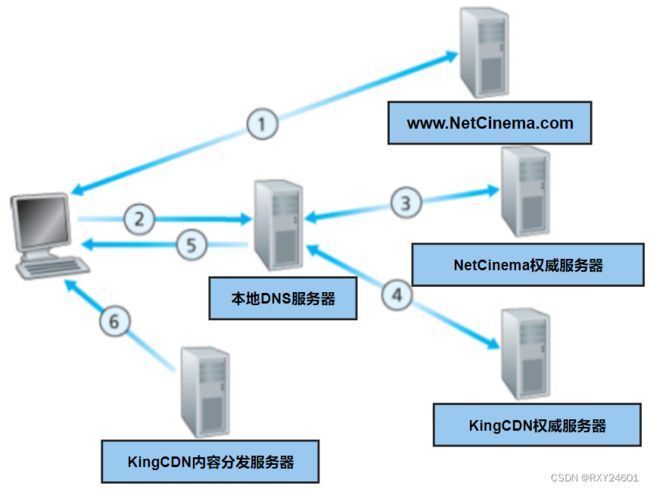
以上是一个内容提供商NetCinema通过第三方CDN公司KingCDN向客户分发视频的流程图。
①用户访问NetCinema的Web网页
②用户点击视频URL连接http://video.netCinema.com/6Y7B23V,用户主机发送一个对于video.netcinema.com的DNS请求
③本地DNS服务器将该DNS请求中继到一台NetCinema权威服务器,该服务器观察到主机名中的video。为了将该DNS请求转交给KingCDN,NetCinema权威DNS服务器并不返回一个IP地址,而是向本地DNS服务器返回一个KingCDN域的主机名
④本地DNS服务器发送第二个请求,即对KingCDN权威服务器的DNS请求。KingCDN权威服务器返回一个内弄服务器的IP地址
⑤本地DNS服务器向用户主机返回内容分发服务器的IP地址
⑥用户主机直接向KingCDN内容分发服务器发送TCP连接请求,并且发出视频的请求连接
2.集群选择策略
集群选择策略(cluster selection strategy)动态地将客户定向到CDN中某个服务器集群或者数据中心。是任何CDN部署的核心。
- 地理最近原则(geographically closest)
- 忽略了网络实际情况
- 有些终端可能被配置为使用远程 LDNS,这种情况忽略了时延和可用带宽变化
- 网络最快原则
- 需要实时监测网络延迟,但有些服务器可能不接受延迟测试
2.6.4学习案例
1.Netflix

- 网飞同时使用亚马逊云与专属CDN
- 亚马逊云负责一些复杂的或统筹的工作
- 内容接收
- 内容处理
- 创建同一个视频文件的多个版本以支持 DASH
- 内容分发
- 内容会被分发给各个 CDN
- 网飞的网络结构采取“推”模式,所有的视频内容都会被定期推向所有的CDN
- 网飞不需要借助 DNS 进行重定向,运行在亚马逊云的软件会直接确定最佳的CDN,并将其域名发送给客户端
2.YouTube
- YouTube(现已被Google收购),使用“拉”策略+DNS重定向
- 利用了 HTTP 的“字节范围请求”来避免流量的浪费
3.KanKan
- CDN-P2P混合,客户首先从CDN服务器请求影片的开头,然后寻找同级的主机。
- 不同于P2P的“传输速率”优先策略,视频播放中会优先选择“能提供持续传输”的主机作为伙伴
- 一旦当前的主机连接满足了视频播放的需求,客户就会断开与服务器的连接
2.7套接字编程:生成网络应用
网络应用程序有两类:①由协议标准中所定义的操作实现②专用的网络应用程序,应用层协议没有公开发布
应用进程使用传输层提供的服务才能够交换报文,实现应用协议。
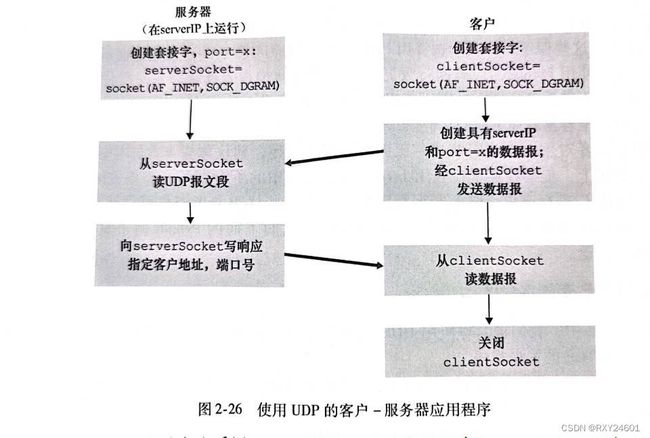
2.7.1UDP套接字编程
UDP在客户端和服务器之间没有连接:没有握手;发送端在一个报文中明确地指定目标的IP地址和端口号;服务器也必须从收到的分组中提取出发送端的IP地址和端口号。
UDP传送的数据可能乱序,也可能丢失。
UDPClient
#UDPClient
from socket import *
serverName = 'servername'
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_DGRAM)
message = input('Input lowercase sentence:')
clientSocket.sendto(message.encode(), (serverName, serverPort))
modifiedMessage, serverAddress = clientSocket.recvfrom(2048)
print(modifiedMessage.decode())
clientSocket.close()①from socket improt * 该socket模块形成了在Python中所有网络通信的基础
②serverName = '8.8.8.8' 将变量serverName设置为字符串“hosthome”,提供包含服务器的IP地址或者包含服务器的主机名的字符串。如果使用主机名,则自动执行DNS lookup从而得到IP地址
③serverPort = 12000 将整数变量serverPort设置为12000
④clientSocket = socket(AF_INET, SOCK_DGRAM) 创建客户的套接字,成为clientSocket。第一个参数指示地址簇,AF_INET指示底层网络使用了IPv4。第二个参数指示类型,SOCK_DGRAM指示clienSocket是一个UDP套接字。创建套接字的过程中并没有明确的指出客户套接字的端口号。
⑤message = input('Input lowercase sentence:') 提示用户输入一串小写字符,并将其存取message中
⑥clientSocket.sendto(message.encode(), (serverName, serverPort)) ④⑤设立了一个套接字和一个报文之后,将套接字向目的主机发送报文。这里通过encode()实现向套接字发送字节,sendto()为报文附上目标地址(serverName,serverPort)并向进程的套接字clientSocket发送结果分组
⑦modifiedMessage, serverAddress = clientSocket.recvfrom(2048) 当来自因特网的分组到达用户套接字时,数据存放在modifiedMessage中,源地址存放在serverAddress中。变量serverAddress包含服务器的IP地址和服务器的端口号。方法recvfrom取缓存长度2048作为输入
⑧print(modifiedMessage.decode()) 将报文从字节转化为字符,并打印modifiMessage
⑨clientSocket.close() 关闭套接字,结束进程
UDPServer
#UDPServer
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
serverSocket.bind(('', serverPort))
print("The server is ready to receive")
while True:
message, clientAddress = serverSocket.recvfrom(2048)
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)
①serverSocket.bind(('', serverPort)) 将端口号12000与该服务器的套接字绑定。通过这种方式为套接字分配一个端口号,轴任何人向该服务器的IP地址的端口12000发送一个分组,分组都将导向该套接字。
②进入while循环 循环是的UDPServer能持续的接收并且处理来自用户的分组
③message, clientAddress = serverSocket.recvfrom(2048) 当分组到达服务器的套接字时,分组的数据存放在变量message中,源地址存放在变量clientAddress中。变量clientAddress中存放客户的IP地址和客户的端口号。UDPServer利用该地址信息,明确报文发送目的地。
④modifiedMessage = message.decode().upper() 将报文转化为字符串后,获取用户发送的字符串行,并用方法upper()将其转换为大写
⑤serverSocket.sendto(modifiedMessage.encode(), clientAddress) 将用户的地址(IP地址和端口号)附在大写的包文章,并将所得到的分组发送给服务器的套接字。由因特网将分组发送到用户地址。服务器在发送报文之后并不关闭,在while循环中等待(任一主机上的任何用户发送的)另一个UDP分组到达。
2.7.2TCP套接字编程
TCP在客户端和服务器之间有连接:有握手;发送端在一个报文中明确地指定目标的IP地址和端口号;服务器也必须从收到的分组中提取出发送端的IP地址和端口号。
应用程序角度:TCP在客户端和服务器进程间提供了可靠的,字节流服务
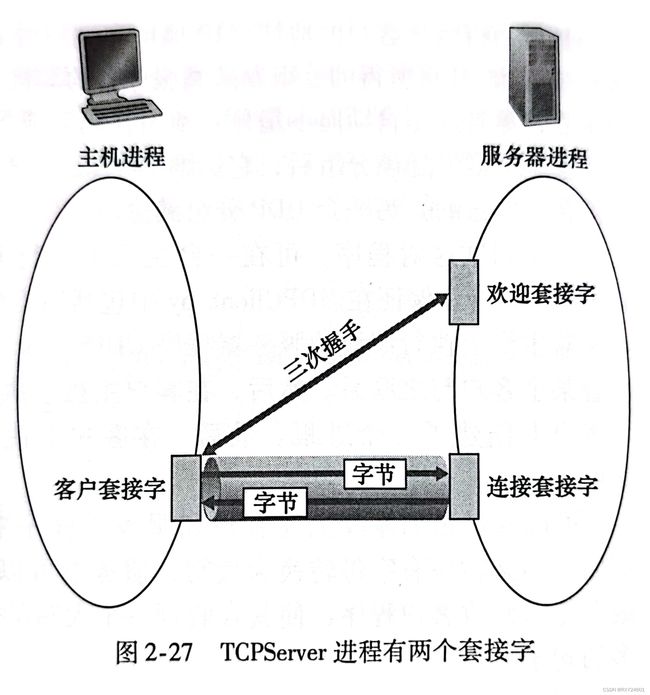
1.服务器首先运行,等待连接建立:创建欢迎socket;和本地端口捆绑;在欢迎socket上阻塞式等待接收用户的连接
2.客户端主动和服务器建立连接:创建客户端本地套接字(隐式捆绑到本地port);指定服务器进程的IP地址和端口号,与服务器进程连接
3.连接API调用有效时,客户端与服务器建立TCP连接
4.当客户端连接请求到来时:服务器接收来自用户端的请求,解除阻塞式等待,返回一个新的socket(与欢迎socket不同),与客户端通信。允许服务器与多个客户端通信,使用源IP和源端口来区分不同的客户端

TCPClient
#TCPClient
from socket import *
serverName = 'servername'
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((serverName, serverPort))
sentence = input('Input lowercase sentence:')
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print('From Server:', modifiedSentence.decode())
clientSocket.oclose()①clientSocket = socket(AF_INET, SOCK_STREAM) 创建用户套接字。第一个参数指示底层网络使用IPv4,第二个参数指示该套接字是TCP套接字。当我们创建该客户套接字时仍未指定其端口号
②clientSocket.connect((serverName, serverPort)) 发起客户与服务器之间的TCP连接。connect()中的参数是服务器端的地址。这条代码执行完后,执行三次握手,并在客户和服务器之间建立一条TCP连接
③sentence = input('Input lowercase sentence:') 从用户处获取一行字符串
④clientSocket.send(sentence.encode()) 通过用户的套接字并进入TCP连接发送字符串sentence。该程序并未显示地创建一个分组并未该分组附上目的地址,而UDP套接字却需要。该客户程序指示将字符串sentence中的字节放入TCP连接中。用户等待接收来自服务器的字节
⑤modifiedSentence = clientSocket.recv(1024) 字符到达服务器后,存放在字符串modifiedSentence中,累计保存直至以回车符结束。打印大写句子之后,关闭客户的套接字
⑥clientSocket.oclose() 关闭套接字,同时关闭了客户和服务器之间的TCP连接。引起客户中的TCP向服务器中的TCP发送一条TCP报文
TCPServer
#TCPServer
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_STREAM)
serverSocket.bind(('', serverPort))
serverSocket.listen(1)
print("The server is ready to receive")
while True:
connectionSocket,addr=serverSocket.accept()
sentence=connectionSocket.recv(1024).decode()
capitalizedSentence=sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
connectionSocket.close()①serverSocket = socket(AF_INET, SOCK_STREAM) 将服务器的端口号serverPort与该套接字关联起来
②serverSocket.bind(('', serverPort)) serverPort是TCP中的欢迎套接字
③serverSocket.listen(1) 让服务器聆听来自客户的TCP连接请求,参数定义了请求连接的最大数
④connectionSocket,addr=serverSocket.accept() 调用accept()方法,在服务器中创建一个新套接字connectionSocket,为特定用户使用。客户与服务器完成握手。在客户的clientSocket与服务器的serverSocket之间建立TCP连接,之后能够通过连接互相发送字节
⑤connectionSocket.close() 关闭该连接套接字,但serverSocket保持打开。其他客户仍然能实现功能