RocketMQ安装使用及基本原理
RocketMQ安装使用及基本原理
- 前言
- 安装
-
- 单机安装
- docker安装
- docker下RocketMQ管理工具安装
- RocketMQ
-
- MQ作用及缺点
- MQ相关产品
- 生产者发送消息的方式
-
- **一、普通消息**
- 二、顺序消息
- 三、广播消息
- 四、延时消息
- 五、批量消息
- 六、过滤消息
- 七、事务消息
- 重要概念
- 集群搭建
- 高级功能
-
- 消息存储
- 消息投递
- 消息重试
- 死信队列
-
- 消费幂等
- Rebalance
前言
RocketMQ官网
RocketMQ是阿里巴巴基于Kafka所做的消息中间件。
安装
单机安装
1、下载zip包
2、unzip rocketmq-all-4.8.0-bin-release.zip
3、进入bin目录普通启动./mynamesrv ./mqbroker
后台模式启动
#需要先启动Name Server(注册中心)
nohup ./rocketmq-all-4.8.0-bin-release/bin/mqnamesrv > /dev/null 2>1 &
#需要指定Server地址用于注册
nohup ./rocketmq-all-4.8.0-bin-release/bin/mqbroker -n (本机ip):9876 autoCreateTopicEnable=true > /dev/null 2>1 &
查看服务 ps -ef|grep mq
测试发消息和接受消息服务是否成功
bin目录下执行sh tools.sh org.apache.rocketmq.example.quickstart.Producer 和 sh tools.sh org.apache.rocketmq.example.quickstart.Consumer
注:环境中必须有JDK且JDK必须是1.8以上
RocketMQ配置默认是生产环境配置,设置的jvm的内存值较大,如果想修改默认值可以找runserver.sh和runbroker.sh文件,编辑
JAVA_OPT=”${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn125m -XX:MetaspaceSize=128m -
XX:MaxMetaspaceSize=320m”
配置/etc/profile文件添加export NAMESRV_ADDR=(本机ip):9876
刷新配置source /etc/profile
docker安装
#搜索有哪些docker容器可以使用,这里选择docker.io/foxiswho/rocketmq 4.5.1版本
docker search rocketmq
docker pull foxiswho/rocketmq:broker-4.5.1
docker pull foxiswho/rocketmq:server-4.5.1
#创建server
docker run -di -p 9876:9876 --name=rmqserver01 -e "JAVA_OPT_EXT=-server -Xms128m -Xmx128m -Xmn128m" -e "JAVA_OPTS=-Duser.home=/opt" foxiswho/rocketmq:server-4.5.1
#创建broker
docker run -di -p 10911:10911 -p 10909:10909 --name=rmqbroker01 -e "JAVA_OPTS=-Duser.home=/opt" -e "JAVA_OPT_EXT=-server -Xms128m -Xmx128m -Xmn128m" foxiswho/rocketmq:broker-4.5.1
#配置broker
#docker inspect rmqbroker #查看ipaddress 不用
docker exec -it rmqbroker01 /bin/bash
cd /etc/rocketmq/
vim broker.conf
#添加如下
#brokerIP1 = [ipaddress地址] 不用
brokerIP1 = [本机的ip]
namesrvAddr = [本机的ip]
docker下RocketMQ管理工具安装
#拉取镜像
docker pull styletang/rocketmq-console-ng:1.0.0
#创建并启动容器
docker run -e "JAVA_OPTS=-Drocketmq.namesrv.addr=[namesrvAddr地址]:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false" -p 8082:8080 -t styletang/rocketmq-console-ng:1.0.0
可以在ip:8082进行访问

RocketMQ
**MQ(Message Queue)**消息队列是基础数据结构中先进先出的数据结构。在消息传输过程中保存消息的容器,使生产者和消费者不直接通讯,依靠队列保证消息的可靠性,避免系统间相互影响。
producer->queue->consumer
MQ作用及缺点
一、作用
异步解耦,削峰填谷
1、异步解耦
订单系统与支付、库存、物流系统的联系,中间添加MQ,各个子系统用松耦合方式通信,当某个系统宕机后,(服务降级),其他系统依然可以使用。即是异步解耦
2、削峰填谷
在高并发情况下使请求进行排队等待,保证系统的稳定性。
3、其他
顺序收发
分布式事务一致性
大数据分析
分布式缓存同步
二、缺点
不能完全代替RPC
系统可用性降低
系统的复杂度提高
一致性问题
MQ相关产品
业界的MQ有Kafka、RabbitMQ、ActiveMQ、ApachePulsar
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 时效性 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 可用性 | 高,基于主从架构 | 高,基于主从架构 | 非常高,基于分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有较低概率丢失 | 经过参数优化,可以零丢失 | 经过参数优化,可以零丢失 | |
| 客户端语言 | Java、c++、python | java | java、c++、go、python | |
| 应用 | 用于解耦和异步,较少用于大规模吞吐 | 都有使用 | 用于大规模吞吐、复杂业务中 | 在大数据的实时计算和日志采集中被大规模使用,是业界标准 |
| 消息方式 | RocketMQ | RabbitMQ | Kafka |
|---|---|---|---|
| 顺序消息 | 支持 | 支持 | 支持 |
| 延时消息 | 不支持 | 只支持特定Level | 不支持 |
| 事务消息 | 不支持 | 支持 | 不支持 |
| 消息过滤 | 不支持 | 支持 | 支持 |
| 消息查询 | 不支持 | 支持 | 不支持 |
| 消息失败重试 | 支持 | 支持 | 不支持 |
| 批量发送 | 不支持 | 支持 | 支持 |
总结:
只普通使用推荐RabbitMQ
在阿里云部署或想自主改造MQ推荐RocketMQ
大数据、日志、流式推荐Kafka
生产者发送消息的方式
一、普通消息
1、同步
发送完消息后接受返回成功或失败的结果,在接收结果前进行等待同步
2、异步
发送完消息后会接收结果,但不影响继续运行
底层new Runnable进行执行任务
3、单向
发完消息后不接收返回结果
| 发送方式 | 发送TPS | 发送结果反馈 | 可靠性 |
|---|---|---|---|
| 同步发送 | 快 | 有 | 不丢失 |
| 异步发送 | 快 | 有 | 不丢失 |
| 单向发送 | 最快 | 无 | 可能丢失 |
单个消费者会用多线程方式消费消息
二、顺序消息
topic是逻辑概念
假如Topic是一条公路,Queue则是车道
即一个Topic被分成多个队列,Queue并行发送和接收消息
消费者发送的多条消息让消费者按顺序接收需要满足如下三点
1、broker:消息路由到同一个队列,需要自定义路由选择器
2、消费者:不能采用多线程,需要保证单线程消费同一个队列
3、生产者:不能使用多线程并发发送
三、广播消息
多个消费者消费者,每个消费者都获取到相同的消息(如电影院)
一般指集群模式
不支持顺序消息,每个消息的消费记录保存在不同位置
四、延时消息
如给定时长未支付,订单取消
通常两种实现方式
1、轮询定时任务
2、延时消息
1)Sleep,工作线程sleep导致普通任务也sleep
2)定时扫描
增大数据库压力
不精准(扫描频率低)
Broker端内置延迟消息的核心实现思路:将延迟消息通过一个临时存储进行暂存,到期后才投递到目标Topic中
producer -> 临时存储 ->delay service(用于唤醒) -> 目标topic -> consumer
高性能 :写入性能要高,关系型数据库通常不满足
高可靠:延迟消息写入后不能丢失,需要进行持久化,并进行备份
支持排序:按某个字段对消息进行排序,对于延迟消息需要按照时间进行排序
RocketMQ不支持任意时间的延时,支持一定数量,按照相同的延迟时间进行排队,放入不同的队列中
消息首先进入CommitLog(用于记录消息内容) 类似Mysql行记录
普通消息进入普通的ConsumeQueue:普通队列,类似Mysql索引
延时消息:不想被消费者马上消费的信息进入内置队列(特殊队列):RocketMQ包含多个,特点:对消费者不可见
Broker内部的类ScheduleMessageService,作为延迟服务,消费SCEHEDULE_TOPIC_XXXX中的消息,并投递到目标Topic中。
在启动时,会创建一个定时器Timer,并根据延迟级别的个数,启动对应数量的TimeTask,每个TimerTask负责一个延迟级别的消费与投递。
RocketMQ内置topic:SCHEDULE_TOPIC_XXXX(即上面提的特殊队列consumeQueue,临时存储),到期后ScheduleMessageService将消息变成普通消息,重新存入CommitLog,变成普通消息等待消费。
投递时间 = 消息存储时间(storeTimeStamp) + 延迟级别对应的时间 被记录在Message Tag HashCode 放在ConsumeQueue
Message Tag HashCode:记录消息Tag的哈希值,用于过滤消息,特别的,对于延时消息,这个字段记录的是消息的投递时间戳,该字段被设计成8个字节,而java中的hashCode只返回4个字节
五、批量消息
构建一个集合作为一个消息
注意:消息大小有上限,单次发送消息有上限:4M (int maxMessageSize = 1024 * 1024 * 4)
//计算单条消息大小
int tempSize = message.getTopic().length() + message.getBody().length;
Map<String,String> properties = message.getProperties();
for(Map.Entry<String,String> entry : properties.entrySet()){
tmpSize+=entry.getKey().length+entry.getValue().length();
}
六、过滤消息
消费者只要拿到部分的生产者的消息
两种方式:
1、使用Tags过滤 (Tags相当于二级分类 ,topic为一级分类)
2、Sql表达式 MessageSelector.bySql
七、事务消息
生产者中有本地事务执行与发送消息给RocketMQ的协调
基于两个阶段提交 prepared 和 commited
1、半消息发送:消息发送方发送半事务消息给服务端,MQ返回发送状态(成功)
2、执行本地事务
3、消息发送方发送事务结果Commit或者Rollback给服务端,若没有收到消息,则会去消息发送方回查事务状态,最终拿到事务的状态Commit/Rollback
4、如果拿到的是Commit则提交给消息订阅方(失败则进行重试,默认16次),如果是Rollback则不投递消息,存储三天后删除。
public interface TransactionListener {
/**
* When send transactional prepare(half) message succeed, this method will be invoked to execute local transaction.
* 执行本地事务,返回三种状态
* @param msg Half(prepare) message
* @param arg Custom business parameter
* @return Transaction state
*/
LocalTransactionState executeLocalTransaction(final Message msg, final Object arg);
/**
* When no response to prepare(half) message. broker will send check message to check the transaction status, and this
* method will be invoked to get local transaction status.
* 消息回查:如果executeLoalTransaction方法返回UNKNOW,RocketMQ会检查生产者的本地事务执行状态
* @param msg Check message
* @return Transaction state
*/
LocalTransactionState checkLocalTransaction(final MessageExt msg);
}
public enum LocalTransactionState {
COMMIT_MESSAGE,
ROLLBACK_MESSAGE,
UNKNOW,
}
注意事项:
1、事务消息不支持延时消息和批量消息
2、用户可以通过Broker配置文件transactionCheckMax参数修改回查次数,默认15次,超过则会被丢弃并默认打印错误日志
3、事务性消息可能不止一次被检查或消费需要做幂等性检查
4、事务消息将在Broker的配置文件transactionTimeout的特定时长后被检查。当发送事务消息是,用户还可以通过设置用户属性(CHECK_IMMUNITY_TIME_IN_SECONDS)来改变限制,该参数优先于transactionTimeout
5、提交给用户的目标主题消息可能会失败,目前依日志的记录而定。它的高可用性通过RocketMQ本身的高可用性机制来保证,如果希望确保事务消息不丢失,且保证事务完整性,建议使用同步的双重写入机制。
6、事务消息的生产者ID不能与其他类型消息的生产者ID共享。与其他类型的消息不同,事务消息允许反向查询、MQ服务器能通过他们的生产者ID查询到消费者。
原理
内置Topic:对消费者不可见,而半事务消息则是使用了内置Topic
OP消息 RMQ_SYS_TRANS_OP_HALF_TOPIC 记录二阶段操作,如果是Rollback则只做记录,如果是Commit根据备份信息重新构造消息并投递。回查
HALF消息 RMQ_SYS_TRANNS_HALF_TOPIC 临时存放消息信息,事务消息替换主题,保存原主题和队列信息,半消息对Consumer不可见,不可被投递。
HALF消息如果比OP消息多,则代表有本地事务没有返回消息结果,进行RMQ_SYS_TRANNS_HALF_TOPIC减RMQ_SYS_TRANS_OP_HALF_TOPIC来回查
重要概念
消费者和生产者通过NameServer集群进行服务发现,获取broker节点列表,以进行消费消息和发送消息
producer集群
⬇
broker集群(Master,Slaver) - - -服务注册 - - > NameServer集群(注册中心)
⬆
consumer集群
1、NameServer注册中心
Kafka使用了Zookeeper作为注册中心,Zookeeper提供了选举、分布式锁、数据的发布订阅等功能
由于Rocket只需要最终一致性而不需要强一致性,所以在3.x版本不再依赖Zookeeper转而依赖自己的NameServer。
NameServer没有频繁读写,开销小,稳定性高,每个节点都是独立的,互不通信,没有数据同步,一个挂掉不影响其他,需要broker向每个节点注册。broker每隔30s向NameServer发送信息,而NameServer会记录broker最新的心跳时间,用于判断broker是否存活。
NameServer初始化时会创建一个任务,扫描不活跃的Broker
//NamesrvController类的initialize方法
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
NamesrvController.this.routeInfoManager.scanNotActiveBroker();
}
}, 5, 10, TimeUnit.SECONDS);
public void scanNotActiveBroker() {
//获取broker节点列表
Iterator<Entry<String, BrokerLiveInfo>> it = this.brokerLiveTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, BrokerLiveInfo> next = it.next();
//获取当前broker最新更新,broker服务注册的心跳时间,BROKER_CHANNEL_EXPIRED_TIME = 1000 * 60 * 2 即120s
long last = next.getValue().getLastUpdateTimestamp();
if ((last + BROKER_CHANNEL_EXPIRED_TIME) < System.currentTimeMillis()) {
RemotingUtil.closeChannel(next.getValue().getChannel());
//移除
it.remove();
log.warn("The broker channel expired, {} {}ms", next.getKey(), BROKER_CHANNEL_EXPIRED_TIME);
this.onChannelDestroy(next.getKey(), next.getValue().getChannel());
}
}
}
Broker
提供了消息的接收、存储、拉取等功能
Broker在初始化时会创建一个任务用于发送心跳
//BrokerController类的start方法
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
log.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS);
public synchronized void registerBrokerAll(final boolean checkOrderConfig, boolean oneway, boolean forceRegister) {
TopicConfigSerializeWrapper topicConfigWrapper = this.getTopicConfigManager().buildTopicConfigSerializeWrapper();
if (!PermName.isWriteable(this.getBrokerConfig().getBrokerPermission())
|| !PermName.isReadable(this.getBrokerConfig().getBrokerPermission())) {
ConcurrentHashMap<String, TopicConfig> topicConfigTable = new ConcurrentHashMap<String, TopicConfig>();
for (TopicConfig topicConfig : topicConfigWrapper.getTopicConfigTable().values()) {
TopicConfig tmp =
new TopicConfig(topicConfig.getTopicName(), topicConfig.getReadQueueNums(), topicConfig.getWriteQueueNums(),
this.brokerConfig.getBrokerPermission());
topicConfigTable.put(topicConfig.getTopicName(), tmp);
}
topicConfigWrapper.setTopicConfigTable(topicConfigTable);
}
if (forceRegister || needRegister(this.brokerConfig.getBrokerClusterName(),
this.getBrokerAddr(),
this.brokerConfig.getBrokerName(),
this.brokerConfig.getBrokerId(),
this.brokerConfig.getRegisterBrokerTimeoutMills())) {
doRegisterBrokerAll(checkOrderConfig, oneway, topicConfigWrapper);
}
}
Consumer Group
消费者组
消费者如何快速消费消息
一个消费者组包含多个消费者,同一个队列只能由同一个消费者组下的一个消费者消费
每个队列中有一个offset ,带有组信息,用于指定当前消费者消费消息的位置
多个消费者组可以消费同一队列
集群搭建
一、双主双从集群搭建
brokerClusterName = DefaultCluster 同一个主从节点此名称一致
brokerId = 0为master节点
不能自动切换master节点,需要手动修改,修改完要重启
二、Dledger搭建
可以自动切换master
需要配置dLegerPeers 配置参与选举的端口信息
注:当broker占用10911,也会占用10909和10912,不能使用这几个端口
高级功能
消息存储
目前业界常用的MQ均采用文件系统进行持久化。

commitlog消息真正的物理存储文件,不区分队列,顺序存储
consumequeue消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址

commitLog里放着MappedFile对象,每个MappedFile对象大小1G(102410241024)
MappedFile文件的命名是102410241024 = 1073741824进行递增,名字长度20位,左边补零
例如
00000000000000000000
00000000001073741824
…
文件存着主题,消息,队列id,存储地址
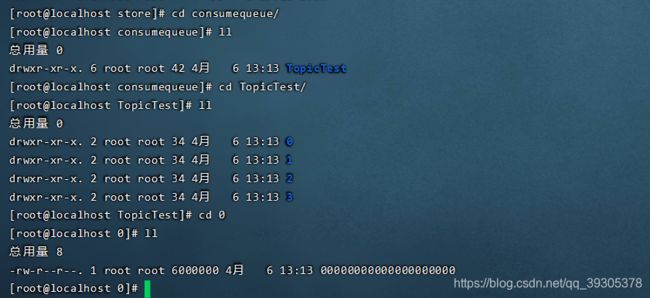
consumequeue里是Topic,包含队列信息,Topic里存着队列,一个queue对应一个consume文件
consumequeue每个节点包含三个部分偏移量,消息长度,TagHashCode
注:RocketMQ消息删除依赖CommitLog的清理机制(RocketMQ自身清理策略)
不依赖消息是否被消费
按时间清理,RocketMQ默认清理3天前的commitLog文件;
按磁盘水位清理,当磁盘使用量达到75%时,开始清理最老的commitLog文件
刷盘机制
分为同步刷盘/异步刷盘 通过flushDiskType参数进行配置
消息投递
默认采用轮询方式
默认方式增强:基于Queue队列轮询算法和消息投递延迟最小的策略投递
优先投递延迟短的消息
随机分配策略
基于Hash分配的策略
消费者在集群模式的消费策略
一个消费者可以订阅多个队列
平均分配算法
环形平均算法
…
consumer方式
MQPullConsumer和MQPushConsumer,本质都是拉方式,即consumer轮询从broker拉取消息。push模式是基于pull实现的,并没有真正实现push
RocketMQ用LongPoll长轮询机制
Consumer发送拉取消息
Broker hold住请求,直到有新消息再返回
请求超时时,则再次发送请求
超时时间默认30s
消息重试
顺序消息重试
顺序消息失败时,RocketMQ会自动不断的重试,间隔为1s,会出现消息阻塞。
无序消息的重试
1、返回了RECUNSUME_LATER,则会进行重试,默认最多16次,每次重试时间间隔会递增,16次总计4小时46分
public enum ConsumeConcurrentlyStatus {
/**
* Success consumption
*/
CONSUME_SUCCESS,
/**
* Failure consumption,later try to consume
*/
RECONSUME_LATER;
}
2、返回了null
3、抛出异常
可以自定义重试次数,当自定义的次数大于16次,则超过的次数为每隔两小时再次重试
死信队列
不能被消费者正常处理的消息被称之为死信消息,将存储死信消息的队列称为死信队列(DLQ Dead-Letter Queue)
死信Topic命名为:%DLQ% + Consumer组名
每个消费者组都有一个死信队列,不是对应单个消费者
如果一个消费者组未产生死信消息,则不会被创建死信队列
对一个消费者组来说,它的所有死信共享一个死信队列
消费幂等
幂等:如果有一个操作,多次执行与一次执行所产生的影响是相同的,称这个操作是幂等的。
RocketMQ能够保证消息不丢失,但不保证消息不重复,消息幂等交给客户端(消费端)
最好的方式是一业务唯一标识作为幂等处理的关键依据如:订单号,流水号等,设置在key上,MessageID可能会出现重复
Rebalance
Rebalance机制是为了提升消息的并行处理能力。Rebalance是重新分配队列和消费者间的关系。
可能会造成消息暂停和消息突增,重复消息(消费了消息但还没有修改offset时rebalance)。