PySpark
 Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing - AMinerSpark 最早源于一篇论文, 该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing - AMinerSpark 最早源于一篇论文, 该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也 是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。
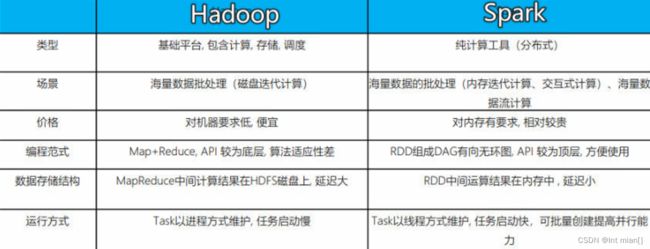
Hadoop VS Spark
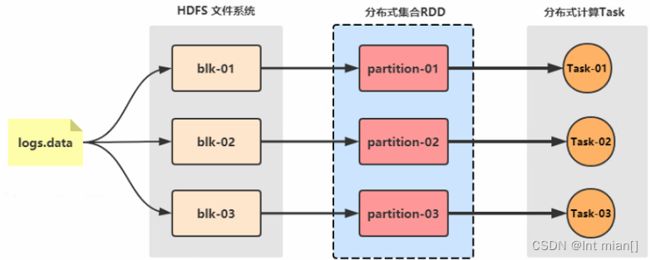
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
搭建、配置
*我的spark部署结构
都在/export/server

python3.8来源Anaconda3,在~/anaconda3
创建了一个pyspark环境
环境变量
export JAVA_HOME=/export/server/jdk1.8.0_291
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/export/server/hadoop-3.3.3
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_CONF_DIR
# spark
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/root/anaconda3/envs/pyspark/bin/python3.8
export PATH=$PATH:$SPARK_HOME/bin
# anaconda3
export ANACONDA_HOME=/root/anaconda3/bin
export PATH=$PATH:$ANACONDA_HOME/bin
#define a environment path
export MYDIR=/mydir
unset MAILCHECK
前置基础知识点
1.Spark用之前还要装Hadoop
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
2.大框架

- SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
- SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
- MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、 Scala、R语言的API,可以编程进行海量离线数据批处理计算。
3.搭建方式:local[*]、集群
之后常用local[*]

Yarn
ResourceManager、NodeManager、ApplicationMaster、Task
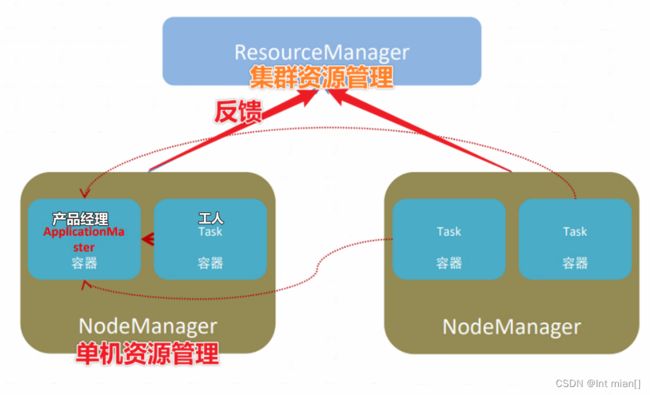
对应Spark架构
ResourceManager
| YARN | Spark | 作用 |
| ResourceManager | Master | 所有机器的爹 |
| NodeManager | Worker | 单机的爹 |
| ApplicationMaster | Driver | 工人头子 |
| Task | Executor | 真正干活的 |

正常情况下Executor是干活的角色,不过在特殊场景下(Local模式)Driver可以即管理又干活
local环境原理、部署
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task,如图K = 2
不携带参数默认就是spark-shell --master local[*]
退出spark-shell,使用 :quit
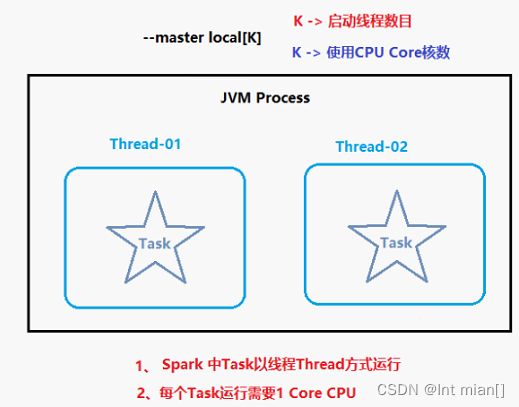

角色分布
资源管理:
- Master:Local进程本身
- Worker:Local进程本身
任务执行:
- Driver:Local进程本身
- Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理 一类是工人)
Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行(Driver是local本身,有只有一个Driver,只能执行一个任务)
部署
装hadoop3.3.3,spark,tar -zxvfspark-3.2.0-bin-hadoop-3.2.tgz,装python3.8(我用的anaconda),配源,配环境变量,启动!有手就行

无交互模式直接提交任务:
spark-submit --master local[*] /export/server/spark/examples/src/main/python/pi.py 2
Standalone环境部署
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理
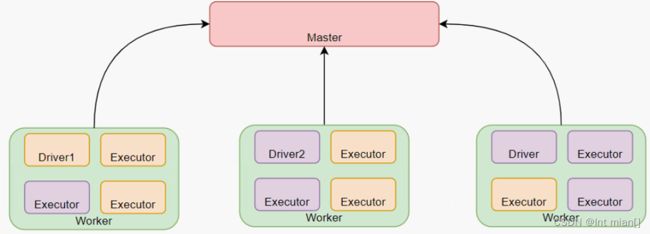
StandAlone 是完整的Spark运行环境,其中:
Master角色以Master进程存在, Worker角色以Worker进程存在
Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行
StandAlone集群在进程上主要有3类进程:
- 主节点Master进程:
Master角色, 管理整个集群资源,并托管运行各个任务的Driver
- 从节点Workers:
Worker角色, 管理每个机器的资源,分配对应的资源来运行Executor(Task); 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
- 历史服务器HistoryServer(可选):
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
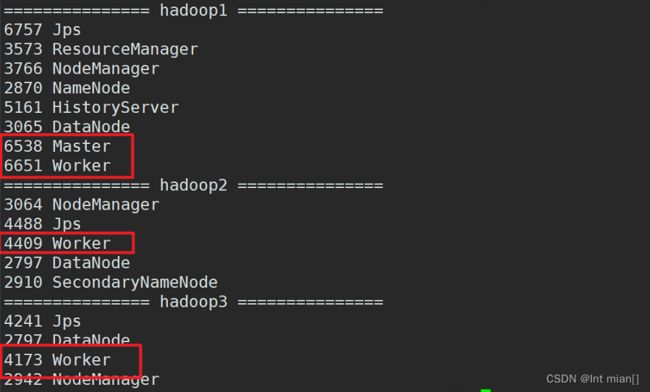
规划架构
hadoop1:master/worker
hadoop2:slave/worker
hadoop3:slave/worker
配置
修改/export/server/spark/conf的worker,添加需要做worker的主机名
修改/export/server/spark/conf的spark-env.sh,添加
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
export SPARK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
## 历史日志服务器
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
启动standalone:sbin/start-all.sh
交互模式启动:还得先进入WebUI,看端口号,./pyspark --master spark://hadoop1:7077(其实这个端口在conf/spark-env.sh指定了)

*日志服务:修改spark-defaults.conf,添加,并且启动hadoop,hadoop fs -mkdir /sparklog
# 开启时间日志功能
spark.eventLog.enabled true
# 路径
spark.eventLog.dir hdfs://hadoop1:8020/sparklog/
# 是否压缩
spark.eventLog.compress true
启动日志服务
![]()
运行架构
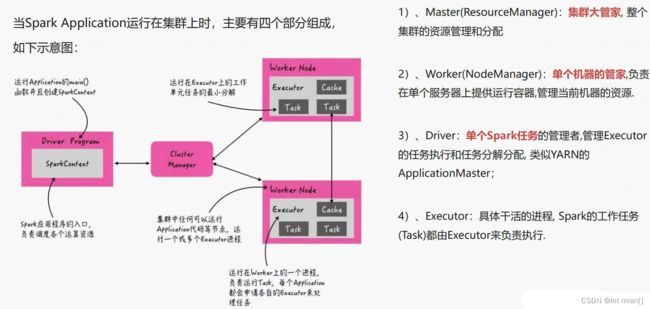
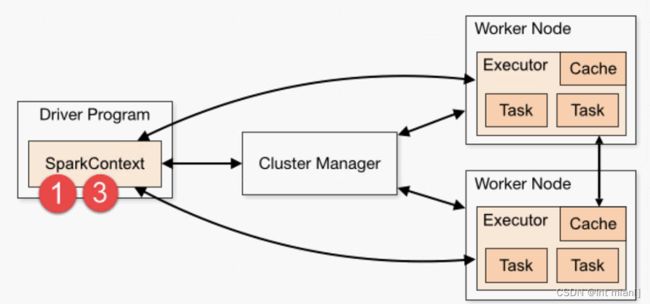
第一、Driver Program
相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
一个SparkApplication仅有一个;
第二、Executors
相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task任务运行需要1 Core CPU,所 有可以认为Executor中线程数就等于CPU Core核数;
一个Spark Application可以有多个,可以设置个数和资源信息;

用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 ClusterManager 会根据用户 提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
2)、Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task;
3)、Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver;
4)、Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新 洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)、Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止;
端口区别
- 4040: 是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态.4040被占用会顺延到4041.4042等 4040是一个临时端口,当前程序运行完成后, 4040就会被注销
- 8080: 默认是StandAlone下, Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态
- 18080: 默认是历史服务器的端口, 由于每个程序运行完成后,4040端口就被注销了. 在以后想回看某个程序的运行状态就可以通过历史 服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程.
- 7077: --master交互命令行端口
运行层次
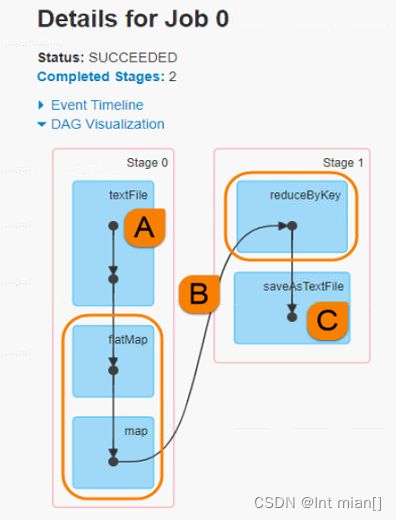
在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的
其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU。
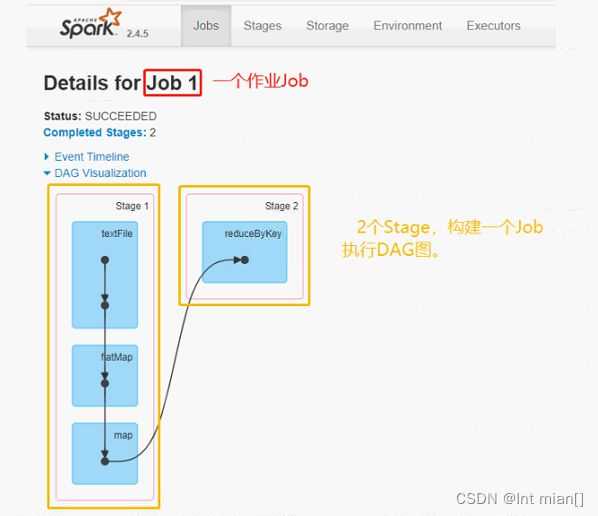

Spark Application程序运行时三个核心概念:Job、Stage、 Task,说明如下:
Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会生成一个 Job。
Stage:一个 Job 会切分成多个 Stage ,Stage 彼此之间相互依赖顺序执行,而每个 Stage 包含多个 Task 的集合,类似 map 和 reduce stage。
Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition (物理层面的概念,即分支可以理解为将数据划分成不同 部分并行处理),就会有多少个 Task,每个 Task 只会处 理单一分支上的数据
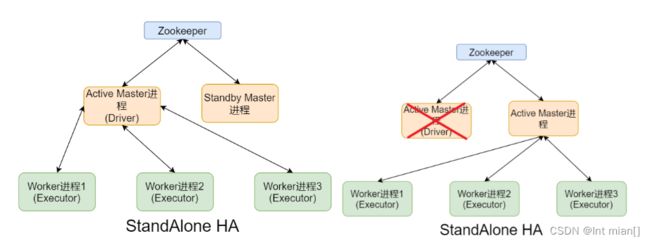
Standalone HA
架构
防止Master寄了,整个集群就寄了,主备切换不影响正在运行的

配置
hadoop1上的spark-env.sh注释掉
# SPARK_MASTER_HOST=node1
增加配置
# spark.deploy.recoveryMode:恢复模式
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
# ZooKeeper的Server地址
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181
# 保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息
-Dspark.deploy.zookeeper.dir=/spark-ha"
启动ZOOKEEPER服务
zkServer.sh status
zkServer.sh stop
zkServer.sh start
node1上启动Spark集群执行
/export/server/spark/sbin/start-all.sh
在node2上再单独只起个master:
/export/server/spark/sbin/start-master.sh

如果将node1的Master进程Kill掉,node2的Master在1Min-2Min左右会接替node1的Master作用。 也就是在执行过程中,使用jps查看Active Master进程ID,将其kill,观察Master是否自动切换与应用运行完成结束。(需要等待1-2min)
★Spark on Yarn
按照前面环境部署中所学习的, 如果我们想要一个稳定的生产Spark环境, 那么最优的选择就是构建:HA StandAlone集群
不过在企业中, 服务器的资源总是紧张的, 许多企业不管做什么业务,都基本上会有Hadoop集群. 也就是会有YARN集群,对于企业来说,在已有YARN集群的前提下在单独准备Spark StandAlone集群,对资源的利用就不高. 所以, 在企业中多数场景下,会将Spark运行到YARN集群中
所以, 对于Spark On YARN, 无需部署Spark集群, 只要找一台服务器, 充当Spark的客户端, 即可提交任务到YARN集群 中运行.
架构
- Master角色由YARN的ResourceManager担任.
- Worker角色由YARN的NodeManager担任.
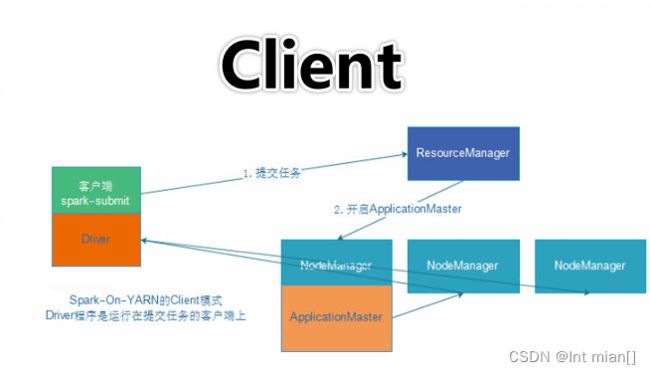
- Driver角色运行在YARN容器内 或 提交任务的客户端进程中
- 真正干活的Executor运行在YARN提供的容器内
关闭hadoop安全模式
hdfs dfsadmin -safemode get
hdfs dfsadmin -safemode leave(我的关不掉,服了!)
配置
spark-env.sh增加,分发hadoop2,3
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
(不配了,配置低!)
两种运行模式
Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式. 这两种模式的区别就是Driver运行的位置
Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中

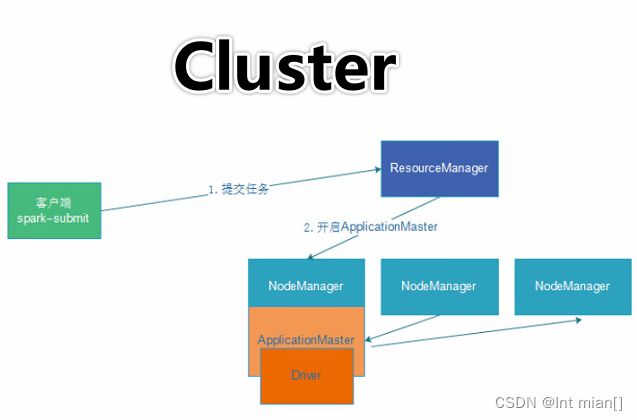
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请 后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开 始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行
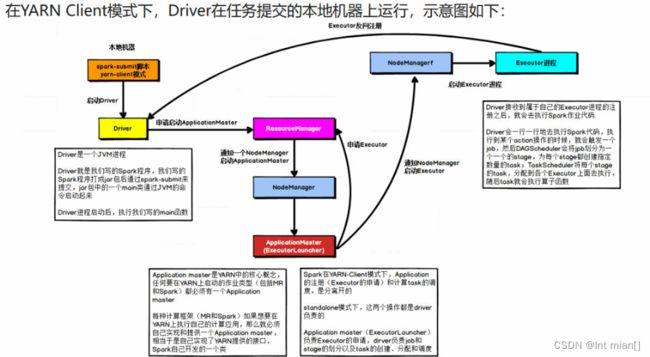
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster ;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后 将Task分发到各个Executor上执行

关掉虚拟机,转战Windows
=======Win========
环境准备
准备python环境,下载pyspark库 ,配环境变量PYSPARK_PYTHON:anaconda的python
WordCount剖析
import os
from pyspark import SparkConf, SparkContext
os.environ['PYSPARK_PYTHON'] = r'D:\Anaconda3\envs\pyspark\python.exe'
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('test-pyspark')
sc = SparkContext(conf=conf)
file_path = './0txt/goodnight.txt'
lines = sc.textFile(file_path)
words = lines.flatMap(lambda line: line.split(' '))
word_one = words.map(lambda x: (x, 1))
res = word_one.reduceByKey(lambda a, b:a+b)
print(res.collect())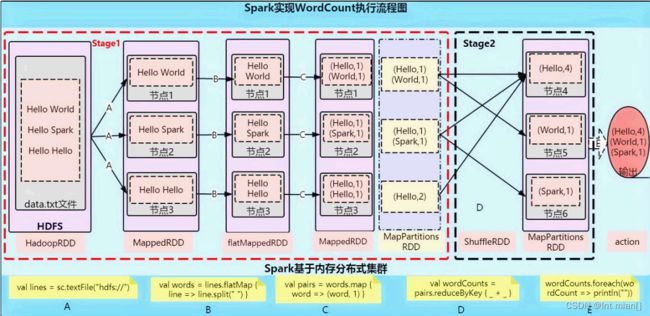
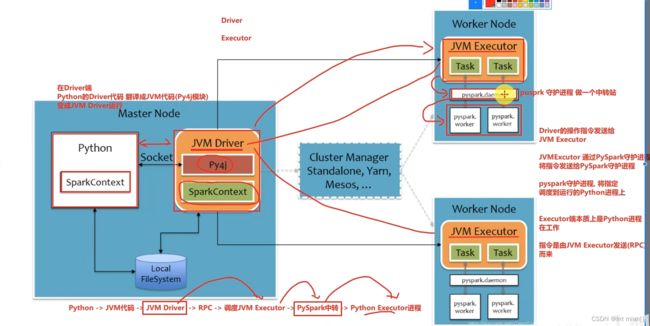
SparkContext对象的构建 以及 Spark程序的退出, 由 Driver 负责执行
具体的数据处理步骤, 由Executor在执行.
非数据处理的部分由Driver工作 数据处理的部分(干活)由Executor工作
python on spark
RDD理论
不能简单的通过Python内置的本地集合对象(如 List\ 字典等)去完成分布式计算,需要一个统一的数据抽象对象RDD:
- 分区控制
- Shuffle控制
- 数据存储\序列化\发送
- 数据计算API
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Dataset:一个数据集合,用于存放数据的。
五大特性图
1、分区
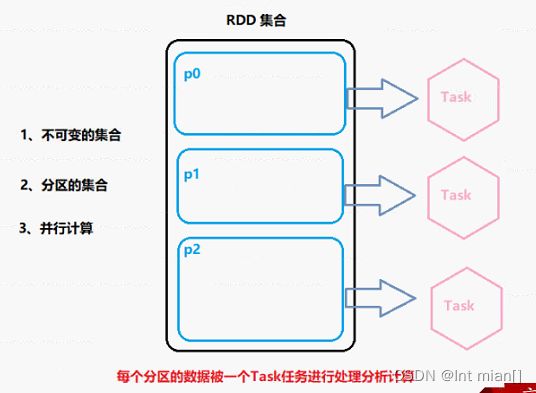
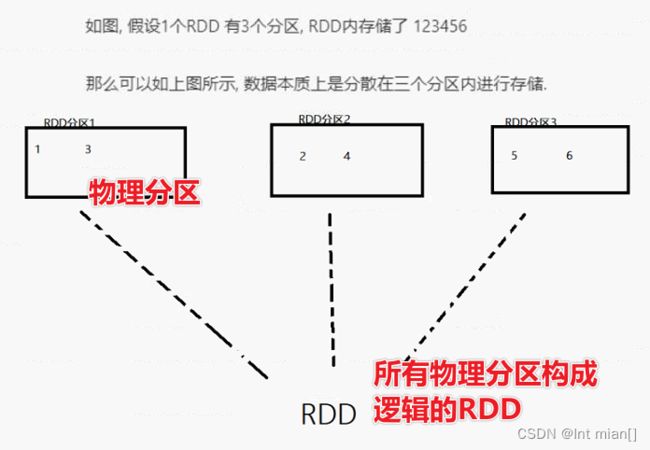
2、对逻辑RDD计算应用到每个物理分区


3、RDD有相互依赖关系

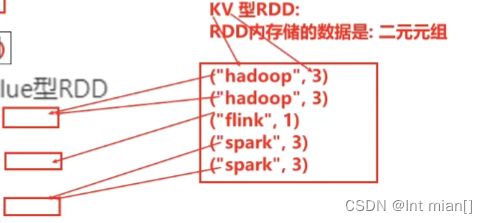
4、KV型的RDD可以有分区器
这个特性不是总是存在,因为不是所有RDD都是KV型
# KV型RDD:RDD内存储的是二元元组
默认是Hash分区,之后也可以使用rdd.partitionBy设置分区器,设置一个RDD内谁和谁一个分区
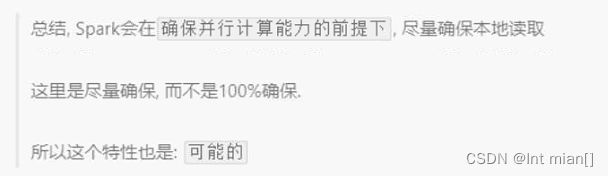
5、分区规划尽量靠近数据所在地
在初始RDD读取数据时,分区会尽量规划到数据所在服务器上,前提是并行!要是没法并行,宁可不靠近数据所在地
RDD数据是过程数据
当一个rdd转化之后,这个rdd就不存在了,为后续计算腾出空间
如果存在
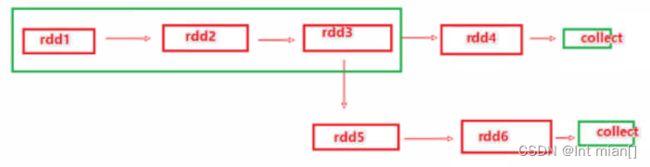
那么rdd4出现之后rdd3就没有了,rdd5用的rdd3是由于血缘关系,从rdd1重新构建生成的
RDD缓存
可以将指定的rdd留在内存or硬盘上,使其可以重复利用

缓存有丢失的风险(断电、清理内存给计算、硬盘炸了),所以缓存也会保留rdd之间的血缘关系,一旦缓存流失就又根据血缘关系计算rdd
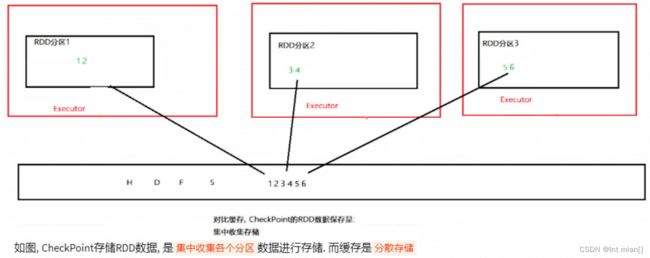
CheckPoint
仅支持硬盘存储,被认为是安全的,所以没保留血缘关系


RDD编程
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言) 只有构建出SparkContext, 基于它才能执行后续的API调用和计算 ,本质上, SparkContext对编程来说主要功能就是创建第一个RDD
RDD创建
- 通过并行化集合创建 ( 本地对象 转 分布式RDD )
- 读取外部数据源 ( 读取文件 )
conf = SparkConf().setMaster('local[*]').setAppName('create')
sc = SparkContext(conf=conf)
# rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
# print(rdd.getNumPartitions()) 默认分区数是16
rdd = sc.parallelize(c=[1, 2, 3, 4, 5, 6, 7, 8, 9], numSlices=3)
print(rdd.collect()) # collect方法是吧RDD中每个分区数据都发送到Driver中,形成一个List对象,分布式->本地
# 参数2不是绝对,有时候不会按照参数来
rdd2 = sc.textFile(name='../0txt/goodnight.txt', minPartitions=10)
print(rdd2.collect())读小文件API:wholeTextFile(路径,最小分区)

RDD算子
就是函数、方法,作用于分布式集合上就叫做算子
--------转换算子--------
RDD -> RDD,lazy加载,没有遇到Action之前,这些转换算子不工作(装炸弹)
map(func)
最基础的,不解除嵌套
rdd.map(lambda x: x*10)
flatMap
进行map后,解除嵌套后在进行map
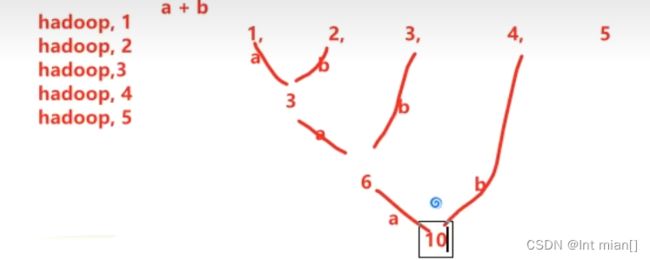
reduceByKey
针对KV型,按照K进行分组,然后根据聚合逻辑对V进行聚合
rdd.reduceByKey(lambda a, b: a+b),只需要两个值,依次两两聚合

mapValues
针对二元元组RDD,对其内部的Value进行map操作
rdd = sc.parallelize([('a', 1), ('a', 3), ('c', 5), ('b', 3), ('a', 4)])
print(rdd.mapValues(lambda x: x * 10).collect())
# [('a', 10), ('a', 30), ('c', 50), ('b', 30), ('a', 40)]groupBy
不针对KV
rdd = sc.parallelize([('a', 1), ('a', 3), ('c', 5), ('b', 3), ('a', 5)])
print(rdd.groupBy(lambda x: x[0]).collect())
# [('c', ), ('b', ), ('a', )]
print(rdd.groupBy(lambda x: x[1]).collect())
# [(1, ), (3, ), (5, )]
# 通过list(V)转化为可视对象
print(rdd.groupBy(lambda x: x[0]).mapValues(lambda x: list(x)).collect())
print(rdd.groupBy(lambda x: x[1]).mapValues(lambda x: list(x)).collect())
# [('c', [('c', 5)]), ('b', [('b', 3)]), ('a', [('a', 1), ('a', 3), ('a', 5)])]
# [(1, [('a', 1)]), (3, [('a', 3), ('b', 3)]), (5, [('c', 5), ('a', 5)])] groupByKey
针对KV数据
自动按照Key分组
rdd = sc.parallelize([('a', 1), ('a', 3), ('c', 5), ('b', 3), ('a', 5)])
print(rdd.groupByKey().mapValues(lambda x: list(x)).collect())
# [('c', [5]), ('b', [3]), ('a', [1, 3, 5])]等于rdd.groupBy(lambda x: x[0].mapValues(lambda x: [v for k, v in x]).collect(filter)
filter
rdd = sc.parallelize([('a', 1), ('a', 2), ('c', 5), ('b', 3), ('a', 4)])
print(rdd.filter(lambda x: x[1] % 2 == 1).collect())
# [('a', 1), ('c', 5), ('b', 3)]distinct
去重,二元组等,对整体去重
union
rdd1 = sc.parallelize([1,3,4,6])
rdd2 = sc.parallelize(['a', 'f', 'c'])
print(rdd1.union(rdd2).collect())
# [1, 3, 4, 6, 'a', 'f', 'c']join、leftOutJoin、rightOutJoin
针对二元元组,全连接,左外连接,右外连接,有手就行
intersection
求两个RDD交集,返回一个新的RDD
rdd.intersection(rdd2)
glom按分区加嵌套
rdd1 = sc.parallelize([1,3,4,6,6,2,3,5], numSlices=3)
print(rdd1.glom().collect())
# [[1, 3], [4, 6], [6, 2, 3, 5]]sortBy(fun, ascending, numPartitions)
fun:指定排序目标
ascend:true升序
分区数多了可能不会全局有序,需要把分区设置为1
rdd.sortBy(lambda x:x[1], ascending=False, numPartitions=2)
sortByKey
针对KV,按照key进行排序
按照key的所有转化为小写字符排序,不影响真实的大小写,仅在排序时临时全部转换为小写
rdd.sortByKey(ascending=True, numPartitions=2, keyfunc=lambda x: str(x).lower())
案例
从订单json中取出地区和对应的商品
{"id":27,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"5600"}|{"id":28,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"8000"}|{"id":29,"timestamp":"2019-05-08T02:03.00Z","category":"服饰","areaName":"杭州","money":"7000"}
data = sc.textFile('../data/order.text')
data = data.flatMap(lambda line: line.split('|'))
dic = data.map(lambda x: json.loads(x))
# print(dic.collect())
# {'id': 1, 'timestamp': '2019-05-08T01:03.00Z', 'category': '平板电脑', 'areaName': '北京', 'money': '1450'}
beijing_rdd = dic.filter(lambda x: x['areaName']=='北京')
rdd = beijing_rdd.map(lambda x: x['areaName']+':'+x['category']).distinct()
print(rdd.collect())
# ['北京:平板电脑', '北京:手机', '北京:家电', '北京:电脑', '北京:家具', '北京:书籍', '北京:食品', '北京:服饰']--------行动算子--------
返回值不是RDD(点火)
countByKey
rdd = sc.textFile('../0txt/goodnight.txt').flatMap(lambda x: x.split(' ')).map(lambda x: (x,1))
rdd2 = rdd.countByKey()
print(rdd2)
print(type(rdd2))
# ★collect

reduce
rdd.reduce(func),对RDD按照逻辑聚合,传入2个参数,返回1个,依次向后聚合
(reduceByKey是对KV,按照Key,对V聚合)
rdd.reduce(lambda a, b: a+b)fold
和reduce逻辑一样,但聚合带有初始值


rdd = sc.parallelize(range(1, 10), numSlices=3)
print(rdd.glom().collect())
print(rdd.fold(zeroValue=10, op=lambda a, b: a+b))
# [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 85first
取出RDD的第一个元素
take(n)
取出前n个元素,并组成list
top(n)
对rdd降序排序,取前n个
takeOrdered
对rdd自定义排序,取前n个
底层一直都是升序排序的,但是参数2可以对数据临时更改后排序,排序后输出不改变原来的数据,如下对数据降序排序
rdd.takeOrdered(3, key=lambda x: -x)
count.
返回RDD中有几条数据
takeSample
随机抽样rdd数据
takeSample(T/F, 个数,种子)
假随机!
rdd = sc.textFile('../0txt/goodnight.txt').flatMap(lambda x: x.split(' '))
print(rdd.takeSample(withReplacement=False, num=5, seed=3))
# ['Their', 'wise', 'last', 'not', 'that']
print(rdd.takeSample(withReplacement=False, num=5, seed=3))
# ['Their', 'wise', 'last', 'not', 'that']
print(rdd.takeSample(withReplacement=False, num=5, seed=5))
# ['night.', 'Do', 'dying', 'that', 'the']foreach
rdd.foreach(func)对每个元素都进行逻辑操作,和map一样,但是没有返回值
rdd = sc.parallelize([5,6,9,4,2,6,6])
print(rdd.foreach(lambda x: print('pri', x)))
collect是统一汇集到driver,在进行统一输出;而这个方法是每个rdd用自己资源输出
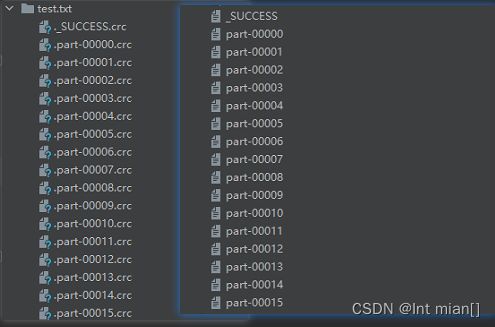
saveAsTextFile
rdd有几个分区,就save几个文件
foreach和saveAsTextFile绕过Driver直接使用Executor执行
--------分区操作算子--------
mapPartitions
和map功能一样
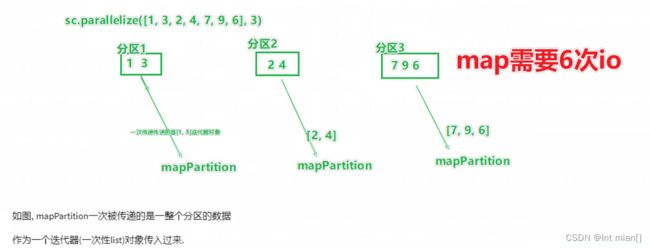
map是一对一的元素映射操作,适用于每个元素都可以独立处理的情况。mapPartitions是一对一或一对多的分区级别操作,适用于需要在分区级别上执行处理的情况,可以提高性能,但需要谨慎使用。
foreachPartition
还是以分区为单位

partitionBy
对rdd进行自定义分区
参数1:新分区数
参数2:规则函数

repartition
仅对rdd分区数量重新设置

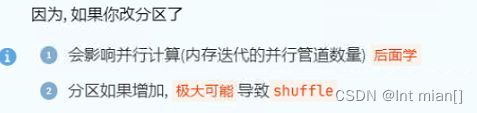
groupByKey与reduceByKey

广播变量
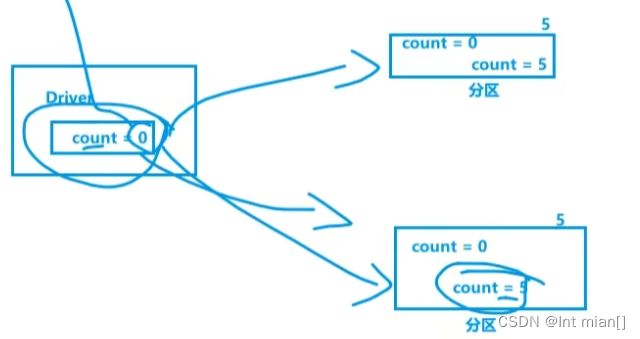
提出问题

此解决方法中,每个rdd分区的map函数都分配了一个同样的表,造成了内存浪费
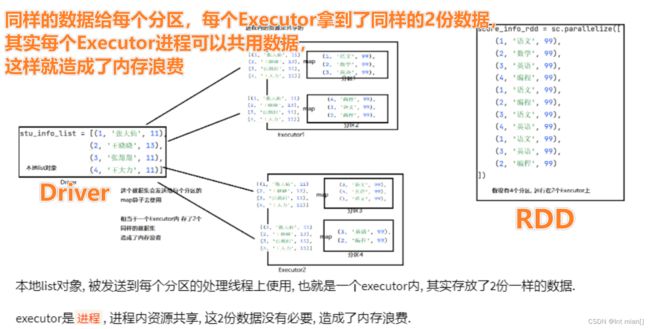
解决问题
提出广播变量,对每个Executor只给一份相同的数据,让里面的rdd共用
广播变量(Broadcast Variables)是分布式计算框架中的一种机制,用于在集群中高效地向所有工作节点广播一个较大的只读变量,以便在任务之间共享数据。广播变量的主要目的是减少网络传输和提高任务执行的性能。
广播变量有以下主要特点:
只读性质: 广播变量是只读的,一旦创建就不能被修改。这确保了所有工作节点都能访问到相同的数据,而不会发生竞态条件。
分布式共享: 广播变量允许将一个变量的值广播到整个集群中的各个节点,而不是将数据复制到每个节点。这大大减少了数据传输的开销,特别是对于大型数据集。
高效性能: 由于广播变量是只读的,它们通常存储在每个工作节点的内存中,因此可以高效地被多个任务共享,而无需多次传输相同的数据。
广播变量通常用于以下情况:
共享配置信息: 例如,将连接数据库的配置信息广播给所有任务,以避免每个任务都去读取相同的配置文件或从中心位置获取配置信息。
共享大型参考数据集: 如果任务需要访问一个较大的只读数据集,例如机器学习模型的参数或字典,可以将这些数据广播到所有任务,以避免在每个任务中重复加载或传输这些数据。
在Apache Spark等分布式计算框架中,广播变量通常通过API来创建和使用。通过广播变量,可以提高性能并减少数据传输的成本,特别是在涉及大量节点和大型数据时。
标记了一处广播变量
stu_list = [1, 2, 3, 4]
broadcast = sc.broadcast(stu_list)
print(broadcast) #
value = broadcast.value
print(value) # [1, 2, 3, 4] 
累加器
提出问题
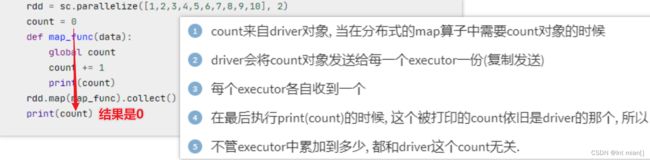
解决问题
# TODO
rdd = sc.parallelize(range(1, 11),2)
accumulator = sc.accumulator(0)
def func(data):
global accumulator
accumulator += data
print(accumulator)
rdd.map(func).collect()
print(accumulator)Q:为啥有个
global accumulator?A:在您的代码中,
func函数内定义的global accumulator的作用是使该变量在函数内部可修改,并且该变量与在函数外部定义的同名变量(即全局作用域中的accumulator)引用的是相同的对象。这允许您在函数内部修改全局作用域中的accumulator变量,而不会创建一个新的局部变量。
注意事项

可以在rdd2进行collect之前进行cache or checkpoint
内核调度(面试,概念)
DAG 有向无环图
根据RDD的依赖关系构建DAG,基于DAG划分Stage, 将每个Stage中的任务发到指定节点运行。


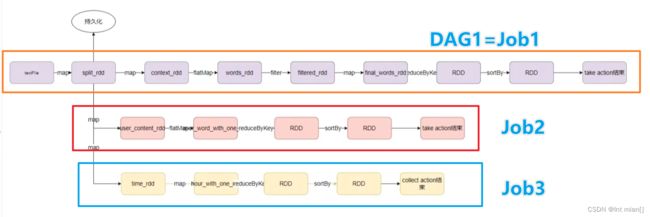
一个代码运行起来就叫一个Application,一个Application有多个job,一个job内含有一个DAG,一个Action产生一个Job

宽窄依赖
窄依赖:一个父rdd把数据发送给一个子rdd
宽依赖:一个父rdd把数据发送给多个子rdd(shuffle)
在Stage内部一定都是窄依赖,遇到一个宽依赖就划分一个Stage
内存迭代计算


设置并行度
优先级:代码 > 任务提交参数 > 配置文件 > 默认1(或基于文件分片数)
conf = SparkConf().set('spark.default.parallelism', '100')
Spark运行各个概念—人话理解
Task在Executor上,一个Executor上有多个Task,一个Executor的Task可以相互通信,而不同Executor之间的Task需要走网络通信(包括本地回环网络)
16核 CPU 意味着系统上有 16 个物理核心可用于并行执行任务。一个服务器上设置16个并行度刚好可以一个服务器不进行本地网络传输,少了存在Executor的闲置,多了增加本地传输
本地变量在Driver上,sc创造的rdd在Executor上
Executor 在物理上是计算资源的一部分,通常包括内存、CPU 核心和磁盘空间等组件。
一个Action产生一个Job,每个Job有自己的DAG,一个DAG会根据宽窄依赖划分为不同Stage,不同Stage内根据分区数,形成内存并行迭代管道,每个管道形成一个Task
===== SparkSQL =====

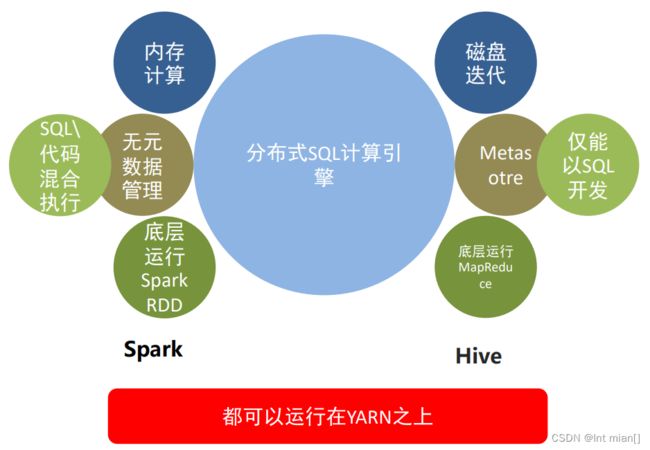
贬低Hive,吹SQL

SparkSession
SparkSession 是 Apache Spark 2.x 版本以及更高版本中引入的,它是一个更高级别的入口点,用于与 Spark 进行交互。它封装了以前在 SparkContext 中进行的功能,并提供了更多的功能,包括对 DataFrame 和 Dataset API 的支持。SparkSession 具有创建 DataFrames、执行 SQL 查询、配置 Spark 应用程序以及连接各种数据源等功能。
模板
if __name__ == '__main__':
ss = SparkSession.builder.appName('create').master('local[*]').getOrCreate()
sc = ss.sparkContext
path = '../0txt/input/stu_score.txt'
df1 = ss.read.csv(path, sep=',', header=False)
df2 = df1.toDF('id', 'name', 'score')
df2.printSchema()
# root
# |-- id: string (nullable = true)
# |-- name: string (nullable = true)
# |-- score: string (nullable = true)
# 1
df2.createTempView('name_score')
ss.sql("""
SELECT * FROM name_score where score=98 LIMIT 10
""").show()
# 2
df2.where('score=98').limit(10).show()
ss.stop()DataFrame
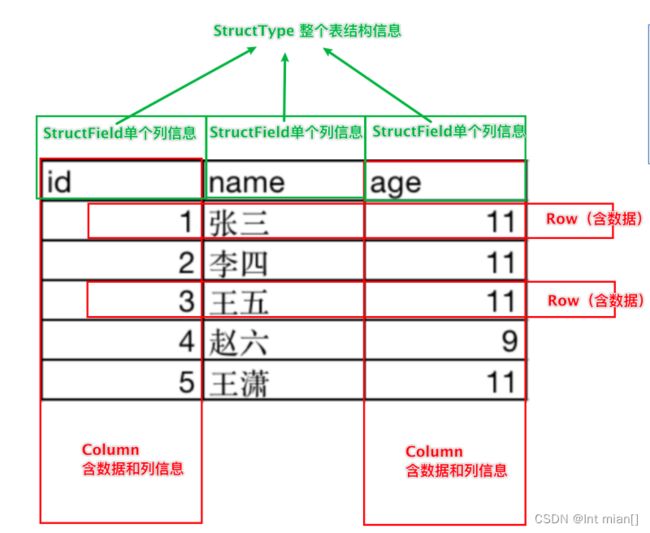
基于这个前提,DataFrame的组成如下:
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
在数据层面
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
创建DataFrame
rdd -> df
path = '../0txt/input/stu_score.txt'
# TODO
# rdd -> df
rdd = sc.textFile(path)\
.map(lambda x: x.split(','))\
.map(lambda x: (x[0], x[1], int(x[2])))
df = ss.createDataFrame(rdd, schema=['id', 'name', 'score'])
df.printSchema() # print表结构
df.show(5, False) # 1:显示几条,default 20, 2:数据太长截断structType
schema = StructType()\
.add('id', IntegerType(), nullable=False)\
.add('name', StringType(), nullable=True)\
.add('score', IntegerType(), nullable=True)
df2 = ss.createDataFrame(data=rdd, schema=schema)toDF
df3 = rdd.toDF(schema=['id', 'name', 'score'])
df3_1 = rdd.toDF(schema=schema)Pandas

统一API进行数据读取
ss.read.format('text|csv|json|parquet|orc|avro|jdbc')\
[.option(key='K', value='V')\]
.schema(schema=schema)\
.load(path=path)


DSL
df.where().limit()


groupBy 按照指定的列进行数据的分组, 返回值是GroupedData对象

SparkSQL shuffle
在SparkSQL中Job产生Shuffle时,默认分区数spark.sql.shuffle.partitions=200,local模式下最好降低


数据清洗(去重,缺失值)
dropDuplicates去重
# df2.dropDuplicates().show()
df2.dropDuplicates(['name', 'score']).show() # 仅考虑这2列相同
df2.dropDuplicates(['name']).show() # 仅考虑这name列相同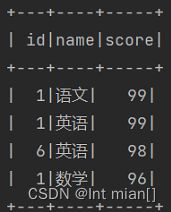
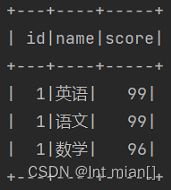
dropna删缺失值

fillna填充缺失值

保存

UDF函数
- ss.udf.register() 可以用于DSL和SQL
- pyspark.sql.functions.udf 仅能使用DSL
df2 = df1.toDF('id', 'name ', 'score')
def score_10(score):
return int(score) - 10
# 1 ss
udf1 = ss.udf.register(name='func1', f=score_10, returnType=IntegerType())
# SQL
df2.selectExpr('func1(score)').show()
# DSL
df2.select(udf1(df2['score']))
# 2 F
udf2 = F.udf(f=score_10, returnType=IntegerType())
# DSL
df2.select(udf2(df2['score']))遇到很多小问题的案例
path = '../0txt/input/stu_score.txt'
# df1 = ss.read.csv(path, sep=',', header=False)
df1 = sc.textFile(path).map(lambda x: [str(x)])
schema = StructType().add('line', StringType())
# df2 = ss.createDataFrame(data=df1, schema=schema)
df2 = df1.toDF(schema=['line'])
def spl(line):
return line.split(',')
udf1 = ss.udf.register(name='func1', f=spl, returnType=ArrayType(StringType()))
df2.select(udf1(df2['line'])).show()returnType可以使用StructType()自定义
窗口函数
df2.createTempView('name_score')
ss.sql("""
SELECT *, AVG(score) OVER() as avg_score FROM name_score
""").show()
ss.sql("""
SELECT *, ROW_NUMBER() OVER(ORDER BY score DESC) as ord FROM name_score WHERE name="语文"
""").show()运行流程
rdd执行流程:
![]()
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。
而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
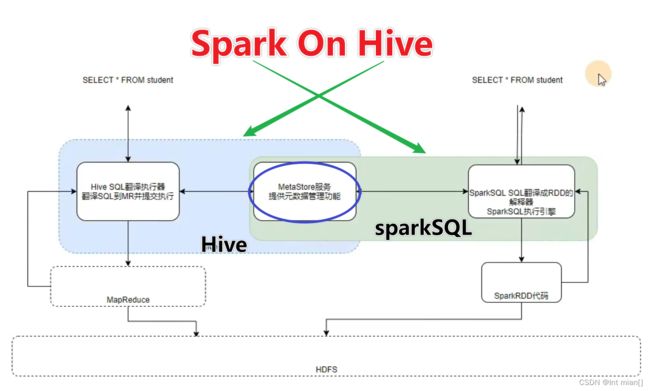
Catalyst优化器
为了解决过多依赖Hive的问题,SparkSQL使用了一个新的SQL优化器替代Hive中的优化器,这个优化器就是Catalyst,整个 SparkSQL的架构大致如下:


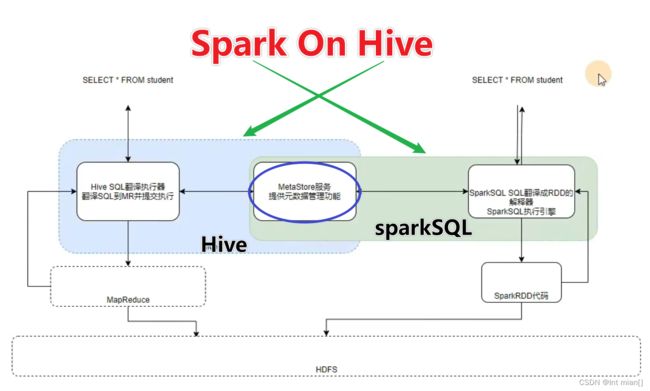
谓词下推(Predicate Pushdown)\断言下推:将逻辑判断提前到前面,以减少shuffle阶段的数据量(行过滤,提前执行where)
列值裁剪(Column Pruning):将加载的列进行裁剪,尽量减少被处理数据的宽度(列过滤,提前规划select的字段数量)
列值裁剪,有一种非常合适的存储系统:parquet

===== Spark on Hive =====
Shuffle
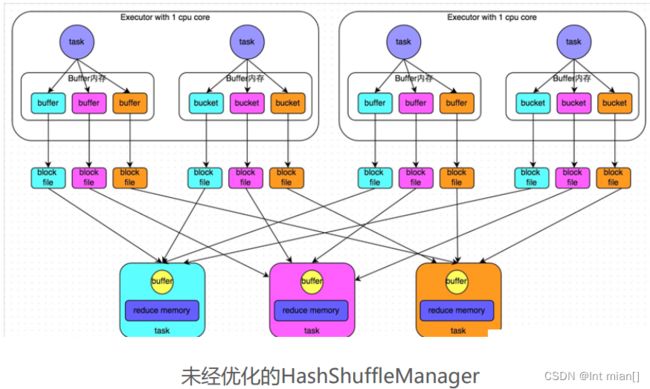
Spark 提供2种Shuffle管理器:
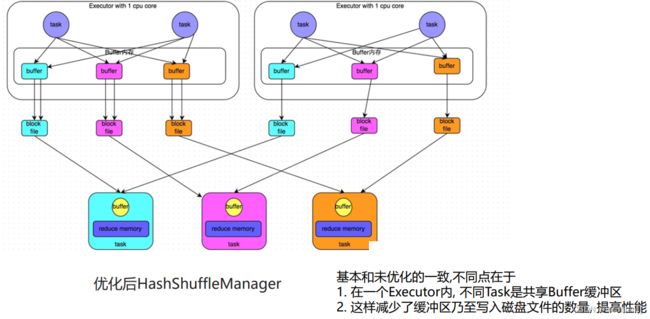
• HashShuffleManager
• SortShuffleManager
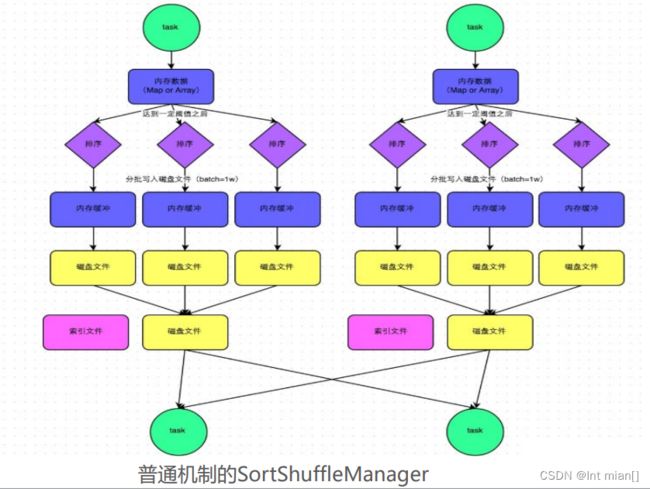
同普通机制基本类同, 区别在于, 写入磁盘临时文件的时候不会在内 存中进行排序 而是直接写, 最终合并为一个task一个最终文件 所以和普通模式IDE区别在于: 第一,磁盘写机制不同; 第二,不会进行排序。也就是说,启用该机制的最大好处在于, shuffle write过程中,不需要进行数据的排序操作,也就节省掉了 这部分的性能开销
SortShuffle对比HashShuffle可以减少很多的磁盘 文件,以节省网络IO的开销
SortShuffle主要是对磁盘文件进行合并来进行文件 数量的减少, 同时两类Shuffle都需要经过内存缓冲区 溢写磁盘的场景. 所以可以得知, 尽管Spark是内存迭 代计算框架, 但是内存迭代主要在窄依赖中. 在宽依 赖(Shuffle)中磁盘交互还是一个无可避免的情况. 所以, 我们要尽量减少Shuffle的出现, 不要进行无意义 的Shuffle计算.