JAVA线程池学习
**
一、线程池的概念
**
例如:与进程相比,线程虽然是一种轻量级的工具,但其创建和关闭依然需要花费时间,如果为每一个小的任务都创建一个线程,那么可能会出现创建线程和销毁线程锁占用的时间大于该线程真实工作所需的时间,得不偿失。
所以,线程池就是为了避免系统频繁的创建和销毁线程,我们可以让创建的线程进行复用(例如数据库连接池一样)。线程池中,总有那么几个活跃的线程,当你使用线程时直接从池子中获取即可。当使用完这个线程,我们并不急着关闭这个线程,只需要将这个线程退回到池子,方便后续(其他人)使用。
总之在使用线程池后,创建线程变为了从线程池中获取空闲线程,关闭线程变成了向池子归还线程。
**
二、JDK对线程池的支持
**
为了能够更好地控制多线程,JDK提供了一套Executor框架,它的核心成员如下图所示:
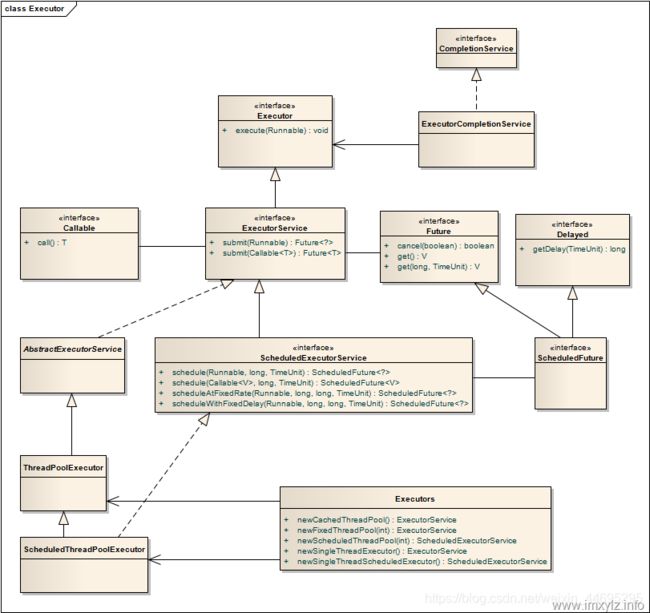
以上成员均在java.util.concurrent,是JDK并发包的核心类。其中ThreadPoolExecutor表示一个线程池。Executors类则扮演着线程池工厂的角色,通过Executors则可以取得一个特定功能的线程池。从图中可以看出,ThreadPoolExecutor类实现了Executor接口,所以,任何Runnable对象都可以被ThreadPoolExecutor线程池调度。
Executor框架提供了各种类型的线程池,主要有以下几种:
public static ExecutorService newFixedThreadPool();
public static ExecutorService newSingleThreadExecutor();
public static ExecutorService newCacheThreadPool();
public static ScheduledExecutorService newSingleThreadSecheduleExecutor();
public static ScheduledExecutorService newScheduledThreadPool();
以上工厂方法分别返回具有不同工作特性的线程池,这些线程池工厂的具体说明如下:
(1)newFixedThreadPool(int n)该方法返回的是一个固定线程的线程池,该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,则处理在任务队列中的任务。以下为使用方法(简单使用):
public class FirstDay {
public static class MyTask implements Runnable{
@Override
public void run() {
System.out.println(System.currentTimeMillis()+":Thread ID"+Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask myTask=new MyTask();
ExecutorService executor= Executors.newFixedThreadPool(5);
for (int i=0;i<10;i++){
executor.submit(myTask);
}
}
}
输出结果如下:
1626674660333:Thread ID11
1626674660333:Thread ID12
1626674660333:Thread ID13
1626674660333:Thread ID14
1626674660333:Thread ID15
1626674661333:Thread ID15
1626674661333:Thread ID12
1626674661333:Thread ID14
1626674661333:Thread ID13
1626674661333:Thread ID11
这个输出就是十个线程的执行情况,很显然前五个和后五个整好相差一秒钟。并且前五个线程ID和后五个线程ID都是相同的,这说明在这10个任务中,是分成两批次执行的。
(2)newSingleThreadExecutor()方法:该方法返回只有一个线程的线程池方法,若多余一个线程被提交到线程池。任务会被保存到一个队列中,待线程空闲,按照先入先出的顺序执行。代码跟之前的差不多!
(3)newCacheThreadPool()方法:该方法返回的是一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程来处理任务。所有线程在执行完当前任务后,返回线程池进行复用。
(4)newSingleThreadScheduleExecutor()方法:该方法返回的是一个ScheduleExecutorService对象,线程池大小为1。ScheduleExecutorService在ExecutorService功能上扩展了在给定时间执行某任务的功能。如在某个固定的延时之后执行,或者周期性执行某个任务!
(5)newScheduledThreadPool()该方法返回的也是一个ScheduleExecutorService对象,但该线程可以指定线程数量。
注意:newScheduledThreadPool()可以根据时间需要对线程进行调度。它的一些主要方法如下:
public ScheduledFuture<?> schedule();
public ScheduledFuture<?> scheduleAtFixedRate();
public ScheduledFuture<?> scheduledWithFixedDelay();
与其他几个线程池不同,ScheduledExecutorService并不一定会立即安排执行任务,他其实是起到了计划任务的作用!
其中:schedule()方法会在给定时间,对任务进行一次调度。scheduleAtFixedRate()和scheduledWithFixedDelay()会对任务进行周期性的调度。
**
三、刨根究底:核心线程的内部实现
**
对于上述介绍到的几个核心线程池,无论是newFixedThreadPool()、newSingleThreadExecutor()还是newCacheThreadPool()。其内部实现均使用了ThreadPoolExecutor来实现。可以看下源码结合:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
让我们来看下其构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
其中,参数的定义如下
- corePoolSize:线程池中的线程数量
- maximumPoolSize:线程池中的最大线程数量
- keepAliveTime:当线程数超过线程池中的数量之后多余的空闲线程存活的时间。即超过corePoolSize的空闲线程,在多长时间内,会被销毁。
- unit:keepAliveTime的时间单位
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。