项目日记:学成在线(第二天P24~p34)
1、注入的两种方式:@Autowired、@Resource(基于类型和名称)
相同:
@Resource和@Autowired都是做bean的注入时使用
不同:
①@Autowird 属于spring框架,默认使用类型(byType)进行注入:(基于类型)@Autowired private Human human;系统会根据接口进行注入,如果这个接口只有一个实现类,那么会正常注入,如果没有实现类,它就会报错,我们可以做如下处理:required = false,如果找不到对应的bean时候,不会抛出错误; 如果required = true,当不存在bean时候,就会抛出异常。
@Resource是JavaEE自带的注解, 默认按byName自动注入。(基于名称)
②@Autowired 有三种注入方式:属性注入、构造方法注入、Setter 注入;而 @Resource 只支持属性注入和 Setter 注入;
2、service注入dao层,controller注入service?
service注入mapper,controller注入service;
问题:注入@Autowired的是Service接口而不是其ServiceImpl实现类,在学习Java基础时接口不可以被实例化,那为什么在这里可以了呢?
表面上是注入接口,但是实际上注入的是接口的实现类对象(注入的是实现类对象,接收的是接口;理解为多态);
另一个方面因为@Autowired自动写入注解的对象是接口的话,Spring默认会使用JDK动态代理,JDK动态代理只能对实现接口的类生成代理,而不能针对类来进行动态代理。
注意:在controller中使用的是service的注解
controller使用的是service,service的实现类中注入的是mapper
service接口没有@service注解,注解在实现类上



3、httpclient中的content-type作用
Content-Type,内容类型,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件
常见的取值:
1、application/x-www-form-urlencoded:(默认值,又名url编码方式),是使用&拼接传递的key(参数名)=value(参数值)
2、multipart/form-data:(又名多部分表单格式),一个常见的 POST 数据提交的方式,用于向服务器发送大量的数据,常用语图片上传和文件上传,它既可以发送文本数据,也支持二进制数据上传。
3、application/json(json格式):作为响应头比较常见。实际上,现在越来越多的人把它作为请求头,用来告诉服务端:消息主体是序列化后的 JSON 字符串
3、关于Httpclient测试
1、swagger存在的两个弊端:
测试需要浏览器进入Swagger;不能保存测试数据。
2、使用:
进入controller类找到http接口对应的方法,右键即可。会生成一个.http结尾的文件,其中写上测试数据类型,然后写测试数据:

4、http和https区别
1、HTTPS 协议需要到 CA (Certificate Authority,证书颁发机构)申请证书,一般免费证书较少,因而需要一定费用。
2、HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 SSL 加密传输协议。(SSL协议——Secure Sockets Layer是安全套接层协议,SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。)
3、HTTP 和 HTTPS 使用的端口不一样,前者是80,后者是443。
4、HTTP 的连接很简单,是无状态的。HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。(无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。)
5、关于跨域问题
问题背景:(第50页)
在通过主机(http://localhost:8601)访问系统模块中的数据字典(http://localhost:63110/system/dictionary/all)时,报错,被CORS policy阻止
CORS全称是 cross origin resource share 表示跨域资源共享。
原因:基于浏览器的同源策略,去判断是否跨域请求,同源策略是浏览器的一种安全机制,从一个地址请求另一个地址,如果协议、主机、端口三者都相同则不是跨域,否则就是跨域请求。
如:从http://192.168.101.10:8601 到 https://192.168.101.11:8601 由于协议不同,是跨域。
注意:服务器之间不存在跨域请求。
解决方法:
1、JSONP
2、添加响应头
3、通过nginx代理跨域
项目主要使用第二种方法,通过在内容管理模块中添加配置类信息,设置白名单域名允许跨域访问,放行所有原始头信息,允许所有方法跨域跨域调用等内容,实现跨域过滤器,即在服务端添加响应头,实现跨域
5、nginx和浏览器为啥同源?
通过查资料,发现在配置nginx时,会将server_name配置成localhost,感觉应该是这个原因。
server_name用于设置虚拟主机服务名称, 为虚拟服务器的识别路径
每个server定义一个server_name,每个server_name可以指定一个或多个域名:server { listen 80; server_name www.baidu.com www.localhost; }

6、面试:Mybatis分页插件的原理?
首先分页参数放到ThreadLocal中,拦截执行的sql,根据数据库类型添加对应的分页语句重写sql
【补充】ThreadLocal
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程
一个ThreadLocal在一个线程中是共享的,在不同线程之间又是隔离的
JavaGuide中的答案:
(1) MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;
(2) 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,
(3) 也可以使用分页插件来完成物理分页。分页插件的基本原理是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
对数据库数据进行分页,依靠offset和limit两个参数,表示从第几条开始,取多少条。
Mybatis中使用RowBounds实现分页的大体思路:
先取出所有数据,然后游标移动到offset位置,循环取limit条数据,然后把剩下的数据舍弃。
7、Serializable接口作用
Serializable接口的作用是实现序列化
序列化:对象的寿命通常随着生成该对象的程序的终止而终止,有时候需要把在内存中的各种对象的状态(也就是实例变量,不是方法)保存下来,并且可以在需要时再将对象恢复。虽然你可以用你自己的各种各样的方法来保存对象的状态,但是Java给你提供一种应该比你自己的好的保存对象状态的机制,那就是序列化
8、sql中union all作用
union all用于合并两个或多个select的结果集
【补充】union all的使用注意事项:
①内部的SELECT语句必须拥有相同数量的列,列也必须拥有相似的数据类型
②每条 SELECT 语句中列的顺序必须相同
【补充】union all和union的区别
①Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
②Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
9、mapperxml中parameterType作用,selectid是要和方法名一样吗,resultMap和resultMap作用
mapper.xml中常用字段的说明:
select id:表示此段sql执行语句的唯一标识,也是接口的方法名称【必须一致才能找到】
parameterType=“xxxx” ——表示该sql语句中需要传入的参数, 类型要与对应的接口方法的类型一致【可选】
resultMap和resultMap都是定义出参,只能二选一
resultType:
resultType是直接表示返回类型的。
如果查询结果只是返回一个值,比如返回String或int,那么可以使用resultType指定简单类型作为输出结果。
还有一种情况就是如果数据库表的字段名和实体bean对象的属性名一样时,那么也可以直接使用resultType返回结果
resultMap:
数据库表的字段名和实体bean对象的属性名不一样时
resultType不需要配置,但是resultMap配置数据库表的字段名和实体bean对象类的属性名一一对应关系:

10、为啥service接口上没有@service,而是在实现类上?controller也是吗
service注解放在实现类(而不是service接口),因为这个注解其实就是相当于new对象的操作,只有类才有对象,接口无法new对象
controller不是这样:
我们是通过创建一个Controller类实现Controller接口,没有单独的分开controller接口和其实现类:@RestController public class CourseBaseInfoController { }而dao层是通过mapper和mapper.xml来实现,其中mapper是接口,不需要实现类(mybatis注解方式通过没有实现类的dao接口进行数据库操作的原理)。Mapper 接口开发方法只需要程序员编写Mapper 接口(相当于Dao 接口),由Mybatis 框架根据接口定义创建接口的动态代理对象。
mapper一个映射文件对应一个实体类,对应一张表的操作,对应一个mapper接口,mapper接口中的一个方法对应xml映射文件的一个sql语句。需要保证:
①mapper接口的全类名和映射文件的命名空间(namespace)保持一致
②mapper接口中方法的方法名和映射文件中编写SQL的标签的id属性保持一致
11、stream、collect、toMap、filter作用
这条语句的作用是,将courseCategoryTreeDtos中的元素从list转换为map,并经其中的key设置为id,value属性不做修改,如果一个map元素中出现两个key值,则用新的key2覆盖原有的key1(根据 id 和 对象自己 转成 Map 集合)
collect方法:
可以收集流中的数据到【集合】或者【数组】中去,举例://1.收集数据到list集合中 stream.collect(Collectors.toList()) //2.收集数据到set集合中 stream.collect(Collectors.toSet()) //3.收集数据到map集合中 例子如图Collectors.toMap方法的3个参数:
第一个参数就是用来生成key值的;
第二个参数就是用来生成value值的;有两种写法:
①Function.identity()
② t -> t(字母可以随便用,v啥的都行)
说明,这两种写法是等价的,都代表就是将对象自己返回
第三个参数用在key值冲突的情况下:如果新元素产生的key在Map中已经出现过了,第三个参数就会定义解决的办法。
filter的作用:将id=传入参数的节点过滤掉,保留id!=参数的节点
stream流:
①Stream 使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合进行链状流式的操作
②可以对流进行中间操作或者终端操作
中间操作:中间操作会再次返回一个流,所以,我们可以链接多个中间操作,注意这里是不用加分号的。代码中的filter 过滤,map 对象转换,sorted 排序,就属于中间操作。
终端操作是对流操作的一个结束动作,一般返回 void 或者一个非流的结果。代码中的 forEach循环 就是一个终止操作。List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1"); myList .stream() // 创建流 .filter(s -> s.startsWith("c")) // 执行过滤,过滤出以 c 为前缀的字符串 .map(String::toUpperCase) // 转换成大写 .sorted() // 排序 .forEach(System.out::println); // for 循环打印
(后续需要看一下Stream流的详细讲解和Java的lambda表达式的内容)

12、一般什么操作会被设置为事务?
事务(Transaction)是访问并可能更新数据库中各项数据项的一个程序执行单元
数据库中的数据是共享资源,因此数据库系统通常要支持多个用户的或不同应用程序的访问,并且各个访问进程都是独立执行的,这样就有可能出现并发存取数据的现象,这里有点类似Java开发中的多线程安全问题(解决共享变量安全存取问题)
四个特征:
①原子性(Atomicity)
事务的原子性保证事务中包含的一组更新操作是原子的,不可分割的,所包含的操作被视为一个整体,执行过程中遵循“要么全部执行,要不都不执行”。
②一致性(Consistency)
事务的一致性要求事务必须满足数据库的完整性约束,且事务执行完毕后会将数据库由一个一致性的状态变为另一个一致性的状态(事务操作前后,数据表中的数据是不会发生变化的,直到成功提交前。)
③隔离性(Isolation)
事务的隔离性要求事务之间是彼此独立的,隔离的。及一个事务的执行不可以被其他事务干扰。
④持续性(Durability)
事物的持续性也称持久性,是指一个事务一旦提交,它对数据库的改变将是永久性的,因为数据刷进了物理磁盘了,其他操作将不会对它产生任何影响。
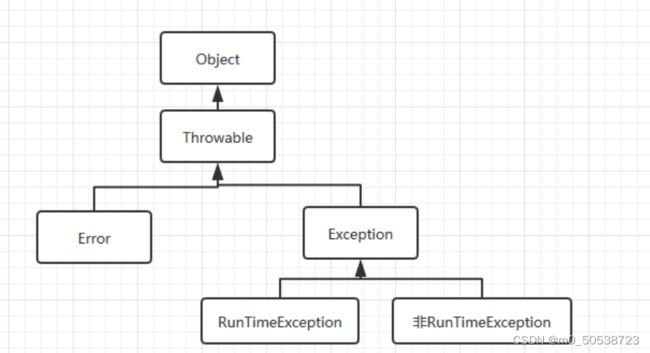
13、RuntimeException和Exception的区别
关系:
RunTimeException:运行时异常,又称不受检查异常,不受检查!
不受检查!!不受检查!!!重要的事情说三遍,因为不受检查,所以在代码中可能会有RunTimeException时Java编译检查时不会告诉你有这个异常,但是在实际运行代码时则会暴露出来
Runtime Exception:
在定义方法时不需要声明会抛出runtime exception; 在调用这个方法时不需要捕获这个runtime exception
Exception:
定义方法时必须声明所有可能会抛出的exception; 在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去
14、在课程新增模块中,出现的bug
在课程新增时,有信息校验,如:课程名称如果为空,会有“课程名称为空”的异常提示,但是测试时没有报出相关异常(具体描述在第二章80页,关于前面设置的提示信息,在第二章77页)
一、关于异常信息,前端和后端需要作的约定:
1、错误提示信息统一以json格式返回给前端。
2、以HTTP状态码决定当前是否出错,非200为操作异常。
二、如何规范异常信息?
代码中统一抛出项目的自定义异常类型,这样可以统一去捕获这一类或几类的异常。(自定义异常类型)
如果捕获了非项目自定义的异常类型统一向用户提示“执行过程异常,请重试”的错误信息。
三、如何捕获异常?
代码统一用try/catch方式去捕获代码比较臃肿,可以通过SpringMVC提供的控制器增强类统一由一个类去完成异常的捕获。
具体过程:
四、项目的具体实现(81页)
1、首先在base工程中引入相关依赖
2、在base模块中,加入异常信息的枚举类
3、自定义一个异常类型,继承了RuntimeException
4、自定义返回异常信息的模型
5、全局异常处理器,通常使用@ExceptionHandler、@ControllerAdvice
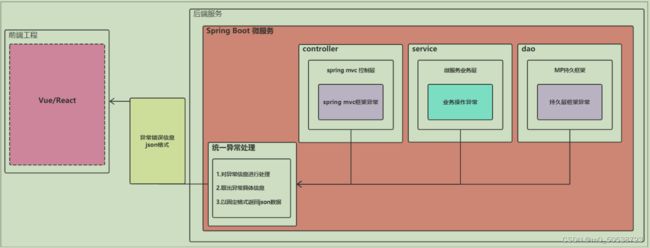
15、 面试:系统如何处理异常?
我们自定义一个统一的异常处理器去捕获并处理异常。
使用控制器增加注解@ControllerAdvice和异常处理注解@ExceptionHandler来实现。
- 处理自定义异常
程序在编写代码时根据校验结果主动抛出自定义异常类对象,抛出异常时指定详细的异常信息,异常处理器捕获异常信息记录异常日志并响应给用户。- 处理未知异常
接口执行过程中的一些运行时异常也会由异常处理器统一捕获,记录异常日志,统一响应给用户500错误。在异常处理器中还可以针对某个异常类型进行单独处理。
16、前端请求后端接口传输参数,是在controller中校验还是在Service中校验?
答案:都需要校验,只是分工不同。
Contoller中校验请求参数的合法性,包括:必填项校验,数据格式校验,比如:是否是符合一定的日期格式,等。
Service中要校验的是业务规则相关的内容,比如:课程已经审核通过所以提交失败。
早在JavaEE6规范中就定义了参数校验的规范,它就是JSR-303,它定义了Bean Validation,即对bean属性进行校验。
SpringBoot提供了JSR-303的支持,它就是spring-boot-starter-validation,它的底层使用Hibernate Validator,Hibernate Validator是Bean Validation 的参考实现。
所以,我们准备在Controller层使用spring-boot-starter-validation完成对请求参数的基本合法性进行校验。
比如在新增课程模块中,对鹅城基本信息进行校验,主要在类中的属性中加上了@NotEmpty和@Size两个注解,@NotEmpty表示属性不能为空,@Size表示限制属性内容的长短
定义好校验规则还需要开启校验,在controller方法中添加@Validated注解,也就是在添加了校验的类前面加上@Validated注解
具体各种校验注解以及他们的意思,见第二章第90页