【机器学习】人工智能实验二:利用贝叶斯分类器实现手写数字识别
一、数据获取
对于新手而言,熟练掌握各种数据的读取方式,并了解读入的数据具体存储形式及相关操作,实际上任务已经完成一大半了!
之所以这么讲,主要是为了强调,数据获取数据处理的在机器学习中的重要意义!
1、Python几种读取mat格式数据的方法
对于怎么获取.mat最合适,以及它们之间的差别,暂时我还没搞清楚,先“搁置争议”(不求甚解),毕竟这篇博客主打的记录代码
2、数据获取:
数据获取见博客:分类-MNIST(手写数字识别)
(一个50多M的.mat文件)
非常重要的一点,若要采用该博客相同的读文件方式,要记得将下载的.mat文件放到当面目录下的\datasets\mldata目录下
3、数据获取和处理的代码:
from sklearn.datasets import fetch_mldata
from sklearn import datasets
import scipy.io as scio
import numpy as np
import pandas as pd
#读取数据并显示
#mnist = scio.loadmat('mnist-original.mat')
mnist = fetch_mldata('mnist-original', data_home = './datasets/')
mnist
X, y = mnist['data'], mnist['target']
print(X.shape)
print(y.shape)
#抽样画出数据集的数字图片
import matplotlib
import matplotlib.pyplot as plt
some_digit = X[56789]
some_digit_image = some_digit.reshape(28,28)
#plt.imshow(some_digit_image, cmap=matplotlib.cm.binary, interpolation="nearest")
plt.imshow(some_digit_image)
plt.show()
#前面60000个当作训练集,后面10000个当测试集
X_train, X_test, y_train, y_test = X[:60000],X[60000:],y[:60000],y[60000:]
4、对应输出结果:
(1)数据集结构信息和warning:
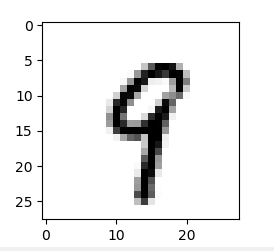
(2)随便选的一个图片绘制成的图片

*(3)或者你喜欢别的图片风格:
这就是另一块知识了,这里就不展开了(初学嘛,肯定是这不懂那不懂,慢慢学吧)
二、贝叶斯分类器算法
1、代码1:降维成14*14维,判断四块小方格只要有一个非零,新的矩阵对应点为1(下面代码请搭配上面的代码一块使用)
(运行大约需要两三分钟)
import os
import struct
import numpy as np
def Pwi(labels): #计算先验概率
arr=[]
S=labels.tolist()
for i in range(10):
arr.append(S.count(i)) #计算0:9每个labels的数量
arr=np.array(arr)
arr=arr/len(labels)
return arr
def PCAH(images): #降维28*28->14*14
newdata=[]
for i in range(len(images)):
x=[]
data=images[i].reshape([28,28])
for j in range(14):
for k in range(14):
if (data[j*2:(j+1)*2,k*2:(k+1)*2].sum()) >0:
x.append(1)
else:
x.append(0)
newdata.append(x)
newdata=np.array(newdata)
return newdata
def towzhi(images): #二值化
arr=[np.clip(images[0],0,1).tolist()] #clip([],min,max)
for i in range(1,len(images)):
x=np.clip(images[i],0,1).tolist()
arr.append(x)
data=np.array(arr)
return data
def Pjwi(data,labels):
P=np.zeros((10,196))
x={0:[],1:[],2:[],3:[],4:[],5:[],6:[],7:[],8:[],9:[]}
for i in range(len(labels)):
x[labels[i]].append(i)
for i in range(10):
for j in range(196):
for k in x[i]:
if data[k,j]!=0:
P[i,j]+=1
P[i]=(P[i]+1)/(len(x[i])+2)
return P
def train():
#images,labels=load_mnist("D:\mnist_all.mat") #读取数据
images=X_train
labels= y_train
images=towzhi(images) #二值化
data=PCAH(images) #主成分分析并降维
P=Pjwi(data,labels) #得到类条件概率
arr=Pwi(labels)
return data,P,arr #返回Pjwi,先验概率
def PwiX(P,arr): #计算后验概率
X=0
Pi=np.zeros((10))
for i in range(10): #计算分母
X+=P[i]*arr[i]
for i in range(10):
Pi[i]=P[i]*arr[i]/X #这里实际上除不除X对最后结果影响差别不大
return Pi
def MAXindex(Pi): #返回最大值的后验概率的值
x=0
for i in range(len(Pi)):
if Pi[x]<Pi[i]:
x=i
return x
def Pxwi(data,P): #计算类条件概率
Pi=np.ones((10))
for i in range(10):
for j in range(196):
if data[j]==0:
Pi[i]*=(1-P[i,j])
else:
Pi[i]*=P[i,j]
return Pi
def test(P,arr): #测试函数
T=0;
#images,labels=load_mnist("D:\py代码", kind='t10k')
images=X_test
labels=y_test
data=PCAH(images) #降维
data=towzhi(data) #二值化
count=[]
countx=np.zeros(10)
S=labels.tolist()
for i in range(10):
count.append(S.count(i)) #计算0:9每个labels的数量
for i in range(len(labels)):
p1=Pxwi(data[i],P) #计算类条件概率
p2=PwiX(p1,arr) #计算后验概率
x=MAXindex(p2) #返回后验概率最大的那个值
if x==labels[i]:
countx[x]+=1
T+=1
for i in range(10):
countx[i]=countx[i]/count[i]
return T/len(labels),countx
data1414,P,arr=train()
T,F=test(P,arr)
print(T)
print(F)
some_digit = data1414[56789]
some_digit_image = some_digit.reshape(14,14)
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary, interpolation="nearest")
#plt.imshow(some_digit_image)
plt.show()
输出结果:
总正确率和对应不同数字的正确率:
![]()
降维后的图形:

2、代码2:上面的代码稍微修改版:降维成7*14维,判断八个小方格至少有2个为非零才对应为1
import os
import struct
import numpy as np
#计算先验概率
def Pwi(labels):
arr=[]
S=labels.tolist()
for i in range(10):
arr.append(S.count(i))
arr=np.array(arr)
return arr/len(labels)
#降维28*28->7*14
def Dredu(images):
newdata=[]
for i in range(len(images)):
x=[]
data=images[i].reshape([28,28])
for j in range(7):
for k in range(14):
if (data[j*4:j*4+4,k*2:k*2+2].sum()) >=2:
x.append(1)
else:
x.append(0)
newdata.append(x)
newdata=np.array(newdata)
return newdata
def standard(images):
arr=[np.clip(images[0],0,1).tolist()] #clip([],min,max)
for i in range(1,len(images)):
x=np.clip(images[i],0,1).tolist()
arr.append(x)
data=np.array(arr)
return data
def Pjwi(data,labels):
P=np.zeros((10,84))
x={0:[],1:[],2:[],3:[],4:[],5:[],6:[],7:[],8:[],9:[]}
for i in range(len(labels)):
x[labels[i]].append(i)
for i in range(10):
for j in range(84):
for k in x[i]:
if data[k,j]!=0:
P[i,j]+=1
P[i]=(P[i]+1)/(len(x[i])+2)
return P
#计算后验概率
def PwiX(P,arr):
X=0
Pi=np.zeros((10))
for i in range(10):
X+=P[i]*arr[i]
for i in range(10):
Pi[i]=P[i]*arr[i]/X
return Pi
#返回最大值的后验概率的值
def MAXindex(Pi):
x=0
for i in range(len(Pi)):
if Pi[x]<Pi[i]:
x=i
return x
#计算类条件概率
def Pxwi(data,P):
Pi=np.ones((10))
for i in range(10):
for j in range(84):
if data[j]==0:
Pi[i]*=(1-P[i,j])
else:
Pi[i]*=P[i,j]
return Pi
#测试
def test(P,arr):
T=0;
data=Dredu(X_test) #降维
data=standard(data) #二值化
count=[]
countx=np.zeros(10)
S=y_test.tolist()
for i in range(10):
count.append(S.count(i))
for i in range(len(y_test)):
p1=Pxwi(data[i],P)
p2=PwiX(p1,arr)
x=MAXindex(p2)
if x==y_test[i]:
countx[x]+=1
T+=1
for i in range(10):
countx[i]=countx[i]/count[i]
return T/len(y_test),countx
def train():
images=X_train
labels= y_train
images=standard(images)
data=Dredu(images)
P=Pjwi(data,labels)
arr=Pwi(labels)
return data,P,arr
data714,P,arr=train()
T,F=test(P,arr)
print(T)
print(F)
some_digit = data714[56789]
some_digit_image = some_digit.reshape(7,14)
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary, interpolation="nearest")
#plt.imshow(some_digit_image)
plt.show()
输出结果:

图片长这样:

三、后记:随便写写
1、稍微分析下,上面代码的一些想法:
用了两种情况,跑出来不同的正确率,这里关于如何提高正确率,主要在于降维的形状(怎么降维)和阈值的大小(降维时选区的点达到什么条件才能算对应的区域为1)两个方面,实际上可以通过一定的循环语句,慢慢测试,最终是能找到一个使得最后正确率较高的降维的形状及其阈值的。
(为什么我不写,emmmmmm)
2、
考虑到前面的数据集太庞大,跑的太慢,这里突然觉得应该修改下获取的数据值(间隔100个数字去一个)
X_train, X_test, y_train, y_test = X[:60000:100],X[60000::100],y[:60000:100],y[60000::100]
3、np.clip截取函数
具体不会的函数多查,多练习!
4、附加一个流程图绘制网站和简易流程图
ProcessOn
