消息队列kafka
1.什么是kafka?
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。Kafka最初是由LinkedIn开发,并随后于2011年初开源。
2. kafka软件结构
kafka是一个结构相对简单的消息队列(MQ)软件
软件结构图
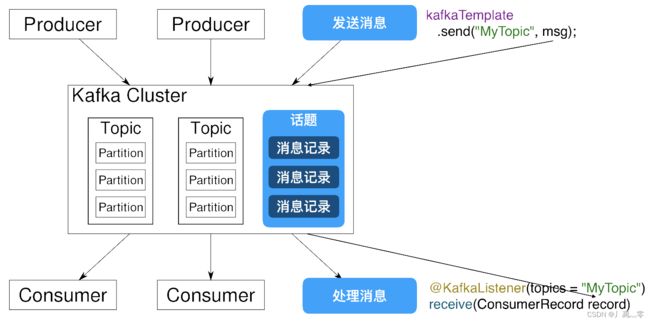
Kafka Cluster(Kafka集群)
Partition(分片)
Producer:消息的发送方,也就是消息的来源,Kafka中 的生产者
Consumer:消息的接收方,也就是消息的目标,Kafka中的消费者
Topic:话题或主题的意思,消息的收发双方要依据同一个话题名称,才不会将消息错发给别人
Record:消息记录,就是生产者和消费者传递的信息内容,保存在指定的Topic中
3.Kafka的特征和优势
Kafka作为消息队列,他和其他同类产品相比,突出的特点就是性能强大
Kafka将消息队列中的信息保存在硬盘中
Kafka对硬盘的读取规则进行优化后,效率能够接近内存
硬盘的优化规则主要依靠:“顺序读写,零拷贝,日志压缩等技术”
Kafka处理队列中数据的默认设置:
--Kafka队列信息能够一直向硬盘中保存(理论上没有大小限制)
--Kafka默认队列中的信息保存7天,可以配置这个时间,缩短这个时间可以减少Kafka的磁盘消耗
4. Kafka的安装和配置
必须将Kafka软件的解压位置设置在一个根目录,文件夹迷你工程尽量短
然后路径不要有空格和中文
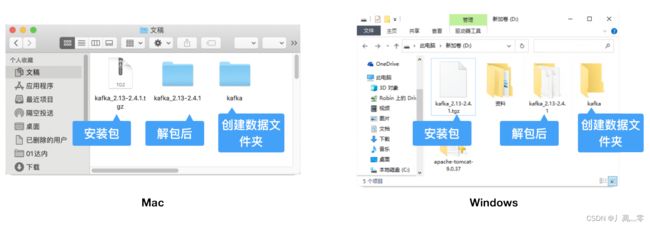
创建一个空目录用于保存Kafka运行过程中产生的数据
例如:创建名称为data的空目录
进行配置:
先到D:\kafka\config下配置有文件zookeeper.properties
找到dataDir属性修改如下
```
dataDir=D:/data
```
修改完毕之后要Ctrl+S进行保存,否则修改无效!!!!
注意D盘和data文件夹名称,匹配自己电脑的真实路径和文件夹名称
还要修改server.properties配置文件
```
log.dirs=D:/data
```
5. 启动Kafka
要想启动Kafka必须先启动Zookeeper
zoo:动物园
keeper:园长
可以引申为管理动物的人
Linux服务器中安装的各种软件,很多都是有动物形象的
如果这些软件在Linux中需要修改配置信息的话,就需要进入这个软件,去修改配置,每个软件都需要单独修改配置的话,工作量很大
我们使用Zookeeper之后,可以创建一个新的管理各种软件配置的文件管理系统
Linux系统中各个软件的配置文件集中到Zookeeper中
实现在Zookeeper中,可以修改服务器系统中的各个软件配置信息
长此以往,很多软件就删除了自己写配置文件的功能,而直接从Zookeeper中获取
Kafka就是需要将配置编写在Zookeeper中的软件之一
所以要先启动zookeeper才能启动kafka
Zookeeper启动
进入路径
D:\kafka\bin\windows
输入cmd进入dos命令行
D:\kafka\bin\windows>zookeeper-server-start.bat ..\..\config\zookeeper.propertieskafka启动
总体方式一样,输入不同指令
D:\kafka\bin\windows>kafka-server-start.bat ..\..\config\server.properties
6. Kafka使用演示
添加依赖
org.springframework.kafka
spring-kafka
com.google.code.gson
gson
修改yml文件进行配置
spring:
kafka:
# 定义kafka的配置信息:确定kafka的ip和端口
bootstrap-servers: localhost:9092
# consumer.group-id必须设置的配置
# 意思是"话题分组",这个配置的目的是为了区分不同的项目而配置的
# 本质上,这个分组名称会前缀在所有话题名名称之前,例如话题名称为message,真正发送时csmall.message
consumer:
group-id: csmall在SpringBoot启动类中添加启动Kafka的注解
@SpringBootApplication
@EnableDubbo
// 启动支持Kafka的功能
@EnableKafka
// 为了测试Kafka发送消息的功能
// 我们利用SpringBoot自带的调用工具,周期性的向kafka发送消息
// 下面的注解和Kafka软件没有直接必然的依赖关系
@EnableScheduling
public class CsmallCartWebapiApplication {
public static void main(String[] args) {
SpringApplication.run(CsmallCartWebapiApplication.class, args);
}
}下面我们就可以实现周期性的向kafka发送消息并接收的操作了
编写消息的发送
cart-webapi包下创建kafka包
包中创建Producer类来发送消息
// 这个类实现周期性向Kafka发送消息
// 因为Spring的任务调度需要将当类保存到Spring容器,所以要加下面的注解
@Component
public class Producer {
// 直接获取Spring容器中支持向Kafka发送消息的对象
// 这个对象会在SpringBoot启动时自动的装配到Spring容器
// KafkaTemplate<[话题的类型],[消息的类型]>
@Autowired
private KafkaTemplate kafkaTemplate;
// 实现每隔10秒向Kafka发送消息
int i=1;
// 设置每隔10秒(10000毫秒)运行一次的调度注解
@Scheduled(fixedRate = 10000)
// SpringBoot启动后,每隔10秒运行一次下面的方法
public void sendMessage(){
// 实例化一个Cart对象,赋值并发送给Kafka
Cart cart=new Cart();
cart.setId(i++);
cart.setCommodityCode("PC100");
cart.setUserId("UU100");
cart.setPrice(RandomUtils.nextInt(90)+10);
cart.setCount(RandomUtils.nextInt(10)+1);
// "{"id":"1","price":"58",...}"
// 利用Gson依赖,将cart对象转换为上面样式的json格式字符串
Gson gson=new Gson();
String json=gson.toJson(cart);
System.out.println("要发送的信息为:"+json);
// 执行发送
kafkaTemplate.send("myCart",json);
}
} kafka包中创建一个叫Consumer的类来接收消息
> 接收消息的类可以是本模块的类,也可以是其它模块的类,编写的代码是完全一致
// 需要接收kafka的消息,因为kafkaTemple是Spring容器管理的对象
// 所以消息的接收功能,也要保存到Spring容器中
@Component
public class Consumer {
// SpringKafka接收消息依靠框架提供的"监听机制"
// 框架中有一个线程,一直实时关注Kafka的消息接收
// 如果我们指定的话题名称(myCart)接收了消息,那么这条线程就会自动调用下面的方法
@KafkaListener(topics = "myCart")
// 下面方法的参数也是来自监听机制,也就是myCart话题接收到的消息
public void received(ConsumerRecord record){
// 接收消息的方法参数必须是ConsumerRecord
// 泛型类型和发送消息时指定的泛型一致<[话题名称的类型],[消息的类型]>
// record就是消息本身,可以从这个对象中获得具体消息内容
String json=record.value();
// 将json格式的字符串转换为java对象
Gson gson=new Gson();
// 执行转换
Cart cart=gson.fromJson(json,Cart.class);
//{"id":2,"commodityCode":"PC100","price":61,"count":9,"userId":"UU100"}
System.out.println(cart);
}
}