Oracle迁移达梦实践过程
目录
前言
1.统计oracle数据库信息
1.1.统计基本信息
1.2.统计数据库中对象及表数量
2.迁移准备
2.1.注意事项
2.2.检查基本参数
2.3.检查兼容ORACLE参数
2.4.检查用户及表空间
3.DTS迁移过程
3.1.新建迁移任务
3.2.迁移表结构及序列
3.3.迁移表数据
3.4.迁移索引
3.5.迁移视图、物化视图等
4.核对数据库迁移结果
4.1.统计达梦数据中的对象及表数据量
4.2.比对达梦数据库与oracle数据库差异
4.3.迁移完成之后的收尾工作
5.创建定时任务
5.1.检查定时任务
5.2.创建定时
6.迁移过程中问题参考
6.1.字符串截断
6.2.记录超长
6.3.违反唯一约束
6.4.违反引用约束
6.5.无效用户对象
6.6.错误的时间日期格式
6.7.长度超出定义
前言
现在越来越多的项目从Oracle迁移到DM数据库来,总结一下迁移过程,常见问题处理方式。希望可以帮助到各位伙伴。
1.统计oracle数据库信息
1.1.统计基本信息
| --统计页大小 select name,value from v$parameter where name ='db_block_size'; --查询编码格式 select * from v$nls_parameters a where a.PARAMETER='NLS_CHARACTERSET'; |
1.2.统计数据库中对象及表数量
| --根据指定用户统计用户下的各对象类型和数目 select object_type,count(*) from all_objects where owner='OA8000_DM2015' group by object_type; --创建移植辅助表,统计指定用户下所有的对象并插入到辅助表中 create table oracle_objects(obj_owner varchar(100),obj_name varchar(100),obj_type varchar(50)); insert into oracle_objects select owner,object_name,object_type from all_objects where owner='ITPUX'; select * from oracle_objects; --创建移植辅助表,统计每个表的数据量并插入到移植辅助表中 CREATE TABLE oracle_tables ( tab_owner VARCHAR ( 100 ), tab_name VARCHAR ( 100 ), tab_count int ); BEGIN FOR rec IN ( SELECT owner, object_name FROM all_objects WHERE owner = 'ITPUX' AND object_type = 'TABLE' ) loop BEGIN execute IMMEDIATE 'insert into oracle_tables select ''' || rec.owner || ''',''' || rec.object_name || ''',count(*) from ' || rec.owner || '.' || rec.object_name; EXCEPTION WHEN others THEN dbms_output.put_line ( rec.owner || '.' || rec.object_name || 'get count error' );
END;
END loop; END; select * from oracle_tables; |
2.迁移准备
2.1.注意事项
数据库参数检查:
- 字符集需要注意默认采用GB18030
- 大小写需要敏感
- 修改达梦数据库兼容ORACLE参数
- 需要使用单独的业务表空间,创建用户和表空间
- 生产环境建议创建30G一个数据文件,关闭自动扩展
2.2.检查基本参数
| select '实例名称' 数据库选项,INSTANCE_NAME 数据库集群相关参数值 FROM v$instance union all select '数据库版本',substr(svr_version,instr(svr_version,'(')) FROM v$instance union all SELECT '字符集',CASE SF_GET_UNICODE_FLAG() WHEN '0' THEN 'GBK18030' WHEN '1' then 'UTF-8' when '2' then 'EUC-KR' end union all SELECT '字符数据类型' NAME, CASE VALUE WHEN 0 THEN 'BYTE' WHEN 1 THEN 'CHAR' end FROM v$parameter WHERE name like '%LENGTH_IN_CHAR%' union all SELECT '页大小',cast(PAGE()/1024 as varchar) union all SELECT '簇大小',cast(SF_GET_EXTENT_SIZE() as varchar) union all SELECT '大小写敏感',cast(SF_GET_CASE_SENSITIVE_FLAG() as varchar) union all select '数据库模式',MODE$ from v$instance union all select '唯一魔数',cast(permanent_magic as varchar) union all select 'LSN',cast(cur_lsn as varchar) from v$rlog ; |
2.3.检查兼容ORACLE参数
| SELECT * FROM V$DM_INI WHERE para_name='COMPATIBLE_MODE'; alter system set 'COMPATIBLE_MODE' = 2 spfile 或者 sp_set_para_value(2,‘COMPATIBLE_MODE’,2); |
2.4.检查用户及表空间
| SQL> select path from v$datafile; 行号 PATH ---------- --------------------------- 1 /dm/dmdata/erpdb/SYSTEM.DBF 2 /dm/dmdata/erpdb/ROLL.DBF 3 /dm/dmdata/erpdb/TEMP.DBF 4 /dm/dmdata/erpdb/MAIN.DBF 已用时间: 31.840(毫秒). 执行号:36500. SQL> |
生产环境建议创建30G一个数据文件,关闭自动扩展
| create tablespace itpux datafile '/dm/dmdata/erpdb/itpux01.dbf' size 30g autoextend off; alter tablespace ITPUX datafile '/dm/dmdata/erpdb/itpux01.dbf' autoextend off; --生产环境配置好,可以一次性创建20g大小一个 alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux02.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux03.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux04.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux05.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux06.DBF' size 1024 autoextend on next 1024 maxsize 30720; alter tablespace ITPUX add datafile '/dm/dmdata/erpdb/itpux07.DBF' size 1024 autoextend on next 1024 maxsize 30720; --创建索引表空间 create tablespace itpux_idx datafile '/dm/dmdata/erpdb/itpux_idx01.dbf' size 1000 autoextend off; |
创建用户并授权
| create user "itpux " identified by "itpux123456" default tablespace itpux default index tablespace itpux_idx; grant dba to itpux; conn itpux/itpux123456; |
3.DTS迁移过程
注意:根据业务数据量,注意迁移方式
1.选择合理的迁移顺序:先迁移序列、再迁移表、最后迁移视图
2.对于数据量大的表单独迁移
3.对于分区表数据量没有超过1亿建议迁移成普通表,在分区列上创建索引
4.对于大字段较多的表,需要修改批量的行数,以免造成迁移工具内存溢出。
3.1.新建迁移任务


选择oracle==》达梦,选择下一步

配置oracle连接

配置目的端参数

3.2.迁移表结构及序列

选择要迁移的表

选择转换只选择表定义与表及字段注释,如下图

然后勾选应用当前选项到其他同类对象后,会弹出下图
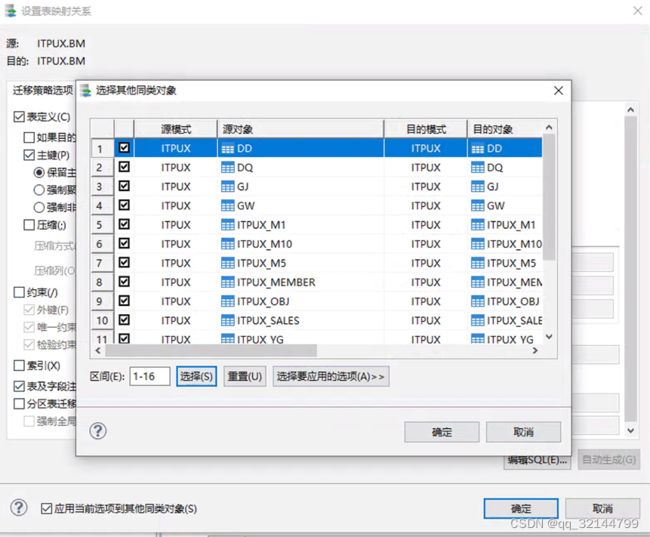
确定往下一步,下一步执行
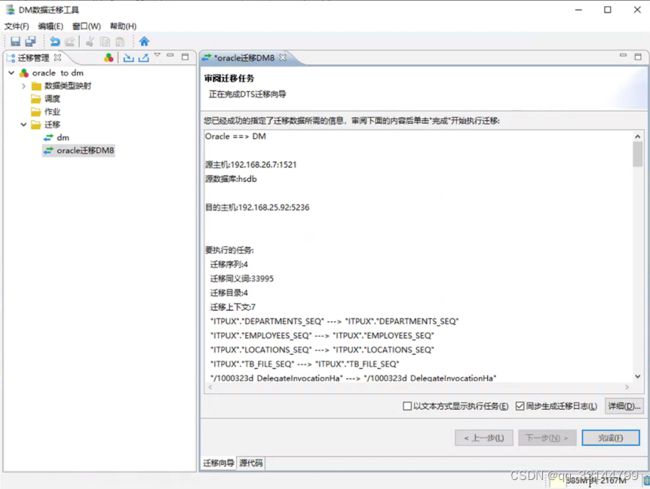
表结构迁移完

3.3.迁移表数据

全选后然后点转换,如下图


注意:大字段读写取行数,可以适当开启并行。不开快速装载
3.4.迁移索引
选择对应的约束

点完成,开始迁移

如下索引迁移完成

3.5.迁移视图、物化视图等

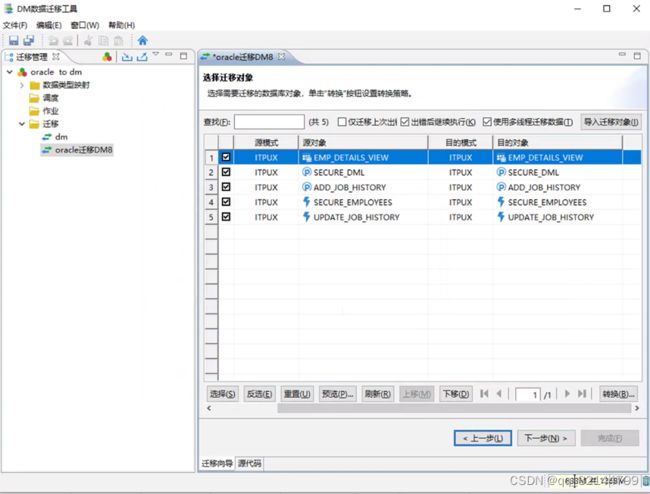
迁移完成

4.核对数据库迁移结果
4.1.统计达梦数据中的对象及表数据量
a. 根据指定用户统计用户下的各对象类型和数目
| select object_type,count(*) from all_objects where owner='ITPUX' group by object_type; |
b. 统计指定用户下所有的对象,并记录到新的记录表中
| create table dm_objects(obj_owner varchar(100),obj_name varchar(100),obj_type varchar(50)); insert into dm_objects select owner,object_name,object_type from all_objects where owner='ITPUX'; |
c. 统计每个表的数据量到表数据记录表(使用DISQL运行)
| create table dm_tables(tab_owner varchar(100),tab_name varchar(100),tab_count int); begin for rec in ( select owner, object_name from all_objects where owner ='ITPUX' and object_type='TABLE' ) loop begin execute immediate 'insert into dm_tables select '''|| rec.owner ||''','''|| rec.object_name ||''',count(*) from '|| rec.owner || '.' || rec.object_name; exception when others then print rec.owner || '.' || rec.object_name || 'get count error'; end; end loop; end; select * from dm_tables; |
4.2.比对达梦数据库与oracle数据库差异
a. 比对对象,找出没有迁移的对象
| select * from oracle_objects where (obj_owner,obj_name) not in ( select obj_owner,obj_name from dm_objects) --and obj_type='TABLE' |
b. 比对表数据量,找出数据量不相等的表
| select a.tab_owner,a.tab_name,a.tab_count-b.tab_count from oracle_tables a, dm_tables b where a.tab_owner=b.tab_owner and a.tab_name=b.tab_name and a.tab_count-b.tab_count<>0 |
4.3.迁移完成之后的收尾工作
更新统计信息,数据核对完成无问题后,应进行一次全库的统计信息更新工作。
统计信息更新脚本示例如下:
| DBMS_STATS.GATHER_SCHEMA_STATS( 'ITPUX', FALSE, 'FOR ALL COLUMNS SIZE AUTO'); |
5.创建定时任务
5.1.检查定时任务
| select * from sysjob.sysjobs; |
5.2.创建定时
| 登录数据库执行以下命令,创建作业系统表 SP_INIT_JOB_SYS(1); 全量备份(每周六 23 点全备):其中有1分钟后的一次性全备调度,执行完成后检查备份是否成功。 call SP_CREATE_JOB('bakfull',1,0,'',0,0,'',0,''); call SP_JOB_CONFIG_START('bakfull'); call SP_ADD_JOB_STEP('bakfull', 'bak1', 6, '01020000/dmbak', 0, 0, 0, 0, NULL, 0); call SP_ADD_JOB_SCHEDULE('bakfull', 'std1', 1, 2, 1, 64, 0, '23:00:00', NULL, '2021-11-01 21:17:22', NULL, ''); call SP_ADD_JOB_SCHEDULE('bakfull', 'once', 1, 0, 0, 0, 0, NULL, NULL, sysdate+1/1440, NULL, ''); call SP_JOB_CONFIG_COMMIT('bakfull'); 增量备份(每周除周六外每天 23 点增量备份): call SP_CREATE_JOB('bakincr',1,0,'',0,0,'',0,''); call SP_JOB_CONFIG_START('bakincr'); call SP_ADD_JOB_STEP('bakincr', 'bak2', 6, '41010000/dmbak|/dmbak', 0, 0, 0, 0, NULL, 0); call SP_ADD_JOB_SCHEDULE('bakincr', 'std2', 1, 2, 1, 63, 0, '23:00:00', NULL, '2021-11-01 21:19:30', NULL, ''); call SP_JOB_CONFIG_COMMIT('bakincr'); 备份定期删除(每天 23:30 删除 14 天前备份): call SP_CREATE_JOB('delbak',1,0,'',0,0,'',0,''); call SP_JOB_CONFIG_START('delbak'); call SP_ADD_JOB_STEP('delbak','bak1',0, 'SF_BAKSET_BACKUP_DIR_ADD(''DISK'',''/dmdata/dmbak'');call sp_db_bakset_remove_batch(''DISK'',now()-14);', 1, 2, 0, 0, NULL, 0); call SP_ADD_JOB_SCHEDULE('delbak', 'del01', 1, 1, 1, 0, 0, '23:30:00', NULL, '2020-11-02 14:48:41', NULL, ''); call SP_JOB_CONFIG_COMMIT('delbak'); 另外添加自动收集统计信息的任务(每天1点收集全库统计信息) call SP_CREATE_JOB('statistics',1,0,'',0,0,'',0,''); call SP_JOB_CONFIG_START('statistics'); call SP_ADD_JOB_STEP('statistics', 'statistics1', 0, 'begin for rs in (select ''sf_set_SESSION_para_value(''''HAGR_HASH_SIZE'''',(select cast( case when max(table_rowcount(owner,table_name))<=(select max_value from v$dm_ini where para_Name=''''HAGR_HASH_SIZE'''') and max(table_rowcount(owner,table_name))>=( select min_value from v$dm_ini where para_Name=''''HAGR_HASH_SIZE'''') then max(table_rowcount(owner,table_name)) when max(table_rowcount(owner,table_name))<( select min_value from v$dm_ini where para_Name=''''HAGR_HASH_SIZE'''') then (select min_value from v$dm_ini where para_Name=''''HAGR_HASH_SIZE'''') else (select max_value from v$dm_ini where para_Name=''''HAGR_HASH_SIZE'''') end as bigint) from dba_tables where owner=''''''||NAME||''''''));'' sql1,''DBMS_STATS.GATHER_SCHEMA_STATS(''''''||NAME||'''''',100,TRUE,''''FOR ALL COLUMNS SIZE AUTO'''');'' sql2 from SYS.SYSOBJECTS where TYPE$=''SCH'' ) loop execute immediate rs.sql1; execute immediate rs.sql2; end loop; end;', 0, 0, 0, 0, NULL, 0); call SP_ADD_JOB_SCHEDULE('statistics', 'statistics1', 1, 2, 1, 64, 0, '01:00:00', NULL, '2021-06-09 22:54:37', NULL, ''); call SP_JOB_CONFIG_COMMIT('statistics'); |
6.迁移过程中问题参考
6.1.字符串截断
一般从oracle 迁移到 DM7 的时候,出现字符串截断的一般都是字段中含有中文,出 现这种问题是因为 DM7 初始化的时候选择的字符集是 Unicode (即 utf 8 ),该字符集的 国际标准是一个汉字占 3 个字节,而 oracle 中默认情况下一个汉字占 2 个字节,此时迁移 的时候就会报下面的错误:

解决办法:
- 是在初始化的时候,字符集选择 gb18030 ,如下图

2.选择 VARCHAR 类型以字符为单位,如图:

3.因为前面 2 种都需要重新初始化数据库,第三种不需要重新初始化数据库即可解决,即在 选择迁移方式的时候,选择字符长度隐射关系为 2 ,如下图

6.2.记录超长
DM7在初始化的时候,选择的页大小影响后面表每行数据的长度,表每行的长度之和(普通数据类型)不能超过一页大小,如果超过 1 页大小即报记录超长的错误,如下图:

解决办法:
- 找到表中 varchar 类型比较长的(如 varchar2 8000 )这种),修改成 text类型;
- 初始化的时候页大小选择 32k 。(对于表中 varchar2 类型较长,并且字段较多的情 况不太适合,这种情况采用方法 1 解决)
6.3.违反唯一约束
这种情况是因为表中设置了唯一性约束或者主键约束,但是数据中有重复记录造成的。也有可能是原始库 的约束被禁用了,或者数据重复迁移造成的。

解决办法:
在确定源数据没有问题的情况下,迁移的时候选择删除后再拷贝,如下图: 在迁移界面中,先中要迁移的表,然后点击转换

在弹出的窗口中选择删除后拷贝,如下图:

6.4.违反引用约束
这种问题主要是由外键约束造成的,父表的数据没有迁移,先迁移了子表的数据,错误 如图所示:

解决办法:
迁移的时候先不迁移外键等约束,在选择好要迁移的表时,点击转换,按照下面步骤迁移。
(1)第一次只选择表定义,不选择约束等,如图:

(2)第一次迁移完成后(确保没有错误),第二次只选择数据,如图:
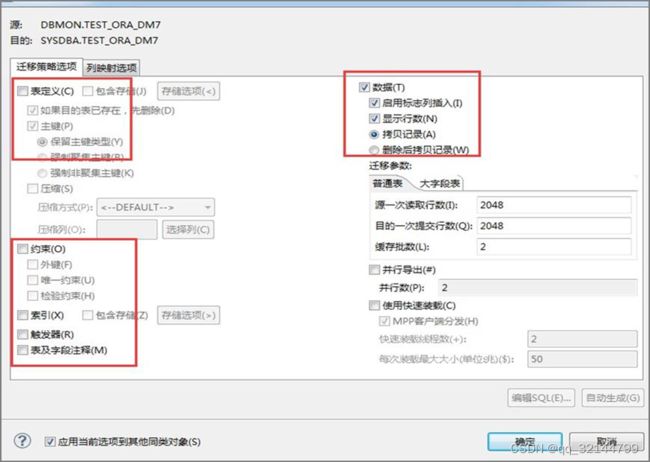
(3)第三步选择约束、索引等,如图:

6.5.无效用户对象
这个问题一般是因为在迁移视图之前,没有将视图依赖的表迁移过去,如图所示:
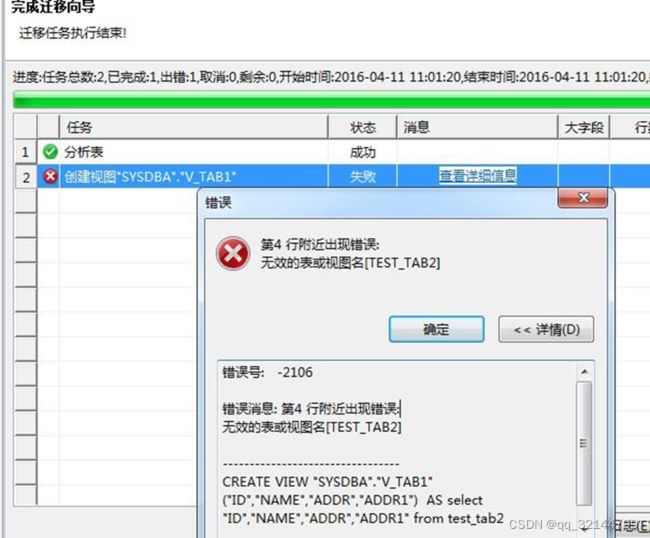
解决办法:
严格按照迁移的顺序,先迁移表,然后再迁移视图、存储过程、函数等的顺序迁移即可。
6.6.错误的时间日期格式
该问题原因是将mysql迁移到达梦数据库时,mysql中存在0000-00-00 00:00:00这种格式的存在,在达梦数据库中这种格式会报错。

解决办法:
- 迁移达梦数据库时将该字段类型修改为字符类型,迁移过来之后修改
- 修该源库该条数据库时间格式,重新迁移
6.7.长度超出定义
错误消息: 列[RECOMMEND]长度超出定义,错误号: -6169

解决办法:
修改列字段映射为2之后重新迁移正常

24小时免费服务热线:400 991 6599
达梦技术社区:https://eco.dameng.com