Python —— UI自动化之八大元素定位
1、基础元素定位
1、id定位
使用html中标签的id元素去定位,在一般定位中优先选择,举例:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
driver.maximize_window() # 放大窗口
'''第一种方式,也是最简单的定位方式,ID'''
driver.find_element(By.ID,"kw").send_keys("测试开发工程师")
sleep(5)2、name定位
举例如下:
找到百度页面的name元素:
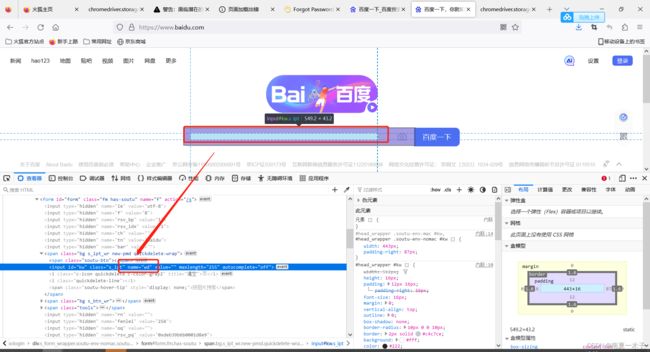
通过name方式定位这个元素:
'''第二种方式,通过name定位'''
driver.find_element(By.NAME,"wd").send_keys("高薪工作")
sleep(5) #停留5秒针
driver.close() # 关闭浏览器操作3、标签名定位
一般一个页面会有多个重复的标签名,标签名定位默认去找页面中的第一个input标签名的元素,所以这种方式几乎不使用
'''第三种方式,通过标签名定位'''
driver.find_element(By.TAG_NAME,"input").send_keys("高薪工作")
sleep(5)
driver.close()4、样式名定位
样式定位使用标签中的classname定位,在元素的class属性值 ,用的较少
注意:CLASS_NAME只能支持单个样式值,不能支持多个。如果要能去支持多个样式值的话,我们可以使用CSS选择器/Xpath

'''第四种方式,通过样式名定位'''
driver.find_element(By.CLASS_NAME,"s_ipt").send_keys("高薪工作")
sleep(5)
driver.close()
5、超链接完整文本定位方式

'''第五种方式:link_text定位 - 超链接元素的文本'''
driver.find_element(By.LINK_TEXT,"更多").click()
sleep(5)
driver.close()备注一个小知识:什么情况下超链接会打开一个新的窗口,超链接元素有属性target="_blank"

6、超链接部门文本定位方式

'''第五种方式:link_text定位 - 超链接元素的文本'''
driver.find_element(By.PARTIAL_LINK_TEXT,"北京延庆下雪").click()
sleep(5)
driver.close()备注:超链接定位元素是建立在要定位的元素在a标签中的基础上
2、cssSelector选择器 - 元素定位
1、根据标签名,实际使用很少
driver.find_element(By.CSS_SELECTOR,"input");2、根据ID
使用id定位时,id的值前方需要加 “#” 号,有2种方式:
1、“#id值”,如下:
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("测试派")
sleep(5)
driver.close()2、“标签名#id值”,如下:
driver.find_element(By.CSS_SELECTOR,"input#kw").send_keys("柠檬")
sleep(5)
driver.close()3、根据className
有2种方式:
1、直接写样式名,写法 “.样式名”
driver.find_element(By.CSS_SELECTOR,".s_ipt").send_keys("橙子")
sleep(5)
driver.close()2、写标签名加样式名,写法 “标签名.样式名”
driver.find_element(By.CSS_SELECTOR,"input.s_ipt").send_keys("橙子")
sleep(5)
driver.close()4、根据属性选择定位
写法:“标签名[属性名=‘属性值’]”
driver.find_element(By.CSS_SELECTOR,"div[aria-label='百度热搜']").click()
sleep(3)
driver.close()5、多属性选择定位
写法:"标签名[属性1='属性值'][属性2='属性值']"
driver.find_element(By.CSS_SELECTOR,"input[class='s_ipt'][name='wd']").send_keys("你好")
sleep(5)
driver.close()3、xpath元素定位(支持web页面+APP页面+小程序页面)
1、概述
xpath是一种path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标。xpath基于XML文档树形结构,是XML路径语言,用来查询xml文档中的节点。xpath既可以用于XML,也可以用于HTML。
以下介绍xpath的定位方式。
2、xpath绝对定位即绝对路径,一般不推荐使用
绝对路径以 / (单引号)表示,而且是让解析引擎从文档的根节点开始解析,也就是html这个节点下开始解析,举例如下:
找到要定位的元素的html标签,在标签旁边点击右键 - 选择 copy - 选择Copy full Xpath,即可复制当前标签的绝对路径,可以看到有 xpath和full xpath两种方式,xpath代表相对路径,full xpath是绝对路径
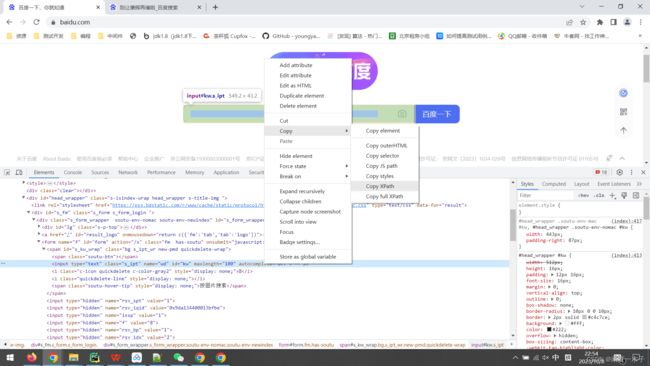
代码:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[5]/div[1]/div/form/span[1]/input").send_keys("测试")
sleep(5)
driver.close()这个代码是有问题的,不能找到指定元素
3、xpath相对路径
相对路径则以 // (双斜杠)表示,则表示让解析的引擎从文档的任意符合的元素节点开始运行解析(条件:身高、体重)
1、属性定位
有2种定位方式:
1、//标签名[@属性名=‘值’] 或者 标签名[属性名=‘属性值’] #css选择器的写法
driver.find_element(By.XPATH,"//*[@id='kw']").send_keys("测试找工作")
2、多个属性定位,// 标签名[@属性名=‘值1’ and @属性名=‘值2’]
driver.find_element(By.XPATH,"//input[@class='s_ipt' and @name='wd']").send_keys("测试开发工程师")
2、文本定位
driver.find_element(By.XPATH,"//a[text()='网盘']").click()
3、*代表通配符,表示筛选所有的标签名
//*[@id='kw']4、包含匹配 - 模糊匹配-contains函数
使用场景:当文本或者属性中的值过长,可以使用它来简化表达式,写法://标签名[contains(@属性名,'值')] 、//标签名[contains(text(),'值')]
注意:写被包含的部分的时候,这部分必须是原始值连续的一段字串,不能是间隔的,有2种方式
1、属性包含匹配
百度页面局举例:
driver.find_element(By.XPATH,"//span[contains(@class,'s-top-right-text')]").click()
2、文本包含匹配
携程页面举例:
driver.find_element(By.XPATH,"//h3[contains(text(),'国内火')]").click()
5、层级关系定位(对前面的补充)
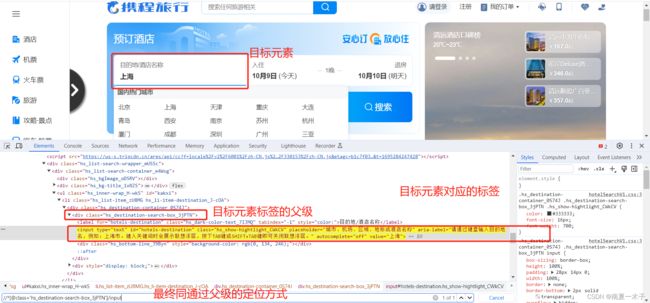
driver.find_element(By.XPATH,"//*[@class='hs_destination-search-box_3jPTN']/input").send_keys("北京")

driver.find_element(By.XPATH,"//*[@id='hotelSearchV1']//input[@class='hs_show-hightlight_CWkCV']").send_keys("测试")
6、xpath轴定位
使用场景:如果元素之间有父关系(儿子找爸爸)、兄弟关系(找哥哥/找弟弟)
| 轴名称 | 释义 |
| ancestor | 选取当前节点的所有祖先节点(包括父节点) |
| parent | 选取当前节点的父节点 |
| preceding | 选取当前节点之前的所有节点 |
| preceding-sibling |
选取当前节点之前的所有兄弟节点 -- 找哥哥
|
| following |
选取当前节点之后的所有节点
|
| following-sibling |
选取当前节点之后的所有兄弟节点 -- 找弟弟
|
使用语法:轴名称::标签名,如://a[text()='登录']//parent::td
举例:在这个豆瓣电影页面,定位“选座购票”
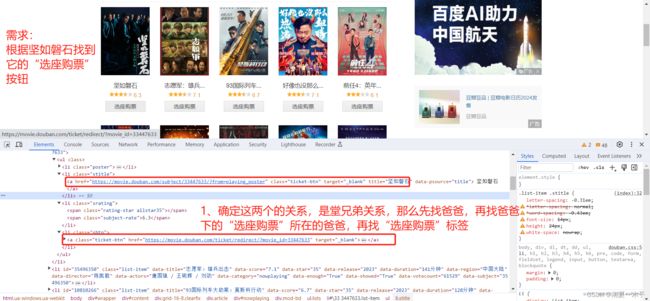
可以这样写:
//a[text()='坚如磐石']/parent::li/following-sibling::li[2]/a