1.自动化测试+selenium+八大定位元素
1.自动化测试简介
1.1 什么是自动化测试
自动化测试就是把以人为驱动转化为 机器执行的过程。目的是将过于繁杂的固定的手工测试行为转化为自动化执行,从而有更多的时间来走手工测试。
自动化功能测试:测开。目前主流技术:Selenium
自动化性能测试:性能测试
自动化测试可以实现:
1.一般都是应用在回归测试阶段,对系统的核心流程(固定的流程)进行回归测试时使用。简单来说自动化就是一个测试手段
2.一般自动化是如何确定执行的?
开会——评估系统是否具备自动化的条件——评估提取的核心主体是哪些是必须要纳入自动化测试范畴的——设计自动化测试框架——制定研发计划——实现——测试部署
1.2 测试开发是什么?
测试开发是应用代码来实现自动化测试,Django和Flask是python web框架
自动化分层 :
*UI层:基于系统UI界面来实现的自动化测试,是颗粒度最粗,主要关注功能和流程的正常实现,应用Rrequests和Appium来实现这个层级的测试技术
*Service层:接口自动化,主要关注服务于系统的接口数据是否正常,逻辑是否正确,应用Requests和HTTPClient来实现测试
Unit层:单元测试层级,测试粒度最小,Junit5和UnitTest来实现的
自动化测试的实际介入:1.常规的回归测试阶段
2.接口自动化,在前后端联调之前可以介入实现后端测试
****什么场景适合走自动化测试:1.长期运行的系统,针对项目本身设计一个测试框架(POM设计模式)
2.短平快类型系统 ,针对各类不同项目设计一套测试框架(关键字驱动设计模式)
3.外包
4.初创团队
NetWork:抓包工具,限度设置
Chrome浏览器需要关闭自动更新设置(此电脑-管理-应用与服务-服务-Google相关服务全部设置为关闭,并且改为手动启动方式)
什么样的项目适合做自动化测试?
三个条件:软件需求变更不频繁;项目周期比较长(最低一年以上,最好是自研项目);
2.Selenium介绍
目前业内最核心的技术为为自动化测试,selenium是最为主流的自动化测试工具
Appium是基于Selenium继承实现的,
自行安装WebDriver:百度进行下载。一定要安装适配版本的Chromedriver,否则启动浏览器会报错
无论是什么浏览器,都要关闭自动更新。
在现阶段测试中,只会使用Selenium+WebDriver来实现自动化测试
环境搭建:1.安装Selenium:通过pip install selenium/通过Pycharm中的interpreter来进行安装
2.WebDriver:
2.1 Python+Selenium的实际操作
WebDriver+Selenium运行原理:
WebDrive:其实是一个服务端,启动时时是启动一个服务。由该服务上传下发基于HTTP协议的指令
环境配置完成以后,编写一个driver_demo来实现访问指定的URL
#导入webdriver
from selenium import webdriver
#from selenium.webdriver.chrome.webdriver import WebDriver
#创建一个浏览器对象
driver=webdriver.Chrome()
#wb=WebDriver(executable_path="chromedriver")
#浏览器访问指定URL
driver.get('http://www.baidu.com')
元素的定位,输入文本,并点击
元素定位就是通过元素的信息或元素层级结构来定位元素的
定位元素依赖于1,标签名2,属性3,层级4,路径
#导入webdriver
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.by import By
#创建一个浏览器对象
wb=WebDriver(executable_path="chromedriver")
#浏览器访问指定URL
wb.execute('get',{'url':'http://www.baidu.com'})
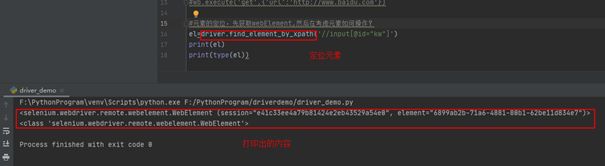
#元素的定位,先获取webElement,然后在考虑元素如何操作?
el=wb.execute('findElement',{
'using':By.XPATH,
'value':'//input[@id="kw"]'
})['value']
el._execute('sendKeysToElement',{'text':'刘阳',
'value':''})
el1=wb.execute('findElement',{
'using':By.XPATH,
'value':'//input[@id="su"]'
})['value']
el1._execute('clickElement')
''
自动化中的hello world
'''
#导入WebDriver模块
from selenium import webdriver
#导入强制等待
from time import sleep
#创建chrome浏览器对象
driver=webdriver.Chrome()
#访问指定url
driver.get('http://www.baidu.com')
#查找需要操作的元素
we_input=driver.find_element_by_id("kw")
#对元素进行输入操作
we_input.send_keys('刘阳')
#点击百度一下按钮,执行本次搜索操作
we_button=driver.find_element_by_id('su')
we_button.click()
#WebDriver是一个服务端代理,当自动化结束时,需要记得释放资源
sleep(5)
driver.quit()
如何访问指定的URL?
Webdriver是浏览器驱动的服务端。Webdriver封装了execute()方法,execute()发送请求
实例:实战商城实现登录操作
完成上述按钮的步骤:
- 导包 from selenium import webdriver from time import sleep
- 获取浏览器对象 driver=webdriver.chrome()
- 打开url:driver.get()
- 获取文本框 driver.find_element_by_id()
- 输入文本内容:driver.send_key()
- 获取按钮属性位置
- 点击按钮
- 暂停几秒 sleep()
- 关闭驱动 driver.quit()
close与quit的区别:close:关闭当前浏览页;quit:关闭浏览器,释放进程
报错:element not interactable 定位的元素无法进行交互
报错:NoSuchElementException:没有找到相关的元素定位
#为实现该功能,报错we_button1.click()
from selenium import webdriver
#导入强制等待
from time import sleep
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.by import By
#创建chrome浏览器对象
driver=webdriver.Chrome()
#访问指定url
driver.get('http://39.98.138.157/shopxo/index.php')
#driver.get('http://39.98.138.157/shopxo/index.php?s=/index/user/logininfo.html')
# #查找需要操作的元素
# we_input=driver.find_element_by_id("search-input")
#
#
we_button1=driver.find_element_by_xpath('http://39.98.138.157/shopxo/index.php?s=/index/user/logininfo.html')
we_button1.click()
#输入用户名、密码
we_input=driver.find_element_by_name('accounts')
we_input.send_keys('666666')
we_input=driver.find_element_by_name('pwd')
we_input.send_keys('111111')
#点击登录按钮
we_button=driver.find_element_by_class_name('am-btn am-btn-primary am-radius am-btn-sm btn-loading-example')
we_button.click()
修改为正确代码:
from selenium import webdriver
#导入强制等待
from time import sleep
#创建chrome浏览器对象
driver=webdriver.Chrome()
#访问指定url、
#注意:"\"反斜杠是python中的转义字符(本地url地址时,可能会遇到),解决方法:前面加r(r是一个修饰的字符串,如果字符串有转义字符,不进行转义使用)或者"\\"即可
#使用本地浏览模式,前缀必须加file:///
#file:///D:/study/大二第一学期/jsp/jsp课后练习题/0404160218刘阳/index.jsp
driver.get('http://39.98.138.157/shopxo/index.php')
#查找需要操作的元素,该模块需要完成用户登录的模拟,休要点击登录输入用户名、密码,再次点击登录实现登陆成功
driver.find_element_by_link_text('登录').click()
sleep(5)
#输入用户名、密码
we_input=driver.find_element_by_name('accounts')
we_input.send_keys('666666')
we_input=driver.find_element_by_name('pwd')
we_input.send_keys('111111')
sleep(5)
#点击登录按钮
web_button=driver.find_element_by_link_text('登录').click()
#WebDriver是一个服务端代理,当自动化结束时,需要记得释放资源
sleep(10)
driver.quit()
3.八大元素定位
所有的UI层的自动化都是基于元素定位来实现的,所有的被操作原色,都是webElement对象
元素=html便签
超链接:img/a/input/button/
通用:div/li/span/…
实际的系统中,元素的标签不是由表象来决定的,是通过css样式表来决定的
自动化时,就是基于标签的属性来定位标签
如何精准定位到需要操作的元素:
八大元素定位
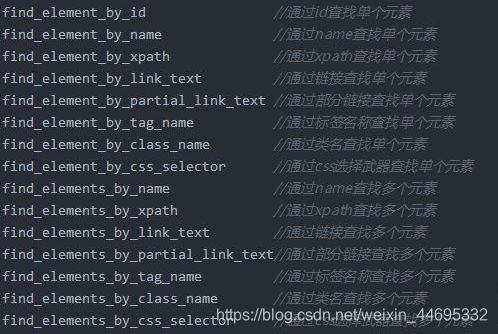
查找单个元素:
{
(id,name,class_name【使用元素的class属性的定位】:属性定
(tag_name:【标签名称<标签名 xxx/>】标签定位) (link_text,partial_link_text[模糊查询]:定位a标签)
(xpath【基于元素路径定位】,css【基于元素选择器定位】:功能强大)
}
#基于id定位 (driver.)
| 查找单个元素方法 | 执行记录 |
|---|---|
| **find_element_by_name | √基于name定位 基于元素属性中的name值来进行定位 name类似于身份证上的名字,有可能重名 |
| **find_element_by_id | √基于元素属性中的id值来进行定位 id类似于身份证号,不出意外,不会重复 |
| find_element_by_link_text | √基于link text定位 主要用于超链接进行定位 driver.find_element_by_link_text(‘注册’).click() |
| **find_element_by_xpath | 目前应用最多的一种行为,基于页面结构来进行的定位 -嵌套关系,直接在源文件中copy xpath内容即可 绝对路径:从html根路径下一层一层往下数,找到对应的层级,从而找到元素(绝境) 相对路径:基于匹配制度查看元素。依据xpath结构来走 |
| find_element_by_partial_link_text | 基于partial link text:link text的模糊查询版本,类似于数据库中的link % |
| find_element_by_tag_name | 通常使用elements <标签名 /> 不方便定位 。如果存在多个相同标签,则返回符合条件的第一个标签 |
| find_element_by_class_name | 基于classname定位 不建议使用,有空格的情况下,会出现查询不到的情况 |
| find_element_by_css_selector | 应用相对较多的一种行为,最初IE浏览器不支持xpath.万群基于class属性来实现的定位 |

一:为什么要使用xpath,css定位呢?
- id,name,class_name:依赖于元素三个对应的属性,如果元素么有以上三个属性,则定位失败
- link_text,partial_link_text:只能定位超链接
- tag_name:只能查找页面唯一元素,或页面中多个相同元素的第一个元素
二:确认xpath路径是否正确?
- 在开发者工具elements页面使用ctrl+f查找,进行判断
- 在console中输入$x()进行校验
如果要基于text来定位元素,在[]中添加text()=‘文本内容’来进行查找。例如://a[text()=‘登录’]
三:xpath定位策略(方式)
- 路径-定位:绝对: 以单斜杠开头,逐级开始编写(不可跳级。如/html/boby/div/p[1]/input)相对:以//开头,//后跟元素名称,不知元素名称可以使用代替 如//input,//
- 利用元素属性-定位:在xpath中,所有的属性必须使用@符号修饰。如://*[@id=‘id值’]
- 属性与逻辑结合-定位://*[@id=‘id值’ and @属性=‘属性值’]
- 层级与属性结合-定位://*[@id=‘父级id属性值’]/子集元素(input)
提示:
- 一般使用指定标签名称,不建议使用*代替,比较慢
- 无论是绝对路径还是相对路径,/后面必须为元素的名称或者*
- 扩展-工作中,如果能使用相对路径就不使用绝对路径
当定位元素无法直接定位时,可以通通过定位子级元素返回父级来获取元素
查找多个元素:所查找的元素是一个list集合。 建议手写xpath
| 查找多个元素方法 | 执行记录 |
|---|---|
| find_elements_by_name | |
| find_elements_by_id | √ |
| find_elements_by_xpath | – |
| find_elements_by_link_text | 多个”百度“元素,通过下标来进行定位 list列表,0,1,2,3… |
| find_elements_by_tag_name | 标签名进行定位,重复度最高,只有在需要定位后进行二次筛选dr=driver.find_elements_by_tag_name(‘a’)for d in dr: if d.text==‘登录’:d.click()- |
| find_elements_by_class_name | – |
| find_elements_by_css_selector | – |
两个私有方法
| 两个私有方法 | 执行记录 |
|---|---|
| find_element | |
| find_elements |

css定位常用策略:
- id选择器:根据元素id属性来选择:#id
- class选择器:根据元素class属性来选择:.class
- 元素选择器;根据元素的标签名选择: a
- 属性选择器: [action="/s"]
- 层级选择器:p>a
八大元素定位使用:
from selenium import webdriver
from time import sleep
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("菜鸟教程")#id 唯一
driver.find_element_by_name("wd").send_keys("菜鸟教程")#name 可重名
driver.find_element_by_class_name("s_ipt").send_keys("菜鸟教程")#class_name
driver.find_element_by_tag_name("input").send_keys("菜鸟教程")#tag_name:只返回第一个元素
#link_text:只能定位a标签,定位的内容必须为全部匹配
driver.find_element_by_link_text("新闻").click()# 点击新闻超链接 link_text:
#partial_link_text:只能定位a标签,定位的内容可以是模糊匹配,但需代表唯一性
driver.find_element_by_partial_link_text("新闻").click()
driver.find_element_by_xpath("//input[@class='s_ipt']").send_keys("hello")#xpath
driver.find_element_by_css_selector("#kw").send_keys("hello")#css id
driver.find_element_by_css_selector('.s_ipt')#css class
driver.find_element_by_css_selector('form')#css 元素
driver.find_element_by_css_selector('[action="/s"]')#css 属性
driver.find_element_by_css_selector('p->a')#css 层级
sleep(3)
课后作业:1.上次的登录流程,将所有的元素定位全部替换为手写xpath的形式来实现
2.基于网易云音乐实现一次登录操作自动化 :http://music.163.com