AlphaPose windows+ubuntu双平台配置运行
AlphaPose更新的比较快,很多以前的教程已经和现在不一样了,本文写于2022年11月,希望可以帮助大家成功配置运行AlphaPose。
目录
源代码
根据pytorch版本选择分支
Anaconda查看自己pytorch版本的方法
Anaconda创建新的环境安装pytorch
AlphaPose的README
Model Zoo
Quick Start
windows运行
cython_bbox
Ubuntu运行
其他
源代码
GitHub - MVIG-SJTU/AlphaPose: Real-Time and Accurate Full-Body Multi-Person Pose Estimation&Tracking System
需要注意,这里最好去官网的仓库,去其他人的仓库可能会没有后续需要用到的分支。在GitHub直接搜AlphaPose,星星最多的那个就是了。
根据pytorch版本选择分支
在下图位置点开分支。

可以看到以下三个主要使用的分支,分别是pytorch版本大于等于1.11的、在1.5到1.11之间的和pytorch版本小于1.5的,根据自己的pytorch版本进行选择。本文先使用主分支,后来遇到问题后切换到pytorch<1.11分支,未使用过pytorch<1.5分支,请注意甄别。

Anaconda查看自己pytorch版本的方法
①conda activate 你的环境名
②conda list
然后找到pytorch版本,如下图中的1.10.0
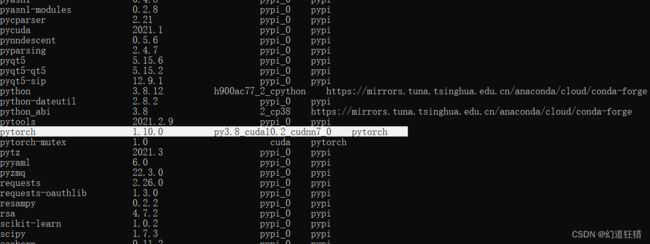
Anaconda创建新的环境安装pytorch
这里需要注意,如果你想用主分支的代码(更新最快),那么需要1.11及以上版本的pytorch,而在pytorch的github官网中可以看到,1.11版本需要python>=3.7,所以在创建环境时需要使用3.7版本以上的python。版本对应如下图:
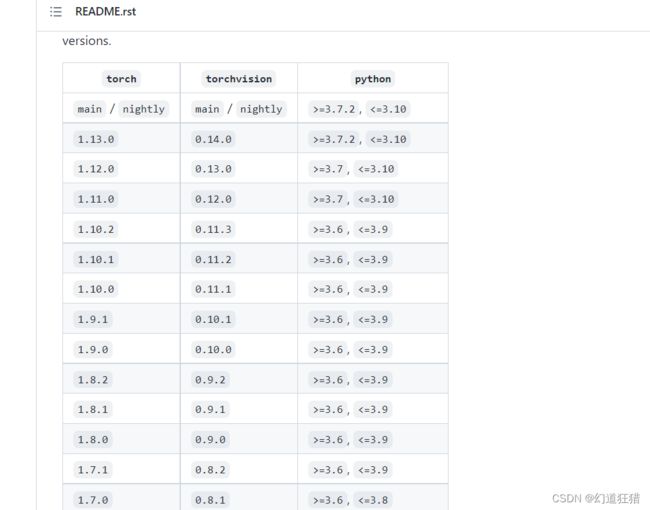
pytorch官网:
GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
Anaconda创建环境:
①conda create -n 你的环境名 python=3.7
②conda activate 你的环境名
③安装pytorch,去此路径根据电脑的cuda版本寻找对应安装命令。
Previous PyTorch Versions | PyTorch
如下图中,v1.11.0代表pytorch版本,Conda代表使用conda安装,Linux and Windows代表这俩平台。CUDA 10.2 CUDA 11.3代表不同版本的CUDA需要使用的安装命令。CUDA安装相关略。查看电脑的cuda版本:nvcc -V

由此可以根据pytorch版本选择分支下载代码。
AlphaPose的README
以下内容均在主分支的AlphaPose中,为我认为的需要注意的东西。按照先后顺序排列。
Model Zoo

点进MODEL_ZOO.md会发现,里面放了许多AlphaPose可用的模型及用法。
本文使用的是下图中的基于Halpe全身数据集的前26个关键点(不包含脸部和手部)的模型,这个ZOO里面内容非常多,如果此模型不能满足你的功能需求,可以仔细阅读这一页去选择自己需要的模型。
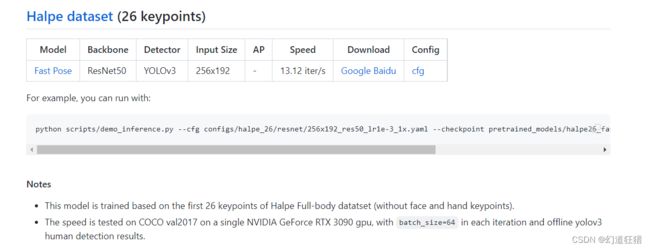
for example,you can run with:是教你如何使用这个模型的,后面的那一行代码如下:
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --indir examples/demo/ --save_img简化一下就是 python demo_inference.py --cfg xxx.yaml --checkpoint xxx.pth --indir xxx -- save_img
也就是使用
①python运行demo_inference.py,
②设置参数cfg为这个模型对应的.yaml,路径下都有,不用自己下载。
③设置参数checkpoint为这个模型对应的.pth,需要在Model Zoo里下载,然后放到参数中所述位置,也就是alphapose-master\pretrained_models下。

④设置输入的东西。
⑤设置保存图片。
这是命令行里的做法,不太方便,知道原理之后我们可以自己在pycharm中完成相关配置:

点击上图位置,进入下图的配置界面,其中parameters里就填刚刚那些参数,python interpreter里选之前创建的或已有的包含pytorch的环境。需要注意的是,官网样例中的参数,是按照在AlphaPose根目录设置的,而在pycharm运行,相当于是在代码目录运行,所以cfg等参数的地址需要进行修改,也就是加一个../表示回到上一级目录。

indir表示设置输入的图片文件夹,在windows下报错了,所以我直接使用了更简单的方法,把路径直接写在了代码中,删除了-- indir。但是-- save_img还是要保留的。

至此参数配置就算完成了,待环境配置好就可以运行了。
Quick Start

是教你linux下怎么用他写的inference.sh快速运行的,如果上一步在Zoo里已经弄好了这儿就不需要看了。后面需要训练自己的模型的时候再回来看这里。
windows运行
windows下配置好pycharm之后就右键运行吧,缺哪个库下哪个库,建议每一次下库之前都去百度一下这个库能不能直接pip install xxx,有些可以的,有些不行,比如cython_bbox就不能直接pip,
cython_bbox
在linux下需要先pip install cython,再pip install cython_bbox,但是在windows下就算这样也不行,需要先pip install cython,再
python -m pip install git+https://github.com/yanfengliu/cython_bbox.git等所有的库装好之后运行,会提示
No such file or directory: 'detector/yolo/cfg/yolov3-spp.cfg'
也是路径问题,直接点进报错的最后一个地方,在darknet.py中的50行左右
file = open(cfgfile, 'r')
把cfgfile换成绝对路径就行
file = open(r'D:\data\SIDS\code\zitaiguji\alphapose-master\detector\yolo\cfg\yolov3-spp.cfg', 'r')
然后加载yolo模型那儿也会报错,大约在darknet.py中的400多行,
fp = open(weightfile, "rb")
换成你自己的绝对路径。
fp = open(r'D:\data\SIDS\code\zitaiguji\alphapose-master\detector\yolo\data\yolov3-spp.weights', "rb")
这两步改完就能跑啦,windows似乎只能用CPU,我的笔记本跑起来十分费劲,跑几张图片看看效果就好了。效果确实比之前用的关键点模型好,所以决定在linux下使用。
Ubuntu运行
我把之前在windows下弄好的代码,包含yolo权重,骨骼关键点权重等,一起弄到了linux下,然后跟上面基本上相同的步骤,调整参数,运行,缺啥库安啥库,linux下安装cython_bbox需要先pip install cython,再pip install cython_bbox
还有No module named 'yaml
并不是pip install yaml,而是pip install pyyaml等。其他环境我不记得了,反正安装之前都搜一下准没错。
但是之后报了个很奇怪的错:
ImportError: cannot import 'roi_align_cuda' from partially initialized module 'alphapose.utils.roi_align' (most likely due to a circular import)
这个错误……网上找不到解决办法。
只有(3条消息) AlphaPose训练自己的数据集_cv-daily的博客-CSDN博客_alphapose 训练
这篇博客有所提及,但是我当时没看懂。去google了一下发现在AlphaPose的Issue里也有人遇到过相同的问题,但是同样没有解决办法。
cannot import name 'roi_align_cuda' · Issue #494 · MVIG-SJTU/AlphaPose · GitHub
不过我在这里看到有人提及setup.py,想了想好像确实之前在windows下一直没弄这个。
于是跟着下文进行了python setup.py build develop操作。同时也在这里看到了关于pytorch<1.11分支的消息。(3条消息) 2022年最新AlphaPose环境配置(Linux+GPU)_独角兽团队的博客-CSDN博客_"git checkout \"pytorch<1.11"
后来又遇到了
detector/nms/src/nms_kernel.cu:5:10: fatal error: ATen/ceil_div.h: No such file or directory
5 | #include
| ^~~~~~~~~~~~~~~~~
compilation terminated.
error: command '/usr/lib/cuda/bin/nvcc' failed with exit status 1
的错误,在Issue中找到了这个问题
fatal error when running python setup.py build develop · Issue #1063 · MVIG-SJTU/AlphaPose · GitHub

我的pytorch版本也低于1.11。
看起来是pytorch版本的问题。因此更换成pytorch<1.11分支,最终成功在ubuntu下运行代码。
其他
--vis_fast这个参数,可以加快推理速度,默认是关闭的。开启后未见明显精度下降。不知道有什么其他影响。
--save_video可以保存视频。