SpringBoot和Hibernate——如何提高数据库性能
摘要:本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
前言
在软件开发领域,性能是重中之重。无论您是构建小型 Web 应用程序还是大型企业系统,用户都期望快速且响应迅速的软件。作为开发人员,我们不断努力优化我们的代码并减少那些可怕的加载时间。
影响应用程序性能的关键因素之一是数据库交互。数据库是许多应用程序的支柱,有效存储和检索数据至关重要。这就是流行的对象关系映射 (ORM) 框架 Hibernate 发挥作用的地方。Hibernate 通过将数据库表映射到 Java 对象来简化与数据库交互的过程。它是一个强大的工具,但像任何工具一样,它需要明智地使用。
在本文中,小编将带您了解我使用 Hibernate 二级缓存在 Spring Boot 应用程序中提高数据库性能的经验。我们将深入研究缓存策略、配置设置和最佳实践,以提高应用程序的响应能力。在本次旅程结束时,您将拥有增强数据库性能的知识和工具。
缓存
像 Hibernate 这样的 ORM 框架通过将数据库表映射到 Java 对象,提供了一种使用数据库的便捷方法。它们透明地缓存数据。缓存是指将经常访问的数据存储在内存中,从而减少重复查询数据库的需要。这可以带来显着的性能提升,尤其是处理大型对象图时。
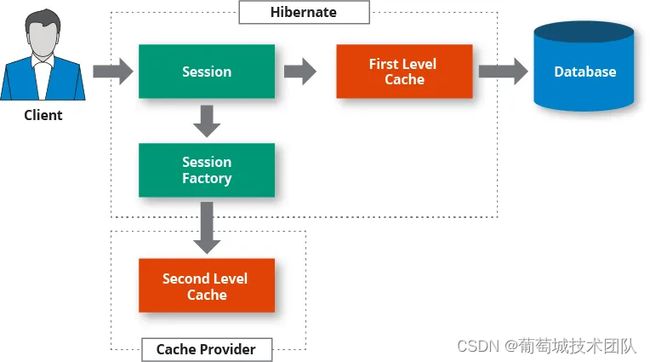
Hibernate 中的二级缓存是在会话工厂级别运行的共享缓存,使其可以跨多个会话访问。它用于存储和管理实体数据,以便可以有效地检索实体数据,而无需重复访问数据库。
二级缓存说明:
1.一级缓存:在Hibernate中, 每个会话(数据库事务)都有自己的一级缓存。此缓存用于存储和管理在该会话中检索或操作的实体实例。一级缓存是隔离的,并且与特定的会话绑定。当会话关闭时,一级缓存被丢弃。
2.二级缓存:相比之下,二级缓存是在从同一会话工厂创建的所有会话之间共享的全局缓存。它在更高的水平上运行,允许 跨不同会话和事务缓存和检索的数据。
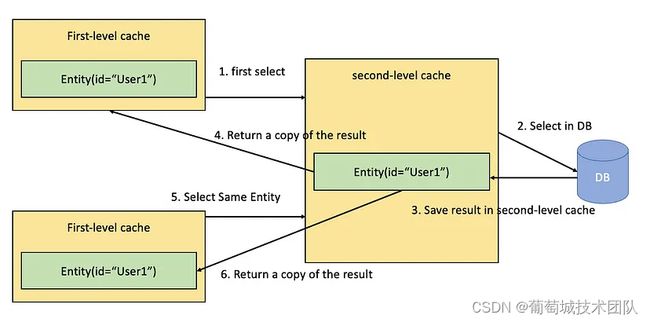
二级缓存的工作原理:
当通过 ID(主键)查找实体实例并为该实体启用二级缓存时,Hibernate 将执行以下步骤:
检查一级缓存: Hibernate 首先检查与当前会话关联的一级缓存(会话缓存)。如果实体实例已经存在于一级缓存中,则立即返回,避免数据库查询。
检查二级缓存:如果在一级缓存中没有找到实体,Hibernate 将检查二级缓存。二级缓存在全局级别存储实体数据,使其可供所有会话访问。
从数据库加载:如果在一级缓存或二级缓存中都没有找到实体数据,Hibernate就会继续从数据库加载数据。一旦从数据库中获取数据,Hibernate 就会组装一个实体实例并将其存储在当前会话的一级缓存中。
后续调用的缓存:一旦实体实例位于一级缓存(会话缓存)中,同一会话中的所有后续调用都会返回该实体实例,而无需额外的数据库查询。另外,如果实体数据是从数据库中获取的,它也可以存储在二级缓存中以供其他会话将来使用。
如何使用 Spring Boot 使用二级缓存
第一步:设置 Spring Boot 项目
您可以使用 Spring Initializr 或您喜欢的 IDE 创建新的 Spring Boot 项目。确保至少选择 Spring Boot、Spring Data JPA、Hibernate、Ehcache 和 Web 所需的依赖项。
第二步:配置Ehcache
ehcache.xml在该目录下创建Ehcache配置文件src/main/resources。下面是一个简单的例子:
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://www.ehcache.org/ehcache.xsd"
updateCheck="true" monitoring="autodetect" dynamicConfig="true">
<defaultCache
maxEntriesLocalHeap="10000"
eternal="false"
timeToIdleSeconds="3600"
timeToLiveSeconds="7200"
overflowToDisk="false"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU" />
ehcache>
- timeToIdleSeconds:条目在被视为过期并删除之前可以在缓存中空闲(未访问)的最长时间(以秒为单位) 。
- maxEntriesLocalHeap:本地堆内存中存储的缓存条目的最大数量。当达到此限制时,旧条目将被逐出,以便为新条目腾出空间。
- timeToLiveSeconds:条目在被视为过期并被删除之前可以在缓存中存在的最长时间(以秒为单位),无论是否已被访问。
- diskPersistent:如果true,磁盘存储是持久的,这意味着即使在系统重新启动后条目也会保留。如果false,条目将在系统重新启动时丢失。
第三步:实体类
创建一个要缓存的实体。例如,一个Product实体:
@Entity
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private BigDecimal price;
// Constructors, getters, and setters
}
第四步:存储库接口
import org.springframework.data.jpa.repository.JpaRepository;
public interface ProductRepository extends JpaRepository<Product, Long> {
// Define custom query methods if needed
}
第五步:服务层
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public Product getProductById(Long productId) {
// The following query result will be cached if caching is configured properly
return productRepository.findById(productId).orElse(null);
}
// Other service methods
}
第六步:配置应用程序属性
确保application.properties 您具有启用缓存所需的属性并指定 Ehcache 配置:
# Enable Hibernate second-level cache
spring.jpa.properties.hibernate.cache.use_second_level_cache=true
# Specify the region factory class for Ehcache
spring.jpa.properties.hibernate.cache.region.factory_class=org.hibernate.cache.ehcache.EhCacheRegionFactory
# Ehcache configuration file location
spring.cache.ehcache.config=classpath:ehcache.xml
当调用 时productRepository.findById(productId),ProductServiceHibernate 和 Spring Data JPA 会处理会话和缓存管理。发生的情况如下:
Product如果在二级缓存中找到了所请求的实体(例如),则从缓存中返回该实体,并且不打开任何数据库会话。
如果在缓存中未找到实体,Spring Data JPA 将自动打开数据库会话。执行数据库查询以检索实体。
检索到的实体存储在二级缓存中并返回给您的服务方法。
关于SpringBoot的更多资料还可以点击这里。
缓存集合(一对多和多对多关系)
集合缓存允许您缓存关联实体的整个集合。这些集合可以是域模型的一部分,例如实体之间的一对多或多对多关系。
集合缓存很有价值在处理频繁加载的实体之间的关联时以及缓存可以显着提高性能的地方。当您启用集合缓存时,Hibernate 会缓存与实体关联的整个集合,例如列表或集。
当 Hibernate 缓存集合时,它不会缓存整个实体集合,而是缓存集合中包含的实体的 ID。
与缓存整个实体集合相比,仅缓存 ID可以减少内存使用量。
当集合更新时,只需使缓存中的相关ID失效,而不是整个集合。这最大限度地减少了缓存失效的开销。
@Entity
@Cacheable
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "category")
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
private List<Product> products;
// Getters and setters
}
@Entity
@Cacheable
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
private Category category;
// Getters and setters
}
- Hibernate 创建一个名为
的缓存区域com.example.model.Category.products。该区域专门用于存储与类别关联的产品的缓存集合。 - 假设我们有一个 ID 为 1 的类别,其中包含 ID 为 101、102 和 103 的产品。Hibernate
使用键值对将此数据存储在缓存中。 - 键值对可能看起来像"Category:1:products — [101, 102, 103]"