数据结构和算法概述及算法分析
一、数据结构和算法概述
B站学习视频
1.1首先我们为什么要学习数据结构?
数据结构和算法这门课程无论在哪个学校的计算机专业,都是一门必修课,因为这门课程非常重要的,是编程必备的基础,但是这门课程是一门不太好学习的课程,因为它学习起来是非常的枯燥乏味的。但是如果你想让自己的编程能力有质的飞跃,不再停留于调用现成的API,而是追求更完美的实现,那么这门课程就是你的必修课,因为程序设计=数据结构+算法。
通过对基础数据结构和算法的学习,能够更深层次的理解程序,提高编写代码的能力,让程序代码更优雅,性能更高。
1.2什么是数据结构?
官方解释: 数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及他们之间的关系和操作等相关问题的学科
大白话: 数据结构就是把数据元素按照一定的关系组织起来的集合,用来组织和存储数据
1.3数据结构分类
传统上,我们可以把数据结构分为**逻辑结构(按数据与数据之间的关系进行分类)和物理结构(按计算机存储角度进行分类)**两大类。
逻辑结构分类:
逻辑结构是从具体问题中抽象出来的模型,是抽象意义上的结构,按照对象中数据元素之间的相互关系分类,也是我们后面课题中需要关注和讨论的问题。
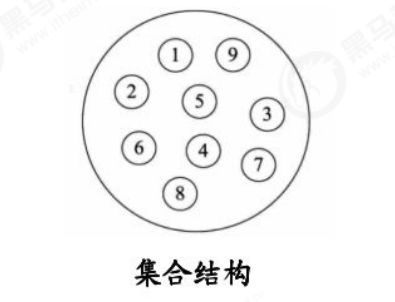
a.集合结构:集合结构中数据元素除了属于同一个集合外,他们之间没有任何其他的关系。
b.线性结构:线性结构中的数据元素之间存在一对一的关系

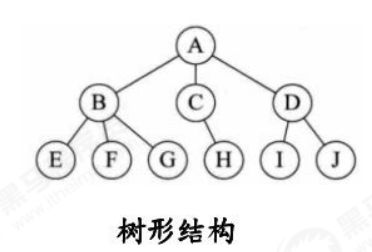
c.树形结构:树形结构中的数据元素之间存在一对多的层次关系
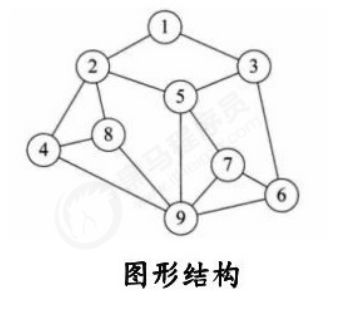
d.图形结构:图形结构的数据元素是多对多的关系
物理结构分类:
逻辑结构在计算机中真正的表示方式(又称为映像)称为物理结构,也可以叫做存储结构。常见的物理结构有顺序存储结构、链式存储结构。
顺序存储结构:
把数据元素放到地址连续的存储单元里面,其数据间的逻辑关系和物理关系是一致的 ,比如我们常用的数组就是顺序存储结构。

取值时间复杂度O(1)【根据下标直接取值】,插入删除时间复杂度O(n)【插入或删除位置之后的元素都要向前/向后移动一位】
链式存储结构:
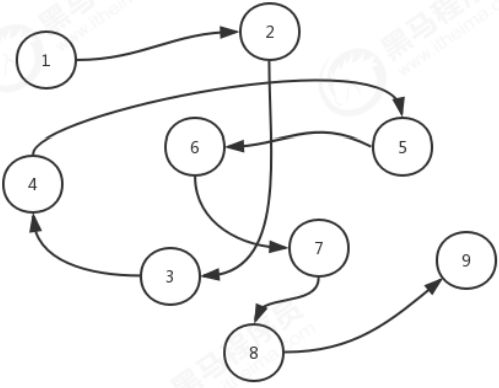
是把数据元素存放在任意的存储单元里面,这组存储单元可以是连续的也可以是不连续的。此时,数据元素之间并不能反映元素间的逻辑关系,因此在链式存储结构中引进了一个指针存放数据元素的地址,这样通过地址就可以找到相关联数据元素的位置
取值时间复杂度O(n)【需要遍历整条链表】,插入删除时间复杂度O(1)【直接改变指针指向即可】
1.4什么是算法
官方解释: 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
大白话: 根据一定的条件,对一些数据进行计算,得到需要的结果。
1.5算法初体验
在生活中,我们如果遇到某个问题,常常解决方案不是唯一的。
例如从西安到北京,如何去?会有不同的解决方案,我们可以坐飞机,可以坐火车,可以坐汽车,甚至可以步行,不同的解决方案带来的时间成本和金钱成本是不一样的,比如坐飞机用的时间最少,但是费用最高,步行费用最低,但时间最长。
再例如在北京二环内买一套四合院,如何付款?也会有不同的解决方案,可以一次性现金付清,也可以通过银行做按揭。这两种解决方案带来的成本也不一样,一次性付清,虽然当时出的钱多,压力大,但是没有利息,按揭虽然当时出的钱少,压力比较小,但是会有利息,而且30年的总利息几乎是贷款额度的一倍,需要多付钱。
在程序中,我们也可以用不同的算法解决相同的问题,而不同的算法的成本也是不相同的。总体上,一个优秀的算法追求以下两个目标: 1.花最少的时间完成需求; 2.占用最少的内存空间完成需求;
下面我们用一些实际案例体验一些算法。
需求1:
计算1到100的和。
第一种解法:
public static void main(String[] args) {
int sum = 0;
int n=100;
for (int i = 1; i <= n; i++) {
sum += i;
}
System.out.println("sum=" + sum);
}
第二种解法:
public static void main(String[] args) {
int sum = 0;
int n=100;
//高斯定理
sum = (n+1)*n/2;
System.out.println("sum="+sum);
}
第一种解法要完成需求,要完成以下几个动作:
1.定义两个整型变量;
2.执行100次加法运算;
3.打印结果到控制台;
第二种解法要完成需求,要完成以下几个动作:
1.定义两个整型变量;
2.执行1次加法运算,1次乘法运算,一次除法运算,总共3次运算;
3.打印结果到控制台;
很明显,第二种算法完成需求,花费的时间更少一些。
需求2:
计算10的阶乘
10! = 1*2*3...*10
第一种解法:
public class Test {
public static void main(String[] args) {
//递归实现
long result = fun1(10);
System.out.println(result);
}
//计算n的阶乘
public static long fun1(long n){
//递归出口
if (n==1){
return 1;
}
return n*fun1(n-1);
}
}
第二种解法:
public class Test {
public static void main(String[] args) {
long result = fun2(10);
System.out.println(result);
}
//计算n的阶乘
public static long fun2(long n){
int result=1;
for (long i = 1; i <= n; i++) {
result*=i;
}
return result;
}
}
第一种解法,使用递归完成需求,fun1方法会执行10次,并且第一次执行未完毕,调用第二次执行,第二次执行未完毕,调用第三次执行…最终,最多的时候,需要在栈内存同时开辟10块内存分别执行10个fun1方法。
第二种解法,使用for循环完成需求,fun2方法只会执行一次,最终,只需要在栈内存开辟一块内存执行fun2方法 即可。
很明显,第二种算法完成需求,占用的内存空间更小。
二、算法分析
2.1如何衡量一个算法的好坏呢?
当然是靠时间复杂度和空间复杂度了
时间复杂度:
顾名思义,一个程序完成所花费的时间
空间复杂度:
就是一个程序所占用的内存空间大小
时间复杂度越小空间复杂度越小算法越优
2.2算法时间复杂度
我们要计算算法时间耗费情况,首先我们得度量算法的执行时间,那么如何度量呢?
事后分析估算方法:
比较容易想到的方法就是我们把算法执行若干次,然后拿个计时器在旁边计时,这种事后统计的方法看上去的确不错,并且也并非要我们真的拿个计算器在旁边计算,因为计算机都提供了计时的功能。这种统计方法主要是通过设计好的测试程序和测试数据,利用计算机计时器对不同的算法编制的程序的运行时间进行比较,从而确定算法效率的高低,但是这种方法有很大的缺陷:必须依据算法实现编制好的测试程序,通常要花费大量时间和精力,测试完了如果发现测试的是非常糟糕的算法,那么之前所做的事情就全部白费了,并且不同的测试环境(硬件环境)的差别导致测试的结果差异也很大。
public static void main(String[] args) {
long start = System.currentTimeMillis();
int sum = 0;
int n=100;
for (int i = 1; i <= n; i++) {
sum += i;
}
System.out.println("sum=" + sum);
long end = System.currentTimeMillis();
System.out.println(end-start);
}
时间复杂度O(n)
事前分析估算方法:
在计算机程序编写前,依据统计方法对算法进行估算,经过总结,我们发现一个高级语言编写的程序程序在计算机上运行所消耗的时间取决于下列因素:
1.算法采用的策略和方案;
2.编译产生的代码质量;
3.问题的输入规模(所谓的问题输入规模就是输入量的多少);
4.机器执行指令的速度;
由此可见,抛开这些与计算机硬件、软件有关的因素,一个程序的运行时间依赖于算法的好坏和问题的输入规模。 如果算法固定,那么该算法的执行时间就只和问题的输入规模有关系了。
比较算法随着输入规模的增长量时,可以有以下规则:
1.算法函数中的常数可以忽略;
2.算法函数中最高次幂的常数因子可以忽略;
3.算法函数中最高次幂越小,算法效率越高。
大O记法
定义:
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随着n的变化情况并确定T(n)的量级。算法的时间复杂度,就是算法的时间量度,记作:T(n)=O(f(n))。它表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称时间复杂度,其中f(n)是问题规模n的某个函数。
在这里,我们需要明确一个事情:执行次数=执行时间
用大写O()来体现算法时间复杂度的记法,我们称之为大O记法。一般情况下,随着输入规模n的增大,T(n)增长最慢的算法为最优算法。
基于我们对函数渐近增长的分析,推导大O阶的表示法有以下几个规则可以使用:
1.用常数1取代运行时间中的所有加法常数;
2.在修改后的运行次数中,只保留高阶项;
3.如果最高阶项存在,且常数因子不为1,则去除与这个项相乘的常数;
常见的大O阶
1.线性阶
一般含有非嵌套循环涉及线性阶,线性阶就是随着输入规模的扩大,对应计算次数呈直线增长
2.平方阶
一般嵌套循环属于这种时间复杂度
3.立方阶
一般三层嵌套循环属于这种时间复杂度
4.对数阶
对数,属于高中数学的内容,我们分析程序以程序为主,数学为辅,所以不用过分担心。
int i=1,n=100;
while(i<n){
i = i*2;
}
由于每次i*2之后,就距离n更近一步,假设有x个2相乘后大于n,则会退出循环。由于是2^x=n,得到x=log(2)n,所以这个循环的时间复杂度为O(logn);
对于对数阶,由于随着输入规模n的增大,不管底数为多少,他们的增长趋势是一样的,所以我们会忽略底数
5.常数阶
一般不涉及循环操作的都是常数阶,因为它不会随着n的增长而增加操作次数。
常见时间复杂度总结:

他们的复杂程度从低到高依次为:
O(1)
从平方阶开始,随着输入规模的增大,时间成本会急剧增大,所以,我们的算法,尽可能的追求的是O(1),O(logn),O(n),O(nlogn)这几种时间复杂度,而如果发现算法的时间复杂度为平方阶、 立方阶或者更复杂的,那我们可以称这种算法是不可取的,需要优化。
最坏情况
假如有一个需求:
有一个存储了n个随机数字的数组,请从中查找出指定的数字的下标。
public int search(int num){
int[] arr={11,10,8,9,7,22,23,0};
for (int i = 0; i < arr.length; i++) {
if (num==arr[i]){
return i;
}
}
return -1;
}
最好情况:
查找的第一个数字就是期望的数字,那么算法的时间复杂度为O(1)
最坏情况:
查找的最后一个数字,才是期望的数字,那么算法的时间复杂度为O(n)
平均情况:
任何数字查找的平均成本是O(n/2)
最坏情况是一种保证,在应用中,这是一种最基本的保障,即使在最坏情况下,也能够正常提供服务,所以,除非特别指定,我们提到的运行时间都指的是最坏情况下的运行时间。
2.3算法空间复杂度
计算机的软硬件都经历了一个比较漫长的演变史,作为为运算提供环境的内存,更是如此,从早些时候的512k,经历了1M,2M,4M…等,发展到现在的8G,甚至16G和32G,所以早期,算法在运行过程中对内存的占用情况也是一个经常需要考虑的问题。我么可以用算法的空间复杂度来描述算法对内存的占用。
java中常见内存占用
1.基本数据类型内存占用情况:

2.计算机访问内存的方式都是一次一个字节
3.一个引用(机器地址)需要8个字节表示:
例如: Date date = new Date(),则date这个变量需要占用8个字节来表示
4.创建一个对象,比如new Date(),除了Date对象内部存储的数据(例如年月日等信息)占用的内存,该对象本身也有内存开销,每个对象的自身开销是16个字节,用来保存对象的头信息。 对象头信息?jvm?
5.一般内存的使用,如果不够8个字节,都会被自动填充为8字节:

6.java中数组也被限定为对象,他们一般都会因为记录长度而需要额外的内存,一个原始数据类型的数组一般需要 24字节的头信息(16个自己的对象开销,4字节用于保存长度以及4个填充字节)再加上保存值所需的内存。
了解了java的内存最基本的机制,就能够有效帮助我们估计大量程序的内存使用情况。 算法的空间复杂度计算公式记作:S(n)=O(f(n)),其中n为输入规模,f(n)为语句关于n所占存储空间的函数。
由于java中有内存垃圾回收机制,并且jvm对程序的内存占用也有优化(例如即时编译),我们无法精确的评估一个java程序的内存占用情况,但是了解了java的基本内存占用,使我们可以对java程序的内存占用情况进行估算。
由于现在的计算机设备内存一般都比较大,基本上个人计算机都是4G起步,大的可以达到32G,所以内存占用一般情况下并不是我们算法的瓶颈,普通情况下直接说复杂度,默认为算法的时间复杂度。
但是,如果你做的程序是嵌入式开发,尤其是一些传感器设备上的内置程序,由于这些设备的内存很小,一般为几 kb,这个时候对算法的空间复杂度就有要求了,但是一般做java开发的,基本上都是服务器开发,一般不存在这样的问题。