datawhale课程《transformers入门》笔记2:BERT入门
Bert
文章目录
-
- Bert
-
-
- 1.1 BERT简介
- 1.2 Bert训练中的关键点
- 1.3为什么要进行预训练?
- 2 BERT基础原理
-
- 2.1 Masked LM(带mask的单词级别语言模型训练)
-
-
- 2.1.2 为何引入mask机制**
- 2.1.3 Masked LM训练过程
- 2.1.4 为什么选[CLS]表示整句话语义?
-
- 2.2 引入Next Sentence Prediction (NSP,句子级别的连续性预测任务)
- 2.3 模型输入输出
- 3. BERT实际应用
-
- 3.1 接分类器微调
- 3.2 BERT用于特征提取
- 4.BERT和transformer的异同点:
-
- 4.1BERT只使用Transformer的Encoder部分
-
参考《图解BERT》
开篇先分享苏神的两篇文章《Attention is All You Need》浅读(简介+代码)、《Sep从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。还有一篇讲BERT输入的《为什么BERT有3个嵌入层,它们都是如何实现的》(这篇不感兴趣可以不看)
1.1 BERT简介
BERT是2018年10月由Google AI研究院提出的一种预训练模型,在多种不同NLP测试中创出SOTA表现,成为NLP发展史上的里程碑式的模型成就。BERT的出现标志着NLP 新时代的开始。
BERT全称是“Bidirectional Encoder Representation from Transformers“,即双向Transformer解码器。是一种NLP领域的龙骨模型,用来提取各类任务的基础特征,即作为预训练模型为下游NLP任务提供帮助。
1.2 Bert训练中的关键点
BERT模型有四大关键词: Pre-trained, Deep, Bidirectional Transformer, Language Understanding
a. Pre-trained:
首先明确这是个预训练的语言模型,使用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
b. Deep
Google开源了Base和Large两个版本的BERT模型,供所有人使用
Base:版本Layer = 12, Hidden = 768, Head = 12, Total Parameters = 110M
Large版本:Layer = 24, Hidden = 1024, Head = 16, Total Parameters = 340M
对比于原始论文的Transformer: Layer = 6, Hidden = 2048, Head = 8,可以看出Bert是一个深而窄的模型,效果更好。
C. Bidirectional Transformer:
Bert的创新点,BERT的模型架构基于多层双向转换解码。Bert直接引用了Transformer架构中的Encoder模块,并舍弃了Decoder模块, 这样便自动拥有了双向编码能力和强大的特征提取能力。“双向”表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息。
D. Language Understanding: 更加侧重语言的理解,而不仅仅是生成(Language Generation)
1.3为什么要进行预训练?
随着深度学习的发展,模型参数的数量迅速增加。需要更大的数据集来完全训练模型参数并防止过度拟合。但是,由于注释成本极其昂贵,因此对于大多数NLP任务而言,构建大规模的标记数据集是一项巨大的挑战,尤其是对于语法和语义相关的任务。
相反,大规模的未标记语料库相对容易构建。为了利用巨大的未标记文本数据,我们可以首先从它们中学习良好的表示形式(通用语法规则),然后将这些表示形式用于其他任务。最近的研究表明,借助从大型无注释语料库中的PTMs提取的表示形式,可以在许多NLP任务上显着提高性能。
预训练的优势可以进一步归纳如下:
1.学习通用语言表示形式:在庞大的文本语料库上进行预训练,可以学习通用的语言表示形式,帮助完成下游任务。
2.提供了更好的模型初始化:可以看做给后续模型的提供良好初始化,通常可以带来更好的泛化性能并加快目标任务的收敛速度。
3.可以将预训练视为一种正则化,以避免对小数据过度拟合
4.可以将的Bert模型作当做一个特征提取器,从而节省了从零开始训练语言处理模型所需要的时间、精力、知识和资源。
2 BERT基础原理
BERT的Pre-trained阶段有两大核心任务先介绍Masked LM。
2.1 Masked LM(带mask的单词级别语言模型训练)
BERT 模型的这个预训练过程其实就是在模仿我们学语言的过程,思想来源于「完形填空」的任务。具体来说,在一句话中随机选择 15% 的词汇抹去用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。
2.1.2 为何引入mask机制**
Encoder 的 Self Attention 层,每个 token 会把大部分注意力集中到自己身上,那么这样将容易预测到每个 token,模型学不到有用的信息。所以BERT 提出使用 mask,把需要预测的词屏蔽掉,可以在不泄露 label 的情况下融合双向语义信息。
为什么不把15%的词全部 [MASK] 替换?
如果我们 100% 地使用 [MASK],非屏蔽词仍然用于上下文,但该模型已针对预测屏蔽词进行了优化。模型只需要保证输出层的分类准确,对于输出层的向量表征并不关心,模型不一定会为非屏蔽词生成良好的标记表示,因此可能会导致最终的向量输出效果并不好 。
而且在下游的自然语言处理任务中,语句中并不会出现 [MASK] 标记,[MASK]仅仅只是为了训练。为了和后续任务保持一致,不应该全部替换。
为什么要随机替换?
模型不知道哪个 token 位是被随机替换的,就迫使模型尽量在每一个词上都学习到一个全局语境下的表征,因而也能够让 BERT 获得更好的语境相关的词向量(这正是解决一词多义的最重要特性);
为什么要保留部分不变?
保持不变,也就是真的有 10% 的情况下是泄密的(占所有词的比例为15% * 10% = 1.5%),这样能够给模型一定的 bias ,相当于是额外的奖励,将模型对于词的表征能够拉向词的真实表征。(此时输入层是待预测词的真实 embedding,在输出层中的该词位置得到的embedding,是经过层层 Self-attention 后得到的,这部分 embedding 里多少依然保留有部分输入 embedding 的信息,而这部分就是通过输入一定比例的真实词所带来的额外奖励,最终会使得模型的输出向量朝输入层的真实 embedding 有一个偏移)。
为何既有10%概率[MASK]又有10%概率保持不变
如果我们 90% 的时间使用 [MASK],10% 的时间使用随机单词,这将告诉模型观察到的单词永远不会正确。如果我们 90% 的时间使用 [MASK],10% 的时间保持相同的单词,那么模型可以简单地复制非上下文嵌入。
原文链接:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/109475187
而且在这一种高度不确定的情况下, 反倒逼着模型快速学习该token的分布式上下文的语义, 更多地依赖于上下文信息去预测词汇,尽最大努力学习原始语言说话的样子!!! 同时因为原始文本中只有15%的token参与了MASK操作, 所以并不会破坏原语言的表达能力和语言规则!!!并且赋予了模型一定的纠错能力( BERT 模型 [Mask] 标记可以看做是引入了噪音)
预测[mask]标记对应单词时,不仅要理解当前空缺位置之前的词,还要理解空缺位置之后的词,从而达到双向建模的目的。
2.1.3 Masked LM训练过程

具体的,如上图。在进行mask LM时,sentenceA起始位置字符为[CLS],它 的含义是分类(class的缩写)。[CLS]对应的输出向量T是整个句子的embedding,可以作为文本分类时,后续分类器的输入,即[CLS]对应向量直接拿来分类。特殊符[SEP]是用于分割两个句子。在最后一个句子的尾部也会加上[SEP] token。训练中,sentenceA的中的每个词对应的句子向量都是sentenceA。
2.1.4 为什么选[CLS]表示整句话语义?
因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。
而[CLS]位本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。
当然,也可以通过对最后一层所有词的embedding做pooling去表征句子语义。
2.2 引入Next Sentence Prediction (NSP,句子级别的连续性预测任务)
BERT为了更好地处理多个句子之间的关系(比如问答系统,智能聊天机器人等场景),预训练过程还包括一个额外的任务,即预测输入 BERT 的两段文本A和B是否为连续的文本。引入这个任务可以更好地让模型学到连续的文本片段之间的关系。训练过程如下图所示:

Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练(所以第二个句子有50%的几率是第一个句子的下一句),与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
2.3 模型输入输出
1.模型输入
BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示。
更具体的,Bert的语言输入表示包含了3个组成部分:
1.词嵌入向量: word embeddings,第一个单词是CLS,可以用于之后的分类任务
2.语句向量: segmentation embeddings,用来区别两种句子。(因为预训练不光做LM还要做以两个句子为输入的分类任务)
3.位置编码向量: position embeddings
最终的embedding向量是将这3个向量直接相加得到。与 Transformer 本身的 Encoder 端相比,BERT 的 Transformer Encoder 端输入的向量表示,多了segmentation embeddings。

就像 Transformer 中普通的 Encoder 一样,BERT 将一串单词作为输入,这些单词在 Encoder 的栈中不断向上流动。每一层都会经过 Self Attention 层,并通过一个前馈神经网络,然后将结果传给下一个 Encoder。
2.模型输出:
想要获取获取bert模型的输出非常简单,使用 model.get_sequence_output()和model.get_pooled_output() 两个方法,但这两种方法针对NLP的任务需要进行一个选择
1、输出为 model.get_sequence_output()
这个获取每个token的output。输出shape是**[batch_size, seq_length, embedding_size]** 如果做seq2seq 或者ner 用这个。但是这里也包括[CLS]和[SEP],因此在做token级别的任务时要注意它。
2、输出为 model.get_pooled_output()
这个输出就是上述==[CLS]==的表示,输出shape是[batch size,hidden size]。
3、注意
bert模型限制了输入序列(语句)的最大长度为512(因为再长内存就不够用了)。
3. BERT实际应用
3.1 接分类器微调
以下图句子分类为例,我们将BERT的预训练结果,输入一个分类器(上图中的 Classifier,属于监督学习)进行训练。在训练过程中 几乎不用改动BERT模型,只根据任务训练分类器就行,这个训练过程即为微调。(即BERT+分类器模式)

3.2 BERT用于特征提取
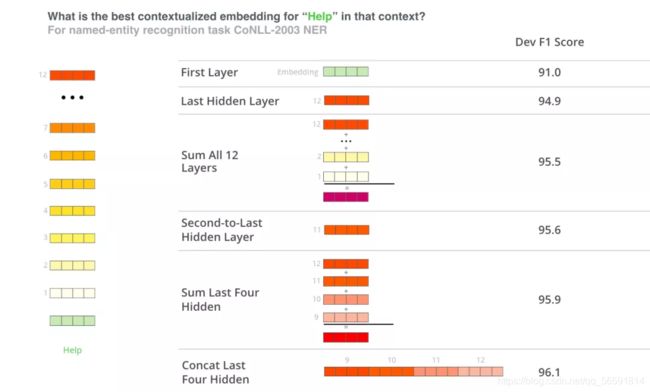
使用 BERT 并不是只有微调这一种方法。就像 ELMo 一样,你可以使用预训练的 BERT 来创建语境化的词嵌入。然后你可以把这些词嵌入用到你现有的模型中。论文里也提到,这种方法在命名实体识别任务中的效果,接近于微调 BERT 模型的效果。(embedding模型选用BERT提取的词向量特征)

那么哪种向量最适合作为上下文词嵌入?我认为这取决于任务。论文里验证了 6 种选择(与微调后的96.4 分的模型相比):
4.BERT和transformer的异同点:
4.1BERT只使用Transformer的Encoder部分
为什么BERT只使用了encoder部分?
1.从两种模型的任务场景来说:
Transformer最初是用来做机器翻译的,所以借用了seq2seq的结构,用encoder来编码提取特征,用decoder来解析特征,得到翻译结果。解析时,解码器不仅要接受编码器的最终输出信息,还要接受上一时刻的翻译结果。而且中英文是两种不同的语义空间,所以中间有一个转换。
而对于BERT,它作为一个预训练模型,最根本的目的是提取语料特征。即利用巨大的未标记文本数据,从中学习语言的良好的表示形式(包含通用语义、语法规则等等的语言模型)。所以BERT的输入是一种语义空间下的文本信息,只需要训练一种语言,只需要使用一种模块,encoder相比decoder更能做到这一点。
(再扯一扯就是decoder比encoder多了一个encoder-decoder-attention层,只是用一个模块的话,这个层就是多余的了。而且decoder还采用了掩码机制,屏蔽未来时刻的信息,对于翻译来说有必要,对于学习language modeling就不合适)
2.从训练机制来说:
transformer是seq2seq结结构,以英译汉来举例。是用decoder来预测输入的英文对应的中文是什么。训练时,是中英文一对对来训练的,相当于有了标注。
而BERT主要任务是从无标注文本中学习language modeling,引入了masked 机制。所以它是一个用上下文去推测中心词[MASK]的任务,和Encoder-Decoder架构无关。所以说,BERT的预训练过程,其实就是将Transformer的Decoder拿掉,仅使用Encoder做特征抽取器,再使用抽取得到的“特征”做Masked language modeling的任务,最终计算Negative Log Likelihood Loss,并在一次次迭代中以此更新参数。(通过建模任务修正参数。)
当然了,BERT不仅仅做了MLM任务,还有Next Sequence Prediction。