5_ARM Cortex-M汇编
文章目录
-
- 汇编语言语法
- 指令后缀使用
- 统一汇编语言UAL
- 指令集
-
- 处理器内传送数据
- 存储器访问指令
-
- 立即数偏移
- PC相关寻址(文本)
- 寄存器偏移(前序)
- 后序
- 多加载和多存储
- 压栈和出栈
- SP相关寻址
- 非特权访问等级下的加载和存储
- 算术运算
- 逻辑运算
- 移位和循环移位指令
- 数据转换运算(展开和反序)
- 位域处理指令
- 比较和测试
- 程序流控制
-
- 跳转
- 函数调用
- 条件跳转
- 比较和跳转
- 条件执行(IF-THEN指令)
- 表格跳转
- 饱和运算
- 异常相关指令
- 休眠模式相关指令
- 存储器屏障指令
- 其他指令
- 不支持的指令
- Cortex-M4特有的指令
-
- Cortex-M4的增强DSP扩展
- SIMD饱和指令
- 乘法和MAC指令
- 打包和解包
- 浮点指令
- 桶形移位器
- 编程中访问特殊寄存器和特殊指令
-
- 简介
- 内在函数
- 内联汇编和嵌入汇编
- 使用其他的编译器相关的特性
- 访问特殊寄存器
汇编语言语法
对于ARM汇编,ARM工具链,指令格式如下:
label
mnemonic operand1,operand2, ... ;注释
标号label表示地址位置,为可选的。有些指令前面可能会有标号,这样可以通过这个标号得到指令的地址。标号也可以用于表示数据地址。例如,可以在程序内的查找表处放一个标号。label后为mnemonic助记符,也就是指令的名字,后面跟着的时多个操作数,;后的内容为注释,可以提高程序的可读性:
- 对于ARM汇编器中编写的数据处理指令,第一个操作数为操作的目的。
- 对于存储器读指令,多次加载指令除外,第一个操作数为数据被加载进去的寄存器。
- 对于存储器写指令,多次存储指令除外,第一个操作数为保存待写入存储器的数据的寄存器。
每条指令的操作数个数由指令的类型决定,有些指令不需要任何操作数,有些可能只需要一个。
注意,助记符后可能存在不同类型的操作数,这样可能会得到不同的指令编码。如MOV(move)指令可以在两个寄存器间传输数据,也可以将立即数放到寄存器中,立即数通常具有前缀"#",如下所示:。
MOVS R0, #0x12 ;设置 R0 = 0x12 (十六进制)
MOVS R1, #’A’ ; 设置 R1 = ASCII 字符 A
对于GNU工具链,汇编语法一般为:
label:
mnemonic operand1,operand2, ... /* 注释 */
操作码和操作数与ARM汇编器是相同的,不过标号和注释的语法不同。对于前面的指令,按照GNU可以写作:
MOVS R0, #0x12 /* 设置 R0 = 0x12 (十六进制) */
MOVS R1, #’A’ /* 设置 R1 = ASCII 字符 A */
gcc中插入注释的另一种方法为使用内联注释字符"@",如下:
MOVS R0, #0x12 @ 设置 R0 = 0x12 (十六进制)
MOVS R1, #’A’ @ 设置 R1 = ASCII 字符 A
汇编代码的一个常见特性为定义常量。通过常量定义,可以时程序代码的可读性及维护性得到提升。对于ARM汇编,定义常量的示例为:
NVIC_IRQ_SETEN EQU 0xE000E100
NVIC_IRQ0_ENABLE EQU 0x1
...
LDR R0,=NVIC_IRQ_SETEN ;将0xE000E100放入R0,这里的LDR为伪指令,被汇编器转换为PC相关的数据加载。
MOVS R1,#NVIC_IRQ_ENABLE ;将立即数0x1放入寄存器R1
STR R1,[R0] ;将0x1存入0xE000E100,使能中断IRQ#0
上面的代码,伪指令LDR将NVIC寄存器的地址加载到寄存器R0中。汇编器会将一个常数值放到程序代码的某个位置,并插入一个将数据值读入R0的存储器读指令。之所以使用伪指令,是因为对于一个传送立即数的指令来说,这个常数值就有点太大了。在使用LDR伪指令将数据加载到寄存器中时,需要对数据增加=前缀,在将立即数加载到寄存器中的一般情况下,如使用MOV,前缀应使用#。
类似的,按照GNU工具链的汇编语法可以实现相同的代码:
.equ NVIC_IRQ_SETEN 0xE000E100
.equ NVIC_IRQ0_ENABLE 0x1
...
LDR R0,=NVIC_IRQ_SETEN /* 将0xE000E100放入R0,这里的LDR为伪指令,被汇编器转换为PC相关的数据加载。*/
MOVS R1,#NVIC_IRQ_ENABLE /* 将立即数0x1放入寄存器R1 */
STR R1,[R0] /* 将0x1存入0xE000E100,使能中断IRQ#0 */
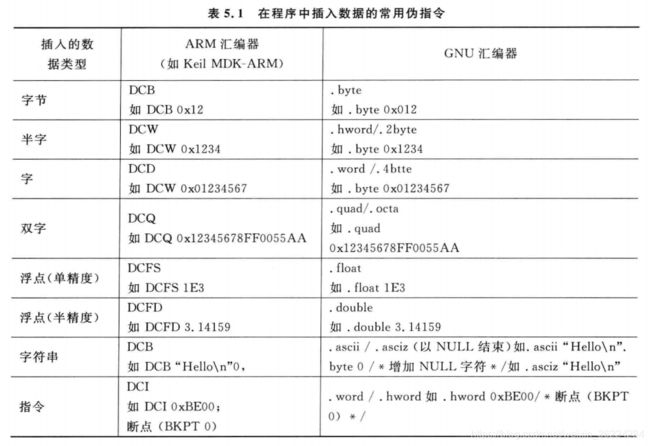
多数汇编工具允许将数据插入程序中,这是另一个典型的特性。例如,可以在程序存储器中的特定位置定义数据,并使用存储器读指令进行访问。ARM汇编器的一个例子为:
LDR R3,=MY_NUMBER ;获取MY_NUMBER的存储器位置
LDR R4,[R3] ;将0x12345678读入R4中
...
LDR R0,=HELLO_TEXT ;获取HELLO_TEXT的起始地址
BL PrintText ;调用PrintText函数显示字符串
...
ALIGN 4
MY_NUMBER DCD 0x12345678
HELLO_TEXT DCB "Hello\n",0
上面的示例中,DCD用于插入字大小的数据,而DCB用于将字节大小的数据插入到程序中。在插入字大小的数据时,前面应增加ALGIN伪指令,ALGIN后的数字决定了对齐的大小,本例中的4将下面的数据强制对齐到字边界上,用于确保MY_NUMBER中的数据是字对齐的,程序可以通过单次总线传输访问该数据,而且提高了代码的可移植性。
还可以按照GNU工具链的汇编语法,写作:
LDR R3,=MY_NUMBER /* 获取MY_NUMBER的存储器位置 */
LDR R4,[R3] /* 将0x12345678读入R4中 */
...
LDR R0,=HELLO_TEXT /* 获取HELLO_TEXT的起始地址 */
BL PrintText /* 调用PrintText函数显示字符串 */
...
ALIGN 4
MY_NUMBER:
.word 0x12345678
HELLO_TEXT:
.asciz "Hello\n"
ARM汇编器和GNU汇编器中的多个不同的伪指令可以将数据插入到程序中,如下表所示:
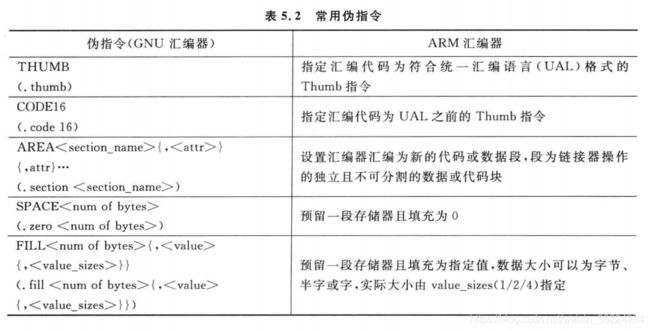
汇编语言编程中还有一些其他有用的伪指令,下班列出来一些ARM汇编伪指令:

指令后缀使用
对于ARM处理器的汇编器,有些指令后跟着后缀,Cortex-M处理器可用的后缀如下表所示:

对于Cortex-M3/M4处理器,数据处理指令可以选择是否更新APSR标志,如果使用统一汇编语言UAL语法,则可以指定是否执行APSR的更新,例如,当将数据从一个寄存器送到另外一个寄存器中时,可以使用:
MOVS R0,R1 ;将R1送到R0,并更新APSR
或
MOV R0,R1 ;将R1送到R0,不更新APSR
第二种后缀用于指令的条件执行,Cortex-M3/M4处理器支持条件跳转,还可以通过将条件指令放到IF-THEN指令块中条件执行指令。利用数据运算及测试TST或比较CMP指令更新APSR后,程序流程可以由运算结果的条件控制。
统一汇编语言UAL
在没有Thumb-2技术时,Thumb指令集可用的特性有限,Thumb指令的语法比较简单。例如对于ARM7TDMI,Thumb模式中几乎所有的数据处理指令都会更新APSR,因此对于Thumb指令来说,S后缀不是必须使用的,即使不使用,也会更新APSR。
在Thumb-2技术出现后,几乎所有的指令都分为2个版本,一个更新APSR,另一个不更新APSR。因此传统的Thumb语法无法适用于Thumb-2的软件开发,为了提高架构间的可移植性,并使不同架构的ARM处理器符合同一种汇编语言语法,较新的ARM开发工具开始支持统一汇编语言UAL,对于之前的汇编来讲,主要区别在于:
- 有些数据运算指令使用三个操作数,不管目的寄存器是否和其中一个源寄存器相同。之前可能只使用两个操作数。
S后缀变得更为明确。过去的汇编,S后缀即使不加,也会更新APSR,对于UAL语法,更新APSR的指令都应具有S后缀,以指明所需的操作,提供不同架构的兼容性。
例如,UAL之前,16为的Thumb代码的ADD指令为:
ADD R0,R1 ;R0 = R0 + R1,更新APSR
按照UAL语法,代码如下:
ADDS R0,R0,R1 ;R0 = R0 + R1,更新APSR
不过多数情况下,指令仍然可以按照UAL之前的风格书写(只有两个操作数),不过S后缀需要更明确:
ADDRS R0,R1 ;R0 = R0 + R1,更新APSR
利用Thumb-2技术中的新指令,有些操作既可以用Thumb指令处理,也可以Thumb-2指令处理。例如,R0 = R0 + 1可以用16位的Thumb指令或32位的Thumb-2指令实现。利用UAL,可以通过后缀指定使用的指令:
ADDS R0,#1 ;默认使用16位Thumb指令,减小代码体积
ADDS.N R0,#1 ;使用16位的 Thumb 指令,N = Narrow
ADDS.W R0,#1 ;使用32位的 Thumb-2 指令,W = wide
.W后缀表示使用32位指令,如果没有指定后缀,则汇编工具一般选择更小的,以获得更优的代码密度。
指令集
Cortex-M3和M4处理器的指令可以按功能分为下面几类:
- 处理器内传送数据
- 存储器访问
- 算术运算
- 逻辑运算
- 移位和循环移位运算
- 转换(展开和反转顺序)运算
- 位域处理指令
- 程序流控制(跳转、条件跳转、条件执行和函数调用)
- 乘累加指令MAC
- 除法指令
- 存储器屏障指令
- 异常相关指令
- 休眠模式相关指令
- 其他指令
另外,Cortex-M4处理器支持增加DSP指令:
- SIMD运算和打包指令
- 快速乘法和MAC指令
- 饱和运算
- 浮点指令(如果浮点单元存在)
处理器内传送数据
微处理器最基本的操作为在处理器内来回传送数据。例如:
- 将数据从一个寄存器送到另一个寄存器。
- 在寄存器和特殊寄存器之间传送数据。
- 将立即数送到寄存器。
对于具有浮点单元的Cortex-M4处理器,还可以:
- 在内核寄存器组中的寄存器和浮点单元寄存器组中的寄存器间传送数据。
- 在浮点寄存器组中的寄存器间传送数据
- 在浮点系统寄存器如FPSCR和内核寄存器间传送数据。
- 将立即数送到浮点寄存器。
下表展示了一些常用的操作:
下表展示了用于具有浮点单元的Cortex-M4处理器的指令:
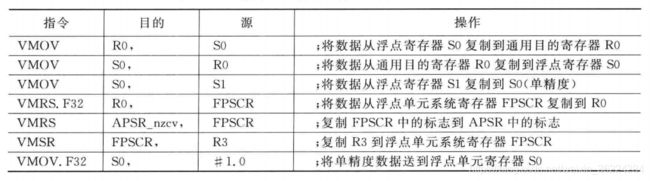
如果将寄存器设置为一个8位的立即数,可以直接使用MOVS指令,而且如果目的寄存器位低寄存器(R0~R7),16位的Thumb指令也可以实现。如果目的寄存器位高寄存器或不需要更新APSR寄存器,则需要使用32位的MOV/MOVS指令。
如果将寄存器设置为一个较大的立即数(9~16位),可以使用MOVW指令。有的汇编工具会自动将9-16位的立即数的MOV或MOVS指令转换为MOVW。
如果要设置寄存器为32位立即数,可以使用下面方式:
最常见的为使用LDR伪指令:
LDR R0,=0x12345678 ;将R0设置为0x12345678
汇编器会将上述指令转换为存储器传输指令及存储在程序映象中的常量:
LDR RO,[PC,#offset]
...
DCD 0x12345678
LDR读取[PC+偏移]处的数据,并存入R0。由于3级流水线结构,PC的值并非LDR指令的地址,这个偏差汇编器会进行计算。
存储器访问指令
由于寻址模式及数据大小和数据传输方向具有多种组合方式,Cortex-M3和M4支持许多存储器访问指令。如下表所示:
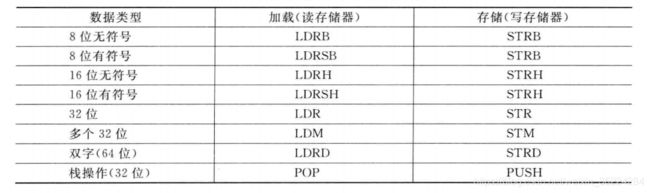
注意:LDRSB和LDRSH会对被加载的数据自动执行有符号展开运算,将其转换为有符号32位数据。
如果浮点单元存在,下表的指令可以用于浮点单元寄存器组和存储器间的数据传送。

立即数偏移
数据传输的存储器地址为寄存器中数据和立即数常量(偏移)的加和,这被称作前序寻址。例如:
LDRB R0,[R1,#0x3] ;从地址R1 + 0x3处读取一个字节并存入R0
偏移值可以是正数或者负数,下表列出了一些常用的加载和存储指令:
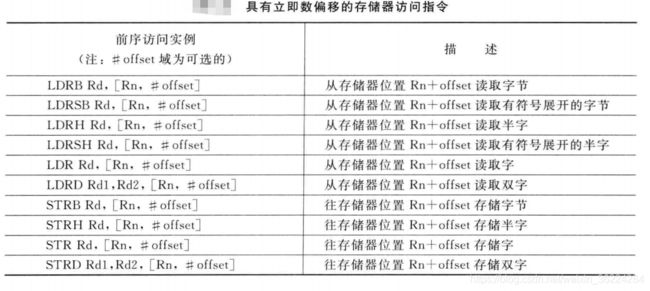
该寻址模式支持对存放地址的寄存器的写回,例如:
LDR R0,[R1,#0x3]! ;在访问存储器地址[R1 + 0x3]以后,R1被更新为R1 + 0x3
指令中的!表示指令完成时是否更新存放地址的寄存器(写回)。不管是否使用!,数据传输的地址都是使用R1 + 0x3的和。下表列出了支持使用写回操作的加载和存储指令:
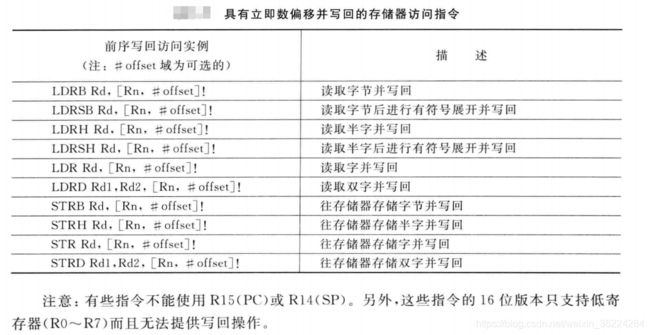
如果浮点单元存在吗,则下表中的指令也可以用于对浮点单元中寄存器执行LDM和STM操作。

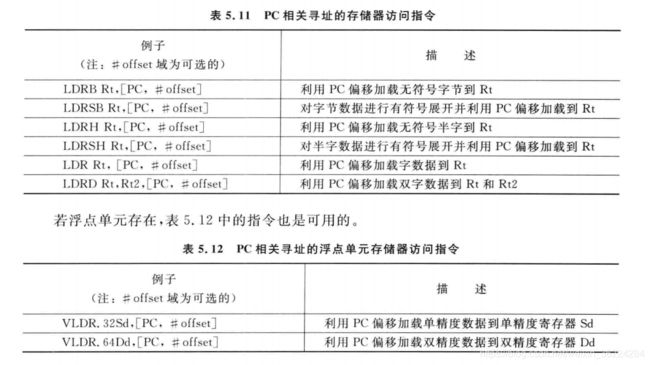
PC相关寻址(文本)
存储器访问可以产生相对于当前PC的地址值和偏移值,常用于将立即数加载到寄存器中,也可以称作文本池访问,如下表所示:
寄存器偏移(前序)
寄存器偏移用于所处理的数据数组的地址为基地址和从索引值计算出的偏移得到情况。为了进一步提高地址计算的效率,在加到基地址寄存器前,索引值可以进行0~3位的移位,这个移位是可选的。如:
LDR R3,[R0,R2,LSL #2] ;将存储器[R0 + (R2 << 2)]读入R3
STR R5,[R0,R7] ;将R5写入存储器[R0 + R7]
与立即数偏移类似,下表展示了不同的使用形式:

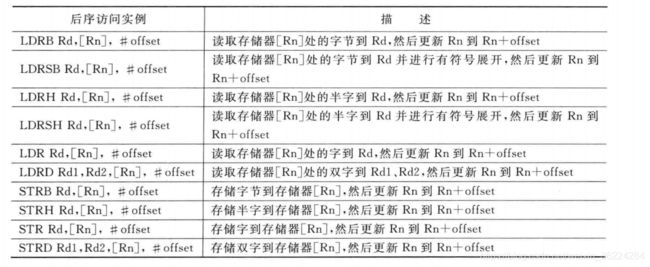
后序
具有立即数寻址模式的存储器访问指令也有一个立即数偏移值。在存储器访问期间不会用到偏移,在数据传输结束后更新地址寄存器,例如:
LDR R0,[R1],#0x1 ;读取存储器[R1]到R0,然后R1 被更新为 R1 + 0x1
使用后序存储器寻址模式,由于数据传输成功后,基地址寄存器总是会得到更新,因此无需使用!,下表列出了后序存储器访问指令的多种形式:
后序寻址模式在处理数组中的数据时很有用,在访问数组中的元素时,地址寄存器可以自动调整,节省代码大小和执行时间。
注意:后序指令不能用R15或R14,后序存储器访问指令都是32位的,偏移数值可以是正数或负数。
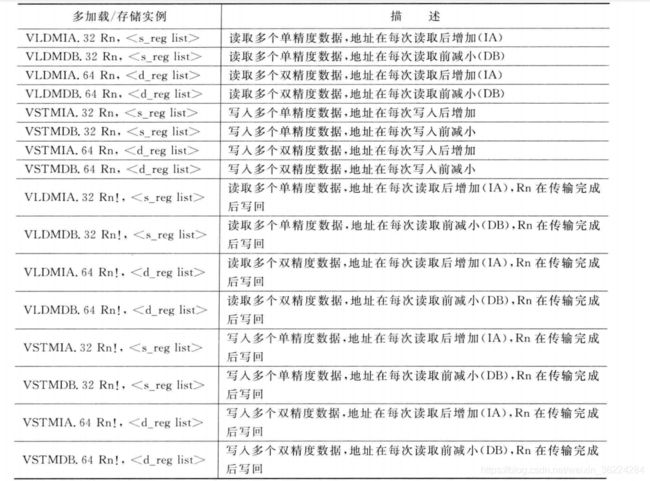
多加载和多存储
ARM架构的一个重要优势在于,可以读写存储器中多个连续数据,LDM(加载多个寄存器)和STM(存储多个寄存器)指令只支持32位数据,支持两种前序:
- IA : 在每次读/写后增加地址
- DB :在每次读/写后减小地址
LDM和STM指令在使用时可以不进行基地址写回,如下表所示:

上表中,
- 开始为
{,结束为}。 - 使用
-表示范围,如R0-R4表示R0、R1、R2、R3以及R4。 - 使用
,隔开每个寄存器。
例如,下面的指令读取地址 0x20000000~0x2000000F的内容到R0 ~ R3:
LDR R4,=0x20000000 ;将R4设置为0x20000000地址
LDMIA R4,{R0-R3} ;读取4个字并存入R0-R3
寄存器列表可以是不连续的,如{R1,R3,R5-R7,R9,R11-R12}。
与其他的加载/存储指令类似,STM和LDM中可以使用写回,例如:
LDR R8,=0x8000 ;R8设置为0x8000
STMIA R8!,{R0-R3} ;存储后R8变为0x8010
LDM和STM指令的16位版本只能使用低急促请你,而且若基地址寄存器为被存储器读更新的目的寄存器之一,则其总是具有写回使能,具有写回的多加载/存储存储器访问指令如下表:

如果浮点单元存在,则下表中的指令也可以用来执行浮点单元中寄存器的多加载/存储操作。
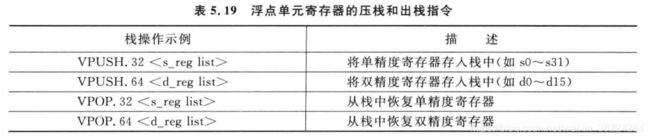
压栈和出栈
栈的PUSH和POP为另一种形式的多存储和多加载,他们利用当前栈指针来生成地址。当前栈指针可以是主栈指针MSP,也可以是进程栈指针PSP,实际选择由处理器的当前模式和CONTROL特殊寄存器的数据决定。压栈和出栈的指令如下表:

寄存器列表的语法和LDM和STM相同:
PUSH {R0,R4-R7,R9} ;将R0,R4,R5,R6,R7,R9压入栈
POP {R2,R3} ;将栈中的内容放入R2,R3中
对于PUSH指令,通常有一个对应的具有相同寄存器列表的POP指令,不过不是必须的。例如异常中就有使用POP作为函数返回的情况:
PUSH {R4-R6,LR} ;子程序开始处保存R4-R6和LR,LR中包含返回地址。
...
POP {R4-R6,PC} ;从栈中恢复R4-R6和返回地址,返回地址直接存入PC,这样会触发跳转(子程序返回)
除了将返回地址恢复到LR然后写入到PC外,可以将返回地址直接写入PC以减少指令数和周期数。
16位的PUSH和POP只能使用低寄存器(R0-R7)、LR(用于PUSH)和PC(用于POP),因此如果函数中某个高寄存器被修改时要保存寄存器的内容,需要使用32位的PUSH和POP指令。
如果浮点单元存在,下表的指令可以用于执行对浮点单元中寄存器的栈操作:
与PUSH和POP不同,VPUSH和VPOP指令需要:
- 寄存器列表中寄存器是连续的。
- 每次VPUSH和VPOP的寄存器的最大数量位16。
如果需要保存超过16个的单精度浮点寄存器,可以使用双精度指令或者使用两组VPUSH或VPOP。
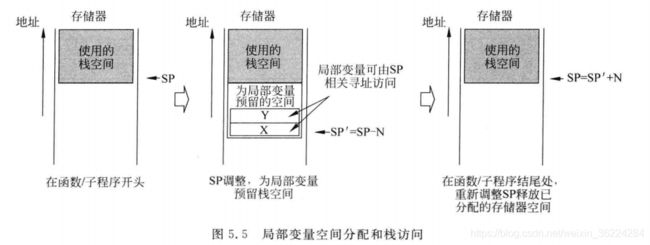
SP相关寻址
除了用于函数或子程序的寄存器临时存储,栈空间还用于局部变量,访问这些变量需要SP相关的寻址,不过多数16位的Thumb指令只能使用低寄存器,因此SP相关的寻址有一对专用的16位LDR和STR指令。
使用SP相关的寻址的示例见下图:在函数开始处,为了给局部变量预留出空间,SP数值减小,这些局部变量可以用SP相关的寻址模式进行访问,在函数结束时,SP增大且恢复为初始值,这样在返回到调用的代码前会将已分配的栈空间释放。
非特权访问等级下的加载和存储
利用一组加载存储指令,处于特权访问等级的程序代码可以访问非特权访问权限的存储器,如下表所示:
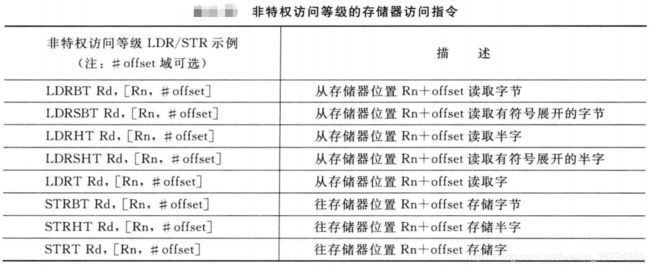
有些OS环境可能会用到这些指令,非特权的应用程序可以访问以数据指针作为输入参数的API函数(运行在特权访问等级),而API的操作的寄存器数据由指针决定。如果数据访问由普通的加载和存储指令完成,非特权任务可以利用这些API修改被其他任务或OS内核使用的数据,而将这些API编码为非特权访问等级的特殊的加载和存储指令后,他们只能访问应用任务可以访问的数据。
算术运算
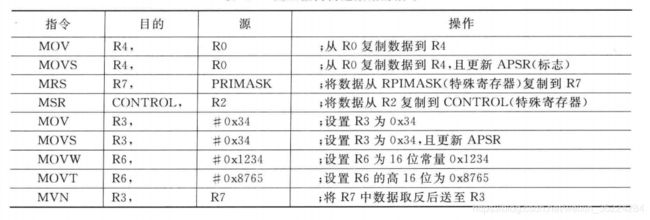
Cortex-M3和M4处理器提供了用于算术运算的多个指令,这里只介绍一些基本运算指令。数据处理指令可以有多种形式,如ADD指令可以操作两个寄存器或者一个寄存器一个立即数:
ADD R0,R0,R1 ;R0 = R0 + R1
ADDS R0,R0,#0x12 ;R0 = R0 + 0x12 APSR标志更新
ADC R0,R1,R2 ;R0 = R1 + R2 + 进位
按照传统的Thumb语法(UAL之前),在使用16位的Thumb代码时,ADD指令会修改PSR中的标志。不过32位的Thumb-2指令可以修改这些标志也可以不修改,为了区分这种操作,根据统一汇编语言UAL语法,如果后面的操作需要标志,则应使用S后缀:
ADD R0,R1,R2 ;标志未变
ADDS R0,R1,R2 ;标志改变
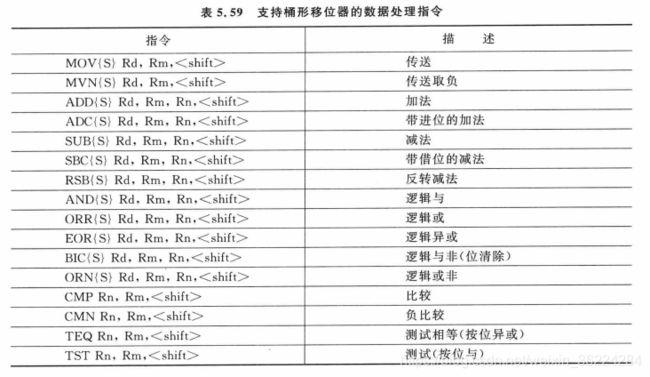
除了ADD指令,Cortex-M3的算术功能还包括SUB(减法)、MUL(乘法)、UDIV/SDIV(无符号和有符号除法),如下表所示:
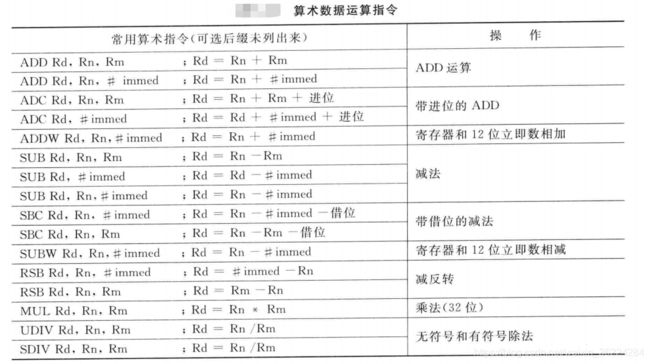
这些指令都可以使用S后缀以指明APSR进行更新。
若出现被零除的情况,UDIV和SDIV指令的结果默认为0。可以设置NVIC配置控制寄存器中的DIVBYZERO位,这样在被零除的时候可以产生异常(使用错误)。
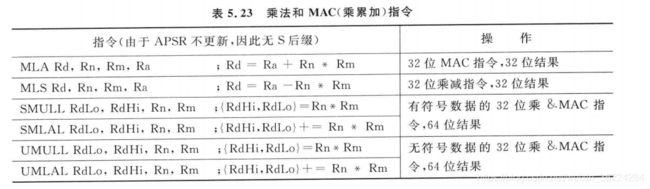
Cortex-M3和M4处理器都支持具有32位和64位结果的32位乘法指令和乘累加(MAC)指令。这些指令支持有符号和无符号的形式,APSR标志不受这些指令的影响:
逻辑运算
Cortex-M3和M4处理器支持多种逻辑运算指令,如AND、OR以及异或等。与算术指令类似,这些指令的16位版本会更新APSR,如果未指定S后缀,汇编器会将他们转换位32位指令。
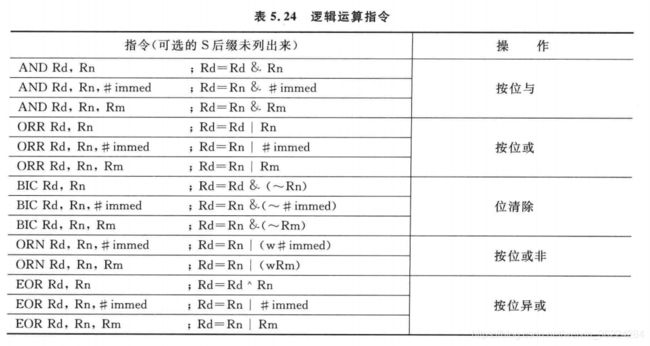
如果使用这些指令的16位版本,则只能操作两个寄存器,且目的寄存器需要为源寄存器之一,另外,还必须是低寄存器R0-R7,而且要使用S后缀进行APSR更新。ORN指令没有16位的形式。
移位和循环移位指令
Cortex-M3和M4处理器支持多种移位和循环移位指令,如下表:

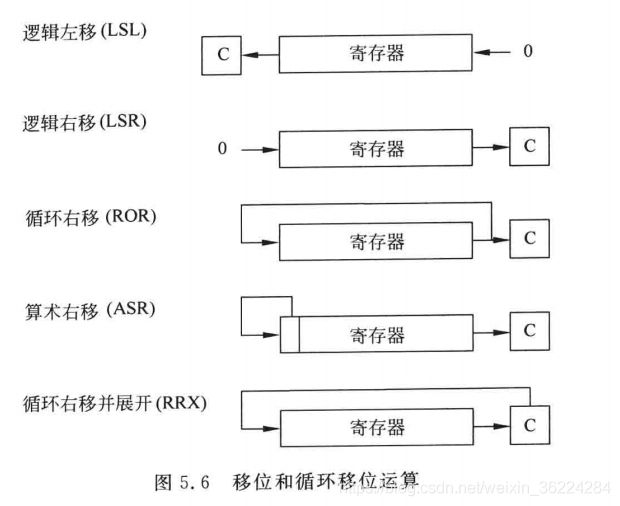
如果使用S后缀,这些循环和移位指令会更新APSR中的进位标志。如果移位运算移动了寄存器中的多个位,进位标志C的数据会为移出寄存器的最后一位。至于只由循环右移没有循环左移,这是因为循环左移可以由循环右移一定数量进行代替。
要使用这些指令的16位版本,寄存器需要为低寄存器,且使用S后缀更新APSR,RRX没有16位版本。
数据转换运算(展开和反序)
Cortex-M3和M4处理器用于处理数据的有符号和无符号展开的指令有很多,如将8位数转换为32位或将16位转换为32位。有符号和无符号指令都由16位和32位的形式,这些指令的16位版本只能访问低寄存器,如下表:
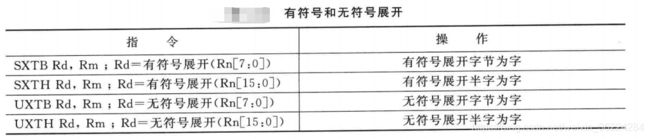
这些指令的32位形式可以访问高寄存器,而且可以选择再进行有符号展开前将输入数据循环右移:

SXTB/SXTH使用Rn的bit[7]/bit[15]进行有符号展开,而UXTB/UXTH则将数据以零展开的方式扩展位32位。
例如,若R0为0x55AA8765:
SXTB R1,R0 ;R1 = 0x00000065,因为bit7为0,所以为正数
SXTH R1,R0 ;R1 = 0xFFFF8765,因为bit15为1,所以为负数
UXTB R1,R0 ;R1 = 0x00000065,无符号展开,不判断正负
UXTH R1,R0 ;R1 = 0x00008765,无符号展开,不判断正负
这些指令可以用于不同的数据类型间的转换,在从存储器中加载数据时,可能同时产生有符号展开和无符号展开,如LDRB用于无符号数据,LDRSB用于有符号数据。
另外一组数据转换运算则用于反转寄存器中的字节,通常用于大端和小端的数据转换,如下图所示:
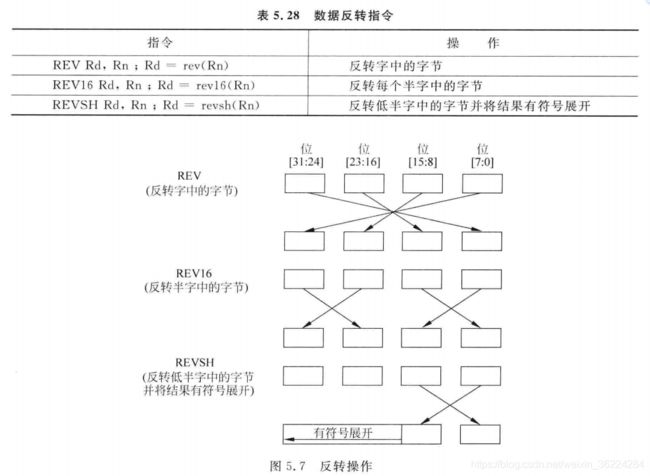
这些指令的16位版本只能访问低寄存器(R0-R7)。
REV反转字数据中字节顺序,而REVH反转半字中的字节顺序。例如若R0为0x12345678,则执行下面指令后:
REV R1,R0 ;R1 = 0x78563412
REVH R2,R0 ;R2 = 0x34127856
REVSH和REVH类似,只是它们只能处理低半字后将结果有符号展开。例如,若R0为 0x33448899,则:
REVSH R1,R0 ;R1 = 0xFFFF9988,因为bit15为1,所以为负数
位域处理指令
为了使Cortex-M3和M4处理器架构适合控制类的应用,它们支持多种位域处理运算,如下表:
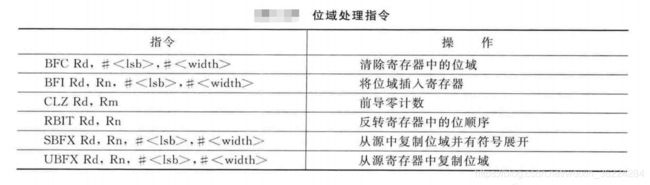
BFC清除寄存器任意相邻的1-31位,语法为:
BFC <Rd>,<#lsb>,<#width>
例如:
LDR R0,=0x1234FFFF
BFC R0,#4,#8 ;R0 = 0x1234F00F
BFI将一个寄存器的1-31位复制到另一个寄存器的任意位置,语法为:
BFI <Rd>,<Rn>,<#lsb>,<#width>
例如:
LDR R0,=0x12345678
LDR R1,=0x3355AACC
BFI R1,R0,#8,#16 ;将R0[15:0]插入到R1[23:8],R1 = 0x335678CC
CLZ计算前导零的个数,如果没有位位1,则结果位32,如果所有位都为1,则结果为0。通常用于在对数据进行标准化处理时确定移位的个数,以便将第一个1移到第31位,在浮点运算中经常用到。
RBIT用于反转字数据中位顺序,语法为:
RBIT <Rd>,<Rn>
这个指令通常在数据通信中用于串行位数据流的处理,例如若R0=0xB4E10C23,二进制1011 0100 1110 0001 0000 1100 0010 0011,执行:
RBIT R0,R1 ;R1 = 0xC430872D, 1100 0100 0011 0000 1000 0111 0010 1101
UBFX和SBFX为无符号和有符号位域提取指令,语法为:
UBFX <Rd>,<Rn>,<#lsb>,<#width>
SBFX <Rd>,<Rn>,<#lsb>,<#width>
UBFX从寄存器中的任意位置<#lsb>开始提取任意宽度<#width>的位域,将其零展开后放入目的寄存器,如:
LDR R0,=0x5678ABCD
UBFX R1,R0,#4,#8 ;R1 = 0x000000BC
类似的,SBFX提取出位域,不过会在放入目的寄存器前进行有符号展开,例如:
LDR R0,=0x5678ABCD
SBFX R1,R0,#4,#8 ;R1 = 0xFFFFFFBC,bit7为1,为负数
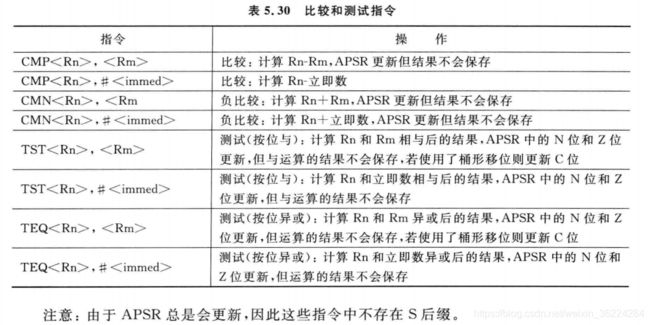
比较和测试
比较和测试指令用于更新APSR中的标志,这些标志随后可能会用于条件跳转或条件执行,如下表:
程序流控制
用于程序流控制的指令有多种:
- 跳转
- 函数调用
- 条件跳转
- 比较和条件跳转的组合
- 条件执行(IF-THEN指令)
- 表格跳转
跳转
多个指令可以引发跳转操作:
- 跳转指令,如
B、BX - 更新R15(PC)的数据处理指令,如
MOV、ADD - 写入R15(PC)的读寄存器指令(如LDR、LDM、POP)
尽管可以使用多种操作来实现跳转,比较常用的还是B跳转、BX间接跳转、POP函数返回。下表为基本的跳转指令:

函数调用
调用函数,可以使用链接跳转BL或者带链接的间接跳转BLX指令,它们执行跳转并同时将返回地址保存到链接寄存器LR,这样在函数结束后,还可以跳回之前的程序,如下图所示:

执行这些指令时:
- 程序计数器PC被设置为跳转目标地址
- 链接寄存器LR被更新为返回地址,这也是已执行的BL/BLX后指令的地址。
- 若指令为BLX,则EPSR中Thumb位也会被更新为存放跳转目标地址的寄存器的最低位。
由于Cortex-M3和M4只支持Thumb状态,BLX操作中使用的寄存器的最低位必须设置为1,不然会试图切换到ARM状态,引发错误异常。
BL指令会破坏LR寄存器的当前内容,如果程序代码稍后需要使用LR寄存器,则在执行BL前需要保存LR,最常使用的方法为在程序开头处将LR压入栈中,例如:
main
```
BL functionA
```
functionA
PUSH {LR}
```
BL functionB
```
POP {PC}
functionB
PUSH {LR}
...
POP {PC}
另外,如果调用的子程序为C函数,根据ATPCS规则,R0-R3(用作传入参数和返回值)和R12会被用到,需要将他们保存到栈中。
条件跳转
条件跳转基于APSR的当前值条件执行,N、Z、C、V标志,见下表:

APSR受下面情况影响:
- 多数16位数据处理指令
- 带有S后缀的32位(Thumb-2)数据处理指令
- 比较(如CMP)和测试(如TST、TEQ)
- 直接写APSR/xPSR
bit[27]为另外一个标志,也就是Q标志,用于饱和算术运算而非条件跳转。
条件跳转发生时所需的条件由后缀

可能的条件后缀如下:

例如,考虑下面的操作,图中的程序流可以用条件跳转和简单的跳转指令实现:
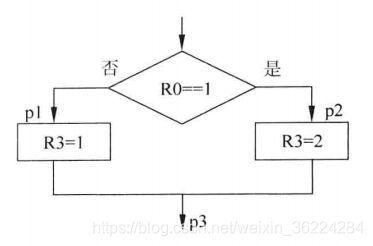
CMP R0,#1 ;比较R0和1
BEQ p2 ;如果相等,跳转到p2
MOV R3,#1 ;执行R3=1
B p3 ;跳转到p3
p2 ;标号p2
MOV R3 #2
p3 ;标号p3
...
比较和跳转
ARMv7-M架构提供了两个新的指令,合并了零比较以及条件跳转操作,指令为:比较为0则跳转CBZ和比较非零则跳转CBNZ,它们只支持前向跳转,不支持后向跳转。
CBZ和CBNZ常用于while等循环结构,例如:
i=5;
while(i!=0)
{
func1();
i--;
}
编译以后可以为:
loop1
MOV R0,#5
CBZ R0,loop1exit ;比较为0的话,跳转到loop1exit,也就是退出循环
BL func1; ;调用函数
SUBS R0,#1 ;i = i-1
B loop1
loop1exit
CBNZ的用法和CBZ类似,只是在不为零的情况下才会跳转。
条件执行(IF-THEN指令)
除了条件跳转,Cortex-M3和M4还支持条件执行,在IT指令执行后,接下来最多4个指令可以根据IT指令指定的条件以及APSR数值条件执行。
IT指令块中包含1个指明条件执行细节的IT指令,后面1-4个条件执行指令。条件执行指令可以为数据处理指令或存储器访问指令,IT块的最后一个条件执行指令也可以是条件跳转指令。
IT指令语句中包含IT指令操作码并附加最多3个可选后缀T(then)以及E(else),后面是要检查的条件,与条件跳转中的条件符号一样。T/E表明IT指令块接下来还有几条指令,以及在符合条件时它们是否应该执行。
如下图:
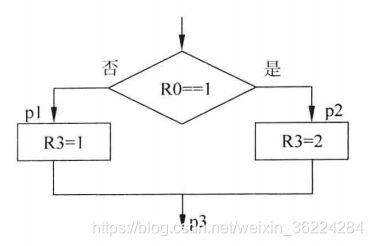
使用IT指令可以为:
CMP R0,#1
ITE EQ ;如果EQ置位,也就是R0 = 1时,执行下一条指令
MOVEQ R3,#2
MOVNE R3,#1 ;如果EQ不置位,也就是R0 !=1,则执行R3=1
注意,当使用E后缀时,IT指令块中指令对应的执行条件必须与IT指令指定的条件相反。
T和E具有不同的组合序列:
- 只有一个条件执行指令:IT
- 两个条件执行指令:
ITT、ITE - 三个条件执行指令:
ITTT、ITTE、ITET、ITEE - 四个条件执行指令:
ITTTT、ITTTE、ITTET、ITTEE、ITETT、ITETE、ITEET、ITEEE
下表列出来IT指令块序列的多种形式和示例,其中:
- 指定第二个指令的执行条件
- 指定第三个指令的执行条件
- 指定第四个指令的执行条件

若
在有些汇编工具中,可以简单的给指令添加条件后缀,编译工具会自动在前面添加IT指令。
例如:

IT指令块中的数据处理指令不应修改APSR的数值,当有些16位的数据处理指令在IT指令块中使用时,APSR不会更新,这一点和正常操作更新APSR的情况不同,这样就可以在IT指令块中使用16位数据处理指令以降低代码大小。由于可以避免跳转开销以及降低跳转指令的个数,IT指令可以显著提高程序代码的性能,例如,一个IF-THEN-ELSE的程序流程通常需要一个条件跳转和无条件跳转,而用IT指令一个就可以代替了。
表格跳转
Cortex-M3和M4支持两个表格跳转指令:TBB字节表格跳转、TBH半字表格跳转。它们总是和跳转表一起使用,通常用于实现C代码中的switch语句。由于程序计数器的值第0位总是0,利用表格跳转指令的跳转表也就无需保存着一位,因此在目标地址计算中跳转偏移被乘以2。
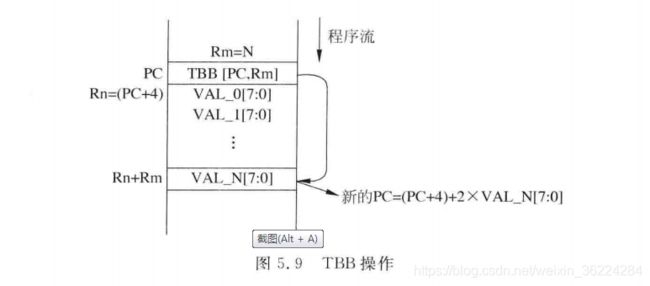
TBB用于跳转表的所有入口被组织成字节数组的形式(相对于基地址的偏移小于2x2^8,512字节),当所有的入口为半字数组时(相对于基地址的偏移小于 2x 2 ^16,128KB),则使用TBH。基地址可以是当前程序计数器PC或者另一个寄存器中的数值,由于三级流水线特性,当前PC值位TBB/TBH指令的地址加4,这个在跳转的时候必须要考虑到。TBB和TBH都只支持前向跳转。
TBB指令语法为:
TBB [Rn,Rm]
其中,Rn中存放跳转表的基地址,Rm则为跳转表偏移。TBB偏移计算用的立即数位域存储器地址[Rn+Rm]。若R15用作Rn,则可以看到下图的操作:
TBH指令的情况是类似的,只是跳转表中的每个入口都是双字节大小,因此数组的索引不同,且偏移范围较大。为了表示索引的差异,TBH语法稍微不同:
TBH [Rn,Rm,LSL #1]
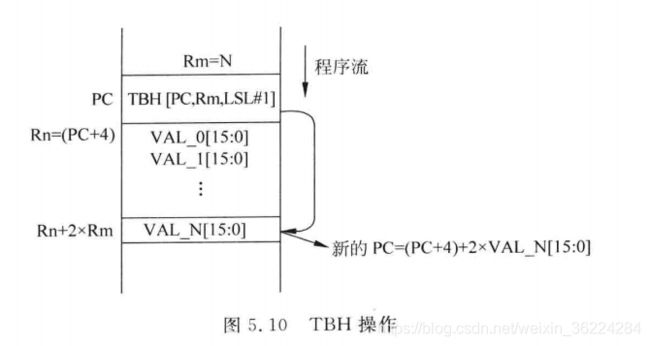
TBH和TBB指令被C编译器用于switch case语句,而在汇编编程时直接使用这两条指令就没有那么容易了,因为跳转表中的数值和当前程序计数器数值相关。若跳转目标地址未在同一个汇编程序文件中,汇编阶段无法确定地址偏移数值。
对于ARM汇编器armasm,可以通过下面的方式实现TBB跳转表:
TBB [PC,R0] ;由于TBB指令为32位,执行这条指令时,PC等于branchtable
bracnchtable ;跳转表起始
DCB ((dest0ebranchtable)/2) ;由于数据为8位,使用DCB
DCB ((dest1ebranchtable)/2) ;由于数据为8位,使用DCB
DCB ((dest2ebranchtable)/2) ;由于数据为8位,使用DCB
DCB ((dest3ebranchtable)/2) ;由于数据为8位,使用DCB
dest0
... ;若R0=0,则执行
dest1
... ;若R0=1,则执行
dest2
... ;若R0=2,则执行
dest3
... ;若R0=3,则执行
对于上面的例子,当TBB执行时,由于流水线结构,当前PC值为TBB指令的地址加4,而且由于TBB指令为4字节大小,因此也就和branchtable相同。
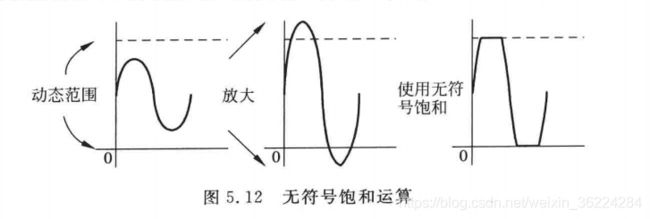
饱和运算
Cortex-M3处理器支持两个用于有符号和无符号数据饱和运算的指令:SSAT用于有符号数据和USAT用于无符号数据。Cortex-M4除了这两条指令外,还支持其他的用于饱和算法的指令。
饱和多用于信号处理,比如在放大处理等操作后,信号的幅度可能会超出允许的输出范围,如果只是将数据的最高位去掉,则会导致波形产生严重的变形,如下图:
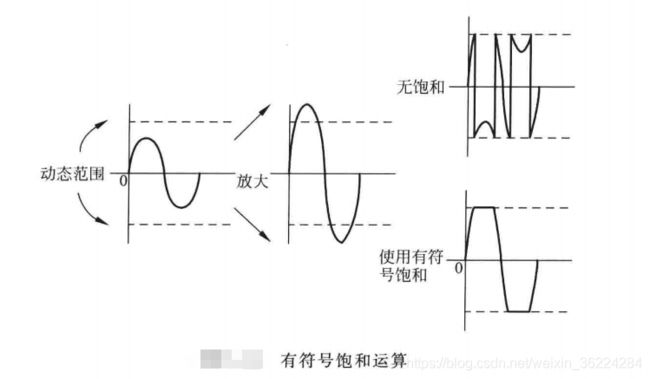
饱和运算通过将数据强制置为最大允许值,减小了数据畸变。畸变仍然是存在的,不过若数据没有超过最大范围太多,则不会有太大问题。SSAT和USAT指令语法如下:
SSAT <Rd>,#<immed>,<Rn>,{,<shift>} ;有符号数据的饱和
USAT <Rd>,#<immed>,<Rn>,{,<shift>} ;无符号数据的饱和
其中,#LSL N或者#ASR N,
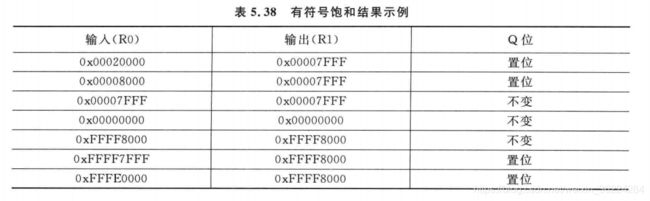
除了目的寄存器,APSR中的Q位也会受结果的影响。若在运算中出现饱和Q标志就会被置位,可以通过写APSR进行清除。例如,若一个32位有符号数值要被饱和为16位有符号数,可以使用下面的指令:
SSAT R1,#16,R0
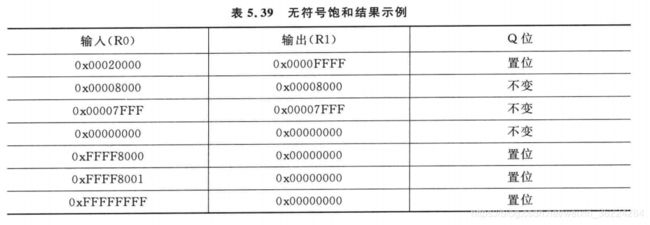
下表列出来SSAT运算结果的几个例子:
USAT稍微有些不同,它的结果为无符号数据,起包和运算的情况如下图:
可以利用下面代码将32位的有符号数转换为16位无符号数:
USAT R1,#16,R0
下表列出了USAT的结果示例:
异常相关指令
管理调用指令SVC用于产生SVC异常,异常类型为11。SVC一般用于嵌入式OS中,运行在非特权执行状态的应用可以请求运行在特权状态的OS的服务。SVC异常机制提供了从非特权到特权的转换。
SVC机制也可以用作应用任务访问各种服务,包括OS服务或者其他API函数的入口,这样应用任务就可以在无需了解服务的实际存储器地址的情况下请求所需服务。它只需要直到SVC服务编号、输入参数和返回结果。
SVC指令要求SVC异常的优先级高于当前的优先级,而且异常没有被PRIMASK等寄存器屏蔽,不然会触发错误异常。因此由于NMI和HardFault异常的优先级总是比SVC优先级高,也就无法在这两个处理中使用SVC。
SVC语法如下:
SVC #<immed>
其中的立即数为8位,数值自身不会影响SVC异常的动作,不过SVC处理可以在程序中提取出这个数值并作为输入参数,这样可以确定应用任务请求的服务。
按照传统的汇编语法,SVC指令用的立即数可以不用加#,不过还是建议使用#。
另一个和异常相关的指令为改变处理器状态CPS指令。对于Cortex-M处理器,可以使用这条指令来设置或清除PRIMASK和FAULTMASK等中断屏蔽寄存器。注意,这些寄存器也可以使用MSR和MRS指令访问。
CPS指令在使用时必须带一个后缀:IE(中断使能)或ID(中断禁止)。由于Cortex-M3和M4处理器具有多个中断屏蔽寄存器,因此还需要指定设置/清除的寄存器。下表列出了CPS指令的多种形式:

休眠模式相关指令
进入休眠模式主要使用两条指令:
- 等待中断进入休眠,中断、复位或调试操作可以将处理器唤醒, 汇编指令为
WFI,或者CMSIS驱动库的__WFI(); - 等待事件进入休眠, 中断、复位、调试操作或外部事件输入的脉冲信号可以将处理器唤醒。汇编指令为
WFE,或者CMSIS驱动库的__WFE();
处理器的接口信号包括一个事件输入或一个事件输出。处理器的事件输入可以由多处理器系统中其他处理器的事件输出产生,因此WFE休眠的处理器可以由其他的处理器唤醒,有些情况下,这些信号会被连接到Cortex-M微控制器的IO端口,而其他一些微控制器的事件输入可能会被链接到低电平,而事件输出则可能用不上。
事件输出可以由SEV(发送事件)指令触发,也可以使用CMSIS库的__SEV()接口触发。执行SEV时,事件输出接口就会出现一个单周期的脉冲,SEV指令还会设置同一处理器的事件寄存器。
存储器屏障指令
对于ARM架构,在不影响数据处理结果的情况下,存储器传输的顺序和程序代码是可以不同的,这种情况对于具有乱序执行能力的高端处理器是很常见的。不过在对存储器访问重新排序后,若数据在多个处理器间共用,则另一个处理器看到的数据顺序可能和设定的不同,导致出现错误。
存储器屏障指令用于:
- 确保存储器访问的顺序
- 确保存储器访问和另一处理器操作间的顺序。
- 确保系统配置放生在后序操作之前。
Cortex-M处理器支持三种存储器屏障指令,如下图所示:

对于CMSIS驱动的变成,可以使用下面的函数来实现:
void _DMB(void); //数据存储器屏障
void _DSB(void); //数据同步器屏障
void _ISB(void); //指令同步屏障
由于Cortex-M处理器具有流水线,而且AHB Lite总线不允许对存储器系统中的传输进行重新排序,因此即使没有这些存储器屏障指令,多数应用也是可以正常工作的,不过下面情况下应该使用屏障指令,如下图:

从架构的角度来看,某些情况下,两次操作间需要使用存储器屏障,但是不使用也不会有什么问题,如下图所示:

其他指令
NOP 用于产生指令对齐或延时,空指令,什么也不做。
NOP //汇编指令
_NOP(); //CMSIS函数指令
BKPT断点指令用于实现应用程序中的软件断点。若程序在SRAM中执行,则该指令一般由调试器插入以替换原有的指令。当到达断点处,处理器会被暂停,然后调试器会恢复原有的指令,用户也可以通过调试器执行调试任务。BKPT指令也可以用于产生调试监控异常,它具有一个8位的立即数,调试器或者调试监控异常可以将该数据提取出来,根据其信息确定要执行的动作。
BKPT语法为:
BKPT #<immed> //汇编断点,可以不使用#
BKPT <immed>
_BKPT(immed); //C语言函数
除了BKPT,Cortex-M3和M4还存在一个断点单元,它具有最多8个硬件断电,而且不用覆盖原有的程序映像。
不支持的指令
整个Thumb的指令集,包括Thumb-2技术的32位指令,在设计上是面向多种处理器硬件的,其中一些指令无法用于Cortex-M处理器上,如下表所示:

有些修改处理器状态 CPS指令也是不支持的,这是因为Cortex-M处理器的程序状态寄存器PSR的定义和传统的ARM或Cortex-A/R处理器不同,如下表所示:

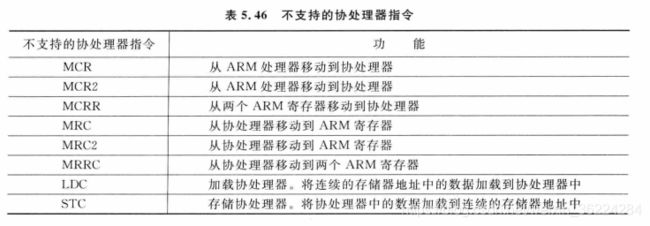
有些ARMv7-M架构中定义的一些指令,Cortex-M3和M4处理器设计中也是不支持的,因为Cortex-M3和M4处理器都不支持协处理器,因此在执行下表中的协处理器指令时会导致错误异常:
Thumb还定义了多个提示指令,在Cortex-M3和M4处理器中执行效果和NOP一样,如下表:

执行其他未定义的指令时,都会产生错误异常。
Cortex-M4特有的指令
Cortex-M4的增强DSP扩展
与Cortex-M3相比,Cortex-M4支持的指令更多,包括:
- 单指令多数据SIMD
- 饱和指令
- 其他的乘法和MAC乘累加指令
- 打包和解包指令
- 可选的浮点指令,若浮点单元存在
有了这些指令,Cortex-M4可以进行更高效的实时数字信号处理。
一般来说,需要处理的数字信号多为16位或者8位,如ADC采集的音频信号,一般位16位或者更低,而图像像素数据通常由多个8位数据表示。由于处理器内部的数据通常是32位的,因此可以处理2x16或4x8位的数据,还需要考虑数据有符号或者无符号,因此1个32位的寄存器可以用作4中类型的SIMD数据,多数情况下,SIMD数据集合中的数据类型通常都是一样的,不存在有符号和无符号的混用,这样可以简化SIMD指令集的设计,如下图:
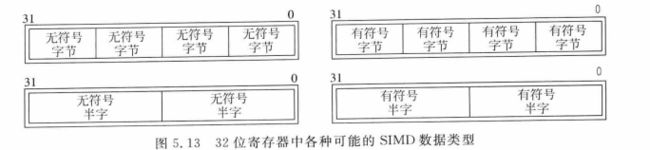
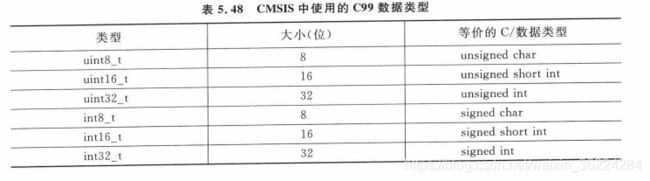
为了处理SIMD数据,Cortex-M架构增加了额外的指令,被称作增强的DSP扩展, 架构则叫做ARMv7E-M,和ARM9E一致。由于SIMD的数据类型非C的标准类型,C编译器一般无法用普通的C代码生成所需的DSP指令,因此提供了CMSIS-DSP库,可以由软件开发人员免费使用。CMSIS-DSP中使用了下图中的C99数据类型:
SIMD饱和指令
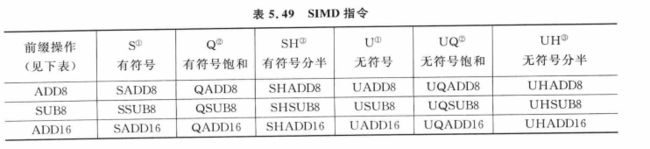
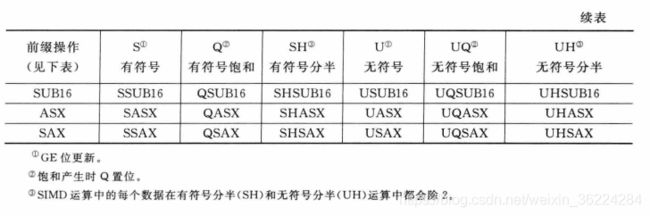
SIMD和饱和指令非常多,有些饱和指令支持SIMD,使用不同的前缀表示指令用于有符号数还是无符号数,如下表所示:
基本的运算如下表所示:

另外还有一些SIMD指令,如下表所示:

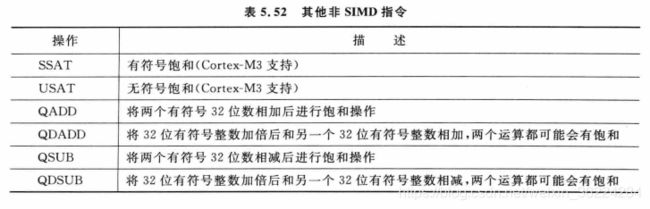
有些饱和指令不支持SIMD,如下表所示:
这些指令的语法如下表:
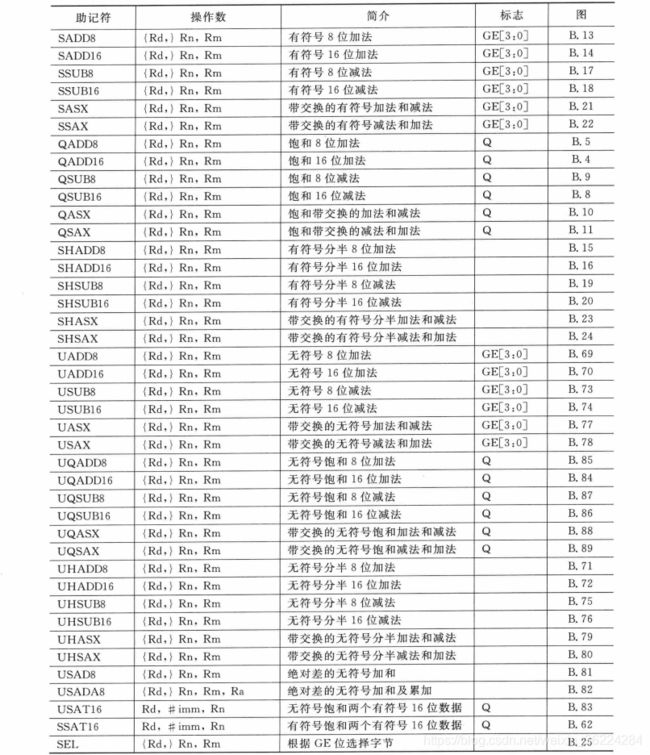

注意:有些指令在产生饱和时会设置Q位,不过这些指令不会清除Q位,必须手动写入APSR才能将其清楚,程序代码一般需要检查APSR中的Q位,以确定在计算过程中是否产生了饱和,因此,如果没有显式指明,Q位是不会被清除的。
乘法和MAC指令
Cortex-M3和Cortex-M4都支持的乘法和MAC指令如下表:
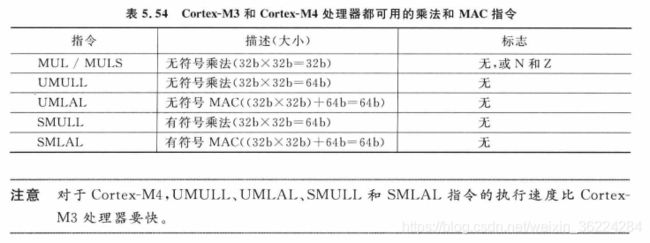
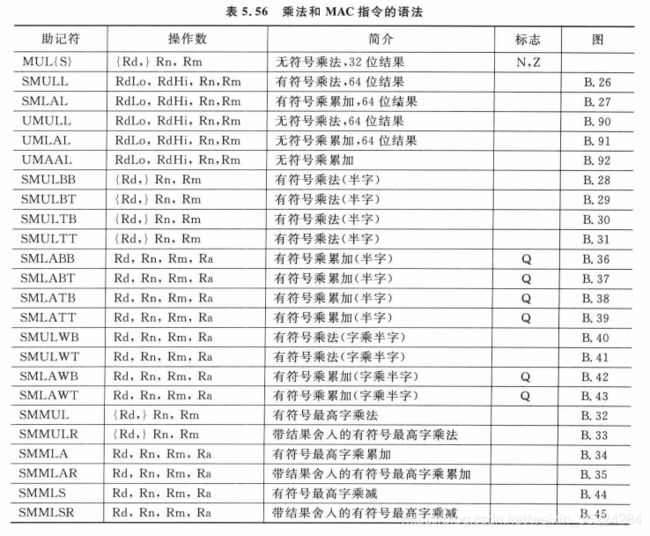
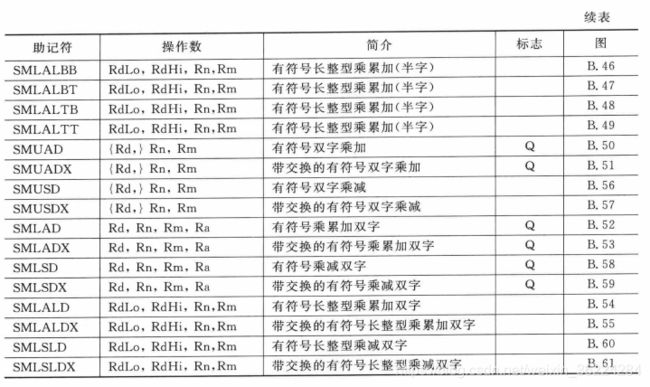
Cortex-M4还支持其他的乘法和MAC指令,有些还具有多种形式,可以选择输入参数的低半字和高半字,如下表所示:



注意:有些指令在产生有符号溢出时会将Q置位,不过这些指令不会清除Q位,必须手动写入APSR才能将其清楚,程序代码一般需要检查APSR中的Q位,以确定在计算过程中是否产生了饱和,因此,如果没有显式指明,Q位是不会被清除的。这些指令的语发如下表所示:
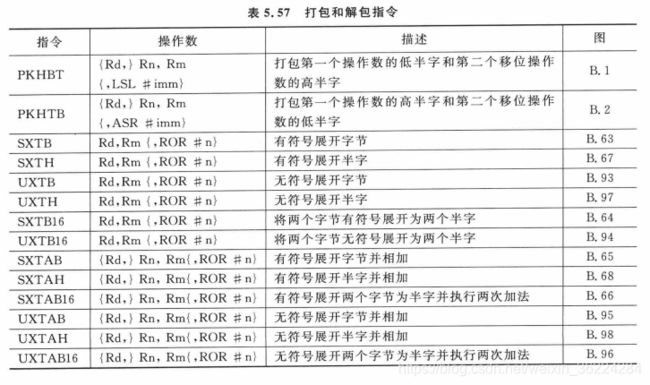
打包和解包
为了便于SIMD数据的打包和解包,处理器中还存在多个相关指令,其中有些指令支持第二个操作数的桶形移位或者循环移位,移位或循环移位是可选的,如下表所示,其中用于循环移位ROR的n可以是8、16或者24,PKHBT和PKHTB可以进行任意数量的移位:
浮点指令
为了支持浮点运算,Cortex-M4还具有多个用于浮点数据处理和浮点数据传输的指令,如表5.58所示。若所使用的Cortex-M4设备中不存在浮点单元,则这些指令也是不可用的,浮点指令以字母V开头:
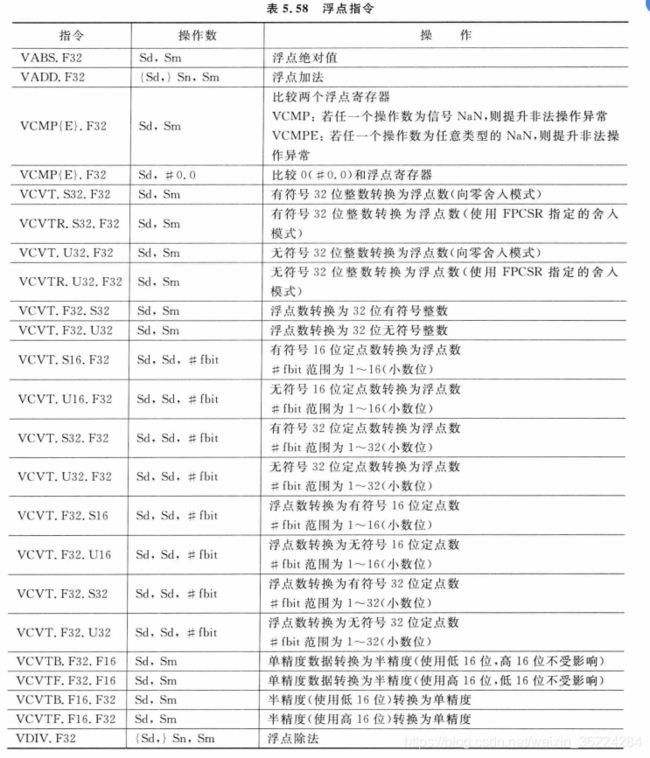
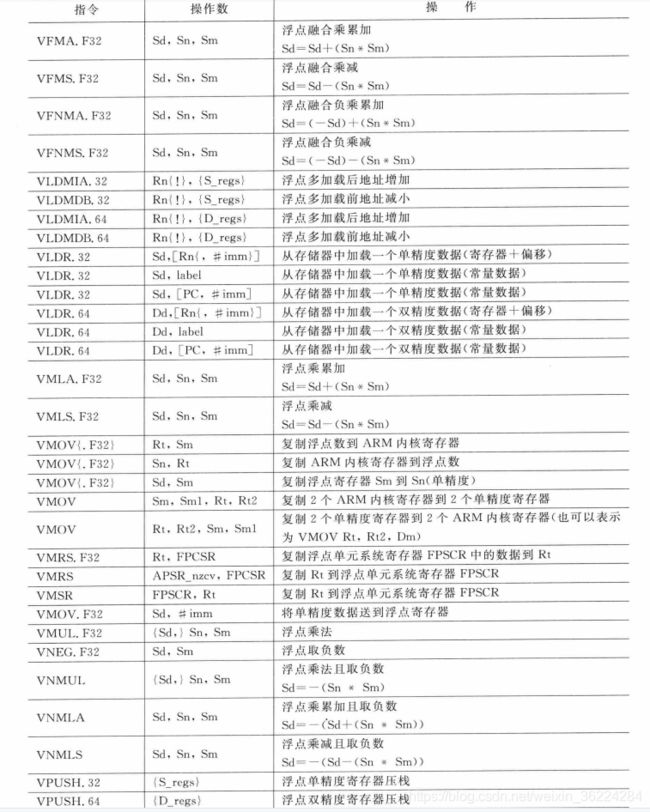
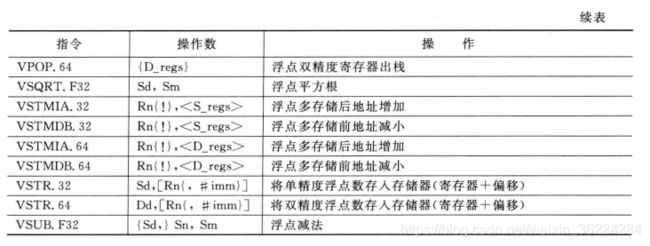
在使用浮点指令前,必须设置协处理器访问控制器SCB->CPACR。地址位0xE000ED88中的CP11和CP10位域来使能浮点单元,微控制器厂商提供的设备初始化代码SystemInit中一般会进行这个操作。另外设备头文件的_FPU_PRESENT也应该置1。对于浮点运算,输入参数要转换为浮点格式,否则会变为NaN操作数,有些NaN可用于浮点异常。
桶形移位器
多个32位Thumb指令可以利用Cortex-M3和M4处理器中的桶形移位器。例如若第二个操作数为ARM内核寄存器Rm,一些数据处理指令可以在进行数据处理前选择移位操作,如下图所示:
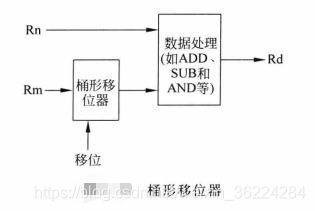
语法格式为:
助记符指令 Rd,Rn,Rm,<shift>
其中
- ASR #n 算术右移n位,1≤n≤32
- LSL #n 逻辑左移n位,1≤n≤31
- LSR #n 逻辑右移n位,1≤n≤32
- ROR #n 循环右移n位,1≤n≤31
- RRX 循环右移1位并展开,移位使包括C标识
移位操作时可选的,如果不需要移位,可以将指令写作:
助记符指令 Rd,Rn,Rm,
桶形移位器操作的用法如下表所示:
桶形移位器还可以用于存储器访问指令,如在计算地址时,特别适用于数组处理时地址等于array_base+index * 2^n的场景:
LDR Rd,[Rn,Rm,LSL #n]
编程中访问特殊寄存器和特殊指令
简介
有些指令无法在C编译器中利用普通C函数生成,如触发休眠(WFI,WFE)及存储器屏蔽(ISB、DSB、DMB)指令,如果适用这些指令,可以适用下面的方法:
- 使用CMSIS提供的内在函数,位于CMSIS-Core头文件中。
- 使用编译器提供的内在函数。
- 利用内联汇编插入所需的指令。
- 利用关键字或习语灯编译器相关的特性。
有些情况下,还需要访问处理器内的特殊寄存器,同样可以使用下面方式:
- 使用CMSIS-Core提供的处理器访问函数。
- 使用ARM C编译器中的寄存器名变量等编译器相关的特性。
- 利用内联汇编或嵌入式汇编插入汇编代码。
一般来说,建议用CMSIS-Core函数,和编译器独立,可移植性更好。
内在函数
内在函数有两种:
- CMSIS-Core内在函数。CMSIS-Core的头文件定义了一组用于访问特殊寄存器的内在函数,位于CMSIS-Core文件core_cmInstr.h和core_cm4_simd.h(用于Cortex-M4的SIMD指令)中。
- 编译器相关的内在函数。编译器相关的内在函数的使用方式和C函数差不多,只是它们是内置在C编译器中,这种方式通常会提供最优化的代码,不过函数定义依赖于编译工具,因此应用代码无法在工具链间移植。
内联汇编和嵌入汇编
在某些情况下,可能需要在C代码中利用内联汇编插入汇编指令,如在gcc中使用SVC时。它还可以用于生成优化的代码,因为可以很好的控制所生成的指令顺序。不过,利用内联汇编所创建的程序是和工具链相关的,可移植性差。ARM C编译器还支持嵌入汇编的特性,利用嵌入汇编,可以在C程序中创建汇编函数。
使用其他的编译器相关的特性
多数C编译器都具有方便产生特殊指令的多种特性,如ARM C编译器或Keil MDK-ARM可以利用_svc关键字插入SVC指令。
另一种编译器相关的特性位习语识别,若是以某种形式书写的数据运算C语句,C编译器会识别出这种功能并以简单的指令代替。
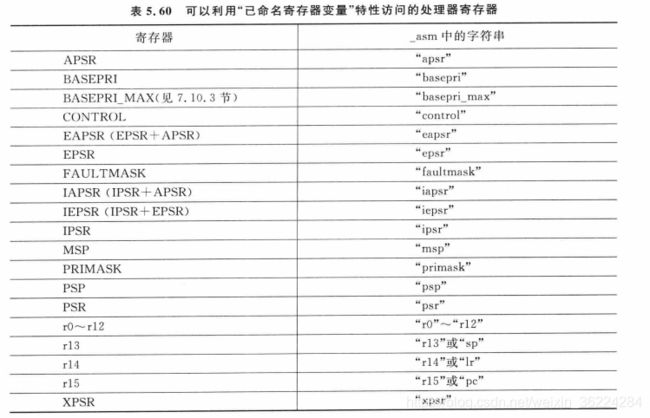
访问特殊寄存器
CMSIS-Core提供了访问Cortex-M3/M4处理器内特殊寄存器的多个函数。
如果使用ARM C编译器,可以使用已命名寄存器变量特性来访问特殊寄存器,语法为:
register type var-name _arm(reg);
其中,type为已命名寄存器变量的数据类型。var-name为已命名寄存器变量的名称。reg为指明使用哪个寄存器的字符串。
例如可以将寄存器名声明为:
register unsigned int reg_apsr _asm("apsr");
reg_apsr = reg_apsr & 0xF7FFFFFFUL; //清除APSR中Q标志
可以使用已命名寄存器变量特性来访问下表中的寄存器: