CC00011.spark——|Hadoop&Spark.V11|——|Spark.v11|sparkcore|开发环境搭建IDEA|
一、创建工程
### --- 创建一个maven工程:
~~~ Create New Project——>Maven——>Next——>Name:SparkBigData——>Finish——>END
### --- 安装scala插件;能读写HDFS文件
### --- 导入依赖插件,写入pom.xml文件
4.0.0
com.yanqi.sparkbigdata
com.yanqi.sparkbigdata
1.0-SNAPSHOT
1.8
1.8
2.12.10
2.4.5
2.9.2
UTF-8
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.12
${spark.version}
org.apache.spark
spark-sql_2.12
${spark.version}
joda-time
joda-time
2.9.7
mysql
mysql-connector-java
5.1.44
org.apache.spark
spark-hive_2.12
${spark.version}
net.alchim31.maven
scala-maven-plugin
3.2.2
org.apache.maven.plugins
maven-compiler-plugin
3.5.1
net.alchim31.maven
scala-maven-plugin
scala-compile-first
process-resources
add-source
compile
scala-test-compile
process-test-resources
testCompile
org.apache.maven.plugins
maven-compiler-plugin
compile
compile
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
二、编程代码
### --- 创建一个目录:scala
~~~ ——>main——>New:Directory——>New Directory:scala——>回车——>END
~~~ ——>创建包:cn.yanqi.sparkcore——>New Package——>
~~~ ——>增加scala Class——>SparkBigData——>Add Framework Support——>左侧:scala;右侧:scala-sdk-2.12.12——>ok
~~~ ——>创建一个class——>New:scala class——>Name:WordCount——>Object——>回车——>END### --- 编程代码
package cn.yanqi.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//使用本地文件
// val lines: RDD[String] = sc.textFile("data/wc.dat")
// 使用hdfs文件 -- 无配置文件
// val lines: RDD[String] = sc.textFile("hdfs://hadoop01:9000/wcinput/wc.txt")
// 使用资源文件调用hdfs --- 有配置文件:src/main/resources/core-site.xml
val lines: RDD[String] = sc.textFile( path="/wcinput/wc.txt")
lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
// 暂停时间,查看web界面
// Thread.sleep(100000)
sc.stop()
}
}
三、编译打印,资源调用
### --- 调用本地文件
~~~ # 创建data文件,写入wc.txt文件
~~~ # 拷贝相对路径:data/wc.txt
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn yanqi
yanqi mapreduce
yanqi mapreduce~~~ # 编程代码
//使用本地文件
val lines: RDD[String] = sc.textFile("data/wc.dat")
// 使用hdfs文件 -- 无配置文件
// val lines: RDD[String] = sc.textFile("hdfs://hadoop01:9000/wcinput/wc.txt")
// 使用资源文件调用hdfs --- 有配置文件:src/main/resources/core-site.xml
// val lines: RDD[String] = sc.textFile( path="/wcinput/wc.txt")~~~ # 编译打印
(hadoop,2)
(yanqi,3)
(mapreduce,5)
(yarn,2)
(hdfs,1)~~~ # web-UI的地址:http://windows10.microdone.cn:4040
~~~ 这个地址是很难捕捉到的;可以给它一个sleep值,让它等待在这个位置
~~~ # 通过Chrome访问地址:http://windows10.microdone.cn:4040
Thread.sleep(100000)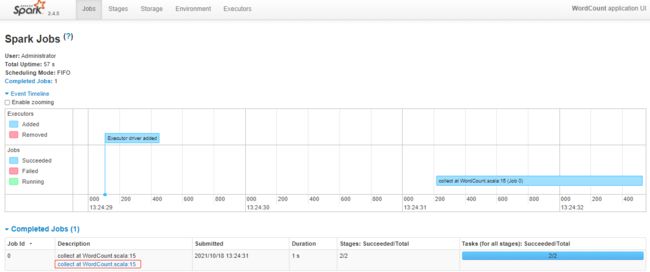
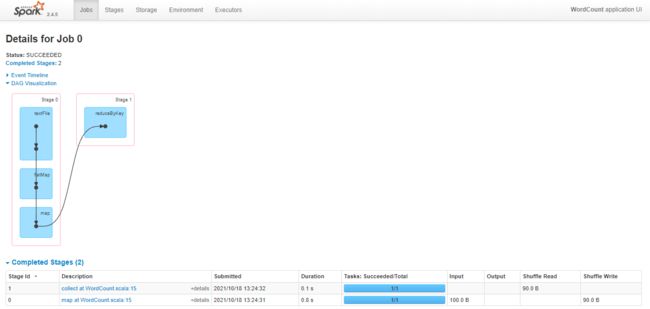
### --- 调用hdfs文件
~~~ # 编程代码
//使用本地文件
// val lines: RDD[String] = sc.textFile("data/wc.dat")
// 使用hdfs文件 -- 无配置文件
val lines: RDD[String] = sc.textFile("hdfs://hadoop01:9000/wcinput/wc.txt")
// 使用资源文件调用hdfs --- 有配置文件:src/main/resources/core-site.xml
// val lines: RDD[String] = sc.textFile( path="/wcinput/wc.txt")
// 暂停时间,查看web界面
// Thread.sleep(100000)~~~ # 编译打印
(hadoop,2)
(#在文件中输入如下内容,1)
(yanqi,3)
(mapreduce,3)
(yarn,2)
(hdfs,1)
三、通过配置文件调用hdfs上的资源参数
### --- 查看Hadoop集群上的core-site.xml资源参数
~~~ 把查找到的资源文件内容,拷贝到IDEA的resources下的core-site.xml配置文件中
[root@hadoop01 ~]# cat $HADOOP_HOME/etc/hadoop/core-site.xml### --- 在resources里创建hdfs的资源文件file:core-site.xml并写入配置参数
fs.defaultFS
hdfs://hadoop01:9000
hadoop.tmp.dir
/opt/yanqi/servers/hadoop-2.9.2/data/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
### --- 修改程序参数
//使用本地文件
// val lines: RDD[String] = sc.textFile("data/wc.dat")
// 使用hdfs文件 -- 无配置文件
// val lines: RDD[String] = sc.textFile("hdfs://hadoop01:9000/wcinput/wc.txt")
// 使用资源文件调用hdfs --- 有配置文件:src/main/resources/core-site.xml
val lines: RDD[String] = sc.textFile( path="/wcinput/wc.txt")### --- 编译运行程序
~~~ # 调用hdfs配置文件,并通过配置文件调用hdfs文件
(hadoop,2)
(#在文件中输入如下内容,1)
(yanqi,3)
(mapreduce,3)
(yarn,2)
(hdfs,1)
四、spark-core:链接源码
### --- spark-core源码下载地址:https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5.tgz
~~~ ——>打开源码:ctrl+点击:sparkconf——>choose sources——>选择源码包地址:spark-2.4.5-src
附录一:报错处理一
### --- 报错现象:
INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:12
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/wcinput/wc.txt### --- 报错分析:
~~~ # 错误提示是找不到这个文件
/wcinput/wc.txt### --- 解决方案:
~~~ # 方案一:
~~~ 调用hdfs失败:在resources里创建hdfs的资源文件file:core-site.xml并写入配置参数
~~~ # 方案二:
~~~ 把这个文件拷贝到本地调用