《利用Python进行数据分析》笔记记录第六章——数据载入、存储及文件格式
文章目录
- 前言
- 一、文本格式数据的读写
-
- 1.1 分块读入文件文本
- 1.2 将数据写入文件格式
- 1.3 使用分隔格式
- 1.4 JSON数据
- 1.5 XML和HTML:网络抓取
- 总结
前言
在上几篇文章中简单的了解了NumPy,pandas如何构建数组以及对数组的一些基本操作。接下来也是进行下面的学习记录。访问数据是使用各类工具所必需的第一步。我们将重点关注使用pandas进行数据输入和输出。
输出和输入通常有以下几种类型:读取文本文件及硬盘上其他更高效的格式文件、从数据库载入数据、与网络资源进行交互(比如Web API)。
下面将介绍文本文件的读取。
一、文本格式数据的读写
将表格型数据读取为DataFrame对象是pandas的重要特性。下表总结了部分实现该功能的函数,read_csv和read_table可能是后期我们使用最多的函数。
| 函数 | 描述 |
|---|---|
| read_csv | 从文件、URL或文件型对象读取分隔好的数据,逗号是默认分隔符 |
| read_table | 从文件、URL或文件型对象读取分隔好的数据,制表符(‘\t’) |
| read_fwf | 从特定宽度格式的文件中读取数据(无分隔符) |
| read_clipboard | read_table的剪贴板版本,在将表格从Web页面上转换成数据时有用 |
| read_excel | 从Excel的XLS或XLSX文件中读取表格数据 |
| read_ hdf | 读取用pandas存储的HDF5文件 |
| read_html | 从HTML文件中读取所有表格数据 |
| read_json | 从JSON字符串中读取数据 |
| read_msgpack | 读取MessagePack二进制格式的pandas数据 |
| read_pickle | 读取以Python pickle格式存取的任意对象 |
| read_sas | 读取存储在SAS系统中定制存储格式的SAS数据集 |
| read_sql | 将SQL查询的结果(使用SQLAlchemy)读取为pandas的DataFrame |
| read_ stata | 读取Stata格式的数据集 |
| read_feather | 读取Feather二进制格式 |
这些函数会将文本数据转换为DataFrame,这些函数的可选参数主要以下几种类型:
- 索引:可以将一或多个列作为返回的DataFrame,从文件或用户处获得列名,或者没有列名。
- 类型推断和数据转换:包括用户自定义的值转换和自定义的缺失值符号列表。
- 日期时间解析:包含组合功能,也包括将分散在多个列上的日期和时间信息组合成结果中的单个列。
- 迭代:支持对大型文件的分开迭代
- 未清洗数据问题:跳过行、页脚、注释以及其他次要数据,比如使用逗号分隔千位的数字。
注:一些数据载入函数,比如pandas.read_csv,会进行类型推断,因为列的数据类型并不是数据格式的一部分。那就意味着你不必指定哪一列是数值、整数、布尔值或字符串。其他的数据格式,比如HDF5、Feather和msgpack在格式中已经存储了数据类型。
让我们从一个小型的逗号分隔符文本文件(CSV)开始:

由于这个文件是逗号分隔符的,我们可以使用read_csv将它读入一个DataFrame。正常情况下,第一行作为列索引。:
df = pd.read_csv(r'D:\python project\aa.csv')
print(df)
---------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
当然我们也可以使用read_table,并指定分隔符:
df1 = pd.read_table(r'D:\python project\aa.csv',sep=',')
print(df1)
---------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
有的文件并不包含表头行。考虑以下文件:
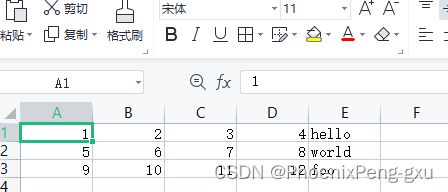
要读取该文件。你可以允许pandas自动分配默认列名,也可以自己指定列名:
df2 = pd.read_csv(r'D:\python project\ab.csv', header=None)
print(df2)
df3 = pd.read_csv(r'D:\python project\ab.csv',names=['a','b','c','d','message'])
print(df3)
---------------------------------------------------------
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
假设你想要message列成为返回DataFrame的索引,你可以指定位置4的列为索引,或将‘message’传给参数index_col:
df3 = pd.read_csv(r'D:\python project\ab.csv',names=['a','b','c','d','message'],index_col='message')
print(df3)
---------------------------------------------------------
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
当我们有一个这样的CSV文件:
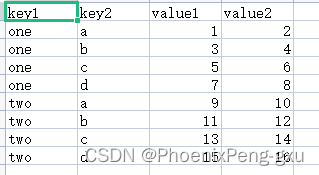
当你想要从多个列中形成一个分层索引,需要传入一个包含列序号或列名的列表:
df4 = pd.read_csv(r'D:\python project\ac.csv',index_col=['key1','key2'])
print(df4)
---------------------------------------------------------
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
一张表的分隔符并不是固定的,使用空白或其他方式来分隔字段。考虑下列CSV文件:

当字段是以多种不同数量的空格分开时,可以向read_table传入一个正则表达式作为分隔符。正则表达式为\s+。
df5 = pd.read_table(r'D:\python project\ad.csv',sep='\s+')
print(df5)
---------------------------------------------------------
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
在本例中,由于列名的数量比数据的列数少一个,因此read_table推断第一列应当作为DataFrame的索引。
解析函数有很多附加参数帮助你处理各种发生异常的文件格式。例如你可以使用skiprows来跳过第一行、第三行和第四行。

df6 = pd.read_csv(r'D:\python project\ae.csv',skiprows=[0,2,3])
print(df6)
---------------------------------------------------------
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
缺失值处理是文件解析过程中一个重要且常常的微妙的部分。通常情况下,缺失值要么不显示(空字符串),要么用一些标识值。默认情况下,pandas使用一些常见的标识,例如NA和NULL:

df7 = pd.read_csv(r'D:\python project\af.csv')
print(df7)
a = pd.isnull(df7)
print(a)
---------------------------------------------------------
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
something a b c d message
0 False False False False False True
1 False False False True False False
2 False False False False False False
na_values选项可以传入一个列表或一组字符串来处理缺失值:
df8 = pd.read_csv(r'D:\python project\af.csv',na_values=['1'])
print(df8)
---------------------------------------------------------
something a b c d message
0 one NaN 2 3.0 4 NaN
1 two 5.0 6 NaN 8 world
2 three 9.0 10 11.0 12 foo
在字典中,每列可以指定不同的缺失值标识:
sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
df9 = pd.read_csv(r'D:\python project\af.csv', na_values=sentinels)
print(df9)
---------------------------------------------------------
something a b c d message
0 one 1 2 3.0 4 NaN
1 NaN 5 6 NaN 8 world
2 three 9 10 11.0 12 NaN
下表列举了pandas.read_csv和pandas.read_table中常用的选项。
| 参数 | 描述 |
|---|---|
| path | 表明文件系统位置的字符串、URL或文件型对象 |
| sep 或 delimiter | 用于分隔每行字段的字符序列或正则表达式 |
| header | 用作列名的行号,默认是0(第一行),如果没有列名的话,应该为None |
| index_col | 用作结果中行索行的列号或列名,可以是一个单一的名称/数字 |
| names | 结果的列名列表,和header=None一起用 |
| skiprows | 从文件开头处起,需要跳过的行数或行号列表 |
| na_values | 需要用NA替换的值序列 |
| comment | 在行结尾处分隔注释符 |
| parse_dates | 尝试将数据解析为datetime,默认为False。如果为True,将尝试解析所有的列。也可以指定列号或列名列表来进行解析。如果列表的元素是元组或列表,将会把多个列组合在一起进行解析 |
| keep_date_col | 如果连接列到解析日期上,保留被连接的列,默认是False |
| converters | 包含列名称映射到函数的字典(例如{’foo‘:f}会把函数f应用到’foo‘列) |
| dayfirst | 解析非明确日期时。按照国际格式处理(例如7/6/2012-> June 7,2012),默认为False |
| date_parser | 用于解析日期的函数 |
| nrows | 从文件开头处读入的行数 |
| iterator | 返回一个TextParser对象,用于零散地读入文件 |
| chunksize | 用于迭代的块大小 |
| skip_footer | 忽略文件尾部的行数 |
| verbose | 打印各种解析器输出的信息,比如位于非数值列中的缺失值数量 |
| encoding | Unicode文本编码(例如’utf-8‘用于表示UTF-8编码的文本) |
| squeeze | 如果解析数据只包含一列,返回一个Series |
| thousands | 千位分隔符(例如’,‘或’.‘) |
1.1 分块读入文件文本
当需要处理大型文件或找出正确的参数集来正确处理大文件时,你可能需要读入文件的一个小片段或者按小块遍历文件。
result = pd.read_csv(r'D:\python project\ag.csv')
print(result)
--------------------------------------------------------------
one two three four key
0 0.358904 1.847321 -1.254227 1.251241 L
1 -0.990574 -0.826405 -0.233157 -1.282877 B
2 1.920885 0.597549 0.646940 -1.928790 H
3 2.228516 -0.860897 0.383491 -0.456372 J
4 -1.157310 -0.269323 0.037063 0.859981 E
5 -0.590421 1.411186 1.325885 1.211605 T
6 -1.014570 1.437334 0.048242 1.331328 A
7 0.652341 0.382947 1.473874 -1.933292 D
8 -1.692246 0.403185 1.266175 0.905261 T
9 0.010318 0.940105 -2.015481 -0.822804 Y
如果你只想读取一部分(避免读取整个文件),可以指明nrows:
result1 = pd.read_csv(r'D:\python project\ag.csv', nrows=5)
print(result1)
--------------------------------------------------------------
one two three four key
0 0.358904 1.847321 -1.254227 1.251241 L
1 -0.990574 -0.826405 -0.233157 -1.282877 B
2 1.920885 0.597549 0.646940 -1.928790 H
3 2.228516 -0.860897 0.383491 -0.456372 J
4 -1.157310 -0.269323 0.037063 0.859981 E
为了分块读入文件,可以指定chunksize作为每一块的行数:
chunker = pd.read_csv(r'D:\python project\ag.csv',chunksize=10)
print(chunker)
--------------------------------------------------------------
<pandas.io.parsers.readers.TextFileReader object at 0x000001939AB89700>
read_csv返回的TextParser对象允许你根据chunksize遍历文件。例如我们可以遍历ag.csv,并对’key‘列聚合获得计数值:
chunker = pd.read_csv(r'D:\python project\ag.csv',chunksize=10)
print(chunker)
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(),fill_value=0 )
tot =tot.sort_values(ascending=False)
print(tot[:10])
---------------------------------------------------------
T 2.0
L 1.0
B 1.0
H 1.0
J 1.0
E 1.0
A 1.0
D 1.0
Y 1.0
dtype: float64
TextParser还具有get_chunk方法,允许你按照任意大小读取数据块。
1.2 将数据写入文件格式
数据可以导出为分隔的形式。让我们看下之前读取的CSV文件:
df = pd.read_csv(r'D:\python project\af.csv')
print(df)
---------------------------------------------------------
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
使用DataFrame的to_csv方法,我们可以将数据导出为逗号分隔的文件:
df.to_csv(r'D:\python project\af1.csv')
输出结果:
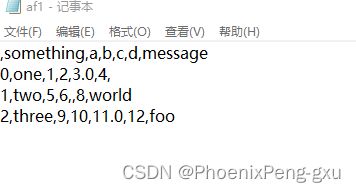
当然,其他的分隔符也是可以的(写入到sys.stdout时,控制台中打印的文本结果):
import sys
df.to_csv(sys.stdout,sep='|')
---------------------------------------------------------
|something|a|b|c|d|message
0|one|1|2|3.0|4|
1|two|5|6||8|world
2|three|9|10|11.0|12|foo
缺失值在输出时以空字符串出现。可以使用其他标识值对缺失值进行标注:
df.to_csv(sys.stdout,na_rep='NULL')
---------------------------------------------------------
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
如果没有其他选项被指定的话,行和列的标签都会被写入。不过二者也都可以禁止写入:
df.to_csv(sys.stdout, index=False, header=False)
---------------------------------------------------------
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
你也可以仅写入列的子集,并且按照你选择的顺序写入:
df.to_csv(sys.stdout, index=False, columns=list('abc'))
---------------------------------------------------------
a,b,c
1,2,3.0
5,6,
9,10,11.0
Series也有to_csv方法:
dates = pd.date_range('1/1/2000',periods=7)
ts = pd.Series(np.arange(7),index=dates)
ts.to_csv(r'D:\python project\time1.csv',header=False)
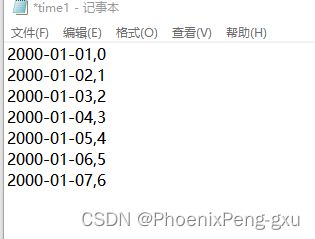
注意这里要header=False,否则会自动默认写入头列默认值为,0.
1.3 使用分隔格式
绝大多数的表型数据都可以使用函数pandas.read_table从硬盘中读取。然而,在某些情况下,一些手动操作可能是必不可少的。接收一个带有一个行或多行错误的文件并不少见,read_table也无法解决这种情况。为了介绍一些基础工具,考虑如下的小型CSV文件:

对于任何带有单字符分隔符的文件,你可以使用Python的内建csv模块。要使用它,需要将任一打开的文件或文件型对象传给csv.reader:
import csv
f = open(r'D:\python project\ah.csv')
reader = csv.reader(f)
像遍历文件那样遍历reader会产生元组,元组的值为删除了引号的字符:
for line in reader:
print(line)
---------------------------------------------------------
["'a'", "'b'", "'c'"]
["'1'", "'2'", "'3'"]
["'1'", "'2'", "'3'"]
之后,你就可以自行做一些必要处理,以将数据整理为你需要的形式。让我们按部就班,首先将文件读取为行的列表:
with open(r'D:\python project\ah.csv') as f:
lines = list(csv.reader(f))
然后,我们将数据拆分为列名行和数据行:
header, value = lines[0], lines[1:]
再然后,我们使用字典推导式和表达式zip(*value)生成一个包含数据列的字典,字典中行转置成列:
data_dict = {h: v for h ,v in zip(header,zip(*value))}
print(data_dict)
---------------------------------------------------------
{"'a'": ("'1'", "'1'"), "'b'": ("'2'", "'2'"), "'c'": ("'3'", "'3'")}
在这本书的前面章节中有提过,zip(*value)的作用,作为去“拆分”序列。将行的列表转换成列的列表。换句话就是说将列表中按列封装成元组。
print(list(zip(*value)))
---------------------------------------------------------
[("'1'", "'1'"), ("'2'", "'2'"), ("'3'", "'3'")]
CSV文件有多种不同风格。如需根据不同的分隔符、字符串引用约定或行终止符定义一种新的格式时,我们可以使用csv.Dialect定义一个简单的子类:
class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ';'
quotechar = '"'
quoting = csv.QUOTE_MINIMAL
f = open(r'D:\python project\ah.csv')
reader =csv.reader(f,dialect=my_dialect)
for lines in reader:
print(lines)
---------------------------------------------------------
["'a','b','c'"]
["'1','2','3'"]
["'1','2','3'"]
我们也可以不必定义子类,直接将CSV方言参数传入csv.reader的关键字参数:
reader = csv.reader(f,delimiter='|')
下表中列出了csv.Dialect中的一些属性及其用途:
| 参数 | 描述 |
|---|---|
| delimiter | 一个用于分隔字段的字符,默认是’,‘ |
| lineterminator | 行终止符,默认是’\r\n’,读取器会忽略行终止符并识别跨平台行终止符 |
| quotechar | 用在含有特殊字符字段中的引号,默认是’"’ |
| quoting | 引用惯例。选项包括csv.QUOTE_ALL(引用所有的字段),csv.QUOTE_MINIMAL(只使用特殊字符,如分隔符),csv.QUOTE_NONE(不引用)。默认是csv.QUOTE_MINIMAL |
| skipinitialspace | 忽略每个分隔符后的空白,默认是False |
| doublequote | 如何处理字段内部的引号。如果为True,则是双引号 |
| escapecher | 当引用设置为csv.QUOTE_NONE时用于转义分隔符的字符串,默认是禁用的 |
需要手动写入被分隔的文件时,你可以使用csv.writer。这个函数接收一个已经打开的可写入文件对象以及和csv.reader的相同方言、格式选项:
with open(r'D:\python project\ah1.csv', 'w') as f:
writer = csv.writer(f, dialect=my_dialect)
writer.writerow(('one', 'two', 'three'))
writer.writerow(('1', '2', '3'))
writer.writerow(('4', '5', '6'))
writer.writerow(('7', '8', '9'))
1.4 JSON数据
JSON已经成为web浏览器和其他应用间通过HTTP请求发送数据的标准格式。它是一种比CSV等表格文本形式更为自由的数据形式。请看下面的例子:
obj = """
{"name":"Wes",
"places_lived":["United States","Spain","Germany"],
"pet" : null,
"siblings :[{"name":"Scott","age":30,"pets":["Zeus","Zuko"]},
{"name":"Katie","age":38,"pets":["Sixes","Stache","Cisco"]}]
}
"""
JSON非常接近有效的Python代码,除了它的空值null和一些其他的细微差别(例如不允许列表末尾的逗号)之。基本类型是对象(字典)、数组(列表)、字符串、数字、布尔值和空值。对象中所有键都必须是字符串。有几个Python库用于读写JSON数据。我将在这里使用json,因为它是内置在Python标准库中的。将JSON字符串转换为Python形式时,使用json.loads方法:
JSON------>Python
import json
result = json.loads(obj)
print(result)
---------------------------------------------------------
{'name': 'Wes',
'places_lived': ['United States', 'Spain', 'Germany'], 'pet': None,
'siblings': [{'name': 'Scott', 'age': 30, 'pets': ['Zeus', 'Zuko']}, {'name': 'Katie', 'age': 38, 'pets': ['Sixes', 'Stache', 'Cisco']}]}
Python------>JSON
另一方,json.dumps可以将Python对象转换回JSON:
asjon = json.dumps(result)
如果你想将JSON对象或对象列表转换为DataFrame或其他数据结构。可以将字典构成的列表(之前是JSON对象)传入DataFrame构造函数,并选出数据字段的子集:
JSON ------>DataFrame
siblings = pd.DataFrame(result['siblings'],columns=['name','age'])
print(siblings)
---------------------------------------------------------
name age
0 Scott 30
1 Katie 38
pandas.read_json可以自动将JSON数据集按照指定次序转换为Series或DataFrame。

JSON ------>DataFrame和Series
pandas.read_json的默认选项是假设JSON数组中的每个对象是表里的一行:
data = pd.read_json(r'D:\python project\dsf.json')
print(data)
---------------------------------------------------------
a b c
0 1 2 3
1 4 5 6
2 7 8 9
如果你需要从pandas中将数据导出为JSON,一种方法是对Series和DataFrame使用to_json方法:
DataFrame和Series------>JSON
print(data.to_json())
print(data.to_json(orient='records'))
---------------------------------------------------------
{"a":{"0":1,"1":4,"2":7},"b":{"0":2,"1":5,"2":8},
"c":{"0":3,"1":6,"2":9}}
[{"a":1,"b":2,"c":3},{"a":4,"b":5,"c":6},{"a":7,"b":8,"c":9}]
1.5 XML和HTML:网络抓取
Python拥有很多可以对HTML和XML格式进行读取、写入数据的库,例如lxml(http://lxml.de)、Beautiful Soup 和 html5lib。尽管lxml是相对更快的库,但其他库可以更好地处理异常的HTML或XML文件。
pandas的内建函数read_html可以使用lxml和Beautiful Soup等库将HTML中的表自动解析为DataFrame对象。为了展示该功能我从某个网站的天气数据给大家演示:
详细的可以看这个文章进行阅读,感谢这个老哥的方法给我找到了示例。
示例也可以自己找,但是要带< table >标签的表格型数据。否则会报错:
ValueError: No tables found
还有就是在使用read_html前下载好两个库:beautifulsoup4 和 html5lib。
pandas.read_html 函数有很多选项,但是默认情况下,它会搜索并尝试解析所有包含在< table >标签中的表格型数据,返回的结果是DataFrame对象的列表:
ur1 = 'http://weather.sina.com.cn/china/shanghaishi/'
head = pd.read_html(ur1)
print(len(head))
failures = head[0]
print(failures.head())
---------------------------------------------------------
2
0 1 ... 6 7
0 市 县/区 ... 今天周三 (01月22日) 夜间 今天周三 (01月22日) 夜间
1 市 县/区 ... 风力方向 最低温度
[2 rows x 8 columns]
XML是另一种常用的结构化数据格式,它使用元数据支持分层、嵌套数据。 详情的示例可以看其他相关文章或者原著这里不做演示。
总结
例如:以上就是今天要讲的内容,本文介绍了如何使用各类工具去访问不同格式的文件数据。本文仅介绍了文本格式数据的读写常用的函数有read_csv和read_table。还介绍了我们在读入大型文本文件是可以进行分块读入,此外我们还学习了如何将数据写入文本格式中,并且在读取和写入时所采用到的分隔格式。还简单介绍了JSON数据,XML和HTML等。有关于其他类型将会在下次文章中学习。