第7节 hudi 0.9 与Flink 1.12.2 集成测试
安装Flink
从hudi 0.9的编译pom中查看,编译时用的 flink版本是1.12.2,在官网下载
Index of /dist/flink/flink-1.12.2
(1)上传到集群中
因为是测试流程,先单节点 上传至cdh06 解压
先不做hadoop 环境变量的配置,因为使用的cdh ,先让flink自己识别系统中的hadoop环境
(2)启动flink集群
cd /data/software/flink-1.12.2/bin
[xxx@cdh06 bin]# ./start-cluster.sh
(3)启动flink sql client,并关联编译好的hudi依赖包
[xxx@cdh06 bin]# ./sql-client.sh embedded -j /data/software/Hudi/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.11-0.9.0.jar
上面方式启动后操作会有问题
建议将这个 hudi-flink-bundle_2.11-0.9.0.jar 放在flink/lib 包下,再启动
./sql-client.sh embedded
启动
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR or HADOOP_CLASSPATH was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
No default environment specified.
Searching for '/data/software/flink-1.12.2/conf/sql-client-defaults.yaml'...found.
Reading default environment from: file:/data/software/flink-1.12.2/conf/sql-client-defaults.yaml
No session environment specified.
Command history file path: /root/.flink-sql-history
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
Flink SQL> Flink Sql Client操作
1.插入数据
(1)设置返回结果模式为tableau,让结果直接显示,设置处理模式为批处理
Flink SQL> set execution.result-mode=tableau;
Flink SQL> SET execution.type = batch;(2)创建一张Merge on Read的表,如果不指定默认为copy on write表
CREATE TABLE t1
( uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://nameservice1/tmp/flink-hudi/t1',
'table.type' = 'MERGE_ON_READ');(3)插入数据
INSERT INTO t1 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');(4)查看flink ui提示成功,查看对应9870页面,hdfs路径下已有数据产生
注意提交后观察flink 最大计算单元的并行度是多少,单节点测试,要将并行度配置到满足最大并行度计算所需的solt(卡槽)才能保证提交的任务能够有足够的资源去计算,并行度太少提交的作业会一直阻塞直到报错挂掉
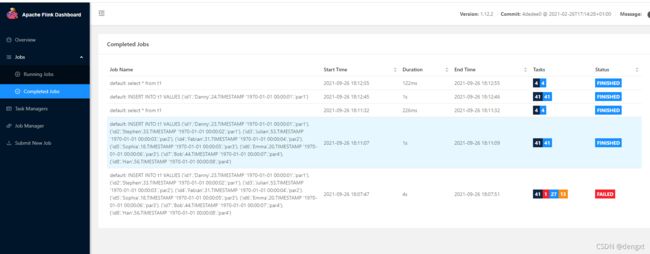
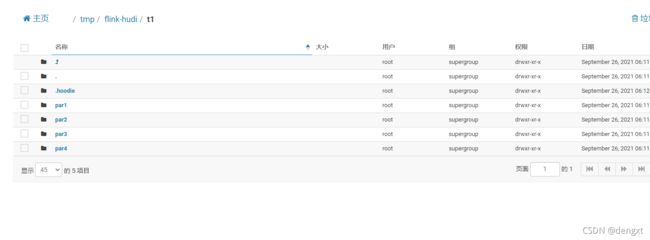
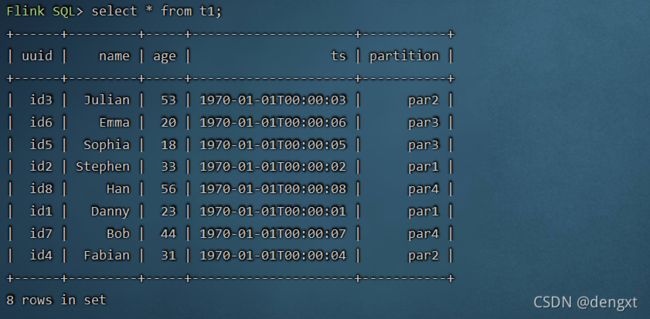
(5)查询表数据
Flink SQL> select *from t1;
2.修改数据
(1)flink sql操作hudi时很多参数不像spark需要一一设置,但是都有default默认值,比如文档上方建了t1表,插入数据时没有像spark一样指定唯一键,但是不代表flink的表就没有。参照官网参数可以看到flink表中唯一键的默认值为uuid.
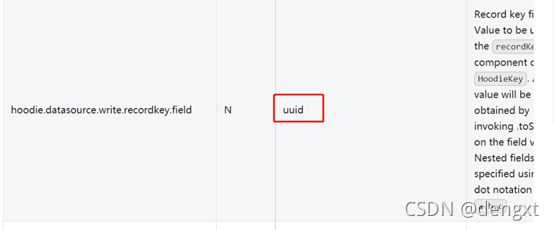
(2)所以t1表的主键其实已经指定好为uuid,那么sql语句则可进行修改操作
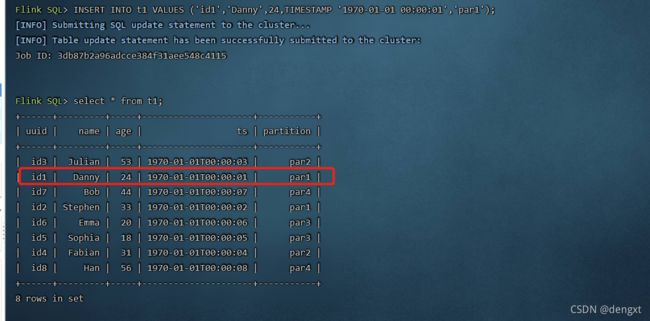
Flink SQL> insert into t1 values ('id1','Danny',24,TIMESTAMP '1970-01-01 00:00:01','par1');
(3)修改uuid为id1的数据,将原来年龄23岁改为24岁,flink sql除非第一次建表插入数据模式为overwrite,后续操作都是默认为append模式,可以直接触发修改操作。修改完毕后进行查询
3.流式查询
(1)hudi还提供flink sql流式查询,需要定义一个开始时间,那么该时间戳以后数据更改都会进行实时的更新。再建一张t2表指定相应参数,指定开始提交时间为2021年8月9号13点42分整开始,指定表每次检查提交间隔时间为4秒,默认1分钟。
这个要注意,t2是在t1的数据上建的表
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://nameservice1/tmp/flink-hudi/t1',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210926134200' ,
'read.streaming.check-interval' = '4'
);(2)设置执行模式为流,进行查询
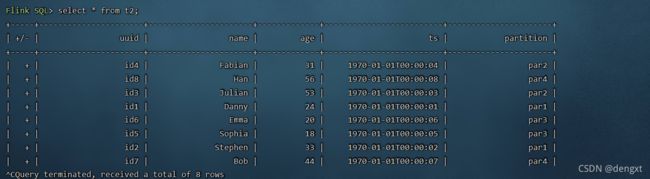
Flink SQL> SET execution.type=streaming;
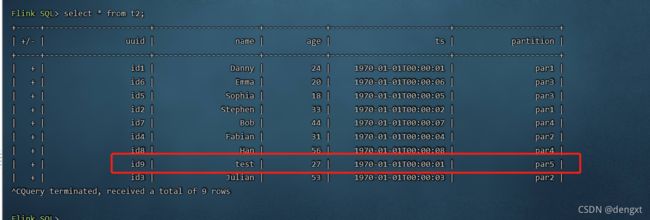
Flink SQL> select *from t2;
继续给t1表插入数据
insert into t1 values ('id9','test',27,TIMESTAMP '1970-01-01 00:00:01','par5');
select *from t2;