使用Python移除背景

我们生活在视频通话的时代。通过互联网,使用笔记本电脑或电脑自带的相机,我们把我们的生活广播给我们的同学、同事和家人。
但有时候,我们并不想广播我们自己的空间。我的办公室和其他许多办公室一样,常年杂乱无章。我身后的墙上还有一把吉他,这并不代表我很专业。
因此,Zoom和其他视频通话软件有一个隐藏背景的功能,通常把背景隐藏在你选择的图像后面。虽然大多数人不会考虑太多,但是确定由什么决定图像中前景和背景的实际任务并不容易。
前景检测
前景检测是计算机视觉领域最突出的应用之一。除了视频通话的例子,前景检测可以用于寻找和阅读图像中的文本,确定自动驾驶汽车中的障碍物,以及许多其他应用。
因此,许多复杂的方法被开发出来,以区分前景和背景。
OpenCV提供了几个“开箱即用”的解决方案;然而,在没有任何其他背景的情况下,这些都是黑盒,它们没有太多的学习机会。相反,我将使用一个定制的算法,它利用几个OpenCV模块来实现类似的结果。
OpenCV提供的“开箱即用”的解决方案:https://docs.opencv.org/master/d1/dc5/tutorial_background_subtraction.html
边缘检测和轮廓
我将演示的方法基于两个概念:边缘检测和轮廓。
边缘检测,顾名思义,就是试图在图像中找到对比线或边缘。这个关键的第一步是对图像进行预处理,以帮助区分任何物体。有几种边缘检测方法存在,其中,Canny方法是非常受欢迎的,并打包在OpenCV中。
Canny:https://en.wikipedia.org/wiki/Canny_edge_detector
一旦找到了边缘,寻找轮廓就变得更加容易和准确。在计算机视觉中,轮廓就是颜色或强度对比区域之间的连续边界线。不像边缘检测,寻找轮廓将在图像中发现突出的形状。
算法
如前所述,我将不会使用OpenCV中预先打包的背景移除器。相反,下面的流程图概括了我将使用的方法:
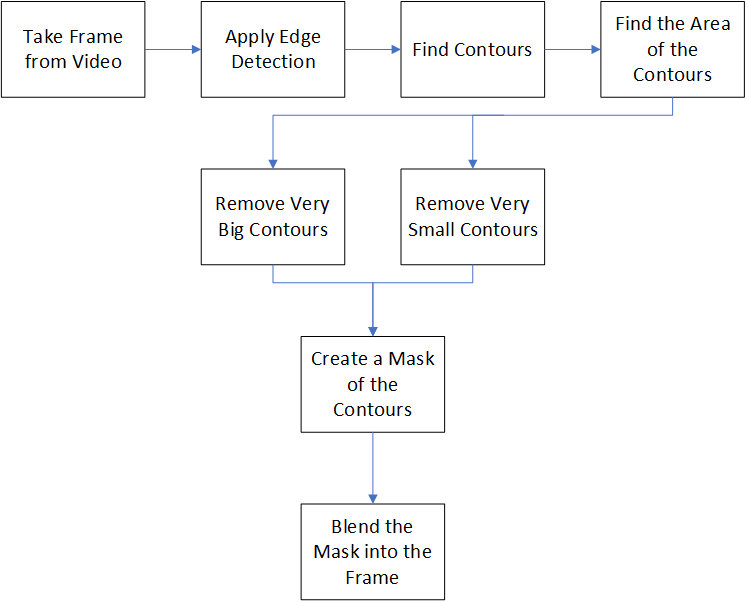
首先,我们将把图像转换成黑白。接下来,应用边缘检测,找到图像中的轮廓。对于前景来说,任何太大或太小的轮廓都将被移除。
其余的轮廓将被视为前景。这具有一定的直观意义,因为在复杂的背景中,特别小的细节将产生非常小的轮廓。相比之下,占据大部分屏幕的巨大轮廓可能不是前景,而是背景的一些视觉假象。
最后从剩余的轮廓生成一个蒙版并混合到原始图像中。
实现
import numpy as np
import cv2
NumPy的工作是使一些数据处理更加有效。OpenCV处理图像操作。
# Parameters
blur = 21
canny_low = 15
canny_high = 150
min_area = 0.0005
max_area = 0.95
dilate_iter = 10
erode_iter = 10
mask_color = (0.0,0.0,0.0)
接下来,分配一组变量,这些变量将影响背景的移除方式。每个变量都有一个独特的效果,可能需要根据视频的主题进行微调。简而言之:
blur:影响背景与前景分界线的“平滑度”
canny_low:沿边缘绘制的最小强度值
canny_high:沿边缘绘制的最大强度值
min_area:前景轮廓可能占据的最小面积。取为0到1之间的值。
max_area:前景轮廓可能占据的的最大面积。取为0到1之间的值。
dilate_iter:膨胀的迭代次数将在蒙版上发生。
erode_iter:腐蚀的迭代次数将在蒙版上发生。
mask_color:背景被移除后的颜色。
其中一些解释可能还没有意义,但是随着它们出现在代码中,我们将对其进行进一步解释。同时,可以随意使用提供的默认值来开始。
# initialize video from the webcam
video = cv2.VideoCapture(0)
接下来,初始化web摄像机(如果可用的话)。如果没有视频文件的路径,可以用0代替。
while True:
ret, frame = video.read()
一个无限循环是通过读取相机的帧开始的。read方法返回2个值。
一个布尔值,用于判断相机是否正常工作,存储在ret变量中。
来自视频提要的一个实际帧,记录在frame变量中。
if ret == True:
# Convert image to grayscale
image_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Apply Canny Edge Dection
edges = cv2.Canny(image_gray, canny_low, canny_high)
if 子句允许代码仅在摄像机正确捕获视频时继续执行。帧被渲染成灰度,因此可以进行下一步(边缘检测)。
设置强度值的最小值(canny_low变量)决定检测对比度的灵敏度。把它调整得太低可能会导致检测到更多不必要的边缘。
设置强度值最大值(canny_high变量)意味着任何高于其值的对比度将立即被分类为边缘。调得太高可能会影响性能,但调得太低可能会错过重要的边缘。
edges = cv2.dilate(edges, None)
edges = cv2.erode(edges, None)
这一步是严格可选的,但是对边缘进行膨胀和腐蚀会使它们更明显,并返回一个更好的最终产品。
\# get the contours and their areas
contour_info = [(c, cv2.contourArea(c),) for c in cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)[1]]
这一行中有很多内容,但这样写是为了提高性能。本质上,OpenCV函数findContours返回一个信息数组。在这些信息中,我们只关心以1为索引的轮廓。
对于所有找到的轮廓,实际轮廓本身及其面积的元组存储在一个列表中。
# Get the area of the image as a comparison
image_area = frame.shape[0] * frame.shape[1]
# calculate max and min areas in terms of pixels
max_area = max_area * image_area
min_area = min_area * image_area
计算图像的面积,然后确定最大和最小面积。
理想情况下,这一步应该在循环之外执行,因为这会影响性能。在流媒体播放之前使用初始帧,或者事先知道相机的尺寸,这样性能会更好。话虽如此,为了使代码更简单,便于演示,这就足够了。
# Set up mask with a matrix of 0's
mask = np.zeros(edges.shape, dtype = np.uint8)
接下来,创建一个蒙版,在这一点上它是一个0的矩阵。
# Go through and find relevant contours and apply to mask
for contour in contour_info:
# Instead of worrying about all the smaller contours, if the area is smaller than the min, the loop will break
if contour[1] > min_area and contour[1] < max_area:
# Add contour to mask
mask = cv2.fillConvexPoly(mask, contour[0], (255))
对于所有找到的轮廓线,将轮廓线的面积与最小值和最大值进行比较。如果轮廓大于最小值且小于最大值,则该轮廓将被添加到蒙版中。
如果轮廓小于最小值或大于最大值,它就不被认为是前景的一部分。
# use dilate, erode, and blur to smooth out the mask
mask = cv2.dilate(mask, None, iterations=mask_dilate_iter)
mask = cv2.erode(mask, None, iterations=mask_erode_iter)
mask = cv2.GaussianBlur(mask, (blur, blur), 0)
像之前一样,对蒙版进行膨胀和腐蚀在技术上是可选的,但创造了一个更美观的效果。同样的原理也适用于高斯模糊。
# Ensures data types match up
mask_stack = mask_stack.astype('float32') / 255.0
frame = frame.astype('float32') / 255.0
这些线将蒙版和框架都转换为需要混合的数据类型。这是一个普通但很重要的预处理步骤。
# Blend the image and the mask
masked = (mask_stack * frame) + ((1-mask_stack) * mask_color)
masked = (masked * 255).astype('uint8')
cv2.imshow("Foreground", masked)
最后,蒙版和框架混合在一起,这样背景就被涂黑了。最后一行显示结果。
# Use the q button to quit the operation
if cv2.waitKey(60) & 0xff == ord('q'):
break
else:
break
cv2.destroyAllWindows()
video.release()
在最后一分钟清理时,前几行创建了一个存在条件。如果按下键盘上的“q”,它将中断循环并终止程序。
else连接回前面关于相机正确捕获帧的if语句。如果相机失灵,它也会打破循环。
最后,一旦中断循环,将关闭显示结果图像的窗口,并关闭相机。
结果
如果一切顺利,应该创建一个显示实时背景删除的输出窗口。虽然这里的算法在非常简单的背景上工作得很好,但它可能在区分杂乱的背景方面遇到更多的困难。然而,总的来说,它工作得很好,足以证明这个概念。
下面是一个理想的例子,我靠着一堵白墙站着:
在理想的情况下实时去除背景。
这个算法很容易就能把我和墙区分开来。有些卡顿现象需要解决,但第一次尝试,效果很好。
相反,当我靠在书架上时,最坏的情况是这样的:
在恶劣条件下去除背景。
非常杂乱的背景,如装满书籍和其他配件的书架,会混淆算法,导致不完美的结果。它很难区分前景和背景,因为我的手臂和脸的大片区域在背景中闪烁。
我确实夸大了这个结果。我把背靠在书架上,这样效果就更明显了。如果我再站在书柜前面,结果就不会这么糟糕了;然而,它说明了背景减法在非理想情况下的困难。
在现实中,大多数尝试都会产生介于最佳和最差情况之间的结果。
结论
前景检测和背景减法的概念交织在一起,是计算机视觉研究的热点之一。虽然有许多方法存在,但是边缘检测和在图像中查找轮廓的简单应用提供了良好的基础。
使用OpenCV的内置函数,所使用的方法能够实时渲染背景移除。在理想的条件下,算法工作近乎完美,但是对于复杂的背景,可能需要进行一些其他调整。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓