Redis:基础、数据类型和版本区别(持续更新)
Redis:基础、数据结构和版本区别
- Redis:基础
- Redis:数据类型
-
- String(字符串)
- List(列表)
- Hash(哈希)
- Set(无序集合)
- ZSet(有序集合sorted set)
- Redis:版本对比
-
- Redis2.0
- Redis3.0
- Redis4.0
- Redis5.0
- Redis6.0
- Redis7.0
Redis:基础
推荐java3y:https://mp.weixin.qq.com/s/SdE6MR9g-v93ZtJPme9e8Q
一:Redis的是什么?
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。使用C语言编写,支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
二:Redis作用与使用场景
1、Redis的作用
获取最新的n个数据;获取TOP N的数据;设置精准的抢购时间;实现计数器;去除重复值;利用set命令制作反垃圾系统;构建队列系统。
三:Redis的瓶颈在于内存和网络,而不在于CPU
Redis是基于内存操作而CPU又不是Redis的瓶颈,Redis的瓶颈最有可能来自内存和网络带宽。单线程实现起来更简单,cpu又不是瓶颈,所以Redis是由单线程实现的。
四:Redis为什么快?
1、redis是基于内存的,内存的读写速度非常快
CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
2、redis是单线程的,省去了很多上下文切换线程的时间
2.1:不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除
一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2.2:单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
2.3:CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
2.4:如果CPU成为Redis瓶颈,或者不想让服务器其他CPU核闲置,那怎么办?:
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
3、redis使用多路复用技术,可以处理并发的连接。
非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
4、IO多路复用技术
redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
五:Redis单线程的优劣势
1、单进程单线程优势
代码更清晰,处理逻辑更简单
不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
不存在多进程或者多线程导致的切换而消耗CPU
2、单进程单线程弊端
无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
Redis:数据类型
String(字符串)
string:最简单的字符串类型键值对缓存,也是最基本的
一:key相关
keys *:查看所有的key (不建议在生产上使用,有性能影响)
type key:key的类型
二:常用命令
get/set/del:查询/设置/删除
set rekey data:设置已经存在的key,会覆盖
setnx rekey data:设置已经存在的key,不会覆盖
set key value ex time:设置带过期时间的数据
expire key:设置过期时间
ttl:查看剩余时间,-1永不过期,-2过期
append key:合并字符串
strlen key:字符串长度
incr key:累加1
decr key:类减1
incrby key num:累加给定数值
decrby key num:累减给定数值
getrange key start end:截取数据,end=-1 代表到最后
setrange key start newdata:从start位置开始替换数据
mset:连续设值
mget:连续取值
msetnx:连续设置,如果存在则不设置
四:其他
select index:切换数据库,总共默认16个
flushdb:删除当前下边db中的数据
flushall:删除所有db中的数据
List(列表)
一:list介绍
Redis列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- list类型是用来存储多个有序的字符串的,支持存储2^32次方-1个元素。
- redis可以从链表的两端进行插入(pubsh)和弹出(pop)元素,充当队列或者栈
- 支持读取指定范围的元素集
- 读取指定下标的元素等
list是链表结构,是双向的。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)
另外当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
也可以把list看成一种队列,所以在很多时候可以用redis用作消息队列,这个时候它的作用就类似于activeMq啦;
应用案例有时间轴数据,评论列表,消息传递等等,它可以提供简便的分页,读写操作。
二:常用命令
lpush:从列表左侧头部添加数据
例子:lpush mylist 1 或 lpush mylist 2
rpush:从列表右侧尾部添加数据
例子:rpush mylist 1 或 rpush mylist 2
lpop:从左侧头部取出一个元素(移除列表头部第一个元素,返回值为移除的元素)
例子:lpop mylist
查看:lrange mylist
rpop:从左侧尾部取出一个元素(移除列表的最后一个元素,返回值为移除的元素)
例子:rpop mylist
查看:lrange mylist
lrange:取出指定范围的元素
Lrem:删除列表指定元素
例子:为删除个数(如果小于0 从右往左删除,如果等于0,全部删除)
lrem mylist 3 1
index:获取第几个坐标的值
index mylist 2
llen:获取列表的长度
llen mylist
lset:修改坐标小的值
lset mylist 1 tomcat
ltrim:修剪列表
ltrim mylist 1 3
linsert:指定位置添加元素
linsert mylist befor 0 -1
lpushx:将一个值插入到已存在的列表头部;如果存在列表就添加,不存就不添加
rpushx:将一个值插入到已存在的列表尾部;如果存在列表就添加,不存就不添加
blpop:如果列表有值就取出,如果没有值就阻塞到有值在获取,超时时间(timeout 0代表无限期)
blpop mylist 0
brpop:同上
brpoplpush:同上
Hash(哈希)
一:hash介绍
类似map,存储结构化数据结构,比如存储一个对象(不能有嵌套对象)。
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
二:hash使用场景
一般对象用string + json存储,对象中某些频繁变化的属性抽出来用hash存储。
当对象的某个属性需要频繁修改时,不适合用string+json,因为它不够灵活,每次修改都需要重新将整个对象序列化并赋值,如果使用hash类型,则可以针对某个属性单独修改,没有序列化,也不需要修改整个对象。
比如,商品的价格、销量、关注数、评价数等可能经常发生变化的属性,就适合存储在hash类型里。
三:常用命令
Hset key field value:命令用于为哈希表中的字段赋值 。
如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
如果字段已经存在于哈希表中,旧值将被覆盖。
HSET myhash field1 "foo"
返回值
如果字段是哈希表中的一个新建字段,并且值设置成功,返回 1 。 如果哈希表中域字段已经存在且旧值已被新值覆盖,返回 0 。
HGET key field:获取存储在哈希表中指定字段的值。
hget testhash name
返回给定字段的值。如果给定的字段或 key 不存在时,返回nil。
HGETALL key:获取在哈希表中指定 key 的所有字段和值
以列表形式返回哈希表的字段及字段值。 若 key 不存在,返回空列表。
hgetall testhash
HKEYS key:获取所有哈希表中的字段
包含哈希表中所有域(field)列表。 当 key 不存在时,返回一个空列表。
hkeys testhash
HEXISTS key field:查看哈希表 key 中,指定的字段是否存在。
如果哈希表含有给定字段,返回 1 。 如果哈希表不含有给定字段,或 key 不存在,返回 0 。
hexists testhash name
HLEN key:获取哈希表中字段的数量
返回哈希表中字段的数量。 当 key 不存在时,返回 0 。
hlen testhash
hlen testsss
HVALS key:获取哈希表中所有值;
一个包含哈希表中所有域(field)值的列表。 当 key 不存在时,返回一个空表。
hvals testhash
HSETNX key field value:只有在字段 field 不存在时,设置哈希表字段的值;
设置成功,返回 1 。 如果给定字段已经存在且没有操作被执行,返回 0 。
hsetnx testhash score 100
HINCRBY key field increment:为哈希表 key 中的指定字段的整数值加上增量 increment 。
返回值:执行 HINCRBY 命令之后,哈希表中字段的值。
hgetall testhash
hincrby testhash age 2
HINCRBYFLOAT key field increment:为哈希表 key 中的指定字段的浮点数值加上增量 increment 。
返回值:执行 Hincrbyfloat 命令之后,哈希表中字段的值。
hgetall testhash
hincrbyfloat testhash age 1.1
HMSET key field1 value1 [field2 value2 ]
同时将多个 field-value (域-值)对设置到哈希表 key 中。
hmset student name xiaohu age 18 gender men
查看:
hget student name
hget student age
hget student gender
HMGET key field1 [field2]
获取所有给定字段的值
一个包含多个给定字段关联值的表,表值的排列顺序和指定字段的请求顺序一样。没有则返回nil
hmset student name xiaohu age 18 gender men
查看:
hget student name
hget student age
hget student gender
获取所有:
hmget student name age gender body
Hdel:
删除一个或多个哈希表字段
HSET myhash field1 "foo"
返回值:被成功删除字段的数量,不包括被忽略的字段。
成功:(integer) 1;不能存在:(integer) 0
HSTRLEN key field
获取指定字段的field的长度。3.2后的版本才有的
Set(无序集合)
一:set集合介绍
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
二:set常用命令
1、sadd
添加一个元素到集合中(集合中的元素无序的并且唯一)
sadd myset ceshi1
sadd myset ceshi2 ceshi3
smembers myset
2、smembers
查看集合中所有的元素
smembers myset
3、srem
删除结合中指定的元素
srem myset ceshi1
成功返回 1
4、scard
返回集合元素的数量
scard myset
5、sRandMember
如果不填写返回个数,默认是1,如果填写的数字大于集合的size,那么返回集合的所有元素
如果填写的是负数,如果绝对值大于集合的size,那么返回值里会出现一个元素多次出现的情况。
如果key不存在,则返回nil
srandmember myset
srandmember myset1
6、smove
将一个集合的元素转移到另一个集合中
srandmember myset 5
srandmember myset1 ceshi6
smove myset myset1 ceshi3
7、spop
从集合中随机移出一个元素
smembers myset
spop myset
smembers myset
8、sismember
判断元素是否在集合中,如果存在 返回1,否则返回0
smembers myset
sismember myset ceshi1
sismember myset kkkk
9、sscan
使用游标获取集合中的值
sscan scantest 0 match scanceshi*
从0开始,一直循环,会返回两个集合,第几个是游标的位置,如果为0那么说明执行结束,
如果不为0,那么下次以第一个集合返回的值作为下次开始的位置如下
10、sunion
集合并运算(集合 并/交/差运算)
sadd bing1 1 11 111
sadd bing2 2 22 222
sadd bing3 3 33 333
sunion bing1 bing2 bing3
11、SUNIONSTORE
求并集后存到一个新的集合(如果结果集存入到已有的集合,那么会覆盖以后的数据集合)
sunionstore bing4 bing1 bing2
smembers bing4
12、sinter/sinterstore同上
13、sdiff/sdiffstore同上
ZSet(有序集合sorted set)
一:ZSet介绍
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
二:常用命令
1、zadd 添加(一个或多个)
zadd key score1 member1 [score2 member2]
向有序集合添加一个或多个成员,或者更新已存在成员的分数。
命令用于将一个或多个成员元素及其分数值加入到有序集当中。
如果某个成员已经是有序集的成员,那么更新这个成员的分数值,并通过重新插入这个成员元素,来保证该成员在正确的位置上。
分数值可以是整数值或双精度浮点数。
如果有序集合 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误.
例子:
zadd myzset 1 name 2 age 3 gender
zrang myzset 0 -1 withscore
zadd myzset 1 names
zrang myzset 0 -1 withscores
2、zincrby 修改成员分数
zincrby key increment member
ZINCRBY key increment member
有序集合中对指定成员的分数加上增量 increment
Redis zincrby 命令对有序集合中指定成员的分数加上增量 increment
可以通过传递一个负数值 increment ,让分数减去相应的值,比如 ZINCRBY key -5 member ,就是让 member 的 score 值减去 5 。
当 key 不存在,或分数不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。
当 key 不是有序集类型时,返回一个错误。
分数值可以是整数值或双精度浮点数。
返回值:member 成员的新分数值,以字符串形式表示。
zrang myzset 0 -1 withscores
zincrby myzset -1 class
zrang myzset 0 -1 withscores
zincrby myzset -1 class
3、zrang 查询(索引查询-分数值递增)
通过索引区间返回有序集合指定区间内的成员
语法:ZRANGE key start stop [WITHSCORES]
返回值:指定区间内,带有分数值(可选)的有序集成员的列表。
## 显示整个有序集成员
zrang myzset 0 -1 withscores
## 显示有序集合下标区间 1 至 2 的成员时
zrang myzset 1 2 withscores
## 测试 end 下标超出最大下标时的情况
zrang myzset 0 1000 withscores
4、zcard 获取有序集合成员数量
语法:zcard key
Redis zcard 命令用于计算集合中元素的数量。
返回值:当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0
zcard myzset
zcard myzsets
5、zcount 查询指定区间分数的成员数量
语法:zcount key min max
计算在有序集合中指定区间分数的成员数
命令用于计算有序集合中指定分数区间的成员数量。
返回值:分数值在 min 和 max 之间的成员的数量。
zrang myzset 0 -1
zrang myzset 0 -1 withscores
zcount myset 1 2
zcount myzsets 1 2
6、zlexcount 查询指定字典区间的成员数量
zlexcount key min max
在有序集合中计算指定字典区间内成员数量
返回值:指定区间内的成员数量。
zrang myzset 0 -1 withscores
zlexcount myset [a [b
zlexcount myset [a [d
zlexcount myset [a [z
7、zrangebyscore 查询指定分数区间的成员 - 分数值递增
语法:zrangebyscore key min max [withscores] [limit]
通过分数返回有序集合指定区间内的成员
zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。
具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。
默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
zrang myset 0 -1 withscores
zrangebyscore myset -1 3 withscores
8、zrank 查询指定成员的索引 (分数值递增排序)
zrank key member
返回有序集合中指定成员的索引
zrank 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
zadd myset 1 11 2 22 3 33 4 55 6 66
zrang myset 0 -1 withscores
zrank myset 11
zrank myset 22
9、zrevrank 查询指定成员的索引 (分数值递减排序)
语法:zrevrank key member
返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
返回值:如果成员是有序集 key 的成员,返回成员的排名。 如果成员不是有序集 key 的成员,返回 nil 。
zrevrank 命令返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序。
排名以 0 为底,也就是说, 分数值最大的成员排名为 0 。
使用 ZRANK 命令可以获得成员按分数值递增(从小到大)排列的排名。
zrang myset 0 -1 withscores
zrevrank myset 11
zrevrank myset 22
Redis:版本对比
Redis2.0
1、Redis2.6
Redis2.6在2012年正是发布,经历了17个版本,到2.6.17版本,相对于Redis2.4,主要特性如下:
(1)服务端支持Lua脚本。
(2)去掉虚拟内存相关功能。
(3)放开对客户端连接数的硬编码限制。
(4)键的过期时间支持毫秒。
(5)从节点支持只读功能。
(6)两个新的位图命令:bitcount和bitop。
(7)增强了redis-benchmark的功能:支持定制化的压测,CSV输出等功能。
(8)基于浮点数自增命令:incrbyfloat和hincrbyfloat。
(9)redis-cli可以使用--eval参数实现Lua脚本执行。
(10)shutdown命令增强。
(11)重构了大量的核心代码,所有集群相关的代码都去掉了,cluster功能将会是3.0版本最大的亮点。
(12)info可以按照section输出,并且添加了一些统计项
(13)sort命令优化
2、Redis2.8
Redis2.8在2013年11月22日正式发布,经历了24个版本,到2.8.24版本,相比于Redis2.6,主要特性如下:
(1)添加部分主从复制的功能,在一定程度上降低了由于网络问题,造成频繁全量复制生成RDB对系统造成的压力。
(2)尝试性的支持IPv6.
(3)可以通过config set命令设置maxclients。
(4)可以用bind命令绑定多个IP地址。
(5)Redis设置了明显的进程名,方便使用ps命令查看系统进程。
(6)config rewrite命令可以将config set持久化到Redis配置文件中。
(7)发布订阅添加了pubsub。
(8)Redis Sentinel第二版,相比于Redis2.6的Redis Sentinel,此版本已经变成生产可用。
Redis3.0
1、Redis3.0(里程碑)
Redis3.0在2015年4月1日正式发布,相比于Redis2.8主要特性如下:
Redis最大的改动就是添加Redis的分布式实现Redis Cluster。
(1)Redis Cluster:Redis的官方分布式实现。
(2)全新的embedded string对象编码结果,优化小对象内存访问,在特定的工作负载下载速度大幅提升。
(3)Iru算法大幅提升。
(4)migrate连接缓存,大幅提升键迁移的速度。
(5)migrate命令两个新的参数copy和replace。
(6)新的client pause命令,在指定时间内停止处理客户端请求。
(7)bitcount命令性能提升。
(8)cinfig set设置maxmemory时候可以设置不同的单位(之前只能是字节)。
(9)Redis日志小做调整:日志中会反应当前实例的角色(master或者slave)。
(10)incr命令性能提升。
2、Redis3.2
Redis3.2在2016年5月6日正式发布,相比于Redis3.0主要特征如下:
(1)添加GEO相关功能。
(2)SDS在速度和节省空间上都做了优化。
(3)支持用upstart或者systemd管理Redis进程。
(4)新的List编码类型:quicklist。
(5)从节点读取过期数据保证一致性。
(6)添加了hstrlen命令。
(7)增强了debug命令,支持了更多的参数。
(8)Lua脚本功能增强。
(9)添加了Lua Debugger。
(10)config set 支持更多的配置参数。
(11)优化了Redis崩溃后的相关报告。
(12)新的RDB格式,但是仍然兼容旧的RDB。
(13)加速RDB的加载速度。
(14)spop命令支持个数参数。
(15)cluster nodes命令得到加速。
(16)Jemalloc更新到4.0.3版本。
Redis4.0
下面是Redis4.0的新特性:
(1)提供了模块系统,方便第三方开发者拓展Redis的功能。
(2)PSYNC2.0:优化了之前版本中,主从节点切换必然引起全量复制的问题。
(3)提供了新的缓存剔除算法:LFU(Last Frequently Used),并对已有算法进行了优化。
(4)提供了非阻塞del和flushall/flushdb功能,有效解决删除了bigkey可能造成的Redis阻塞。
(5)提供了memory命令,实现对内存更为全面的监控统计。
(6)提供了交互数据库功能,实现Redis内部数据库的数据置换。
(7)提供了RDB-AOF混合持久化格式,充分利用了AOF和RDB各自优势。
(8)Redis Cluster 兼容NAT和Docker。
Redis5.0
(1)新的Stream数据类型。
(2)新的Redis模块API:Timers and Cluster API。
(3)RDB现在存储LFU和LRU信息。
(4)集群管理器从Ruby(redis-trib.rb)移植到C代码。可以在redis-cli中。查看`redis-cli —cluster help`了解更多信息。
(5)新sorted set命令:ZPOPMIN / MAX和阻塞变量。
(6)主动碎片整理V2。
(7)增强HyperLogLog实现。
(8)更好的内存统计报告。
(9)许多带有子命令的命令现在都有一个HELP子命令。
(10)客户经常连接和断开连接时性能更好。
(11)错误修复和改进。
(12)Jemalloc升级到5.1版
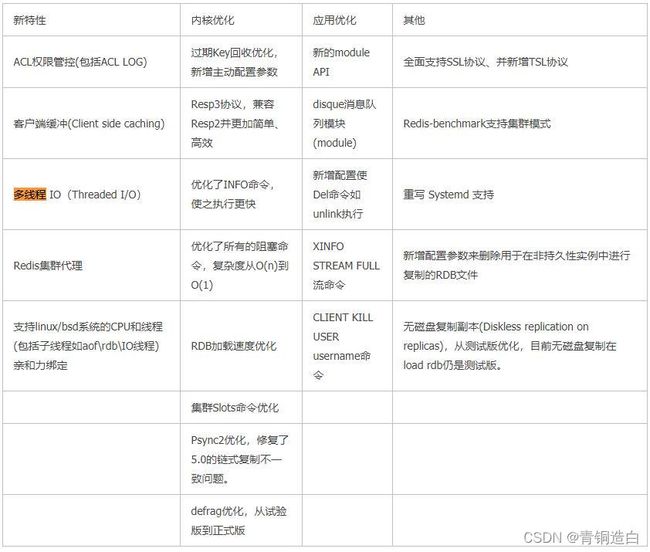
Redis6.0
https://zhuanlan.zhihu.com/p/76788470