Vue3 编译原理
文章目录
- 一、编译流程
-
- 1. 解读入口文件 packgages/vue/index.ts
- 2. compile函数的运行流程
- 二、AST 解析器
-
- 1. `ast` 的生成
- 2. 创建`ast`的根节点
- 3. 解析子节点 `parseChildren`(关键)
- 4. 解析模版元素 Element
- 模版元素解析-举例分析
一、编译流程
1. 解读入口文件 packgages/vue/index.ts
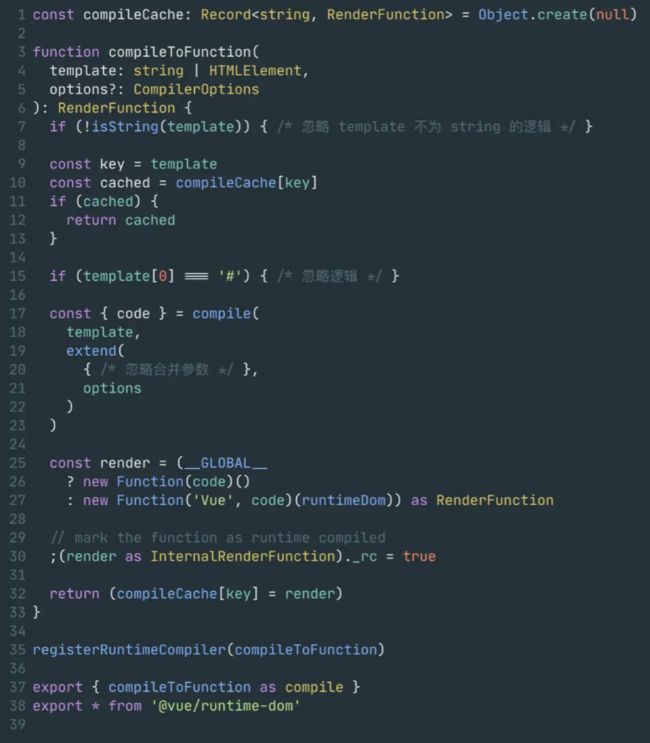
首先从Vue对象的入口开始,packgages/vue/index.ts文件中只有compileToFunction函数:
- 依赖注入编译函数至runtimeregisterRuntimeCompiler(compileToFunction)
- runtime 调用编译函数compileToFunction
- 返回包含code的编译结果
- 将code作为参数传入Function 的构造函数将生成函数赋值给render变量。
- 将render函数作为编译结果返回
下面这个简单的模版,
<template>
<div>
Hello World
div>
template>
经过编译后,code返回的字符串为:
const _Vue = Vue return function render(_ctx, _cache) {
with(_ctx) {
const {
openBlock: _openBlock, createBlock:_createBlock
} = _Vue;
return (_openBlock(), _createBlock("div", null, "Hello World"))
}
}
- 拿到这个代码字符串的结果后,第25行声明了一个render变量,并将生成的代码字符串code 作为参数传入了new Function 构造函数,生成了render函数。可以将上面的code字符串格式化。
- 这里的render显而易见是一个柯里化的函数,返回了一个函数,函数内部通过with来扩展作用域链。
- 最后,入口文件返回了render变量,并顺手缓存了render函数。
- 在第一行,入口文件创建了一个
compileCache对象,用以缓存compileToFunction函数生成的render函数,将template参数作为缓存的key,并在11行进行if分支做缓存判断,如果该模版之前被缓存过,则不再进行编译,直接返回缓存中的render函数,以此提高性能。
2. compile函数的运行流程
compile函数涉及到compile-dom 和compile-core 两个模块。
compile的运行流程:
baseCompile命名理由:因为compile-core是编译的核心模块,接收外部的参数来按照规则完成编译,而compile-dom是专门处理浏览器场景下的编译,在这个模块下导出的compile函数是入口文件真正接收的编译函数。而compile-dom中的compile函数相对baseCompile也是一个更高阶的编译器。例如:当Vue在weex或iOS或Android这些Native App中工作时,compile-dom可能会被相关的移动端编译库来取代。baseCompile函数:

- 从函数声明中看,baseCompile接收template模版以及上层高阶编译器处理过的options编译选项,最终返回一个CodegenResult类型的编译结果。
export interface CodegenResult {
code: string
preamble: string
ast: RootNode
map?: RawSourceMap
}
- 看上方源码的第12行,判断template模版是否为字符串,如果是的话,则会对字符串进行解析,否则直接将template作为AST。(我们平时写的vue代码都是以字符串的形式传递进去的。)
- 然后是第16行调用了transform函数,以及传入了指令转换、节点等工具函数,对由模版生成的AST进行转换。
- 最后32行,将转换好的ast传入进generate,生成CodegenResult类型的返回结果。
二、AST 解析器
1. ast 的生成
ast的生成有一个三目运算符的判断,如果传进来的template模版是一个字符串,那么则调用baseParse解析模版字符串,否则直接将template作为ast对象。
baseParse 函数:
export function baseParse(
content: string,
options: ParserOptions = {}
): RootNode {
const context = createParserContext(content, options) // 创建解析的上下文对象
const start = getCursor(context) // 生成记录解析过程的游标信息
return createRoot( // 生成并返回 root 根节点
parseChildren(context, TextModes.DATA, []), // 解析子节点,作为 root 根节点的 children 属性
getSelection(context, start)
)
}
- 首先会创建解析的上下文,根据上下文获取游标信息,由于还未进行解析,所以游标中的
column、line、offset属性对应的都是template的起始位置。 - 之后就是创建根节点,并返回根节点,至此
ast树生成,解析完成。
2. 创建ast的根节点
export function createRoot(
children: TemplateChildNode[],
loc = locStub
): RootNode {
return {
type: NodeTypes.ROOT,
children,
helpers: [],
components: [],
directives: [],
hoists: [],
imports: [],
cached: 0,
temps: 0,
codegenNode: undefined,
loc
}
}
- 该函数返回了一个
RootNode类型的根节点对象,其中我们传入的children参数会被作为根节点的children参数。
3. 解析子节点 parseChildren(关键)
function parseChildren(
context: ParserContext,
mode: TextModes,
ancestors: ElementNode[]
): TemplateChildNode[] {
const parent = last(ancestors) // 获取当前节点的父节点
const ns = parent ? parent.ns : Namespaces.HTML
const nodes: TemplateChildNode[] = [] // 存储解析后的节点
// 当标签未闭合时,解析对应节点
while (!isEnd(context, mode, ancestors)) {/* 忽略逻辑 */}
// 处理空白字符,提高输出效率
let removedWhitespace = false
if (mode !== TextModes.RAWTEXT && mode !== TextModes.RCDATA) {/* 忽略逻辑 */}
// 移除空白字符,返回解析后的节点数组
return removedWhitespace ? nodes.filter(Boolean) : nodes
}
- parseChildren函数接收三个参数,context解析器上下文,mode文本数据类型,ancestors祖先节点数据。
- 函数执行首先会从祖先节点中获取当前节点的父节点,确定命名空间,以及创建一个空数组,用来存储解析后的节点。
- 之后会有一个while循环,判断是否到达了标签的关闭位置,如果不是需要关闭的标签,则在循环体内对源模版字符串进行分类解析。
- 之后会有一段处理空白字符的逻辑,处理完成后返回解析好的nodes数组。
while循环内的逻辑(函数的核心):
- 在while中会判断文本数据的类型,只有当TextModes为DATA或RCDATA时会继续往下解析。
- 第一种情况就是判断是否需要解析Vue模版语法中的
Mustache语法,如果当前上下文中没有v-pre指令来跳过表达式,并且源模版字符串是以我们指定的分隔符开头的,就会进行双大括号的解析。 - 接下来会判断,如果第一个字符是
<并且第二个字符是!,会尝试解析注释标签,和这三种情况,对于DOCTYPE会进行忽略,解析成注释。 - 之后会判断当第二个字符是
/的情况,已经满足了一个闭合标签的条件了,所以会尝试匹配闭合标签。当第三个标签是>,缺少了标签名字,会报错,并让解析器的进度前进三个字符,跳过。 - 如果是
,并且第三个字符是小写英文字符,解析器会解析结束标签。 - 如果源模版字符串的第一个字符是
<,第二个字符是小写英文字符开头,会调用parseElement函数来解析对应的标签。 - 当这个判断字符串字符的分支条件结束,并且没有解析出任何node节点,则会将node作为文本类型,调用parseText进行解析。
- 最后将生成的节点添加进nodes数组,在函数结束时返回。
- 第一种情况就是判断是否需要解析Vue模版语法中的
while循环的源码如下:
while (!isEnd(context, mode, ancestors)) {
const s = context.source
let node: TemplateChildNode | TemplateChildNode[] | undefined = undefined
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
if (!context.inVPre && startsWith(s, context.options.delimiters[0])) {
/* 如果标签没有 v-pre 指令,源模板字符串以双大括号 `{{` 开头,按双大括号语法解析 */
node = parseInterpolation(context, mode)
} else if (mode === TextModes.DATA && s[0] === '<') {
// 如果源模板字符串的第以个字符位置是 `!`
if (s[1] === '!') {
// 如果以 '