Vue2.0模板编译原理
一、模板编译
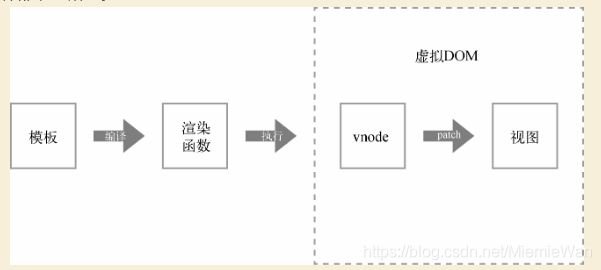
Vue.js通过编译将模板转换成渲染函数(render),执行渲染函数就可以得到一个虚拟节点树,使用这个虚拟节点树就可以渲染页面。
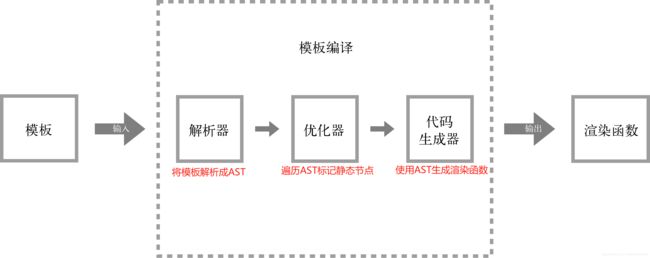
模板编译成渲染函数分为三部分(解析器、优化器、代码生成器):
- 将模板解析成AST(Abstract Syntax Tree,抽象语法树)
- 遍历AST标记静态节点。这样在虚拟DOM中更新节点时,如果发现有静态标记,则不会重新渲染它。
- 使用AST生成渲染函数
二、解析器
解析器内部分了好几个子解析器,比如HTML解析器、文本解析器以及过滤器解析器,其中最主要的是HTML解析器。
1.HTML解析器的作用:是解析HTML,它在解析HTML的过程中会不断触发各种钩子函数。这些钩子函数包括开始标签钩子函数、结束标签钩子函数、文本钩子函数以及注释钩子函数。
伪代码如下:
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
// 每当解析到文本时,触发该函数
},
comment (text) {
// 每当解析到注释时,触发该函数
}
})例:
我是Berwin
当上面这个模板被HTML解析器解析时,所触发的钩子函数依次是:start 、start 、chars 、end 和end 。
2.在钩子函数中构建AST节点
在start 钩子函数中构建元素类型的节点,在chars钩子函数中构建文本类型的节点,在comment 钩子函数中构建注释类型的节点。
当HTML解析器不再触发钩子函数时,就说明所有模板都解析完毕,所有类型的节点都在钩子函数中构建完成,即AST构建完成。
- 钩子函数
start有三个参数,分别是tag、attrs和unary,它们分别说明标签名、标签的属性以及是否是自闭合标签。 - 文本节点的钩子函数
chars和注释节点的钩子函数comment都只有一个参数,只有text。这是因为构建元素节点时需要知道标签名、属性和自闭合标识,而构建注释节点和文本节点时只需要知道文本即可。
3.AST层级关系
用栈来记录AST层级关系,这个层级关系也可以理解为DOM的深度。
HTML解析器在解析HTML时,是从前向后解析。每当遇到开始标签,就触发钩子函数start 。每当遇到结束标签,就会触发钩子函数end 。
基于HTML解析器的逻辑,我们可以在每次触发钩子函数start 时,把当前构建的节点推入栈中;每当触发钩子函数end 时,就从栈中弹出一个节点。
这样就可以保证每当触发钩子函数start 时,栈的最后一个节点就是当前正在构建的节点的父节点.
三、HTML解析器
1.解析HTML模板的过程就是循环的过程,简单来说就是用HTML模板字符串来循环,每轮循环都从HTML模板中截取一小段字符串,然后重复以上过程,直到HTML模板被截成一个空字符串时结束循环,解析完毕。
被截取的片段分很多种类型,如
- 开始标签,例如
- 结束标签,例如
- 结束标签,例如
- HTML注释,例如
。 - DOCTYPE,例如
。 - 条件注释,例如
我是注释。 - 文本,例如
我是Berwin。
四、文本解析器
1. 文本解析器的作用:是对HTML解析器解析出来的文本进行二次加工。
HTML解析器在解析文本时,并不会区分文本是否是带变量的文本。如果是纯文本,不需要进行任何处理;但如果是带变量的文本,那么需要使用文本解析器进一步解析。因为带变量的文本在使用虚拟DOM进行渲染时,需要将变量替换成变量中的值。
2.文本解析的过程
(1)使用正则表达式来判断文本是否为带变量的文本,也就是检查文本中是否包含 {{xxx}} 这样的语法。如果是纯文本,则直接返回undefined ;如果是带变量的文本,再进行二次加工。
function parseText (text) {
const tagRE = /\{\{((?:.|\n)+?)\}\}/g
if (!tagRE(text)) {
return
}
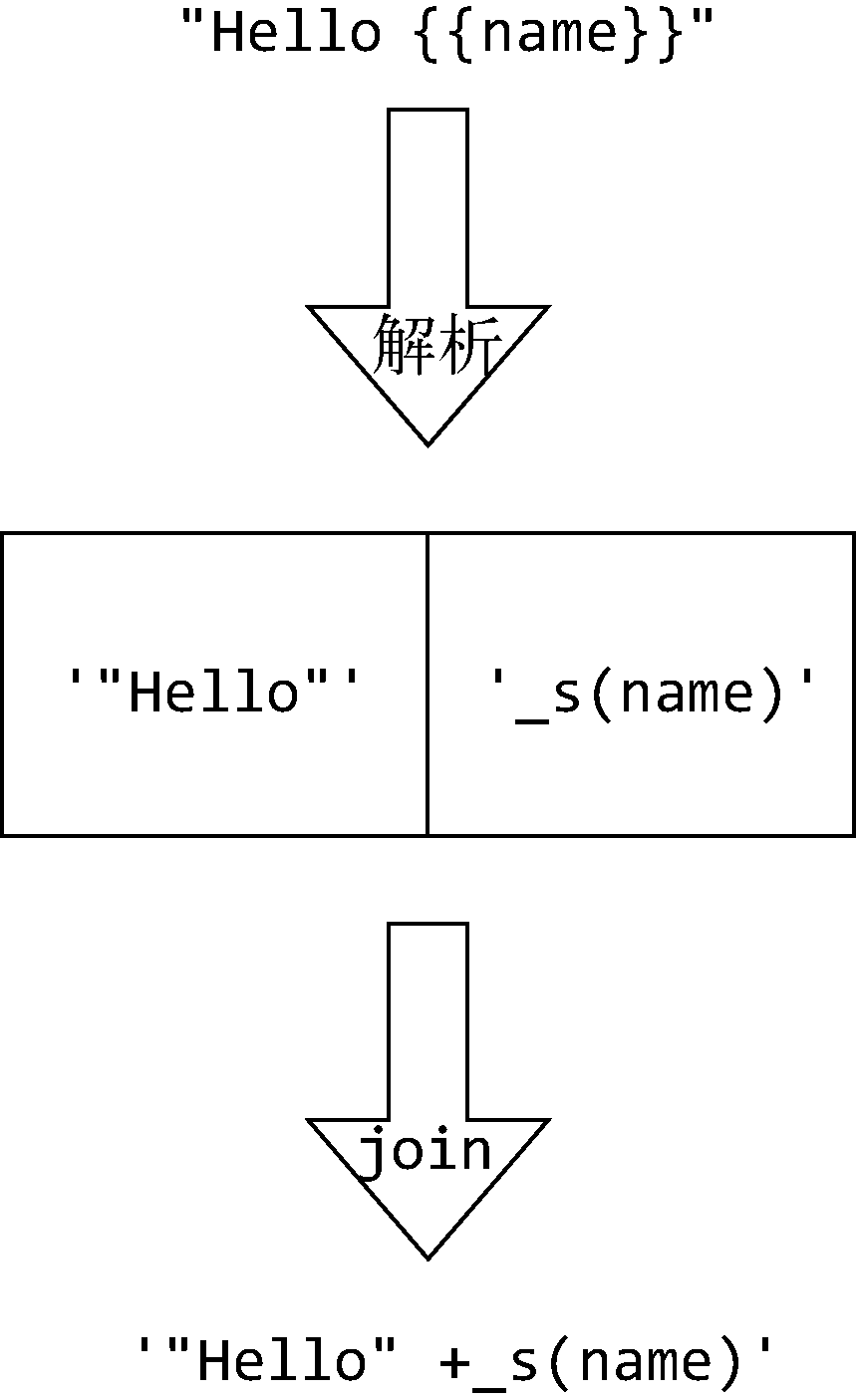
}(2)如果是带变量的文本,则先把变量左边的文本添加到数组中,然后把变量改成 _s(x) 这样的形式也添加到数组中。如果变量后面还有变量,则重复以上动作,直到所有变量都添加到数组中。如果最后一个变量的后面有文本,就将它添加到数组中。
五、优化器
1.优化器的作用:是在AST中找出静态子树并打上标记。
静态子树指的是那些在AST中永远都不会发生变化的节点。例如,一个纯文本节点就是静态子树,而带变量的文本节点就不是静态子树,因为它会随着变量的变化而变化。
2.标记静态子树的两点好处:
- 每次重新渲染时,不需要为静态子树创建新节点。在重新渲染时并不会生成新的子节点树,而是克隆已存在的静态子树。
- 在虚拟DOM中打补丁(patching)的过程可以跳过。如果两个节点都是静态子树,就不需要进行对比与更新DOM的操作,直接跳过。
3.优化器的内部实现主要分为两个步骤:
(1) 在AST中找出所有静态节点并打上标记;优化后,AST中增加static 属性。(静态节点:所有子节点都为静态节点)
(2) 在AST中找出所有静态根节点并打上标记。优化后,AST中增加staticRoot 属性。(静态根节点:所有子节点都为静态节点,父节点为动态节点)