HTTP 请求之合并与拆分技术详解

作者:darminzhou,腾讯 CSIG 前端开发工程师
导语:HTTP/2 中,是否还需要减少请求数?来看看实验数据吧。
1. 背景
随着网站升级 HTTP/2 协议,在浏览页面时常常会发现页面的请求数量很大,尤其是小图片请求,经典的雅虎前端性能优化军规中的第 1 条就是减少请求数,在 HTTP/1.1 时代合并雪碧图是这种场景减少请求数的一大途径,但是现在这些图片是使用 HTTP/2 协议传输的,这种方式是否也适用?另外,在都使用 HTTP/2 的情况,在浏览器并发这么多小图片请求时,是否会影响其他静态资源的拉取速度(例如页面 js 文件的请求耗时)?

基于上面问题的思考,本文进行了一个简单的实验,尝试通过数据来分析 HTTP 中的合并与拆分,以及并发请求是否影响其他请求。通过这次的实验我们对比了以下几个不同 HTTP 场景的耗时数据:
HTTP/1.1 合并 VS 拆分
HTTP/1.1 VS HTTP/2 并发请求
HTTP/2 合并 VS 拆分
浏览器并发 HTTP/2 请求数(大量 VS 少量)时,其他请求的耗时
2. 实验准备
理论:合并与拆分都是 HTTP 请求优化的常用方法,合并主要为了减少请求数,可以减少多次建立 TCP 连接耗时,不过相对的,缓存命中率会受到影响;拆分主要为了利用并发能力,浏览器可以并发多个 TCP 连接,还可以结合 HTTP/1.1 中的长链接,不过受 HTTP 队头阻塞影响,并发能力并不强,于是 HTTP/2 协议出现,使用多路复用、头部压缩等技术很好的解决了 HTTP 队头阻塞问题,实现了较强的并发能力。而 HTTP/2 由于基于 TCP,依然无法绕过 TCP 队头阻塞问题,于是又出现了 HTTP/3,不过本文并不讨论 HTTP/3,有兴趣的同学可以自行 Google。实验环境:
 为了避免自己搭服务器可能存在的性能影响,实验中的图片资源数据使用腾讯云的 COS 存储,并开启了 CDN 加速。
为了避免自己搭服务器可能存在的性能影响,实验中的图片资源数据使用腾讯云的 COS 存储,并开启了 CDN 加速。
3. 实验分析
第一个实验:有 2 个 HTML。1 个 HTML 中并发加载 361 张小图片,记录所有图片加载完成时的耗时;另 1 个 HTML 加载合并图并记录其耗时。并分别记录基于 HTTP/1.1 和 HTTP/2 协议的不同限速情况的请求耗时情况。每个场景测试 5 次,每次都间隔一段时间避免某一时间段网络不好造成的数据偏差,最后计算平均耗时。实验数据:
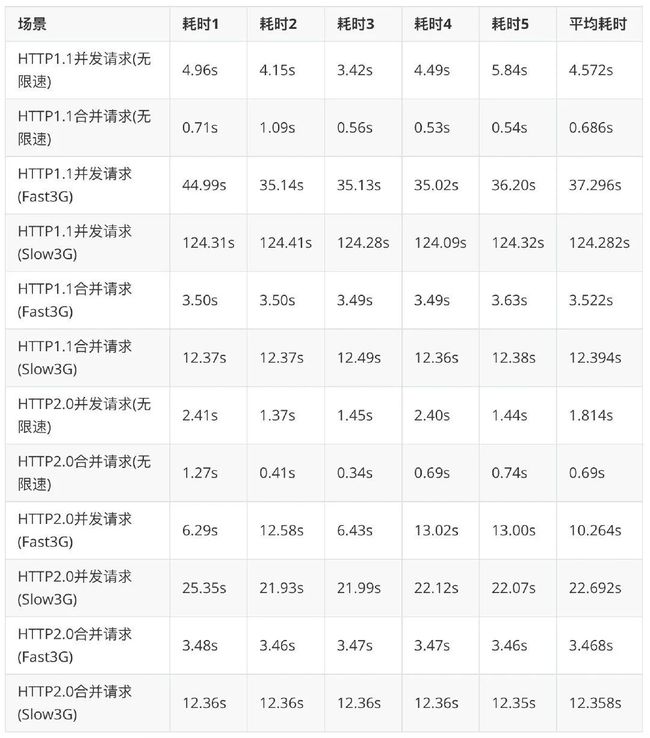
3.1 HTTP/1.1 合并 VS 拆分
根据上面实验数据,抽出其中 HTTP/1.1 的合并和拆分的数据来看,很明显拆分的多个小请求耗时远大于合并的请求,且网速较低时差距更大。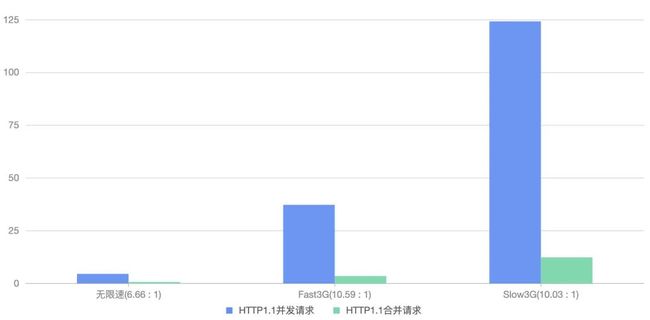
HTTP/1.1 合并请求的优化原理
简单看下 HTTP 请求的主要过程:DNS 解析(T1) -> 建立 TCP 连接(T2) -> 发送请求(T3) -> 等待服务器返回首字节(TTFB)(T4) -> 接收数据(T5)。

从上面请求过程中,可以看出当多个请求时,请求中的 DNS 解析、建立 TCP 连接等步骤都会重复执行多遍。那么如果合并 N 个 HTTP 请求为 1 个,理论上可以节省(N-1)* (T1+T2+T3+T4) 的时间。当然实际场景并没有这么理想,比如浏览器会缓存 DNS 信息,因此不是每次请求都需要 DNS 解析;比如 HTTP/1.1 keep-alive 的特性,使 HTTP 请求可以复用已有 TCP 连接,所以并不是每个 HTTP 请求都需要建立新的 TCP 连接;再比如浏览器可以并行发送多个 HTTP 请求,同样可能影响到资源的下载时间,而上面的分析显然只是基于同一时刻只有 1 个 HTTP 请求的场景。
感兴趣深入了解的可以参考网上一篇HTTP/1.1 详细实验数据,其结论是:当文件体积较小的时候,(网络延迟低的场景下)合并后的文件的加载耗时明显小于加载多个文件的总耗时;当文件体积较大的时候,合并请求对于加载耗时没有明显的影响,且拆分资源可以提高缓存命中率。但是注意有特殊的场景,由于合并资源后可能导致网络往返次数的增加,当网络延迟很大时,是会增大耗时的(参考 TCP 拥塞控制)。
【扩展:TCP 拥塞控制】 TCP 中包含一种称为拥塞控制的机制,拥塞控制的主要工作是确保网络不会同时被过多的数据传输导致过载。当前拥塞控制的方法有许多,主要原理是慢启动,例如,开始阶段只发送一点数据,观察是否能通过,如果能接收方将确认发送回发送方,只要所有数据都得到确认,发送方就在下次 RTT 时将发送数据量加倍,直到观察到丢包事件(丢包意味着过载,需要后退),每次发送的数据量即拥塞窗口,就是这样动态调整拥塞窗口来避免拥塞。拥塞控制机制对每个 TCP 连接都是独立的。
3.2 HTTP/1.1 VS HTTP/2 并发请求
抽出实验数据中的 HTTP/1.1 和 HTTP/2 并发请求来对比分析,可以看出 HTTP/2 的并发总耗时明显优于 HTTP/1.1,且网速越差,差距越大。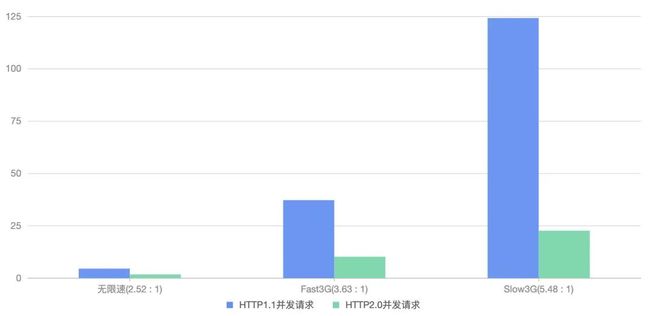
HTTP/2 多路复用和头部压缩的原理
多路复用 :在一个 TCP 链接中可以并行处理多个 HTTP 请求,主要是通过流和帧实现,一个流代表一个 HTTP 请求,每个 HTTP 资源拆分成一个个的帧按顺序进行传输,不同流的帧可以穿插传输,最终依然能根据流 ID 组合成完整资源,以此实现多路复用。帧的类型有 11 种,例如 headers 帧(请求头/响应头),data 帧(body),settings 帧(控制传输过程的配置信息,例如流的并发上限数、缓冲容量、每帧大小上限)等等。
头部压缩 :为了节约传输消耗,通过压缩的方式传输同一个 TCP 链接中不同 HTTP 请求/响应的头部数据,主要利用了静态表和动态表来实现,静态表规定了常用的一些头部,只用传输一个索引即可表示,动态表用于管理一些头部数据的缓存,第一次出现的头部添加至动态表中,下次传输同样的头部时就只用传输一个索引即可。由于基于 TCP,头部帧的发送和接收后的处理顺序是保持一致的,因此两端维护的动态表也就保证一致。
多路复用允许一次 TCP 链接处理多次 HTTP 请求,头部压缩又大大减少了多个 HTTP 请求可能产生的重复头部数据消耗。因此 HTTP/2 可以很好的支持并发请求,感兴趣可以深入 HTTP/2 浏览器源码分析。
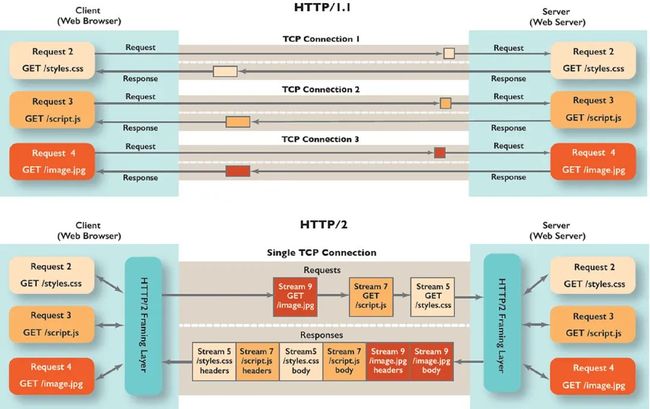
【扩展:队头阻塞】 HTTP/2 解决了 HTTP/1.1 中 HTTP 层面(应用层)队头阻塞的问题,但是由于 HTTP/2 仍然基于 TCP,因此 TCP 层面的队头阻塞依然存在。HTTP/3 使用 QUIC 解决了 TCP 队头阻塞的问题。感兴趣可以看看队头阻塞这篇文章。
HTTP 层面的队头阻塞在于,HTTP/1.1 协议中同一个 TCP 连接中的多个 HTTP 请求只能按顺序处理,方式有两种标准,非管道化和管道化两种,非管道化方式:即串行执行,请求 1 发送并响应完成后才会发送请求 2,一但前面的请求卡住,后面的请求就被阻塞了;管道化方式:即请求可以并行发出,但是响应也必须串行返回(只提出过标准,没有真正应用过)。

TCP 层面的队头阻塞在于,TCP 本身不知道传输的是 HTTP 请求,TCP 只负责传递数据,传递数据的过程中会将数据分包,由于网络本身是不可靠的,TCP 传输过程中,当存在数据包丢失的情况时,顺序排在丢失的数据包之后的数据包即使先被接收也不会进行处理,只会将其保存在接收缓冲区中,为了保证分包数据最终能完整拼接成可用数据,所丢失的数据包会被重新发送,待重传副本被接收之后再按照正确的顺序处理它以及它后面的数据包。
But,由于 TCP 的握手协议存在,TCP 相对比较可靠,TCP 层面的丢包现象比较少见,需要明确的是,TCP 队头阻塞是真实存在的,但是对 Web 性能的影响比 HTTP 层面队头阻塞小得多,因此 HTTP/2 的性能提升还是很有作用的。
HTTP/2 中存在 TCP 的队头阻塞问题主要由于 TCP 无法记录到流 id,因为如果 TCP 数据包携带流 id,所丢失的数据包就只会影响数据包中相关流的数据,不会影响其他流,所以顺序在后的其他流数据包被接收到后仍可处理。出于各种原因,无法改造 TCP 本身,因此为了解决 HTTP/2 中存在的 TCP 对头阻塞问题,HTTP/3 在传输层不再基于 TCP,改为基于 UDP,在 UDP 数据帧中加入了流 id 信息。
3.3 HTTP/2 合并 VS 拆分
由于 HTTP/2 支持多路复用和头部压缩,是不是原来 HTTP/1.1 中的合并请求的优化方式就没用了,在 HTTP/2 中合并雪碧图有优化效果吗?
抽出 HTTP/2 的合并和拆分的数据来看,拆分的多个小请求耗时仍大于合并的请求,不过差距明显缩小了很多。 那么为什么差距还是挺大呢?理论上 HTTP/2 的场景下,带宽固定,总大小相同的话,拆分的多个请求最好的情况应该是接近合并的总耗时的才对吧。
那么为什么差距还是挺大呢?理论上 HTTP/2 的场景下,带宽固定,总大小相同的话,拆分的多个请求最好的情况应该是接近合并的总耗时的才对吧。
分析一下,因为是复用一个 TCP 连接,所以首先排除重复 DNS 查询、建立 TCP 连接这些影响因素。那么再分析一下资源大小的影响:
本身合并的图片(516kB)就比拆分的 361 张小图片总大小(总 646kB)要小。
拆分的很多个小请求时,虽然有头部压缩,但是请求和响应中的头部数据以及一些 settings 帧数据还是会多一些。通过查看 chrome 的 transferred 可以知道小图片最终总传输数据 741kB,说明除 body 外多传输了将近 100kB 的数据。
结合上面两点,理论上拆分的小图片总耗时应该是合并图片的耗时的(741/516=)1.44 倍。但是很明显测试中各网速场景下拆分的小图片总耗时与合并图片耗时的比值都大于 1.44 这个理论值(2.62、2.96、1.84)。其中的原因这里有两点推测:
并发多个请求的总耗时计算的是所有请求加载完的耗时,每个请求都有发送和响应过程,其中分为一个个帧的传输过程,只要其中某小部分发生阻塞,就会拖累总耗时情况。
浏览器在处理并发请求过程存在一定的调度策略而导致。推测的依据来自 Chrome 开发者工具中的 Waterfall,可以看到很多并发请求的 Queueing Time、Stalled Time 很高,说明浏览器不会在一开始就并行发送所有请求。

不过这里只属于猜测,还未深入探究。
3.4 浏览器并发 HTTP/2 请求数(大量 VS 少量)时,其他请求的耗时
第二个实验:在 HTML 中分别基于 HTTP/2 加载 360+张小图片、130+张小图片、20+张小图片、0 张小图片,以及 1 张大图片和 1 个 js 文件,大图片在 DOM 中放在所有小图片的后面,图片都是同域名的,js 文件是不同域名的,然后记录大图片和脚本的耗时,同样也是利用 Chrome 限速工具在不同的网络限速下测试(不过这个连的 WIFI 与第一个实验中不同,无限速时的网速略微不同)。这个实验主要用于分析并发请求过多时是否会影响其他请求的访问速度。实验数据:
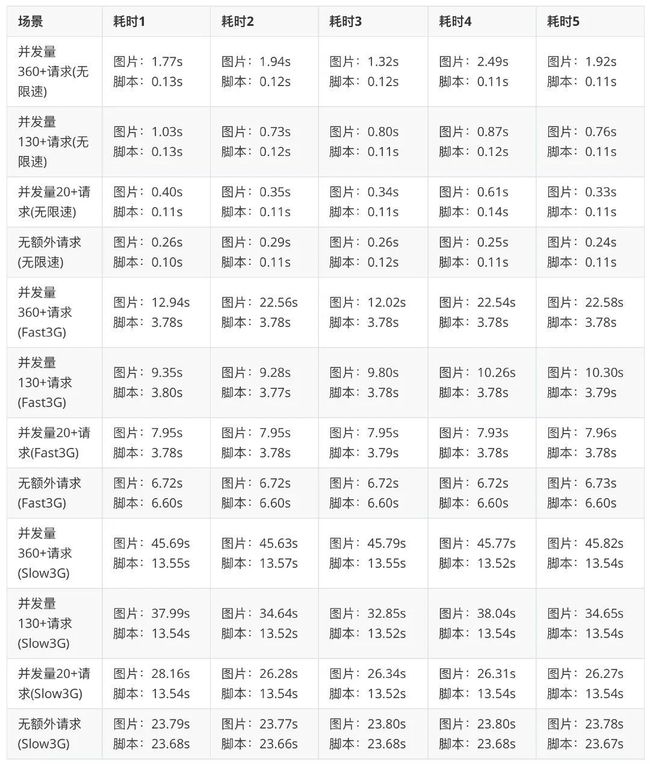
从实验数据中可以看出,
图片并发数量不会影响 js 的加载速度,无限速时无论并发图片请求有多少,脚本加载都只要 0.12s 左右。
很明显对大图片的加载速度有影响,可以看到并发量从大到小时,大图片的耗时明显一次减少。
但是其中也有几个反常的数据:Fast3G 和 Slow3G 的网速限制下,无小图片时的 js 加载耗时明显高于有并发小图片请求的 js 加载耗时。这是为啥?我们推测这里的原因是,由于图片和 js 不同域名,分别在两个 TCP 连接中传输,两个 TCP 是分享总网络带宽的,当有多个小图片时,小图片在 DOM 前优先级高,js 和小图片分享网络带宽,js 体积较大占用带宽较多,而无小图片时,js 是和大图片分享网络带宽,js 占用带宽比率变小,因此在限速时带宽不够的情况下表现出这样的反常数据。
4. 实验结论
HTTP/1.1 中合并请求带来的优化效果还是明显的。
对于多并发请求的场景 HTTP/2 比 HTTP/1.1 的优势也是挺明显的。不过也要结合具体环境,HTTP/2 中由于复用 1 个 TCP 链接,如果并发中某一个大请求资源丢包率严重,可能影响导致整个 TCP 链路的流量窗口一直很小,而这时 HTTP/1.1 中可以开启多个 TCP 链接可能其他资源的加载速度更快?当然这也只是个人猜测,没有具体实验过。
HTTP/2 中合并请求耗时依然会比拆分的请求总耗时低一些,但是相对来说效果没有 HTTP/1.1 那么明显,可以多结合其他因素,例如拆分的必要性、缓存命中率需求等,综合决策是否合并或拆分。
网速较好的情况下,非同域名下的请求相互间不受影响,同域名的并发请求,随着并发量增大,优先级低的请求耗时也会增大。
不过,本文中的实验环境较为有限,说不定换了一个环境会得到不同的数据和结论?比如不同的浏览器(Firefox、IE 等)、不同的操作系统(Windows、Linux 等)、不同的服务端能力以及不同测试资源等等,大家感兴趣也可以抽点时间试一试。
5. 其他思考
以上讨论主要针对低计算量的静态资源,那么高计算量的动态资源的请求呢,(例如涉及鉴权、数据库查询之类的),合并 vs. 拆分?
关于我们
我们团队主要致力于前端相关技术的研究和在腾讯业务的应用,团队内部每周有内部分享会,有兴趣的读者可以加入我们或者参与一起讨论,微信 : darminzhou; camdyzeng。
视频号最新视频