P18 神经网络专题——卷积层
再来读文档

inchannel 输入通道数
outchannel 输出通道数(卷积核个数)
kernel_size 卷积核大小
stride=1 卷积过程路径大小
padding 卷积过程是否进行padding操作
dilation 卷积核中的对应位距离
groups分组卷积一般为 1
bias偏置 一般为True
padding_mode=一般默认是0
一、概念讲解L:

inchannel 输入通道数 一般彩色是3通道
outchannel 输出通道数
kernel_size 卷积核大小 一般数字或元组。如果设3,那就是3×3的卷积核 也可以用元组(1,2)1×2
stride=1 卷积过程(横纵向)路径大小
padding 卷积过程是否进行padding操作
dilation 卷积核中的对应位距离 不常用
groups分组卷积一般为 1
bias偏置 一般为True
padding_mode=一般默认是0
卷积核的值会根据分布选****
1、如果还模糊,可以点击link

发现挺直观的

2、关于out_channel
当令其=2的时候,会用两个卷积核对输出进行卷积。
当然这两个卷积核里面的东西是可以不一样的

二、代码实践:
1、
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
dataset=torchvision.datasets.CIFAR10("./P18_juanji_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
//这里CIFAR10返回的结果就是imgs,targets//
//这里复习 dataset用法,同目录创建文件夹,下载测试集,转换成tensor类型,下载//
dataload=DataLoader(dataset,batch_size=64)
//dataloader作用=抓牌,一次64张//
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 =Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
//定义函数,输入是三通道,6个卷积核计算,卷积核大小3×3,步长为1//
def forward(self,x):
x=self.conv1(x)
return x
tudui=Tudui()
//实例化//
print(tudui)
看下结果
Using downloaded and verified file: ./P18_juanji_data\cifar-10-python.tar.gz
Extracting ./P18_juanji_data\cifar-10-python.tar.gz to ./P18_juanji_data
Tudui(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)
可见有个神经网络叫tudui
里包含了一个卷积层叫 conv1,卷积层里参数见上文
2、在上面的基础上使用tudui
for data in dataload:
imgs,targets=data
output=tudui(imgs)
print(imgs.shape)
print(output.shape)
可以看到通道从imgs输入的3变成了
output的6
经过卷积操作后,图像变成了30×30

3、为了进一步感受,我们用SummarWriter来看下:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
//新加//
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./P18_juanji_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataload=DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 =Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
tudui=Tudui()
print(tudui)
//新加。//
writer= SummaryWriter("P18_logs")
step=0
for data in dataload:
imgs,targets=data
output=tudui(imgs)
writer.add_images("input_imgs",imgs,step)
writer.add_images("output",output,step)
step=step+1
结果报错辣
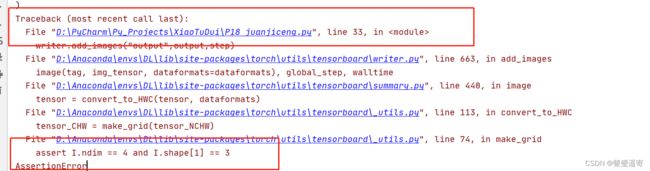
主要原因在于:
add_imgs通道要求是3
而我们的output通道数是6
修改方案:
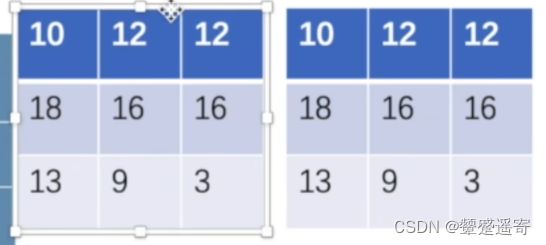
举例子:
1、本来是如图所示的 叠加两个channel:

2、现在我们想让他变成1个channel,那就可以拼接,成一个大块,这样的话batchsize会增多:
**3、代码:**但是具体batchsize增多到多少我们不知道,所以可以先改成-1

import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./P18_juanji_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataload=DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 =Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
tudui=Tudui()
print(tudui)
writer= SummaryWriter("P18_logs")
step=0
for data in dataload:
imgs,targets=data
output=tudui(imgs)
writer.add_images("input_imgs",imgs,step)
//这里关键//
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step=step+1
writer.close()
终端:

ok我们看下结果:
可以观察到outpout变成好多不只64张了

三、其他补充:

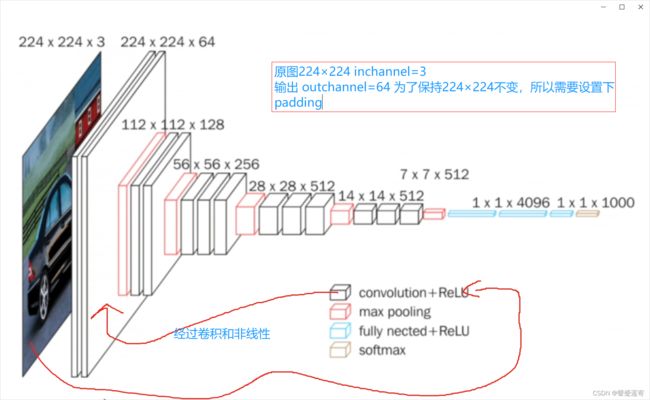
另外:以VGG为例: