linux系统负载--system load
系统负载定义
处于runnable或uninterruptable状态的进程数。
runnable表示正在使用CPU或者等待使用CPU
uninterruptable表示等待IO访问,比如等待磁盘,这种状态不可通过信号来中断,除非重启系统。
如何查看系统平均负载
方式1: cat /proc/loadavg
[[email protected] ~]# cat /proc/loadavg
9.98 10.13 9.81 35/10453 93324
#前三项表示最近1分钟、5分钟、15分钟linux的平均负载
方式2:uptime命令
[[email protected] ~]# uptime
19:35:05 up 5 days, 3:23, 1 user, load average: 8.97, 9.89, 9.74
#load average字段表示最近1分钟、5分钟、15分钟linux的平均负载
方式3: top命令
#load average字段表示最近1分钟、5分钟、15分钟linux的平均负载
[[email protected] ~]# top
top - 19:35:12 up 5 days, 3:23, 1 user, load average: 8.72, 9.81, 9.72
Tasks: 8 total, 1 running, 7 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4194304 total, 2699348 free, 1326748 used, 168208 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2867556 avail Mem
多少算负载高?
结论,参考依据(官方):
- “系统负载 = CPU逻辑核数 * 0.7” --开始关注
- “系统负载 = CPU逻辑核数 * 1.0” --马上修复
- “系统负载 >= CPU逻辑核数 * 5.0” --已经开始出现比较严重的问题了
逻辑核 VS 物理核
假设一个总核数为8的CPU,它是2个4核CPU好还是4个2核CPU或者是8个单核CPU好?
对于system load这个指标而言,三种CPU组成效果等同于一样的。
即“2个4核CPU == 4个2核CPU == 8个1核CPU”
问题1:如何查看有多少CPU物理核?
grep -i "physical id" /proc/cpuinfo | sort | uniq | wc -l
问题2:如何查看有多少CPU逻辑核?
grep -i "processor" /proc/cpuinfo | sort | uniq | wc -l
如何排查system load average高的问题?
由于平均负载还包含了等待CPU和等待IO的进程,所以不一定和CPU使用率一致。
- 计算型,平均负载升高,CPU使用率升高
- IO型,平均负载升高,CPU使用率不一定升高
- 大量进程切换,平均负载升高,CPU使用率也可能升高
1.先确定 “system load average 持续大于 CPU总逻辑核数 *1”,若是,则可以确定是负载较高;
2.再看CPU使用率、CPU idle、CPU IO wait、内存等等指标是否正常,排除是否正常的业务逻辑导致CPU持续高负载
3.若CPU使用率很低、 CPU IO wait也很低,其他指标也很低,那可能是CPU上下文切换导致。
如: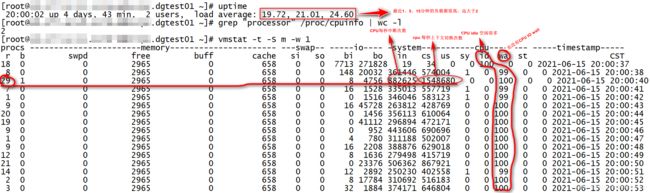
CPU状态良好的指标状态
1.CPU利用率:User Time <= 70%,System Time <= 35%,User Time + System Time <= 70%。
2.上下文切换:与CPU利用率相关联,越小越好。如果CPU利用率状态良好,大量的上下文切换也是可以接受的。
可运行队列:每个处理器的可运行队列<=3个线程。
in每秒CPU的中断次数,包括时间中断
cs每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
使用pidstat命令(yum install -y sysstat)查看CPU上下文切换详情
#查看进程状态
pidstat –w –u 1
pidstat –w –u –t 1
#其中-w是输出进程的数据指标 -u则是输出CPU的数据指标 -t输出线程的数据指标
参考文档:
https://scoutapm.com/blog/understanding-load-averages