java中级高级面试题目会总记录
文章目录
-
- 阿里开发手册的相关的规范 important
-
- 1.sychoronized 和Lock()的区别?
- 2.SpringMVC的执行流程?
- 3.java中保证线程安全的方式?
- 4.使用Volatile能保证线程A安全吗?
- 5.java中创建线程的方式?
- 6.导致Spring中事务失效的情况?
- 7.什么是事务?Spring事务的传播行为有哪些?
- 8.AutoWired和Resource的区别?
- 9.@SpringBootApplication 注解?
-
- 9.1SpringBoot的自动装配?
- 9.2 1.@Scope注解是什么
- 9.22 Spring默认的Bean是线程安全的吗?怎么解决线程不安全问题?
- 9.23 Spring如何保证不会出现线程不安全的问题呢?
- 9.24 SpringBoot Starter机制和原理?
- 10.sleep()和wait()方法区别?
- 15:java面向对象编程的特征?
- 16:设计模式的迪米特法则(最少知道原则)?
- 17.单例模式的几种实现
-
- 饿汉式(推荐使用,但是更加推荐使用double if 判断的懒汉模式):
- 懒汉式:
- 懒汉升级式(双重if判断,推荐使用):
- 静态内部类形式(外面的内进行创建的时候,里面的静态内部类是不会进行创建的,但是你需要 使用它里面的东西是会被创建,相当于懒加载) 推荐使用
- 枚举模式 推荐使用,可以防止反序列化,创建新的对象 :
- 18.java设计模式的七大原则
- 19JDK(java SE Development) ,JRE(java Runtime Environment),JVM(java Virtual Mechine) java 虚拟机?
- 20:String,StringBuilder,StringBuffer区别?
- 20. 如何不改变String地址引用的情况下,改变String的值?
- 21 Integer的享元模式?
- 22.mysql的搜索引擎b+树?
-
- 22.1 truncate 和delete区别?
- 23 Hashtable和HashMap的不同?
-
- 1.安全性:
- 2.是否可以使用null作为key?
- 3.默认容量,及如何扩容?
- 23 java的强,软,弱,虚引用?
- 24 ThreadLocal?
- 25 CocurrentHashMap jdk1.7和jdk1.8的区别?
- 26SpringAop有哪几种通知类型?
- 27 HashMap的jdk1.7和jdk1.8区别?
- 28 Innodb 如何支持范围查询能走索引的?
- 30 什么是代理模式?有哪几种? 为什么要使用?
- 31 静态代理怎么使用?
-
- 32 动态代理?
- 33 深拷贝和浅拷贝?
- Mysql系列
-
- 32. mysql事务隔离级别?
-
- 32.1说一下 spring 的事务隔离?
- 32.1 Spring 管理事务的方式有几种?
- 32.2 Transactional(rollback = Exception.class)注解了解吗?
-
- 项目中的code使用:
- 33. 导致mysql的慢查询?
- 34. 索引设计原则?
- 35 MyisAM 与InnoDb区别?
- 36什么时候用mysql里面的关键字in 和exists 区别,Not exists 和 Not In使用哪个?
- 37 数据结构时间复杂度怎么计算的?冒泡排序计算时间时间度?o(n2)
- 38 redis缓存里面用了什么设计模式?redis使用的时候为什么不共用同一个key好点?
- 39 模板方法模式是什么?
- 40 static关键理解?
- 41.自定义运行时异常的类?同样如何自定义类加载器?
- 42 JUC的常见面试题目
-
- 相关题目图片:
- 1. 谈谈对volatile关键字的理解,
-
- 是java虚拟机提供的一个轻量级同步机制。相当于一个轻量级的sychronized.
- 1.1 它不保证原子性,是不保证线程安全
- 1.2 可以防止指令重排,底层通过内存屏障进行保证,进行读写的屏障。
- 1.3可以保证可见性,对于共享变量的修改对于其他的所有的线程是可见的。
- 2 谈谈JMM(java内存模型)英文 Java Memory Model?
- 3. CAS原理?为什么不使用sychronized而使用CAS?
- 43java创建对象的方式?
- 44 JVM的内存结构?
- 45 谈谈JMM(java内存模型)英文 Java Memory Model?
- 46. 创建线程池有哪几种方式?
- 47. 线程池都有哪些状态?
- 48. 线程池中 submit()和 execute()方法有什么区别?
- 49. 在 java 程序中怎么保证多线程的运行安全?
- 50. 怎么实现动态代理?
- 51Spring源码系列
-
- 1. BeanFactory 和FactoryBean有什么区别?
- 52 SpringAop面向切面编程?
- 53熟悉常见排序的相关的时间复杂度和空间复杂度,和怎么计算?
-
- 53.1对数器,使用已知正确的算法和你自己写的算法进行比较对数
- 53.2 insert排序把每个数往前面进行插入的排序
- 53.3 选择排序
- 53.4 归并排序 重要
- 53.4 快速排序
- 53.5 堆排序
- 53.6 计数排序
- 54.接口幂等
- 55. Spring的循环依赖问题和解决?
- 57 Feign远程调用(1个线程)请求头header丢失问题解决
- 56 Feign远程异步使用CompletableFutrue异步调用订单相关信息(多个线程)请求头header丢失问题解决
- 57怎么判断是一个环形链表?
- 58 服务器端的参数怎么校验?
- 59 xxl-job和scheduling的区别?
- 60 sql一般怎么优化?
-
- range查询导致索引生效问题?
-
- 分页查询的优化
- 61 Redis的内存淘汰策略?
- 62 Redis的过期键(keys)的删除策略?
-
- 62.1 key的冲突问题解决?
- 62.2 怎么提高缓存的命中率?
- 63. Nginx的正向代理和反向代理的区别?
- 64 @Transactional注解导致的分布式事务问题?
-
- 64.1 mysql事务的隔离级别默认
- 64.2 mysql事务的传播行为
- 64.3 本地事务失效问题
- 65 RabbitMq延时队列(实现定时任务)
-
- 65.1 实现方式一 给队列设置过期时间(推荐使用)
- 65.3 实现方式二 给消息设置过期时间
- 65.4 订单超时取消解决方案
阿里开发手册的相关的规范 important
- pojo里面对名定义的属性用包装类型,里面的布尔类型变量不要加上is,RPC方法的返回值和参数必须使用包装数据类型(可以防止NPE(NullPointException))。
- POJO 类必须写 toString 方法。便于排查错误。
- 字符串拼接使用StringBuider或者StringBuffer. (不用String的原因?)和String的存储在位置有关
- 循环体内需要我们考虑性能, new,try–catch,定义变量,获取数据库连接等等这些操作不要在循环体内。
- 集合初始化时,指定集合初始值大小。不知道大小指定默认的capacity大小。因为resize会使Hash表重建,导致性能下降。(例如 Map map = new HashMap(16);
- 使用entrySet遍历Map类集合KV,而不是keySet方式进行遍历。
- camel命名规则。
1.sychoronized 和Lock()的区别?
- sych 是java关键字,lock是一个java类
- sychoronized适合修饰少量代码,lock适合大量代码
- sycho 是不可以获取锁的状态,lock可以
- 它们都是可重入锁,sychoznied 发生阻塞,会一直等待,lock不一定。
- lock手动打开锁,lock()方法释放通过 unlock();(finally{})
2.SpringMVC的执行流程?
- 前端发送一个请求
- DispatcherServlet进行接收,调用HandlerMapping去查找Handler(后端控制器),xml文件和注解进行查找
- 返回一个Handler
- DispatcherServlet调用HandlerAdpater去执行Handler
- 返回一个ModelAndView,SpringMvc的一个 底层对象,包括Model And view
- DispatcherServle调用视频 ViewResolver 解析和渲染
- 响应前端
3.java中保证线程安全的方式?
- 使用用sychronized或者Lock使用线程互斥同步
- 使用自旋CAS保证原子操作,实现共享变量的线程安全。
- 使用ThreadLocal来实现多个线程之间的数据隔离。
4.使用Volatile能保证线程A安全吗?
5.java中创建线程的方式?
- extends Thread类 重写run方法 通过start()方法进行调用线程 (不推荐使用,因为java是单继承)
- implements Runnable()
- implments Callable() 调用 call()方法,try 有返回值
- 创建线程池的方式,(1. 降低资源的消耗 2.提高效率 3,便于管理线程)
6.导致Spring中事务失效的情况?
- @Transational没有作用在public方法上面
- 这个类没有被Spring托管,@Service
- 调用了这个类的其他的方法
- propagation事务传播行为的参数配置错误
- rollBackfor参数配置错误
- 异常被catch()
- 数据库的搜索引擎不支持这个事务,数据库本身不支持事务
7.什么是事务?Spring事务的传播行为有哪些?
ACID属性automatic原子性 Isolation隔离性 Durability持久性 Consistency 一致性
8.AutoWired和Resource的区别?
1.Autowired是Spring提供的,只可以在spring框架中使用,Resource不是,Resource的使用范围更加广泛。
- Autowired是byType注入(required)多个同一类型的bean的时候,@Qualifire(value=“”),Resource默认是byName,但是如果没有name就会ByType进行注入, 参数name,type.
9.@SpringBootApplication 注解?
自动以SpringApplication
SpringApplication是springboot驱动spring应用上下文的引导类
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
...
}
@ComponentScan:扫描。它是什么版本引入的?Spring Framework3.1
@EnableAutoConfiguration :激动自动装配@Enable->@Enable开头的
9.1SpringBoot的自动装配?
可以看这个注解:@EnableAutoConfiguration注解,它也是一个复合注解。
(1)其中@Import(AutoConfigurationImportSelector.class)这个注解就是用于自动导入AutoConfigurationImportSelector这个类。
(2)然后AutoConfigurationImportSelector的selectImports()方法通过SpringFactoriesLoader.loadFactoryNames()扫描所有具有META-INF/spring.factories的jar包。其实每一个可以自动装配的jar里都有一个这样的spring.factories文件。
(3)接着就根据这个spring.factories文件里配置的所有JavaConfig自动配置类的全限定名,找到所有对应的class,然后将所有自动配置类加载到Spring容器中。spring.factories文件示例如下:
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,\
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration,\
org.springframework.boot.autoconfigure.batch.BatchAutoConfiguration,\
org.springframework.boot.autoconfigure.cache.CacheAutoConfiguration,\
org.springframework.boot.autoconfigure.cassandra.CassandraAutoConfiguration,\
org.springframework.boot.autoconfigure.cloud.CloudAutoConfiguration,\
org.springframework.boot.autoconfigure.context.ConfigurationPropertiesAutoConfiguration
....
9.2 1.@Scope注解是什么
@Scope注解是springIoc容器中的一个作用域,在 Spring IoC 容器中具有以下几种作用域:基本作用域singleton(单例)、prototype(多例),Web 作用域(reqeust、session、globalsession),自定义作用域
9.22 Spring默认的Bean是线程安全的吗?怎么解决线程不安全问题?
spring的bean默认是单例的,那么,意味着这个bean只会实例化一次,之后注入到各个component的都是同一个实例。这就是所谓的无状态Bean共享。那么当多个线程调用同一个bean的时候,就会存在线程安全问题。
9.23 Spring如何保证不会出现线程不安全的问题呢?
Spring是用了threadlocal来解决了这个问题。
threadlocal 是什么?
ThreadLocal是一个本地线程副本变量工具类。主要用于将私有线程和该线程存放的副本对象做一个映射,各个线程之间的变量互不干扰,在高并发场景下,可以实现无状态的调用,特别适用于各个线程依赖不通的变量值完成操作的场景。
ThreadLocal的机制:
每个Thread线程内部都有一个Map。
Map里面存储线程本地对象(key)和线程的变量副本(value)
但是,Thread内部的Map是由ThreadLocal维护的,由ThreadLocal负责向map获取和设置线程的变量值。
所以对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成了副本的隔离,互不干扰。
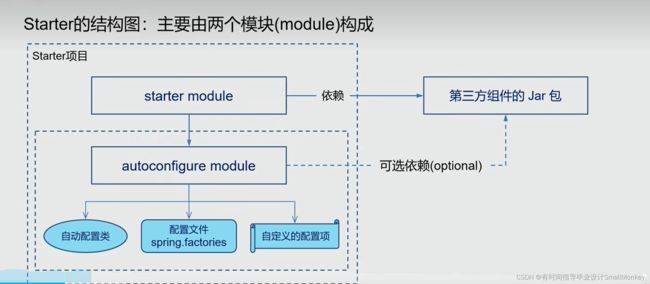
9.24 SpringBoot Starter机制和原理?
1.引入Spring-boot-starter-parent 里面会自动生成两个属性,properties,dependencyManageMent
2. 所有其他的starter会默认继承parent的版本号,比如spring-boot-starter-web 里面自动引入web模块开发需要的相关jar包

10.sleep()和wait()方法区别?
- sleep是thread类里面的方法,wait是Ojbect的的方法
- sleep()不会释放锁,wait()会释放锁
- sleep()休眠到指定时间线程会自动恢复,wait需要通过notify(),notifyAll()唤醒
- wait()需要在同步代码块中进行使用,比如sychronized()修改的同步代码块
- sleep()需要捕获异常,wait(),notify(),notifyAll()不需要
15:java面向对象编程的特征?
封装,继承,多态
封装:属性封装,方法封装。增强代码的可维护性。
继承:extends
多态:继承,重写,父类引用了子类对象。
16:设计模式的迪米特法则(最少知道原则)?
- 类和类之间保持最少的联系。
- 直接和直接朋友进行通信(局部变量的类不是直接朋友)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9eWlD65G-1655637153472)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220619112828368.png)]
17.单例模式的几种实现
概念:软件系统中只有该类的 单个实例,也就是代码中只可以new 一次,并且向其他的访问都提供一个访问该类的静态方法
使用场景:
Windows的Task Manager(任务管理器)就是很典型的单例模式(这个很熟悉吧)
多线程的线程池的设计一般也是采用单例模式,这是由于线程池要方便对池中的线程进行控制。
操作系统的文件系统,也是大的单例模式实现的具体例子,一个操作系统只能有一个文件系统。
网站的计数器,一般也是采用单例模式实现,否则难以同步。
java里面的 经常使用的工具类,比如时间类转换等等。
饿汉式(推荐使用,但是更加推荐使用double if 判断的懒汉模式):
package com.monkey.sigleton;
/*
* 饿汉模式:
* 类加载就实例化,JVM保证线程安全
* 推荐使用
* 唯一缺点: 不管使用与与否,类加载就会完成实例化
*
* */
public class HungryMode {
public static final HungryMode hungry = new HungryMode();
private HungryMode(){};
public static HungryMode getInstance(){ return hungry;};
public static void main(String[] args) {
HungryMode instance = HungryMode.getInstance();
HungryMode instance1 = HungryMode.getInstance();
System.out.println(instance == instance1);
}
}
懒汉式:
package com.monkey.sigleton;
/*
* lazy loading
* 也称懒汉模式
*
* 达到了按需初始化的目的,但是带来多个线程同时访问的时候不安全
*
* */
public class LazyMode {
private static LazyMode Instance;
private LazyMode(){};
public static LazyMode getInstance(){
if(Instance == null){
Instance = new LazyMode();
}
return Instance;
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(()->
System.out.println(LazyMode.getInstance())
).start();
}
}
}
懒汉升级式(双重if判断,推荐使用):
package com.monkey.sigleton;
public class LazyModeImprove {
private static LazyModeImprove Instance;
private LazyModeImprove(){};
private static LazyModeImprove getInstance(){
if(Instance == null){
synchronized (LazyModeImprove.class){
if(Instance == null){
Instance = new LazyModeImprove();
}
}
}
return Instance;
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(()->
System.out.println(Instance.getInstance())
).start();
}
}
}
静态内部类形式(外面的内进行创建的时候,里面的静态内部类是不会进行创建的,但是你需要 使用它里面的东西是会被创建,相当于懒加载) 推荐使用
public class LazyModeStaicInnerClass {
private LazyModeStaicInnerClass(){};
private static class SingletonInstance{
private static final LazyModeStaicInnerClass Instance = new LazyModeStaicInnerClass();
}
private static LazyModeStaicInnerClass getInstance(){
return SingletonInstance.Instance;
}
}
枚举模式 推荐使用,可以防止反序列化,创建新的对象 :
package com.monkey.sigleton;
public enum EnumMode {
INSTANCE;
public void hello(){
System.out.println("hello world");
}
public static void main(String[] args) {
INSTANCE.hello();
for (int i = 0; i < 100; i++) {
new Thread(()-> System.out.println(EnumMode.INSTANCE)).start();
}
}
}
18.java设计模式的七大原则
ocp(开闭原则):对外(功能扩展)开放,对修改关闭。
里氏替换原则:继承里面,子类不要重写父类的方法。
依赖倒转原则:面向接口编程。
单一职责原则:一个类实现一个功能,或者一个方法实现一种功能。
接口隔离原则:为各个类建立它们的专用接口,不要很多类使用一个共同接口。
迪米特法则:只和你的朋友谈,不要和陌生人接触。
合成复用原则:尽量先先使用组合或者聚合等关联关系来实现,其次考虑使用继承关系实现。
19JDK(java SE Development) ,JRE(java Runtime Environment),JVM(java Virtual Mechine) java 虚拟机?
JDK(java标准开发以包)> JRE >JVM
**JDK:**提供编译,运行java的所需的各种工具和资源,包括java编译器,JRE,和常用的java类库。
JRE:java运行时环境,用于运行java的字节码文件。
**JVM:**是JRE的一部分,负责运行字节码文件。
20:String,StringBuilder,StringBuffer区别?
-
都被final修饰不可以被继承
-
String如果每次被改变会重新的创建一个String对象,内存里面对象多了JVM通过GC回收。影响系统性能,如果需要经常改变String的长度应该使用的是StringBuilder.
-
StringBuiler和StringBuffer的区别?
区别1:StringBuffer都被Sychronized同步锁修饰,线程安全,效率相比(jdk1.5新增)StringBuilder低。
String str = "aaa"; str = "aaaaab";
区别2:缓冲区
StringBuffer 代码片段(被transient 修饰的变量不参与序列化和反序列化):
private transient char[] toStringCache;
@Override
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
StringBuilder 代码片段:
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
可以看出**,StringBuffer 每次获取 toString 都会直接使用缓存区的 toStringCache 值来构造一个字符串。**
而 StringBuilder 则每次都需要复制一次字符数组,再构造一个字符串。
所以,缓存冲这也是对 StringBuffer 的一个优化吧,不过 StringBuffer 的这个toString 方法仍然是同步的。
20. 如何不改变String地址引用的情况下,改变String的值?
// 在不改变str地址的情况下,把hou变成 houzhi
String str = new String("hou");
// 重新new了一个对象地址变了
StringBuilder stringBuilder = new StringBuilder(str);
StringBuilder str1 = stringBuilder.append("zhi");
System.out.println(str1);
Field value = str.getClass().getDeclaredField("value");
value.setAccessible(true);
value.set(str,"houzhi".toCharArray());
System.out.println(str);
21 Integer的享元模式?
// 运用了享元模式
// 1. 内部有一个IntegerCache静态内部类, 定义了一个 Integer cache[];数组
// 2. 会通过 Integer.valueOf().方法进行比较你的传入的值,如果在 [-128,127]之内会从这个cache数组取值,否则new Integer(i);
Integer i = 100;
Integer i1 = 100;
System.out.println(i == i1);
Integer j = 128;
Integer j1=128;
System.out.println(j == j1);
22.mysql的搜索引擎b+树?
b树:是一个排序了的二叉树,左边的叶子节点小于root节点,右边大于root节点。
b+树:叶子节点里面有上一个叶子节点的冗余,并且叶子节点里面有双向的指针,同时数据经过排序的。
22.1 truncate 和delete区别?
1.truncate 比delete要节约空间,不可以进行回滚操作。
2.truncate只可以删除整表的信息,不可以删除其中的指定条件的。
3.当表被truncate后,这个表和索引所占用的空间会恢复到初始的大小,但是delete后不会减少表或索引所占用的空间。
比如
delete from user where id = 3
insert into user(username) values('test')这里会
以最后的你的自增主键id进行插入
truncate table user;
insert into user(username) values('test') 这样是不会重置表
23 Hashtable和HashMap的不同?
1.安全性:
Hashtable是线程安全的,源码用sychronized锁修饰,HashMap不是线程安全的。所以HashMap的性能会高于Hashtable,所以单线程下可以使用HashMap。
2.是否可以使用null作为key?
Hashtable不允许null作为key,而HashMap可以使用,不建议这么使用:
HashMap以null作为key时,总量存储在table数组的第一个节点上。
3.默认容量,及如何扩容?
HashMap默认初始容量为16,Hashtable为11,两者填充因子默认为0.75.
HashMap扩容时容量翻倍加1。
23 java的强,软,弱,虚引用?
强引用: GC不会回收,Object object = new Object.
软引用:JVM发生OOM的时候回收,GC回收,通过SoftRefrence类实现的。
弱引用:扫描内存的时候,发现有弱引用的,就会回收。通过 WeakRefrence类实现。(ThreadLocal底层源码里面的 Entry extends WeekaRefrence.)
虚引用:等于没有任何引用,GC看到就会回收 任何时候可能被回收。
24 ThreadLocal?
可以进行线程的隔离,为每个线程创建变量副本,会造成内存的泄漏。
使用 private final static 修饰可以防止多实例的内存泄露问题。
线程池环境下使用后将ThreadLocal局部变量remove掉或者设置成为一个初始值。
package com.monkey.single.threadLocal;
import java.util.concurrent.TimeUnit;
public class ThreadLocalTest {
static ThreadLocal<Person> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3);
threadLocal.set(new Person("houge"));
System.out.println(threadLocal.get());
threadLocal.remove();
//Entry虽然继承了WeakRefrence但是,它剩下的value也会存在内存泄漏,所以通过remove方法可以防止value的泄漏。双重保险。 也就是弱引用解决 key的泄漏,remove解决value的泄漏
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// Spring的源码Transactinal里面有用到这个ThreadLocal,进行存储数据库的连接,Connection.
//获取不到
new Thread(()->{
System.out.println(threadLocal.get()+"111111");
// threadLocal.remove();
}).start();
}
static class Person{
String name = "zhangsan";
Person(String name){ this.name = name;}
}
}
https://www.bilibili.com/video/BV1EZ4y147qZ?p=4&vd_source=2560dd389ac5f0d922f7f3017169752d ThreadLocal应用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GkVsOAIY-1657852085093)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220628081430386.png)]
内存的泄漏:表示有强引用指着它,但是又无法使用它,“点着座位就是不坐”。
ThreadLocal.set()源码:
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lt6ezvNf-1657852085094)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220629223235355.png)]
在线程池中,如果 你使用了ThreadLocal一定要记得清空(remove)再放回去
25 CocurrentHashMap jdk1.7和jdk1.8的区别?
在多线程中,首先保证线程安全使用的是ConCurrentHashMap,不使用HashTable,因为它的效率要高,使用了分段锁。
1.7:底层用 ReenTrantLock(Lock锁)+Entry+segement实现
26SpringAop有哪几种通知类型?
-
前置通知 @Before :切入点的方法执行之前通知。
-
后置通知:@After 切入点方法执行成功之后执行@After
-
返回通知 @AfterReturning: 切入点方法执行成功之后执行。
-
环绕通知@ARound:切入点方法执行前后执行。
-
异常通知:@AfterThrowing 切入点方法发生异常执行。
27 HashMap的jdk1.7和jdk1.8区别?
jdk1.7中
HashMap底层采用数组+链表实现,数组里每个元素是一个单向链表,然后存储Entry对象里面有key,value,hash值(作为HashMap的key),和用于单向链表的next。查询的时间复杂度是O(n)
-
Capacity:当前数组初始容量为16,当达到阀值的时候的进行扩容到当你容量的两倍。
-
locadFactor:负载因子,默认为0.75.
-
threshold:Capity*loadFactor.
jdk1.8
多出红黑树:是为了提升查找效率。O(logn)
-
28 Innodb 如何支持范围查询能走索引的?
# 根据索引进行查询的时候才走
explain select * from category WHERE category_id < 6;
explain select * from category where category_name ='营养滋补/速食'
30 什么是代理模式?有哪几种? 为什么要使用?
创建一个Proxy对象来替换目标对象进行实现。
-
静态代理
-
动态代理
-
cglib代理:(通过内存动态的创建,属于动态代理)
因为有时候我们不可以直接通过目标对象进行实现。
创建开销比较大的类,需要安全控制的对象等等。
31 静态代理怎么使用?
需要定义接口或者父类,代理对象和被代理对象(目标对象)需要实现相同的接口或者继承相同的父类,通过代理对象的方法调用目标对象。
32 动态代理?
代理对象是复用JDK的API动态的在内存中构建代理对象。代理对象不需要实现接口,目标对象需要实现接口,否则不能用动态代理。
JDK中API代理类在:java.lang.reflect.Proxy,需要实现它的 new ProxyInstance方法。
33 深拷贝和浅拷贝?
浅: 被复制对象的所有变量都与原对象有相同的值,而所有的引用对象仍然指向原来的对象。
深:除了被复制对象所有变量都有原来的值外,还把引用对象也拷贝出来,指向了拷贝的新对象。
代码:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zyDf6RH7-1657852085095)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220709195004035.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aTcNEFBn-1657852085095)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220709195341945.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xEW1knZy-1657852085096)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220709195321775.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iSrRewTM-1657852085096)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220709195400491.png)]
Mysql系列
32. mysql事务隔离级别?
-
serilizable
-
repeatable read
-
read commited (它可以看到其他的事务对数据的修改,在事务处理期间,如果其他事务修改这个表,(同一个select 语句返回不同结果) )
-
read uncommitted
隔离级别的安全性依次降低
基于锁的属性:共享锁(也是读锁,一个事务加上这个,不可以再加写锁),排他锁(写锁)
mysql默认是行级锁,修改时只会对修改的那几行加锁,加锁期间其他用户线程是看不到修改结果的,所以会导致不可重复读和幻读的问题;
mysql表级锁(锁住整张表)的引擎如:MyIsAM,幻读就不可能出现;
32.1说一下 spring 的事务隔离?
通过@Transactional(isolation = Isolation.DEFAULT) 这个方式开启,里面封装一个enum类枚举相关的类型
package org.springframework.transaction.annotation;
public enum Isolation {
DEFAULT(-1),
READ_UNCOMMITTED(1),
READ_COMMITTED(2),
REPEATABLE_READ(4),
SERIALIZABLE(8);
private final int value;
private Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
事务隔离级别指的是一个事务对数据的修改与另一个并行的事务的隔离程度,当多个事务同时访问相同数据时,如果没有采取必要的隔离机制,就可能发生以下问题:
脏读:一个事务读到另一个事务未提交的更新数据。
幻读:例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样。
不可重复读:比方说在同一个事务中先后执行两条一模一样的select语句,期间在此次事务中没有执行过任何DDL语句,但先后得到的结果不一致,这就是不可重复读。
32.1 Spring 管理事务的方式有几种?
编程式事务 : 在代码中硬编码(不推荐使用) : 通过 TransactionTemplate或者 TransactionManager 手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
声明式事务 : 在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于@Transactional 的全注解方式使用最多)
32.2 Transactional(rollback = Exception.class)注解了解吗?
-
Exception 分为运行时异常 RuntimeException 和非运行时异常。
-
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
-
在
@Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚。
项目中的code使用:
/**
* 保存自动清算确认页面修改的东西
*/
@Transactional(rollbackFor = Exception.class , propagation = Propagation.REQUIRES_NEW)
public void saveLiquidate(List<ClmAutoClearingLcjm> clmAutoClearingLcjms){
for (ClmAutoClearingLcjm clmAutoClearingLcjm : clmAutoClearingLcjms) {
String chdrnum = clmAutoClearingLcjm.getChdrnum();
String flag01 = clmAutoClearingLcjm.getIsliq();
String result = clmAutoClearingLcjm.getResult();
String clmnum = clmAutoClearingLcjm.getClmnum();
int i = clmAutoClearingLcjmMapper.updateLcjmFlag01AndResult(clmnum , chdrnum , flag01 , result);
}
BaseResponse response = this.policySyncAs400(clmAutoClearingLcjms.get(0).getClmnum(), "notBack");
if (response.getResultCode() != 0){
throw new MyInfoException(500 , response.getResultMsg());
}
}
33. 导致mysql的慢查询?
看到慢查询 首先 explain sql,然后看看它的执行计划的type.
慢查询会有专门的统计平台,如果是使用主键进行查询的基本没有优化的余地。
- 查询的时候没有根据索引进行查询(索引没有命中)
- 查询太多不需要的字段。
- 数据量太大,已经无法优化,可以进行分库分表。
34. 索引设计原则?
- 数量比较小不需要创建索引。
- 如果存在索引a,需要创建(a,b)索引,我们可以修改a索引。
- 对于定义为 image,text,bit的数据类型不合适创建索引。
- 频繁修改的列不适合创建索引。
- 创建短索引,对于长字符串的列创建索引的时候可以指定一个前缀。
35 MyisAM 与InnoDb区别?
- myisam支持表锁,innodb支持行(默认的),表锁。
- innodb支持事务,外键,myisam不支持。
- innodb是聚集索引,使用B+tree实现,数据文件和索引在同一个b+tee中,myisam是非聚集索引,使用B+tee树实现,但是数据文件和索引不在同一颗b+Tree.
- innodb不保存整表的行数,myisam有一个变量存储整表行数。
- innob必须有一个索引(如果没有会进行生产一个隐藏的row_id作为索引),myisam可以没有。
36什么时候用mysql里面的关键字in 和exists 区别,Not exists 和 Not In使用哪个?
exists: 后面的参数是一个子查询,子查询里面如果有一行数据符合条件返回 true,则执行外面的查询,否则不执行。Select NULL 默认返回true,对外查询进行loop。
in:通过hash进行连接外查询和子查询(内查询)。
in 适用于子查询表比较小,exists 子查询表
not eixsts 走索引,not in 走的都是全表扫描。
37 数据结构时间复杂度怎么计算的?冒泡排序计算时间时间度?o(n2)
0 1 2 3 4 5
n2a + Rn
38 redis缓存里面用了什么设计模式?redis使用的时候为什么不共用同一个key好点?
双重if判断有没有实现对象的创建。 单例模式的懒汉模式。 如果你的缓存只要有不一样的地方,就要使用多个key进行不同的缓存。
添加和删除操作需要缓存的同步。
39 模板方法模式是什么?
定义一个Abstract class 里面定义了整个方法的骨架(定义了大致流程)。定义一个子类重写它的关键的方法。
40 static关键理解?
package com.monkey;
public class StaticTest {
static int i = 0;
int j = 0;
StaticTest(){
System.out.println("test");
}
public static void test(){
}
static class monkey{
int i = 0;
}
static interface test{
}
static enum e{
GOOD;
}
public static void main(String[] args) {
System.out.println(e.GOOD);
StaticTest staticTest = new StaticTest();
}
}
41.自定义运行时异常的类?同样如何自定义类加载器?
package com.monkey;
public class MyRuntimeException extends RuntimeException{
private int code;
MyRuntimeException(int code,String msg){
super(msg);
this.code = code;
}
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public BasicResponse test(){
BasicResponse<Object> objectBasicResponse = new BasicResponse<>();
try {
int i = 6 / 0;
}catch (Exception e){
objectBasicResponse.setMessge(e.getMessage());
}
return objectBasicResponse;
}
public static void main(String[] args) {
new MyRuntimeException(111,"这个参数有误");
}
}
进行响应的那个工具类。
package com.monkey;
public class BasicResponse<T>{
int code;
String messge;
T Data;
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMessge() {
return messge;
}
public void setMessge(String messge) {
this.messge = messge;
}
public T getData() {
return Data;
}
public void setData(T data) {
Data = data;
}
}
42 JUC的常见面试题目
相关题目图片:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S10sj20F-1657852085096)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220715094825342.png)]
1. 谈谈对volatile关键字的理解,
是java虚拟机提供的一个轻量级同步机制。相当于一个轻量级的sychronized.
1.1 它不保证原子性,是不保证线程安全
1.2 可以防止指令重排,底层通过内存屏障进行保证,进行读写的屏障。
1.3可以保证可见性,对于共享变量的修改对于其他的所有的线程是可见的。
代码实现volatile的可见性,和防止指令重新排序:
package com.monkey.volatiletest;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
class MyData{
volatile int num = 0;
public void addData(){
this.num = 60;
}
//synchronized 可以解决原子性问题
// 通过java.util.concurrent.atomic下面的一些并发编程的包可以解决这个问题 比如 AtomicInteger
public void addPlus(){
num++;
}
// num++在 JVM执行字节码中分为三步执行
// 1. getFiled 拿到 num的初始值 0
// 2. iadd进行加1
// 3. putfiled把累加后的值写回主物理内存
AtomicInteger atomicInteger =new AtomicInteger();
public void myAtomicInteger(){
atomicInteger.getAndIncrement();
}
}
/*
* 2. volatile不保证原子性?
* 原子性是什么意思?
* 不可分割,完整性。也就是某个线程正在做某个具体业务的时候,中间不可被加塞或者分割,需要完整,要么同时成功,要么同时失败。
*
* */
public class VolatileVisibleCode {
public static void main(String[] args) {
MyData myData = new MyData();
for (int i = 0; i < 20; i++) {
new Thread(
()->{
//执行次数需要大点要不然会看不到效果
for (int j = 0; j < 1000; j++) {
myData.addPlus();
myData.myAtomicInteger();
}
}
,String.valueOf(i)).start();
}
// 后台默认两个线程 1.main线程 2.Gc线程 剩下的是其他的线程。
while (Thread.activeCount() > 2){
Thread.yield(); //让其他的线程执行进行阻塞。
}
System.out.println(Thread.currentThread().getName()+"finally number value is "+myData.num);
System.out.println(Thread.currentThread().getName()+"AtomicInteger,finally number value is "+myData.atomicInteger);
}
//1.可以保证可见性,可以使用线程之间的通信是可见的,及时通知其他线程主物理内存已经被修改
private static void seeOkByvolatile() {
MyData myData = new MyData();
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"开始修改num的值");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
myData.addData();
System.out.println(Thread.currentThread().getName() + "修改值成功" + myData.num);
},"AAA").start();
while (myData.num == 0){
}
System.out.println(Thread.currentThread().getName()+"misson num 的值为"+myData.num);
}
}
2 谈谈JMM(java内存模型)英文 Java Memory Model?
它是一个抽象概念并不真实存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括 实例字段,静态字段)的访问方式。
JMM关于同步的规定:
**工作内存:**是每个线程的私有数据。
主内存:是所有线程共享的内存,具有一个线程修改所有的可见的特性。
JMM可见性:
JMM中规定所有变量都存储在主内存,是共享的,但是线程对变量的操作(读取赋值)必须在工作内存中,需要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成以将变量写回到工作内存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KnGKAnv2-1658495516606)(C:\Users\24473\AppData\Roaming\Typora\typora-user-images\image-20220715214121968.png)]
- 线程解锁前,必须把共享变量的值刷新到主内存。
- 线程加锁前,必须读取主内存的最新值到自己的工作内存。
- 加锁解锁是同一把锁。
3. CAS原理?为什么不使用sychronized而使用CAS?
CAS原理 :UnSafe类和 自旋(CAS思想 ) 它是一条CPU并发原语,它的功能是判断内存某个内存的值是否是期望值,如果是改为新的值,这个过程是原子的。原语的执行必须 是连续的,执行中不会被中断。不会造成不一致问题。
AtomicInteger是一个可以用于并发的Integer类 。
compare and Swap
CAS缺点:
它的里面的方法:unsafe类里面getAndAddInt方法实现:
- 可以从代码知道使用循环:如果CAS失败,会一直进行尝试,长时间不成功会给CPU带来很大开销。
- 只能保证一个共享变量的原子操作。
- 引出ABA问题(线程A 复制主内存中的共享变量A然后进行修改为 B,第二次以修改为A,但是B访问的时候以为其他线程是没有进行修改的,于是 就默认为期望值进行修改A。)
源码分析
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
43java创建对象的方式?
-
clone()
-
new
-
反射
-
通过序列化机制
44 JVM的内存结构?
- 堆
- 方法区
- 本地方法栈
- 虚拟机栈
- 程序计数器
45 谈谈JMM(java内存模型)英文 Java Memory Model?
它是一个抽象概念并不真实存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括 实例字段,静态字段)的访问方式。
JMM关于同步的规定:
**工作内存:**是每个线程的私有数据。
主内存:是所有线程共享的内存,具有一个线程修改所有的可见的特性。
JMM可见性:
**JMM中规定所有变量都存储在主内存,是共享的,但是线程对变量的操作(读取赋值)必须在工作内存中,需要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成以将变量写回到工作内存。
46. 创建线程池有哪几种方式?
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。
④. newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
47. 线程池都有哪些状态?
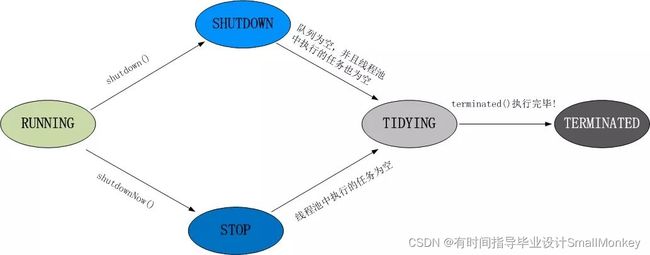
线程池有5种状态:Running、ShutDown、Stop、Tidying、Terminated。
线程池各个状态切换框架图:
48. 线程池中 submit()和 execute()方法有什么区别?
接收的参数不一样
submit有返回值,而execute没有
submit方便Exception处理
49. 在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
50. 怎么实现动态代理?
首先必须定义一个接口,还要有一个InvocationHandler(将实现接口的类的对象传递给它)处理类。再有一个工具类Proxy(习惯性将其称为代理类,因为调用他的newInstance()可以产生代理对象,其实他只是一个产生代理对象的工具类)。利用到InvocationHandler,拼接代理类源码,将其编译生成代理类的二进制码,利用加载器加载,并将其实例化产生代理对象,最后返回。
51Spring源码系列
Spring 框架的核心功能是IOC,AOP的功能,所以作为框架 必须是想要大家去使用,满足各种业务的需求,体现 这个框架的伟大,扩展性就得非常好,而且管理各个方面的东西,维护性也就更加不错 它的大致的实现流程图:
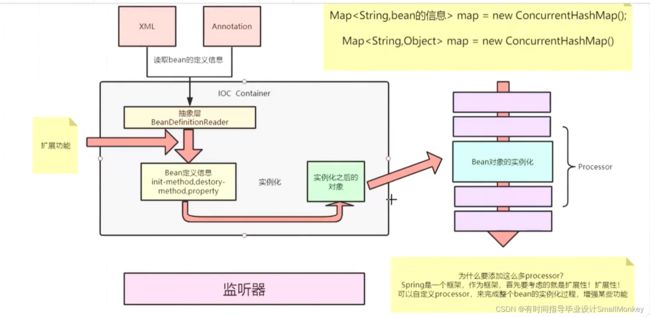
体现了 IOC容器的,可以 扩展性 和 维护性,以及可以良好的管理Bean这些信息。
- 抽象了很多的接口,体现面向 接口编程
- 在Processor实例化之后,BeanDefinition 之前可以进行相关bean属性的定义,扩展性挺不错。
- 之前创建的new的对象随处 new不好管理,现在放在一个容器,统一管理,IOC就像一个主席。
更加详细的流程图:

BeanFactoryPostProcessor,BeanPostProcessor 两个接口,用于人为的去修改Bean的信息,体现了 扩展性 和面向接口编程。
看 abstract class AbstractApplicationContext 抽象类里面的 refresh()方法这个里面实现了所有相关的Spring的流程方法,特别好遵循设计模式的 单一职责原则,也就是每个方法实现一个功能。
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
contextRefresh.end();
}
}
}
1. BeanFactory 和FactoryBean有什么区别?
简单的说 BeanFactory是一个Spring里面顶级父接口,ApplicationContext是有实现它的。
FactoryBean:只是 提供一些扩展功能的作用。该接口在框架本身中大量使用,例如AOP org.springframework.AOP.framework。Open Feign(远程调用框架)
52 SpringAop面向切面编程?
底层使用代码模式的动态代理实现(jdk代理和cglib动态代理),使用java里面的反射进行实现的。具体实现过程看我的博文。SpringAop和自定义注解实现参数校验,权限认证,日志等等
53熟悉常见排序的相关的时间复杂度和空间复杂度,和怎么计算?
53.1对数器,使用已知正确的算法和你自己写的算法进行比较对数
代码 :
package com.hou.sort;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Random;
/**
* @version 1.0
* @Author smallMonkey
* @Date 2022/11/23 19:17
*/
public class CheckDataTool {
static int[] generateRandomArray(){
Random random = new Random();
int[] arr = new int[100000];
for (int i = 0; i < arr.length; i++) {
arr[i] = random.nextInt(10) ;
// arr[i] = (int) (Math.random()*10);
}
return arr;
}
static int check(){
int[] arr = generateRandomArray();
int[] arr1 = new int[arr.length];
//复制一个数组 到 另外一个数组
System.arraycopy(arr,0,arr1,0,arr.length);
Arrays.sort(arr);
//自己定义的算法进行排序 arr1
InsertSort.sort(arr1);
boolean flag = true;
for (int i = 0; i < arr.length; i++) {
if(arr[i] != arr1[i]){
flag = false;
}
}
// System.out.println(flag == true ? "right" : "error");
if(flag == true){
return 1;
}
return 0;
}
static int checkCompareManyTimes(){
HashSet<Integer> sets = new HashSet<>();
//对数器对十次数
for (int i = 0; i < 10; i++) {
int check = check();
sets.add(check);
}
System.out.println(sets.size() > 1 ? 0 : 1);
return sets.size() > 1 ? 1 : 0;
}
public static void main(String[] args) {
checkCompareManyTimes();
}
}
53.2 insert排序把每个数往前面进行插入的排序
package com.hou.sort;
/**
* @version 1.0
* @Author smallMonkey
* @Date 2022/11/30 18:32
*/
public class InsertSort {
static int[] arr = {1,2,3,4,5,7,6,8,6,9};
static void sort(int[] arr){
for (int i = 0; i < arr.length; i++) {
for (int j = i; j> 0 && arr[j] < arr[j - 1]; j --){
swap(arr,j,j-1);
}
}
// print(arr);
}
private static void print(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
sort(arr);
}
}
53.3 选择排序
53.4 归并排序 重要
思想: 递归把数组分开为最后只有两个元素比较
合并: 通过合并进行排序,利用 三个指针, i j k 进行操作把数组排序好
package com.hou.sort;
/**
* @version 1.0
* @Author smallMonkey
* @Date 2022/12/1 23:01
*/
public class MergeSort1 {
public static void main(String[] args) {
int[] arr = {1,3,2,5,4,6,8,7,10,9};
sort(arr,0,arr.length - 1);
print(arr);
}
static void sort(int[] arr,int left, int right) {
if (left == right){
return;
}
int mid = left + (right - left) / 2;
//分离开左边进行排序
sort(arr,left,mid);
//分离开右边进行排序
sort(arr,mid + 1,right);
merge(arr,left,mid + 1,right);
}
static void merge(int[] arr, int leftP, int rightP, int rightBound){
int mid = rightP - 1;
int[] temp = new int[rightBound - leftP + 1];
int i = leftP;
int j = mid + 1;
int k = 0;
while (i <= mid && j <= rightBound){
temp[k++] = arr[i] < arr[j] ? arr[i++]: arr[j++];
}
while (i <= mid){
temp[k++] = arr[i++];
}
while (j <= rightBound){
temp[k++] = arr[j++];
}
// print(temp);
for (int l = 0; l < temp.length; l++) {
arr[leftP + l] = temp[l];
}
}
static void print(int[] arr){
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
53.4 快速排序
Arrays.sort();如果里面的数据类型为基本数据类型,采用的是双轴快速排序。 (轴其实就是数组里面的一个数)
可以假设最右边这个数为轴,采用 左边开始的数为下标为指针,右边轴下标 -1 为指针,采用比较,比轴大的数放到轴右边,比轴小的数放到轴左边,然后每次轴采用左边数中大于轴的第一个数作为下一个轴的位置。
package com.hou.monkey.sort;/*
**
*@author SmallMonkey
*@Date 2022/12/3 10:53
*
**/
public class QuickSort {
public static void main(String[] args) {
int[] arr = {1,3,2,5,4,7,6,9,8,10};
sort(arr,0, arr.length - 1);
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
private static void sort(int[] arr, int left, int right) {
if(left >= right) return;
//对轴进行排序
int mid = quick(arr, left, right);
sort(arr, left, mid -1);
sort(arr, mid + 1, right);
}
static int quick(int[] arr, int left, int rightBound) {
int right = rightBound - 1;
int pivot = arr[rightBound];
while (left <= right){
while (left <= right && arr[left] <= pivot) left++;
while (left <= right && arr[right] > pivot) right--;
if(left < right) swap(arr,left,right);
}
// 轴上面的数和左边第一个比轴数大的位置进行和交换
swap(arr, left, rightBound);
return left;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
53.5 堆排序
53.6 计数排序
package com.hou.sort;
/**
* @version 1.0
* @Author smallMonkey
* @Date 2022/12/6 11:11
*/
// 计数排序 桶排序的思想的一种 不用进行比较
// 量大 范围小使用 大型企业的年龄排序,中考,高考的名次排序 不稳定
public class CountSort {
public static void main(String[] args) {
int[] arr = {1,3,2,3,5,4,5,6,8,7,0,0,9};
int[] arr1 = countSort(arr, 0, arr.length - 1);
MergeSort.print(arr1);
}
static int[] countSort(int[] arr, int left, int right) {
int[] count = new int[11];
int[] arr1 = new int[right - left + 1];
for (int i = 0; i < arr.length; i++) {
count[arr[i]]++;
}
for (int i = 0,j = 0; i < count.length; i++) {
while (count[i]-- > 0){
arr1[j++] = i;
}
}
return arr1;
}
}
54.接口幂等
用户多次请求的时候不会造成数据库的数据不一致
解决办法:
token机制:前端请求的时候带一个token,后端进行接收,匹配成功,然后delete这个token,但是这个可能出现并发的情况导致两个线程同学获取成功,同时执行业务代码,所以需要使用lua脚本保证它的原子性。参考如下code:
/**
* 订单确认页返回需要用的数据
* @return
*/
@Override
public OrderConfirmVo confirmOrder() throws ExecutionException, InterruptedException {
//构建OrderConfirmVo
OrderConfirmVo confirmVo = new OrderConfirmVo();
//获取当前用户登录的信息
MemberResponseVo memberResponseVo = LoginUserInterceptor.loginUser.get();
//TODO :获取当前线程请求头信息(解决Feign异步调用丢失请求头问题)
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
//开启第一个异步任务
CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//1、远程查询所有的收获地址列表
List<MemberAddressVo> address = memberFeignService.getAddress(memberResponseVo.getId());
confirmVo.setMemberAddressVos(address);
}, threadPoolExecutor);
//开启第二个异步任务
CompletableFuture<Void> cartInfoFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//2、远程查询购物车所有选中的购物项
List<OrderItemVo> currentCartItems = cartFeignService.getCurrentCartItems();
confirmVo.setItems(currentCartItems);
//feign在远程调用之前要构造请求,调用很多的拦截器
}, threadPoolExecutor).thenRunAsync(() -> {
List<OrderItemVo> items = confirmVo.getItems();
//获取全部商品的id
List<Long> skuIds = items.stream()
.map((itemVo -> itemVo.getSkuId()))
.collect(Collectors.toList());
//远程查询商品库存信息
R skuHasStock = wmsFeignService.getSkuHasStock(skuIds);
List<SkuStockVo> skuStockVos = skuHasStock.getData("data", new TypeReference<List<SkuStockVo>>() {});
if (skuStockVos != null && skuStockVos.size() > 0) {
//将skuStockVos集合转换为map
Map<Long, Boolean> skuHasStockMap = skuStockVos.stream().collect(Collectors.toMap(SkuStockVo::getSkuId, SkuStockVo::getHasStock));
confirmVo.setStocks(skuHasStockMap);
}
},threadPoolExecutor);
//3、查询用户积分
Integer integration = memberResponseVo.getIntegration();
confirmVo.setIntegration(integration);
//4、价格数据自动计算
//TODO 5、防重令牌(防止表单重复提交)
//为用户设置一个token,三十分钟过期时间(存在redis)
String token = UUID.randomUUID().toString().replace("-", "");
redisTemplate.opsForValue().set(USER_ORDER_TOKEN_PREFIX+memberResponseVo.getId(),token,30, TimeUnit.MINUTES);
confirmVo.setOrderToken(token);
CompletableFuture.allOf(addressFuture,cartInfoFuture).get();
return confirmVo;
}
数据库的悲观锁:select * from table from where id = 1 需要注意这个id是主键或者唯一索引,否则可能会导致锁表问题的,非常难解决。
数据库的乐观锁:适合更新的场景,更新的时候带一个版本号version,处理读多写少的问题。

业务层分布式锁
数据库加上唯一性索引。
Redis的set防重处理。
全局唯一请求id:比如 feign进行重试的机制的时候给每个请求一个请求id,来判断是否已经执行过这个请求。
55. Spring的循环依赖问题和解决?
A依赖B, B依赖C C依赖A
解答:从Bean的比较复杂的生命周期回答
Spring有一个建模的类BeandDefination, 然后把bean的生命周期一步一步答出来
bean的生命周期:首先spring容易启动,启动完之后会做一个简单的扫描,扫描完之后变成BeanDifination存到BeanDifinationMap中,然后对BeanDifinationMap做一个遍历,遍历完之后做一些验证,比如验证是否单例,是否原型,是否懒加载,是否有DepensOn.验证完之后会去 获取一遍当前实例化的bean有没有存在单列池当中。
Bean创建与管理基本过程:
首先通过 getBean()方法从单列池(SingtionBeanRegistry)获取,没有就会创建,有直接返回。创建包括三个步骤:1.通过反射(reflect)进行实例化—>填充属性–》初始化。创建好之后又会放入单列池中,进行返回。
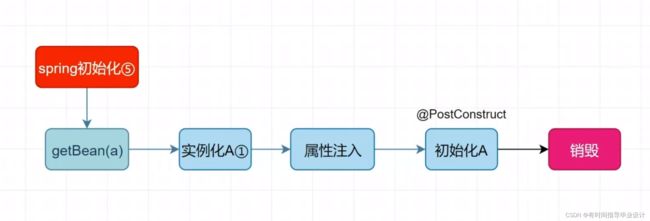
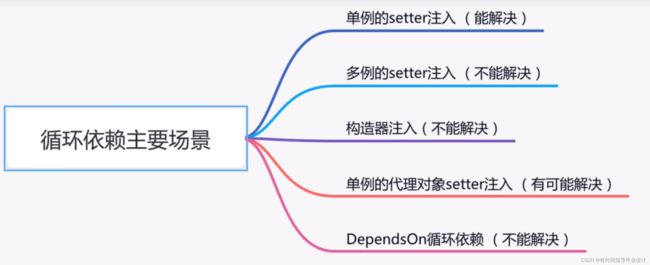
多例的settter注入:@Scope(ConfigurationBeanFactory.SCOPE_PROTOTYPE)有这种注解的setter注入的循环依赖是不可以解决的
构造器注入:也是没有加入到三级缓存的,can’t be solved
Is there an unresolveable circular refrence?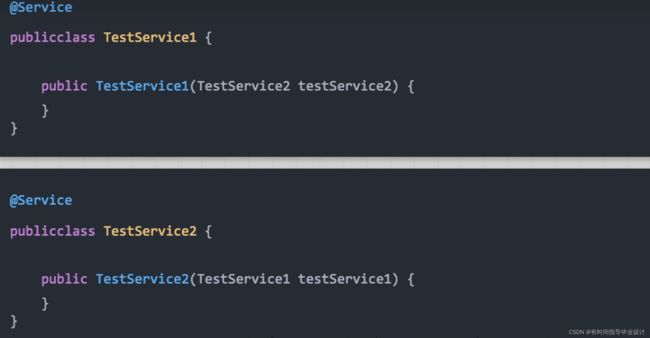
1.生成代码对象产生的循环依赖问题:可以使用@Lazy注解
2.@DependsOn产生的循环依赖:指定加载的先后关系,修改文件名称
3. 如果是多例循环依赖,可以把它改成单例的,@Scope(“singleon”),或者不用写,spring默认是单列的。
57 Feign远程调用(1个线程)请求头header丢失问题解决
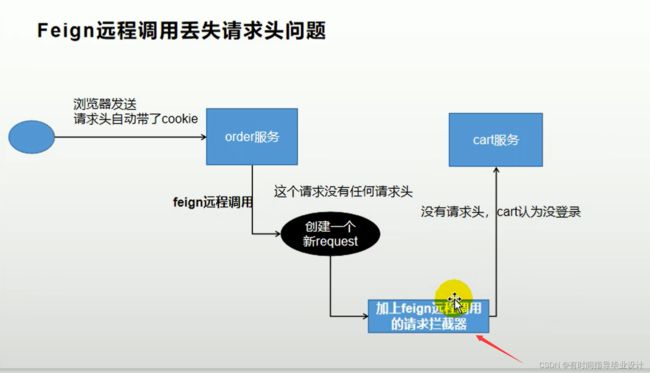
由于feign进行调用的时候会创建一个新的request,所以请求头数据会丢失,所以可以通过配置文件来再次给它加上请求头。
package com.xunqi.gulimall.order.config;
import feign.RequestInterceptor;
import feign.RequestTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
/**
* @Description: feign拦截器功能
* @Created: with IntelliJ IDEA.
* @author: houge
* @createTime: 2020-07-02 21:10
**/
@Configuration
public class FeignConfig {
@Bean("requestInterceptor")
public RequestInterceptor requestInterceptor() {
RequestInterceptor requestInterceptor = new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
//1、使用RequestContextHolder拿到刚进来的请求数据
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (requestAttributes != null) {
//老请求
HttpServletRequest request = requestAttributes.getRequest();
if (request != null) {
//2、同步请求头的数据(主要是cookie)
//把老请求的cookie值放到新请求上来,进行一个同步
String cookie = request.getHeader("Cookie");
template.header("Cookie", cookie);
}
}
}
};
return requestInterceptor;
}
}
56 Feign远程异步使用CompletableFutrue异步调用订单相关信息(多个线程)请求头header丢失问题解决
直接把RequestContextHolder.getRequestAttributes()里面的得到的数据,再设置到(RequestContextHolder.setRequestAttributes())其他的线程
/**
* 订单确认页返回需要用的数据
* @return
*/
@Override
public OrderConfirmVo confirmOrder() throws ExecutionException, InterruptedException {
//构建OrderConfirmVo
OrderConfirmVo confirmVo = new OrderConfirmVo();
//获取当前用户登录的信息
MemberResponseVo memberResponseVo = LoginUserInterceptor.loginUser.get();
//TODO :获取当前线程请求头信息(解决Feign异步调用丢失请求头问题)
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
//开启第一个异步任务
CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//1、远程查询所有的收获地址列表
List<MemberAddressVo> address = memberFeignService.getAddress(memberResponseVo.getId());
confirmVo.setMemberAddressVos(address);
}, threadPoolExecutor);
//开启第二个异步任务
CompletableFuture<Void> cartInfoFuture = CompletableFuture.runAsync(() -> {
//每一个线程都来共享之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
//2、远程查询购物车所有选中的购物项
List<OrderItemVo> currentCartItems = cartFeignService.getCurrentCartItems();
confirmVo.setItems(currentCartItems);
//feign在远程调用之前要构造请求,调用很多的拦截器
}, threadPoolExecutor).thenRunAsync(() -> {
List<OrderItemVo> items = confirmVo.getItems();
//获取全部商品的id
List<Long> skuIds = items.stream()
.map((itemVo -> itemVo.getSkuId()))
.collect(Collectors.toList());
//远程查询商品库存信息
R skuHasStock = wmsFeignService.getSkuHasStock(skuIds);
List<SkuStockVo> skuStockVos = skuHasStock.getData("data", new TypeReference<List<SkuStockVo>>() {});
if (skuStockVos != null && skuStockVos.size() > 0) {
//将skuStockVos集合转换为map
Map<Long, Boolean> skuHasStockMap = skuStockVos.stream().collect(Collectors.toMap(SkuStockVo::getSkuId, SkuStockVo::getHasStock));
confirmVo.setStocks(skuHasStockMap);
}
},threadPoolExecutor);
//3、查询用户积分
Integer integration = memberResponseVo.getIntegration();
confirmVo.setIntegration(integration);
//4、价格数据自动计算
//TODO 5、防重令牌(防止表单重复提交)
//为用户设置一个token,三十分钟过期时间(存在redis)
String token = UUID.randomUUID().toString().replace("-", "");
redisTemplate.opsForValue().set(USER_ORDER_TOKEN_PREFIX+memberResponseVo.getId(),token,30, TimeUnit.MINUTES);
confirmVo.setOrderToken(token);
CompletableFuture.allOf(addressFuture,cartInfoFuture).get();
return confirmVo;
}
57怎么判断是一个环形链表?
给你一个链表的头节点 head ,判断链表中是否有环。
注意:如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。
解题思路:快慢指针法
建立两个指针,都从头指针开始,快指针一次走两步,慢指针一次走一步,如果两个指针相遇则证明链表有环,若在快指针到链表尾时,两指针未相遇则证明链表没有环。
bool hasCycle(struct ListNode *head) {
struct ListNode*p=head;//快指针
struct ListNode*q=head;//慢指针
while(p!=NULL&&p->next!=NULL)
{
p=p->next->next;
q=q->next;
if (p==q)
{
break;
}
}
if (p==NULL||p->next==NULL)
{
return false;
}
return true;
}
原文链接:https://blog.csdn.net/qq_70799748/article/details/127795771
58 服务器端的参数怎么校验?
59 xxl-job和scheduling的区别?
60 sql一般怎么优化?
查询的sql:sql优化一般是针对于查询,一般加上索引。有一些常识性的问题:
1.不用select *,少用or(可能导致索引失效),is null is not null无法使用索引
2.like 查询 %不在前端
3. or 前后查询都需要走索引
4. 符合最左匹配原则
5. 字符串查询没有加’',出现隐式转换的情况。
6. 别在索引上进行相关计算(sum(索引)),或者进行其他一些计算操作
7. 符合最佳左匹配原则。 比如复合索引 idx_name_age_area根据user表的三个字段 创建,你查询的时候一定根据 顺序,where name = ‘sd’ and age = 33这种查询, 直接这样查询where age = 33 不会走索引,尽量不跳过索引的中间列。
8. explain关键字看执行计划,字段 rows影响的行数,possible_key,key,type,ke_len.
select_type字段:
simple #简单SELECT查询,查询中不包含子查询或者UNION
primary # 查询中包含任何复杂的部分,primary类型表示最后执行的sql部分。
SUBQUERY #表示子查询
Derived:#英语意思,产生,衍生,表示所在的table会产生一张中间表
UNION: 若第二个Select 出现在union之后,则被标记为Union;若union被包含在from子查询中,外层select被标记为derived
UNION RESULT: 从union表中获取结果的select
比如里面的type的类型的字段分析:
最好到最差依次是:
system (只有一行记录,等于mysql自带的系统表,const类型特例,平时不会出现)> const(只用于匹配一行数据,很快,比如:主键置于where列表中,mysql就能将该查询转换为一个常量) > eq_ref(唯一性索引扫描,只有一条记录与之匹配,常见于主键或唯一性索引)>ref(非唯一性索引扫描,返回匹配某个单独值的所有行。) >range>index>ALL
# 一般优化到range级别就行
ref解释:

index:
全索引扫描,只扫描我们的索引树(数值比较小),不会扫描全表。
possible_key:理论上使用的索引
key:实际上使用的索引,若查询中出现了覆盖索引,则该索引仅仅出现在key列表中
key_len:索引字段的最大可能长度,并非实际使用索引的长度,同样查询结果的时候key_len越小越好
ref:显示索引的哪一列被使用了,可能是一个const(常量),表示哪些常量或者列被用于查找索引列的值。
extra:包含不适合在其他列中显示但十分重要的额外信息, 几个属性重要:
#important the first three
Using filesort: 称为“文件排序”,出现这个表示没有按照索引进行排序,不好,建议进行优化。
Using temporary: 用临时表保存中间结果,mysql 在对查询结果排序时,使用临时表。常见于排序 order by 和 group by,更加不好需要改进.
Using index:表示相应的select操作使用了覆盖索引,效率可以,如果同时出现using where 表示索引被使用查找,没有出现,表示索引被用来读取数据非查找。
# it's not important
Using join buffer:使用也连接缓存,如果join特别多,可以在配置文件里的join buuffer调节大点.
distinct:
impossible where:where 条件不对
select tables optimize away
order by,group by的时候应该尽量用创建好的复合索引的顺序和个数保持一致,这样容易走索引进行查询:
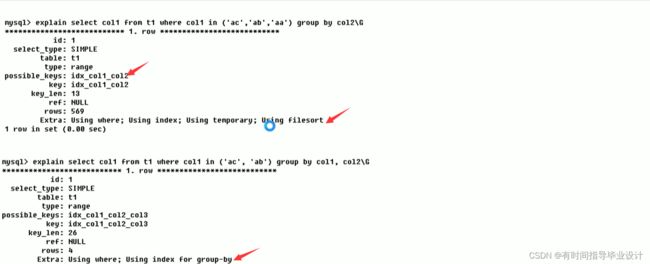
Using index:

索引覆盖(也叫覆盖索引):查询的列在所建的索引中,比如创建了索引 create index idx_col1_col2 on table_name(cool1,col2),你查询所有,col1,col2,或者查询它们的部分都在建立的索引中,这个就是索引覆盖。
id,type,key,rows,extra 这几个属性要求掌握
id字段分析:
相同: 按照顺序执行
逐渐递增:**id越大执行的优先级越大,越先执行**
有相同,有不同:id大的先执行,然后相同的为一组,从上往下按照顺序执行。
- in(驱动小表) 和 exist,in后面的sql先执行。
- union 和 unionAll 可以使用 Union的尽量使用unionall
- limit 分页查询的时候前端可以传一个记录的最大 id,(分页查询优化)
- 你的条件查询范围小放到 where前面。
- 经常在where 条件里面的字段需要加上索引,order by也可以走联合索引,但是需要注意:你不能order by语句里有的字段升序有的字段降序,那是不能用索引的 ,或者是你对order by语句里的字段用了复杂的函数,这些也不能使用索引去进行排序了。
- 索引使用函数进行计算会生效。
- 对于关联的字段可以建立索引。
- group by 优化,它实质是先排序后分组,经常和having进行使用,可以在where条件搞定的就不用在having中
- 通过慢查询日志进行分析,mysql是默认没有开启的,需要我们手动来设置这个参数,如果不是调优需要没有必须开启,对于性能也会有一定的影响, long_query_time的默认时间是10s,我们可以修改这个来锁定超出时间的sql.使用这个命令查看慢查询是否开启:
show variables like '%slow%';

开启慢查询日志,只对本次有效,mysql数据库服务重启之后会失效:
set global slow_query_log = 1

long_query_time默认是10:大于10的sql会被记录下来,修改一下改为5秒,大于3的sql collect(收集)下来。结合explain进行全面分析。使用命令行设置
set global long_query_time = 3;
#查询设置成功没有
show global variables like 'long_query_time';
#count the snow sql
show global status like 'slow_queries%';
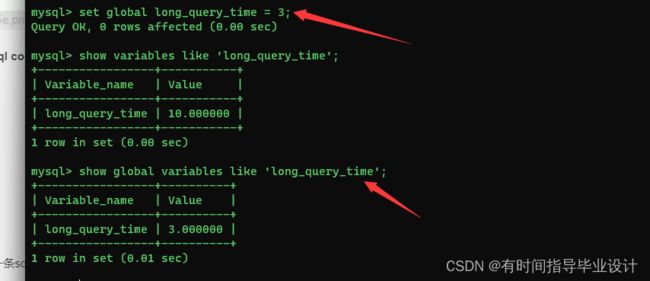
结合mysqldumpslow日志分析工具进行分析:
找出我们的不满足条件
插入的sql: insert 的批量插入的时候我们可以使用Mybaits-Plus的insertBatch,或者用一条sql进行插入多条,相比多条插入语句的效率高。
insert into table_name values(),(),();
range查询导致索引生效问题?
建表语句:
CREATE TABLE `article` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`authour_id` int unsigned NOT NULL,
`category_id` int unsigned NOT NULL,
`views` int unsigned NOT NULL,
`comments` int unsigned NOT NULL,
`title` varbinary(255) NOT NULL,
`content` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=gbk;
insert into article(authour_id,category_id,views,comments,title,content) values
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');
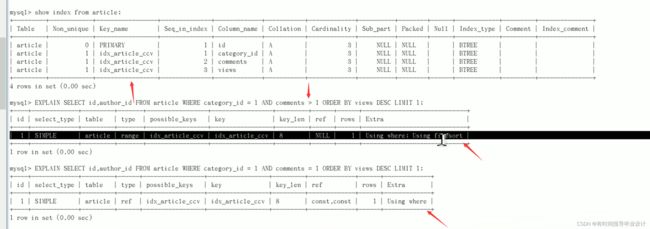
复合索引(idx_article_ccv)建立
create index idx_article_ccv article(category_id,comments,views);
#由于 comments > 1 导致 后面的 order by views没有走索引 extra 属性是 using where;Using filesort(文件内排序,需要进行优化)
explain select id,authour_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
#这种等号的后面的排序不会有失效 情况
select id,author_id,from article where category_id = 1 and comments = 1 order by views desc limit 1;
#type变成了range,这是可以忍受的。但是extra里使用Using filesort仍是无法接受的。#但是我们已经建立了索引,为啥没用呢?
解决上面问题:重新建立符合条件索引, drop index idx_article_ccv on article
drop index idx_article_ccv on article
#重新建立符合条件的索引
create index idx_article_cv on article(category_id,views);
show index from article;
explain select id,author_id,from article where category_id = 1 and comments > 1 order by views desc limit 1;
result:
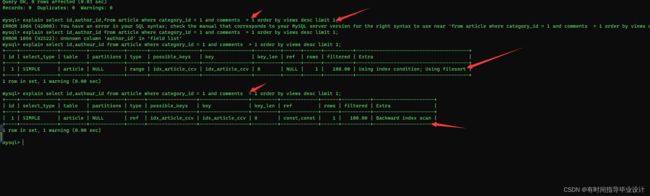
解决之后:

两张表的:left join连接我们给 连接的外键的右表里面创建索引(右连接相反),效率比较高:
# 给class表的card字段建立索引效率比较高
explain select * from book left join class on book.card = class.card;

三张表的left join(索引建立在不是主表的其他两张表就行,需要建立两个索引 ,type类型 ref),以此类推其他多张表的join:
explain select * from book left join class on class.card = book.card left join phone on book.card = phone.card;
create index idx_card on class(card);
create index idx_card on phone(card);
注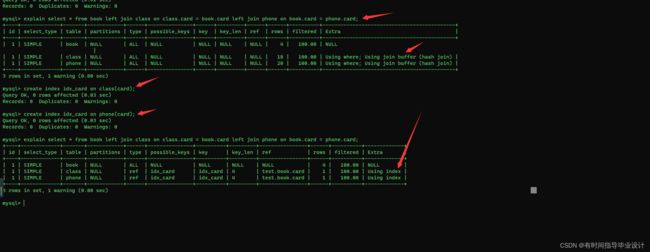
注意:上面无法保证被驱动表的join条件字段可以创建索引,我们同样可以设置JoinBuffer.
结论:永远用小结果集驱动大结果集。
项目上线后怎么进行sql优化总结
1 观察,至少跑1天,看看生产的慢SQL情况。
2.2开启慢查询日志,设置阙值,比如超过5秒钟的就是慢SQL,并将它抓取出来。
3 explain+慢SQL分析
4 show profile5运维经理or DBA,进行SQL数据库服务器的参数调优(这个一般不用我们做,运维做就行)
- 永远用小表集驱动大表
for(int i = 3;.....){
for(int j = 10000,....){
}
}
for(int i = 10000;.....){
for(int j = 3,....){
}
}
//在我们的sql里面一般选择上面的情况,有利于减少和数据的连接,减少资源浪费。
# 当B表的数据量小于 A表优选用in,否则用 exist.
select * from A where id in (select id from B);
执行过程
先 select id from B
再 select * from A where A.id = B.id;
select * from A where exists (select 1 from B where B.id = A.id)
执行过程
先
select * from A
select * from B where B.id = A.id;
exists:将外面的主表数据放到 里面子表中做条件验证,把为true的主查询数据进行保留下来。上面A表数据比B表小时使用
分页查询的优化
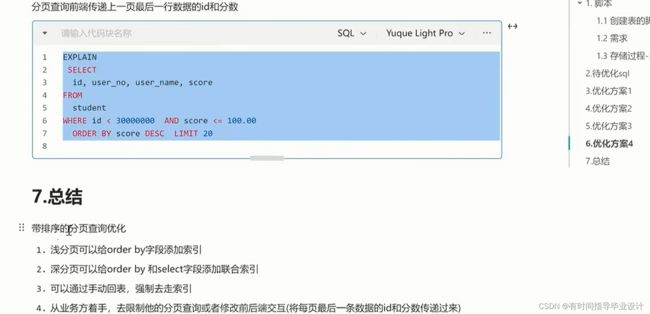
61 Redis的内存淘汰策略?
LRU(Least recently used):最近最少使用的。(只和时间有关,面试中可能也会问到你会手写lru算法么。)
LFU(Least Frequently Used):最近最少的使用。(会和时间频率有关)
TTL:(淘汰快要过期的设置了过期时间的。)
volatile-Random:从设置了过期时间的随机淘汰:全凭天意干掉。
allkeys-random:从数据集中直接随机淘汰。(如果数据的访问次数差不多使用这个)
no-enviction:Redis默认的,禁止驱逐数据,内存不足时新写入会报异常。
62 Redis的过期键(keys)的删除策略?
Redis 2.4版本之前:过期时间删除不准确有 0-1s的误差。
2.6之后 有 0-1ms的误差。
(定时删除)
淘汰过期key:
Redis 过期key有两种方式:主动 (Redis主动检测)和被动(代码里面检测到期过期之后会进行删除,没有请求代码还没有执行的时候key是一直存在redis中的。);
这样还不行,所以redis会主动的进行扫描key,具体是redis每秒(默认)10次会做一些事情:
- 测试随机的 20个keys进行相关的过期检测
- del所有的过期的keys
- 如果多于25%的过期key的话,就会重复进行检测。
定时过期:(自己写一个定时器进行检测,如果key过期就delete)
如果大量的key没有被过期删除,导致redis的内存快耗尽的时候会走内存淘汰机制
62.1 key的冲突问题解决?
- 可以使用业务隔离,不同的业务使用不同的redis集群。
- 对key进行设计,比如 业务 + 系统名称 + 关键名称(可以有效的避免冲突)
- redis分布式锁 + 时间戳
62.2 怎么提高缓存的命中率?
- 提前加载缓存
- 增加redis的内存容量
- 增加缓存的更新频率。
- 根据业务适当调整缓存的类型。
63. Nginx的正向代理和反向代理的区别?
正向代理:我们访问目标服务器不用自己去访问,需要使用我们的proxy(代理服务器去访问)。
advantage(优点): 可以隐藏自己的真实ip(目标服务器不会知道我们自己的ip),可以提高访问速度(可以缓存一些静态资源和请求),突破访问限制.比如 :的使用

Nginx反向代理(代理服务端)
理解:代理服务器将收集到的请求发给服务器,服务器处理完请求将结果返回给代理服务器,再由代理服务器将结果返回给客户端 相当于进行返回 的时候。
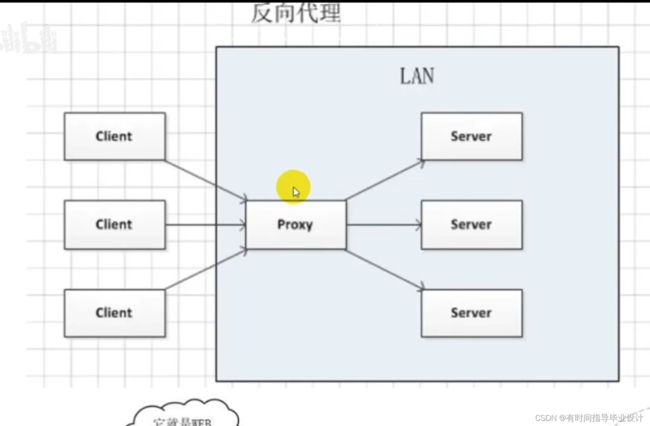
反向代理,其实是"代理服务器"代理了"目标服务器",去和"客户端"进行交互。不要说了我人都蒙了,重点:正向代码是对于客户端也就是我们是客户的代理,反向就是对于服务器端的代理。
4、正向代理和反向代理的区别
(1)正向代理中,客户端知道真正的服务端IP是什么,而服务端并不知真正的道客户端IP是什么;
(2)反向代理中,客户端不知道真正的服务端IP是什么,服务端也不知道真正的道客户端IP是什么;
(3)正向代理一般用来解决访问限制问题;
(4)反向代理一般用来提供负载均衡、安全防护等作用;
参考地址
64 @Transactional注解导致的分布式事务问题?
它只可以保证本地事务的相关异常回滚,feign进行远程调用的方法在里面就不会导致相关的回滚,而且它们也不是在一个数据库。
可以使用mq来保证这个最终一致性。
/**
* 提交订单
* @param vo
* @return
*/
// @Transactional(isolation = Isolation.READ_COMMITTED) 设置事务的隔离级别
// @Transactional(propagation = Propagation.REQUIRED) 设置事务的传播级别
@Transactional(rollbackFor = Exception.class)
// @GlobalTransactional(rollbackFor = Exception.class)
@Override
public SubmitOrderResponseVo submitOrder(OrderSubmitVo vo) {
confirmVoThreadLocal.set(vo);
SubmitOrderResponseVo responseVo = new SubmitOrderResponseVo();
//去创建、下订单、验令牌、验价格、锁定库存...
//获取当前用户登录的信息
MemberResponseVo memberResponseVo = LoginUserInterceptor.loginUser.get();
responseVo.setCode(0);
//1、验证令牌是否合法【令牌的对比和删除必须保证原子性】
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
String orderToken = vo.getOrderToken();
//通过lure脚本原子验证令牌和删除令牌
Long result = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),
Arrays.asList(USER_ORDER_TOKEN_PREFIX + memberResponseVo.getId()),
orderToken);
if (result == 0L) {
//令牌验证失败
responseVo.setCode(1);
return responseVo;
} else {
//令牌验证成功
//1、创建订单、订单项等信息
OrderCreateTo order = createOrder();
//2、验证价格
BigDecimal payAmount = order.getOrder().getPayAmount();
BigDecimal payPrice = vo.getPayPrice();
if (Math.abs(payAmount.subtract(payPrice).doubleValue()) < 0.01) {
//金额对比
//TODO 3、保存订单
saveOrder(order);
//4、库存锁定,只要有异常,回滚订单数据
//订单号、所有订单项信息(skuId,skuNum,skuName)
WareSkuLockVo lockVo = new WareSkuLockVo();
lockVo.setOrderSn(order.getOrder().getOrderSn());
//获取出要锁定的商品数据信息
List<OrderItemVo> orderItemVos = order.getOrderItems().stream().map((item) -> {
OrderItemVo orderItemVo = new OrderItemVo();
orderItemVo.setSkuId(item.getSkuId());
orderItemVo.setCount(item.getSkuQuantity());
orderItemVo.setTitle(item.getSkuName());
return orderItemVo;
}).collect(Collectors.toList());
lockVo.setLocks(orderItemVos);
//TODO 调用远程锁定库存的方法
//出现的问题:扣减库存成功了,但是由于网络原因超时,出现异常,导致订单事务回滚,库存事务不回滚(解决方案:seata)
//为了保证高并发,不推荐使用seata,因为是加锁,并行化,提升不了效率,可以发消息给库存服务
R r = wmsFeignService.orderLockStock(lockVo);
if (r.getCode() == 0) {
//锁定成功
responseVo.setOrder(order.getOrder());
// int i = 10/0;
//这里出现 异常只可以保证上面一个订单可以回滚不创建,但是库存是以属于另外一个系统的,数据库也不一样,会不能进行回滚
//TODO 订单创建成功,发送消息给MQ
rabbitTemplate.convertAndSend("order-event-exchange","order.create.order",order.getOrder());
//删除购物车里的数据
redisTemplate.delete(CART_PREFIX+memberResponseVo.getId());
return responseVo;
} else {
//锁定失败
String msg = (String) r.get("msg");
throw new NoStockException(msg);
// responseVo.setCode(3);
// return responseVo;
}
} else {
responseVo.setCode(2);
return responseVo;
}
}
}
64.1 mysql事务的隔离级别默认
@Transactional(isolation = Isolation.REPEATABLE_READ)//默认为可重复读
package org.springframework.transaction.annotation;
public enum Isolation {
DEFAULT(-1),
READ_UNCOMMITTED(1), //读未提交产生脏读
READ_COMMITTED(2),//读已提交
REPEATABLE_READ(4),//可重复读
SERIALIZABLE(8);//串行化
private final int value;
private Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
64.2 mysql事务的传播行为
它是我的父事务是否传递的子事务的一种机制
注意:Spring和SpringBoot之前,在同一个类(对象)中进行方法间事务的传递,每个方法使用的一定是一个事务,除非在不同对象之前进行事务的传播行为的的设定,原因绕过了代理对象
@Transactional(timeout = 20) //使用方法a事务的其他方法还会继承它的相关事务里面的属性设置
void a(){
b();//使用的是a事务
c();// 使用的是自己的新的事务(产生异常之后c方法不会跟着 a 进行回滚操作)
int i = 10 / 0;
OrderServiceImpl o = (OrderServiceImpl)AopContext.currentProxy();
o.b();
o.c();
}
@Transactional(propagation = Propagation.REQUIRED,timeout = 2)//这里的timeout由于继承了a事务的所以不会起作用了
void b(){
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
void c(){
}
64.3 本地事务失效问题
同一个对象内事务方法互调默认失效,原因绕过了代理对象,事务 使用代理对象来控制的。
解决: 使用代理对象来调用事务方法
1)、引入aop -starter;spring-boot-starter-aop;引入了aspectj
2)、启动类加上如下注解 @EnableAspectJAutoProxy(expose = true) 动态代理功能,以后我们的代理都是aspectj创建的(即使没有接口也可以给我们动态代理,同一个类中的不同方法也可以代理)解决上面问题
3)、在上面加上如下code:
OrderServiceImpl o = (OrderServiceImpl)AopContext.currentProxy(); o.b(); o.c();
65 RabbitMq延时队列(实现定时任务)
场景:比如未付款订单,超过30分钟,系统自动取消订单。
常见解决方案:spring 的 schedule 定时任务,前端轮询数据库,会增加我们数据库的压力,存在较大的时间误差
解决: rabbitmq的消息TTL和死信队列Exchange结合。
如图所示:
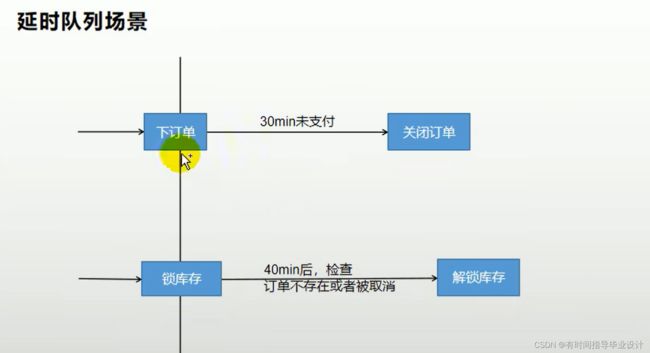
TTL(Time to Live):存活时间。
死信:Rabbitmq可以对队列和和消息分别设置TTL,也可以对每一个单独的消息单独的设置,超过这个时间消息没有被consume(消费),我们认为这个消息就死了,称为死信。
注意:如果**队列和消息都设置了TTL,那么会取小的。**所以一个消息如果被路由到不同队列中,消息死亡时间可能不同,TTL是实现延迟任务的关键,可以通过设置消息的 expiration 字段 或者 x-message-ttl属性来设置时间,两者是一样的效果。
死信路由(Dead letter Exchange):不是死信队列,一个路由可以对应很多队列。
消息一般在如下条件会进入死信路由
- 被consumer拒收,并且rejecct方法里的requeue是false。也就是不会再次放到 其他队列中进行消费。
- 消息的TTL到了,消息过期了。
- 队列的长度限制满了,排在前面的消息会被丢弃或者扔到死信路由上。
65.1 实现方式一 给队列设置过期时间(推荐使用)

问题: 如果设置了三条消息的过期时间分别是2 min, 3min,6min,三条消息分别进入队列之后,需要先等6min的消息过期之后才会被扫描到3min的消息过期,然后再2min的消息过期。
具体实现:


65.3 实现方式二 给消息设置过期时间
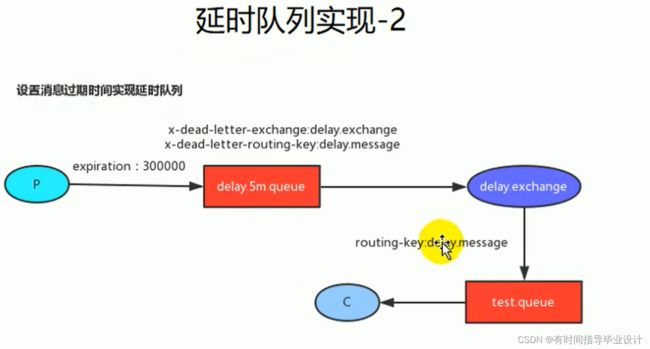
65.4 订单超时取消解决方案
订单取消之后会(通过order.release.other.#路由key)通知库存的队列进行库存释放,然后会进行解锁订单服务。