机器学习(一)监督学习,非监督学习和强化学习
根据机器学习的应用情况,我们又把机器学习分为三类:监督学习(SupervisedLearning, SL), 非监督学习(Unsupervised learning, UL),和强化学习(Reinforcement Learning, RL)。
1、 监督学习是指原始数据中既有特征值也有标签值的机器学习;(有老师教)
我们把监督学习(SL)要解决的问题分成两类:回归(Regression) 和分类(Classification)
监督学习的算法有很多,而且很多算法已经被收集到成熟的算法库中,使用者可以直接调用。常用的经典算法有:
1.邻近算法(K-Nearest Neighbors, KNN)
2.线形回归( Linear Regression)
3.逻辑回归(Logistic Regression)
4.支持向量机(Support Vector Machine, SVM)
5.朴素贝叶斯分类器 (Naive Bayes)
6.决策树(Decision Tree)
7.随机森林(Random Forests)
8.神经网络(Neural Network):比如卷积神经网络(Convolutional Neural Networks, CNN)和深信度网络(Deep Belief Networks, DBN)
我们准备了一大堆猫和狗的照片,我们想让机器学会如何识别猫和狗。当我们使用监督学习的时候,我们需要给这些照片打上标签。
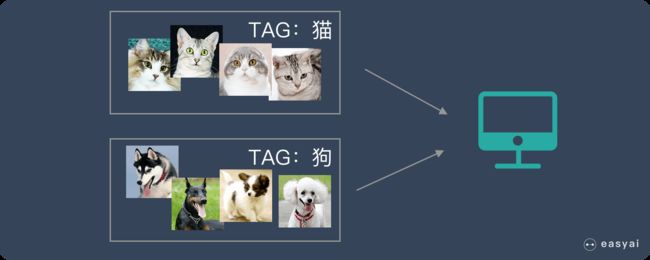
我们给照片打的标签就是“正确答案”,机器通过大量学习,就可以学会在新照片中认出猫和狗。
2、非监督学习(UL)要解决的是另外一种问题。我们喂给机器很多特征数据(输入值),是希望机器通过学习找到输入数据中是不是存在某种共性特征,结构(比如都像猫),或者数据特征值之间是不是存在某种关联。而不是像监督学习那样希望预测输出结果。(没老师教)
非监督学习要解决的问题也可以分成两大类:输入数据聚类(Clustering)和输入特征变量关联(Correlation)。
常用的非监督学习算法有:
1.K均值聚类(K-Means Clustering)
2.具有噪声的基于密度的聚类方法(Density-based Spatial Clustering ofApplications with Noise:DBSCAN)
3.主成分分析算法(Principal Component Analysis ,PCA)
4.自组织映射神经网络(Self-Organizing Map, SOM)
5.受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)
我们把一堆猫和狗的照片给机器,不给这些照片打任何标签,但是我们希望机器能够将这些照片分分类。

通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。对于机器来说,相当于分成了 A、B 两类。
3、强化学习(RL)不同于监督学习和非监督学习。在强化学习(RL)中没有原始已知数据可以学习。强化学习面对的是一个不断变化的状态空间,要解决的是一个决策链问题。(老师拿着棍子教)
其目的是找到在当前环境(状态空间)下最佳决策是什么。这里的挑战是,当下的决策好坏当下无法验证和评估,要根据多次决策以后才能知道。就像下棋,当前的决策(棋子落点)要在五步十步棋之后才能判断是好是坏。所以强化学习中并没有大量的原始已知输入数据,机器需要在变化的环境中通过大量的多次的试错学习,再根据某种规则找到产生最佳结果的最佳路径,从而做出最佳决策。比较常见的应用有下棋(包括下围棋和象棋)、机器人、自动驾驶等。
总结:
监督学习(SL)中有已知的输入数据和输出数据,相当于看着样本学习。非监督学习中没有输出数据,相当于自己学习。其学习目的是找到输入数据中存在的结构(Structure)和模式(Pattern)。强化学习即没有输入数据也没有输出数据,只有某种规则,相当于试错学习。其目的是在大量可能路径中寻找最佳决策或者路径。

关于强化学习:
强化学习(Q-Learning,Sarsa)_nakaizura-CSDN博客_强化学习
强化学习入门总结_菜鸟很菜的专栏-CSDN博客_强化学习
强化学习轻松入门 - 知乎