一文给你解决linux内存源码分析- SLAB分配器概述(超详细)
SLAB分配器概述
-
管理区页框分配器,这里我们简称为页框分配器,在页框分配器中主要是管理物理内存,将物理内存的页框分配给申请者,而且我们知道也可页框大小为4K(也可设置为4M),这时候就会有个问题,如果我只需要1KB大小的内存,页框分配器也不得不分配一个4KB的页框给申请者,这样就会有3KB被白白浪费掉了。为了应对这种情况,在页框分配器上一层又做了一层SLAB层,SLAB分配器的作用就是从页框分配器中拿出一些页框,专门把这些页框拆分成一小块一小块的小内存,当申请者申请的是小内存时,系统就会从SLAB中获取一小块分配给申请者。它们的整个关系如下图:

-
可以看出,SLAB分配器和页框分配器并没有什么直接的联系,对于页框分配器来说,SLAB分配器也只是一个从它那里申请页框的申请者而已。
-
在SLAB分配器中将SLAB分为两大类:专用SLAB和普通SLAB。专用SLAB用于特定的场合(比如TCP有自己专用的SLAB,当TCP模块需要小内存时,会从自己的SLAB中分配),而普通SLAB就是用于常规分配的时候。我们可以使用命令查看SLAB的状态
cat /proc/slabinfo命令结果如下:

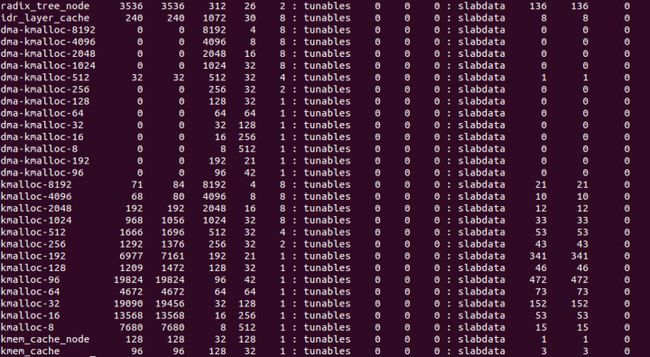
-
如刚才所有,我们看到有些SLAB的名字比较特别,如TCP,UDP,dquot这些,它们都是专用SLAB,专属于它们自己的模块。而后面这张图,如kmalloc-8,kmalloc-16...还有dma-kmalloc-96,dma-kmalloc-192...这些都是普通SLAB,当需要为一些小数据分配内存时(比如一个结构体),就会从这些普通SLAB中获取内存。值得注意的是,对于kmalloc-8这些普通SLAB,都有一个对应的dma-kmalloc-8这种类型的普通SLAB,这种类型是专门使用了ZONE-DMA区域的内存,方便用于DMA模式申请内存。
-
在SLAB中,可分配的内存块称之为对象,在后面那张图中,如kmalloc-8这个普通SLAB,里面所有的对象都是8B大小,同理,kmalloc-16中的对象都是以16B为大小。当你申请1B~8B的内存时,系统会从kmalloc-8中分配一个对象给你,当你申请8B~16B的内存时,系统会从kmalloc-16里给你分配。虽然即使申请5B,分配了一个8B的对象,还有3B空闲,但这样设计已经大大减小了内存碎片化了,保证了碎片内存不会超过50%(kmalloc-8除外)。需要注意,在kmalloc-8中申请到的对象,释放时也会回到kmalloc-8中。
-
除了减小了内存碎片化,SLAB还有一个作用,提高了系统的效率,当对象拥有者释放一个对象后,SLAB的处理是仅仅标记对象为空闲,并不做多少处理,而又有申请者申请相应大小的对象时,SLAB会优先分配最近释放的对象,这样这个对象甚至有可能还在硬件高速缓存中,有点类似管理区页框分配器中每CPU高速缓存的做法。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
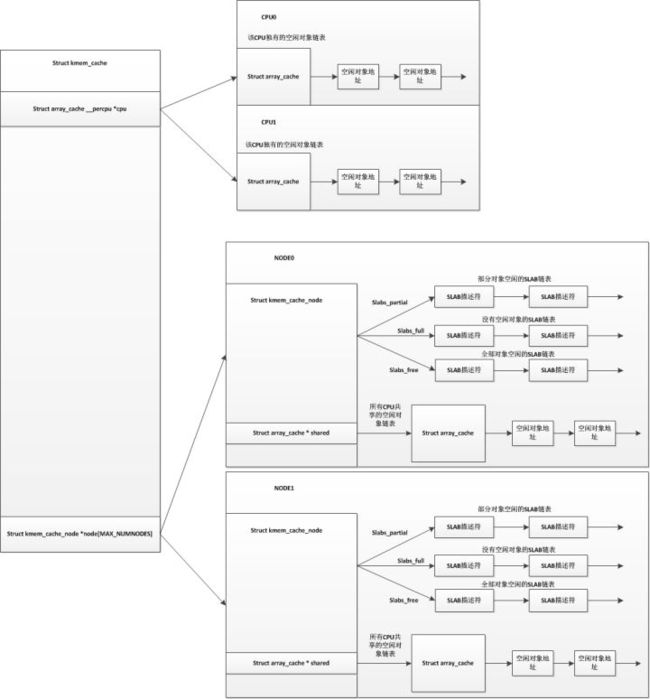
kmem_cache结构
-
虽然叫SLAB分配器,但是在SLAB分配器中,最顶层的数据结构却不是SLAB,而是kmem_cache,我们暂且叫它SLAB缓存吧,每个SLAB缓存都有它自己的名字,就是上图中的kmalloc-8,kmalloc-16等。总的来说,kmem_cache结构用于描述一种SLAB,并且管理着这种SLAB中所有的对象。所有的kmem_cache结构会保存在以slab_caches作为头的链表中。在内核模块中可以通过kmem_cache_create自行创建一个kmem_cache用于管理属于自己模块的SLAB。
-
我们先看看kmem_cache结构:
/* slab分配器中的SLAB高速缓存 */
struct kmem_cache {
/* 指向包含空闲对象的本地高速缓存,每个CPU有一个该结构,当有对象释放时,优先放入本地CPU高速缓存中 */
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
/* 要转移进本地高速缓存或从本地高速缓存中转移出去的对象的数量 */
unsigned int batchcount;
/* 本地高速缓存中空闲对象的最大数目 */
unsigned int limit;
/* 是否存在CPU共享高速缓存,CPU共享高速缓存指针保存在kmem_cache_node结构中 */
unsigned int shared;
/* 对象长度 + 填充字节 */
unsigned int size;
/* size的倒数,加快计算 */
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
/* 高速缓存永久属性的标识,如果SLAB描述符放在外部(不放在SLAB中),则CFLAGS_OFF_SLAB置1 */
unsigned int flags; /* constant flags */
/* 每个SLAB中对象的个数(在同一个高速缓存中slab中对象个数相同) */
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/* 一个单独SLAB中包含的连续页框数目的对数 */
unsigned int gfporder;
/* 分配页框时传递给伙伴系统的一组标识 */
gfp_t allocflags;
/* SLAB使用的颜色个数 */
size_t colour;
/* SLAB中基本对齐偏移,当新SLAB着色时,偏移量的值需要乘上这个基本对齐偏移量,理解就是1个偏移量等于多少个B大小的值 */
unsigned int colour_off;
/* 空闲对象链表放在外部时使用,其指向的SLAB高速缓存来存储空闲对象链表 */
struct kmem_cache *freelist_cache;
/* 空闲对象链表的大小 */
unsigned int freelist_size;
/* 构造函数,一般用于初始化这个SLAB高速缓存中的对象 */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
/* 存放高速缓存名字 */
const char *name;
/* 高速缓存描述符双向链表指针 */
struct list_head list;
int refcount;
/* 高速缓存中对象的大小 */
int object_size;
int align;
/* 5) statistics */
/* 统计 */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/* 对象间的偏移 */
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
/* 用于分组资源限制 */
struct memcg_cache_params *memcg_params;
#endif
/* 结点链表,此高速缓存可能在不同NUMA的结点都有SLAB链表 */
struct kmem_cache_node *node[MAX_NUMNODES];
};-
从结构中可以看出,在这个kmem_cache中所有对象的大小是相同的(object_size),并且此kmem_cache中所有SLAB的大小也是相同的(gfporder、num)。
-
在这个结构中,最重要的可能就属struct kmem_cache_node * node[Max_NUMNODES]这个指针数组了,指向的struct kmem_cache_node中保存着slab链表,在NUMA架构中每个node对应数组中的一个元素,因为每个SLAB高速缓存都有可能在不同结点维护有自己的SLAB用于这个结点的分配。我们看看struct kmem_cache_node:
/* SLAB链表结构 */
struct kmem_cache_node {
/* 锁 */
spinlock_t list_lock;
/* SLAB用 */
#ifdef CONFIG_SLAB
/* 只使用了部分对象的SLAB描述符的双向循环链表 */
struct list_head slabs_partial; /* partial list first, better asm code */
/* 不包含空闲对象的SLAB描述符的双向循环链表 */
struct list_head slabs_full;
/* 只包含空闲对象的SLAB描述符的双向循环链表 */
struct list_head slabs_free;
/* 高速缓存中空闲对象个数(包括slabs_partial链表中和slabs_free链表中所有的空闲对象) */
unsigned long free_objects;
/* 高速缓存中空闲对象的上限 */
unsigned int free_limit;
/* 下一个被分配的SLAB使用的颜色 */
unsigned int colour_next; /* Per-node cache coloring */
/* 指向这个结点上所有CPU共享的一个本地高速缓存 */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
/* 两次缓存收缩时的间隔,降低次数,提高性能 */
unsigned long next_reap;
/* 0:收缩 1:获取一个对象 */
int free_touched; /* updated without locking */
#endif
/* SLUB用 */
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};-
在这个结构中,最重要的就是slabs_partial、slabs_full、slabs_free这三个链表头。
-
slabs_partial:维护部分对象被使用了的SLAB链表,保存的是SLAB描述符。
-
slabs_full:维护所有对象都被使用了的SLAB链表,保存的是SLAB描述符。
-
slabs_free:维护所有对象都没被使用的SLAB链表,保存的是SLAB描述符。
-
可能到这里大家会比较郁闷,怎么又有SLAB链表,SLAB到底是什么东西?SLAB就是一组连续的页框,它的描述符结合在页描述符中,也就是页描述符描述SLAB的时候,就是SLAB描述符。这三个链表保存的是这组页框的首页框的SLAB描述符。链表的组织形式与伙伴系统的组织页框的形式一样。
-
刚开始创建kmem_cache完成后,这三个链表都为空,只有在申请对象时发现没有可用的slab时才会创建一个新的SLAB,并加入到这三个链表中的一个中。也就是说kmem_cache中的SLAB数量是动态变化的,当SLAB数量太多时,kmem_cache会将一些SLAB释放回页框分配器中。
-
我们看看SLAB描述符中相关字段:
struct page {
/* First double word block */
/* 用于页描述符,一组标志(如PG_locked、PG_error),也对页框所在的管理区和node进行编号 */
unsigned long flags; /
union {
/* 用于页描述符,当页被插入页高速缓存中时使用,或者当页属于匿名区时使用 */
struct address_space *mapping;
/* 用于SLAB描述符,指向第一个对象的地址 */
void *s_mem; /* slab first object */
};
/* Second double word */
struct {
union {
/* 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像或匿名区中标识存放在页框中的数据的位置,或者它存放一个换出页标识符 */
pgoff_t index; /* Our offset within mapping. */
/* 用于SLAB描述符,指向空闲对象链表 */
void *freelist;
/* 当管理区页框分配器压力过大时,设置这个标志就确保这个页框专门用于释放其他页框时使用 */
bool pfmemalloc;
};
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
/* SLUB使用 */
unsigned long counters;
#else
/* SLUB使用 */
unsigned counters;
#endif
struct {
union {
/* 页框中的页表项计数,如果没有为-1,如果为PAGE_BUDDY_MAPCOUNT_VALUE(-128),说明此页及其后的一共2的private次方个数页框处于伙伴系统中,正在使用时应该是0 */
atomic_t _mapcount;
struct { /* SLUB使用 */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
/* 页框的引用计数,如果为-1,则此页框空闲,并可分配给任一进程或内核;如果大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放内核数据。page_count()返回_count加1的值,也就是该页的使用者数目 */
atomic_t _count; /* Usage count, see below. */
};
/* 用于SLAB时描述当前SLAB已经使用的对象 */
unsigned int active; /* SLAB */
};
};
/* Third double word block */
union {
/* 包含到页的最近最少使用(LRU)双向链表的指针,用于插入伙伴系统的空闲链表中,只有块中头页框要被插入。也用于SLAB,加入到kmem_cache中的SLAB链表中 */
struct list_head lru;
/* SLAB使用 */
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
/* SLAB使用 */
struct slab *slab_page; /* slab fields */
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page->ptl */
#endif
};
/* Remainder is not double word aligned */
union {
/* 可用于正在使用页的内核成分(例如: 在缓冲页的情况下它是一个缓冲器头指针,如果页是空闲的,则该字段由伙伴系统使用,在给伙伴系统使用时,表明的是块的2的次方数,只有块的第一个页框会使用) */
unsigned long private;
#if USE_SPLIT_PTE_PTLOCKS
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
#endif
/* SLAB描述符使用,指向SLAB的高速缓存 */
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
#if defined(WANT_PAGE_VIRTUAL)
/* 线性地址,如果是没有映射的高端内存的页框,则为空 */
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
void *shadow;
#endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
}-
在SLAB描述符中,最重要的可能就是s_mem和freelist这两个指针。s_mem用于指向这段连续页框中第一个对象,freelist指向空闲对象链表。
-
空闲对象链表是一个由数组制成的简单链表,它保存的地方有两种情况:
-
保存在外部,会从SLAB中分配一个对象用于保存新的SLAB的空闲对象链表。
-
保存在内部,保存在这个SLAB所代表的连续页框的头部。
-
不过一般没有什么其他情况空闲对象链表都是保存在内部居多,这里我们只讨论将空闲对象链表保存在内部的情况,这种情况下,这个SLAB所代表的连续页框的头部首先放的就是空闲对象链表,后面接着放的是对象描述符数组(1,2个字节大小),之后紧接着就是对象所代表的内存了,如下图:

-
我们看看freelist数组是怎么形成一个链表的,之前我们也说了分配时会优先分配最近释放的对象,整个freelist跟struct page中的active有很大联系,可以说active决定了下个分配的对象是谁,在freelist数组制作成的链表中,active作为下标,保存目标空闲对象的对象号,在活动过程中,动态修改这个数组中的值。我们用一幅图可以很清楚看出freelist是如何实现:

-
SLAB中的连续页框个数与kmem_cache结构中的gfporder有关,而这个gfporder在初始化时通过对象数量、大小、freelist大小、对象描述符数组大小和着色区计算出来的。而对于对象的大小,也并不是你创建时打算使用的大小,比如,我打算创建一个kmem_cache的对象大小是10字节,而在创建过程中,系统会帮你优化和初始化这些对象,包括将你的对象保存地址放在内存对其标志,在对象的两边放入一些填充区域(RED_ZONE)进行防止越界等工作。
关于SLAB着色
-
看名字很难理解,其实又很好理解,我们知道内存需要处理时要先放入CPU硬件高速缓存中,而CPU硬件高速缓存与内存的映射方式有多种。在同一个kmem_cache中所有SLAB都是相同大小,都是相同连续长度的页框组成,这样的话在不同SLAB中相同对象号对于页框的首地址的偏移量也相同,这样有很可能导致不同SLAB中相同对象号的对象放入CPU硬件高速缓存时会处于同一行,当我们交替操作这两个对象时,CPU的cache就会交替换入换出,效率就非常差。SLAB着色就是在同一个kmem_cache中对不同的SLAB添加一个偏移量,就让相同对象号的对象不会对齐,也就不会放入硬件高速缓存的同一行中,提高了效率,如下图:

-
着色空间就是前端的空闲区域,这个区有大小都是在分配新的SLAB时计算好的,计算方法很简单,node结点对应的kmem_cache_node中的colour_next乘上kmem_cache中的colour_off就得到了偏移量,然后colour_next++,当colour_next等于kmem_cache中的colour时,colour_next回归到0。
偏移量 = kmem_cache.colour_off * kmem_cache.node[NODE_ID].colour_next;
kmem_cache.node[NODE_ID].colour_next++;
if (kmem_cache.node[NODE_ID].colour_next == kmem_cache.colour)
kmem_cache.node[NODE_ID].colour_next = 0;本地CPU空闲对象链表
-
现在说说本地CPU空闲对象链表。这个在kmem_cache结构中用cpu_cache表示,整个数据结构是struct array_cache,它的目的是将释放的对象加入到这个链表中,我们可以先看看数据结构:
struct array_cache {
/* 可用对象数目 */
unsigned int avail;
/* 可拥有的最大对象数目,和kmem_cache中一样 */
unsigned int limit;
/* 同kmem_cache,要转移进本地高速缓存或从本地高速缓存中转移出去的对象的数量 */
unsigned int batchcount;
/* 是否在收缩后被访问过 */
unsigned int touched;
/* 伪数组,初始没有任何数据项,之后会增加并保存释放的对象指针 */
void *entry[]; /*
};-
这个本地CPU空闲对象链表的存在与伙伴系统中的每CPU页框分配器的存在原因一样,都有两点:
-
每个CPU都有它们自己的硬件高速缓存,当此CPU上释放对象时,可能这个对象很可能还在这个CPU的硬件高速缓存中,所以内核为每个CPU维护一个这样的链表,当需要新的对象时,会优先尝试从当前CPU的本地CPU空闲对象链表获取相应大小的对象。
-
减少锁的竞争,试想一下,假设多个CPU同时申请一个大小的slab,这时候如果没有本地CPU空闲对象链表,就会导致分配流程是互斥的,需要上锁,就导致分配效率低。
-
这个本地CPU空闲对象链表在系统初始化完成后是一个空的链表,只有释放对象时才会将对象加入这个链表。当然,链表对象个数也是有所限制,其最大值就是limit,链表数超过这个值时,会将batchcount个数的对象返回到所有CPU共享的空闲对象链表(也是这样一个结构)中。
-
注意在array_cache中有一个entry数组,里面保存的是指向空闲对象的首地址的指针,注意这个链表是在kmem_cache结构中的,也就是kmalloc-8有它自己的本地CPU高速缓存链表,dquot也有它自己的本地CPU高速缓存链表,每种类型kmem_cache都有它自己的本地CPU空闲对象链表。
所有CPU共享的空闲对象链表
-
原理和本地CPU空闲对象链表一样,唯一的区别就是所有CPU都可以从这个链表中获取对象,一个常规的对象申请流程是这样的:系统首先会从本地CPU空闲对象链表中尝试获取一个对象用于分配;如果失败,则尝试来到所有CPU共享的空闲对象链表链表中尝试获取;如果还是失败,就会从SLAB中分配一个;这时如果还失败,kmem_cache会尝试从页框分配器中获取一组连续的页框建立一个新的SLAB,然后从新的SLAB中获取一个对象。对象释放过程也类似,首先会先将对象释放到本地CPU空闲对象链表中,如果本地CPU空闲对象链表中对象过多,kmem_cache会将本地CPU空闲对象链表中的batchcount个对象移动到所有CPU共享的空闲对象链表链表中,如果所有CPU共享的空闲对象链表链表的对象也太多了,kmem_cache也会把所有CPU共享的空闲对象链表链表中batchcount个数的对象移回它们自己所属的SLAB中,这时如果SLAB中空闲对象太多,kmem_cache会整理出一些空闲的SLAB,将这些SLAB所占用的页框释放回页框分配器中。
-
这个所有CPU共享的空闲对象链表也不是肯定会有的,kmem_cache中有个shared字段如果为1,则这个kmem_cache有这个高速缓存,如果为0则没有。
总结
整个框架已经说明结束了,我们用一幅图进行整理: