RabbitMQ详解
什么是RabbitMQ:
MQ(Message Queue)消息队列
消息队列中间件,是分布式系统中的重要组件
主要解决,异步处理,应用解耦,流量削峰等问题
从而实现高性能,高可用,可伸缩(增加服务器)和最终一致性的架构
使用较多的消息队列产品:RabbitMQ,RocketMQ,ActiveMQ,ZeroMQ,Kafka等
异步处理:
用户注册后,需要发送验证邮箱和手机验证码
将注册信息写入数据库,发送验证邮件,发送手机,三个步骤全部完成后,返回给客户端

应用解耦:
场景:订单系统需要通知库存系统
如果库存系统异常,则订单调用库存失败,导致下单失败
原因:订单系统和库存系统耦合度太高
该订阅可以说是获取,基本一对一

订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户,下单成功
库存系统:订阅下单的消息,获取下单信息,库存系统根据下单信息,再进行库存操作
假如:下单的时候,库存系统不能正常运行,也不会影响下单,因为下单后
订单系统写入消息队列就不再关心其他的后续操作了,实现了订单系统和库存系统的应用解耦
所以说,消息队列是典型的:生产者消费者模型
生产者(订单系统)不断的向消息队列中生产消息,消费者(库存系统)不断的从队列中获取消息
因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的入侵,这样就实现了生产者和消费者的解耦
流量削峰:
抢购,秒杀等业务,针对高并发的场景
因为流量过大,暴增会导致应用挂掉,为解决这个问题,在前端加入消息队列(限制个数)

用户的请求,服务器接收后,首先写入消息队列,如果超过队列的长度,就抛弃,甩一个秒杀结束的页面
说白了,秒杀成功的就是进入队列的用户
背景知识介绍:
AMQP高级消息队列协议
即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议
协议:数据在传输的过程中必须要遵守的规则
基于此协议的客户端可以与消息中间件传递消息
并不受产品、开发语言等条件的限制(我们操作编程时,操作的就是这个协议)
JMS:
Java Message Server,Java消息服务应用程序接口, 一种规范,和JDBC担任的角色类似
是一个Java平台中关于面向消息中间件的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信
二者的联系:
JMS是定义了统一接口,统一消息操作,AMQP通过协议统一数据交互格式
JMS必须是java语言,AMQP只是协议,与语言无关
Erlang语言:
Erlang(['ə:læŋ])是一种通用的面向并发的编程语言,它由瑞典电信设备制造商爱立信所辖的CSLab开发
目的是创造一种可以应对大规模并发活动的编程语言和运行环境
最初是由爱立信专门为通信应用设计的,比如控制交换机或者变换协议等,因此非常适合构建分布式,实时软并行计算系统
Erlang运行时环境是一个虚拟机,有点像Java的虚拟机,这样代码一经编译,同样可以随处运行
为什么选择RabbitMQ:
我们开篇说消息队列产品那么多,为什么偏偏选择RabbitMQ呢:
先看命名:兔子行动非常迅速而且繁殖起来也非常疯狂,所以就把Rabbit用作这个分布式软件的命名(就是这么简单)
Erlang开发,AMQP的最佳搭档,安装部署简单,上手门槛低
企业级消息队列,经过大量实践考验的高可靠,大量成功的应用案例,例如阿里、网易等一线大厂都有使用
有强大的WEB管理页面
强大的社区支持,为技术进步提供动力
支持消息持久化、支持消息确认机制、灵活的任务分发机制等,支持功能非常丰富
集群扩展很容易,并且可以通过增加节点实现成倍的性能提升
总结:如果你希望使用一个可靠性高、功能强大、易于管理的消息队列系统那么就选择RabbitMQ
如果你想用一个性能高,但偶尔丢点数据不是很在乎可以使用kafka或者zeroMQ
kafka和zeroMQ的性能爆表,绝对可以压RabbitMQ一头,但若操作java,即我们追求稳定,所以用RabbitMQ
若操作大数据,则使用kafka,因为数据太多,偶尔丢失几个并没有很大的影响,且提升了性能,各有各的优点
RabbitMQ各组件功能:
注意:除了生产者和消费者外,中间的部分可以看成一个整体(该整体也可以看成两个整体)
即那个信道可以看成整体中的一个整体,中间部分的另外一个整体来访问信道
在操作了后面的编程测试中,你就知道为什么这样说了
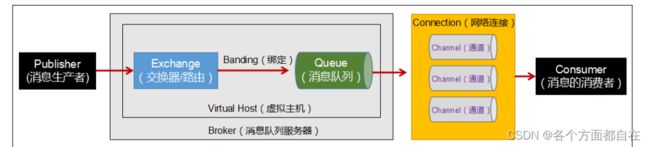
Broker:消息队列服务器实体
Virtual Host:虚拟主机
标识一批交换机、消息队列和相关对象,形成的整体
虚拟主机是共享相同的身份认证和加密环境的独立服务器域
每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制
vhost是AMQP概念的基础,RabbitMQ默认的vhost是 /,必须在链接时指定
虚拟主机可以有多个,所以需要指定,即我们操作java时或者说连接时,需要指定连接哪个虚拟主机
Exchange:交换器(路由)
用来接收生产者发送的消息并将这些消息路由给服务器中的队列
Queue:消息队列
用来保存消息直到发送给消费者
它是消息的容器,也是消息的终点
一个消息可投入一个或多个队列
消息一直在队列里面,等待消费者连接到这个队列将其取走
Banding:绑定,用于消息队列和交换机之间的关联,即只会给对应已经绑定的队列,没有绑定的基本不会给(因为多个队列)
Channel:通道(信道)
RabbitMq对信道采用多路复用连接(线程或者进程可以操作多连接,或者说线程的多个线程,该连接或者线程都可以看成信道)
即多路复用连接中的一条独立的双向数据流通道
信道是建立在真实的TCP连接内的 虚拟链接
AMQP命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,都是通过信道完成的
我们的生产者和消费者一般都需要通过连接来创建管道,来进行操作
所以上面的图未必一定是那样的,他显示的只是对应信息的传递
实际上他们也可以是部分组件的构成,后面的RabbitMQ模式介绍会说明
因为对于操作系统来说,建立和销毁TCP连接都是非常昂贵的开销,所以引入了信道的概念,用来复用TCP连接
Connection:网络连接,比如一个TCP连接
Publisher:消息的生产者,也是一个向交换器发布消息的客户端应用程序
Consumer:消息的消费者,表示一个从消息队列中取得消息的客户端应用程序
Message:消息
消息是不具名的,它是由消息头和消息体组成
消息体是不透明的,而消息头则是由一系列的可选属性组成
这些属性包括routing-key(路由键)、priority(优先级)、delivery-mode(消息可能需要持久性存储,消息的路由模式)
怎么用RabbitMQ:
想要安装RabbitMQ,必须先安装erlang语言环境,类似安装tomcat,必须先安装JDK
查看匹配的版本:https://www.rabbitmq.com/which-erlang.html
假如你使用RabbitMQ的3.8.6版本,那么对应的Erlang需要使用21.3到23.x
即最小的版本是21.3(包括21.3),最大的版本是23.x(包括23.x)
若不在这个范围里,那么可能会出现问题,甚至可能是用不了

RabbitMQ安装启动:
erlang下载:https://dl.bintray.com/rabbitmq-erlang/rpm/erlang
socat下载:http://repo.iotti.biz/CentOS/7/x86_64/socat-1.7.3.2-5.el7.lux.x86_64.rpm,一般RabbitMQ也需要这个,否则可能操作不了,如安装不了,或者安装了,但可能操作不了了,比如程序访问不了RabbitMQ,虽然程序没有问题,但RabbitMQ有问题(可能接收连接的包没有,所以需要他),所以这里最好加上,防止上面说明的情况
RabbitMQ下载:https://www.rabbitmq.com/install-rpm.html#downloads
如果有对应的网站访问不了,可用直接去如下的地址进行下载:
链接:https://pan.baidu.com/s/1MagdVW-Ekh8af1h_8AtqXQ
提取码:alsk
安装(Linux上安装):
可用将对应的文件直接拖到Xshell里面(文件夹不可以)
[root@localhost opt]
[root@localhost opt]
[root@localhost opt]
启动后台管理插件:
[root@localhost opt]
启动RabbitMQ:
[root@localhost opt]
[root@localhost opt]
[root@localhost opt]
[root@localhost opt]
[root@localhost opt]
查看进程:
[root@localhost opt]
测试:
关闭防火墙: systemctl stop firewalld(service可以省略)
浏览器输入:http://ip:15672(ip是对应启动了rabbitmq服务器的ip),注意:要先启动,否则没有对应的页面
没有对应页面返回的,浏览器自然显示找不到页面,请求的信息是浏览器读取自带的请求信息
因为握手连接失败,即没有对应的服务器来操作请求
默认帐号密码:guest,guest用户默认不允许远程连接,只能本地连接(会有提示),这是rabbitmq规定的,所以我们需要创建账号
创建账号:
[root@localhost opt]
设置用户角色:
[root@localhost opt]
设置用户权限:
[root@localhost opt]
查看当前用户和角色:
[root@localhost opt]
修改对应用户的密码:
[root@localhost opt]
管理界面介绍
overview:概览
connections:查看链接情况
channels:信道(通道)情况
Exchanges:交换机(路由)情况,默认4类7个

可以看到,有direct,fanout,headers,topic四个类型,有7个(都是 / ),一开始的默认个数
其中有D的,代表持久化
Queues:消息队列情况
Admin:管理员列表
端口:
5672:RabbitMQ提供给编程语言客户端链接的端口,浏览器访问时,没有对应服务器来操作请求,即握手失败
因为他这个端口是不是操作http协议的,就如我们不能直接访问3306数据库,相当于对应的客户端连接
15672:RabbitMQ管理界面的端口,浏览器访问时,是对应管理界面,这个端口操作的是http协议
25672:RabbitMQ集群的端口,这个访问不了,虽然有对应的服务器来操作请求
但浏览器访问时(端口操作http协议),会持续的重定向访问(好像每过几秒就访问),不用太过在意
即没有具体的响应信息出现
而15672基本只能是看对应情况信息,基本不能操作数据,所以操作数据的部分需要5672端口来操作,即需要程序来操作
RabbitMQ快速入门:
创建一个maven项目,导入对应依赖:
<dependencies>
<dependency>
<groupId>com.rabbitmqgroupId>
<artifactId>amqp-clientartifactId>
<version>5.7.3version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.25version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.9version>
dependency>
dependencies>
日志依赖log4j(可以创建log4j.properties,也可以不创建,这里就不创建了) :
# 输出方式
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
# 表示输出信息为out级别,即输出到控制台的信息(即位置)
log4j.appender.stdout.Target=System.out
# 表示输出格式
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# 打印信息格式
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %m%n
# log4j.appender.file = 表示文件输出方式
log4j.appender.file=org.apache.log4j.FileAppender
# log4j.appender.file.File = 表示文件输出位置
log4j.appender.file.File=rebbitmq.log
# log4j.appender.file.layout = 表示输出格式
log4j.appender.file.layout=org.apache.log4j.PatternLayout
# log4j.appender.file.layout.ConversionPattern = 表示打印格式
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n
# log4j.rootLogger = 表示根日志级别
log4j.rootLogger=debug, stdout,file
创建连接:
先创建好虚拟主机:

这里只需要Name属性即可,其他两个属性可以不写,因为他们两个属性基本只是相当于描述信息而已
创建如下的类:

对应的ConnectionUtil类:
package util;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class ConnectionUtil {
public static Connection getConnection() throws Exception{
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("192.168.164.128");
connectionFactory.setPort(5672);
connectionFactory.setVirtualHost("/lagou");
connectionFactory.setUsername("laosun");
connectionFactory.setPassword("123123");
Connection connection = connectionFactory.newConnection();
return connection;
}
public static void main(String[] args) throws Exception {
Connection connection = getConnection();
System.out.println(connection);
connection.close();
}
}
RabbitMQ模式 :
RabbitMQ提供了6种消息模型,但是第6种其实是RPC(远程调用),并不是MQ,因此我们只学习前5种
在线手册(或者说官网):https://www.rabbitmq.com/getstarted.html

也可以点击如下:
点击下面的Tutorials也可以直接到https://www.rabbitmq.com/getstarted.html里面去(新的窗口)
5种消息模型,大体分为两类:
1和2属于点对点
3、4、5属于发布订阅模式(一对多)
点对点模式:P2P(point to point)模式包含三个角色:
消息队列(queue),发送者(sender),接收者(receiver)
每个消息发送到一个特定的队列中,接收者从中获得消息
队列中保留这些消息,直到他们被消费或超时
特点:
每个消息只有一个消费者,一旦消费,消息就不在队列中了
发送者和接收者之间没有依赖性,发送者发送完成,不管接收者是否运行
都不会影响消息发送到队列中(我给你发微信,不管你看不看手机,反正我发完了)
接收者成功接收消息之后需向对象应答成功(确认)
如果希望发送的每个消息都会被成功处理,那需要P2P
发布订阅模式:publish(Pub)/subscribe(Sub)
pub/sub模式包含三个角色:交换机(exchange),发布者(publisher),订阅者(subcriber)
多个发布者将消息发送交换机,系统将这些消息传递给多个订阅者
特点:
每个消息可以有多个订阅者
发布者和订阅者之间在时间上有依赖,对于某个交换机的订阅者,必须创建一个订阅后,才能消费发布者的消息
为了消费消息,订阅者必须保持运行状态;类似于,看电视直播
如果希望发送的消息被多个消费者处理,可采用本模式
所以他们就分为一对一,一对多
简单模式:
下面引用官网的一段介绍:
RabbitMQ本身只是接收,存储和转发消息,并不会对信息进行处理
类似邮局,处理信件的应该是收件人而不是邮局(不可能随便拆你的信件)

对应的目录:
生产者P:
package simplest;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
String msg = "Hello,RabbitMq";
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("queue1",false,false,false,null);
channel.basicPublish("","queue1",null,msg.getBytes());
System.out.println("已发送");
channel.close();
connection.close();
}
}
消费者C:
package simplest;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println(s);
}
};
channel.basicConsume("queue1",true,defaultConsumer);
}
}
启动生产者,查看对应的队列信息,发现变成了1(Ready和Total变成了1),再次启动消费者
前往管理端查看队列中的信息,所有信息都已经处理和确认(Ready和Total变成了0)
Ready:准备好的数据个数,也就是说还没有被消费掉,当消费者消费时,对应的数据就会没有
Total:全部的数据的总个数
他们之间的数据,可以说是该队列中准备好的信息
注意刷新:

右边是每5秒刷新一下数据(或者说去对应的RabbitMQ里得到一次数据)
我们的浏览器刷新只是刷新界面,对应RabbitMQ里的数据并不会刷新
而当前的页面会每过五秒去对应的RabbitMQ中获取数据,所以说是每5秒刷新一次,且是最小的间隔时间
因为太短的话,每次获取会影响性能的,而5秒刚好居中

消息确认机制ACK:
通过刚才的案例可以看出,消息一旦被消费,消息就会立刻从队列中移除
RabbitMQ如何得知消息被消费者接收:
如果消费者接收消息后,还没执行操作就抛异常宕机(消费方)导致消费失败,但是RabbitMQ无从得知
以为进行了处理(即对应显示消费了,但是并没有实际处理)
这样消息就丢失了或者没有进行他要的操作,导致消费者没有消费且队列也没有对应的消息,即你还不知道,这是非常严重的
比如库存(一对一的,假设的),并没有减少或者说没有对应通知
使得实际上已经没有存货了或不知道有订单(库存还有,可以发送订单)
但订单还有非常多,使得来不及操作订单给出具体货物,造成客户的投诉等等
因为订单发送并没有失败,只是我们接收时,失败了(方法不执行了),但订单是成功的
注意:生产者和消费者只是在数据上的一个解释,并不是说消费者就一定是客户端
比如这里订单代表生产者,但是消费者却是库存(服务器),又比如,发布订阅,视频账号是生产者(服务器),消费者是客户端
所以这些的说明都只是说明而已,就如客户端和服务区之间的说明
只要是接收的,那么就是服务器,而这里只要是接收的就是消费者
因此,RabbitMQ有一个ACK机制,当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收
ACK:(Acknowledge character)即是确认字符,在数据通信中,接收站发给发送站的一种传输类控制字符
表示发来的数据已确认接收无误,类似于我们在使用http请求时,http的状态码200就是告诉我们服务器执行成功
整个过程就相当于快递员将包裹送到你手里,并且需要你的签字,并拍照回执
不过这种回执ACK分为两种情况:
自动ACK:消息接收后,消费者立刻自动发送ACK(快递放在快递柜,打开那么就相当于自动发送ACK了)
手动ACK:消息接收后,不会发送ACK,需要手动调用(快递必须本人签收)
两种情况如何选择,需要看消息的重要性:
如果消息不太重要,丢失也没有影响,自动ACK会比较方便
如果消息非常重要,最好消费完成手动ACK,因为如果自动ACK消费后,RabbitMQ就会把消息从队列中删除
如果此时消费者抛异常宕机,那么消息就永久丢失了,而手动的处理,并不会删除对应消息,等待确认删除
当对应消费者关闭后,又会重新回到没有消费的情况,用来防止中间出现问题,使得消息没有了
比如库存(一对一的,也是假设的),这时若库存没有减少或者说没有对应通知(处在未处理时刻)
可以显示对应订单待操作等消息(因为还没有确认之前,订单是显示待操作的)
上面库存只是举个例子而已,实际上大多数还要更加复杂或者不是这样,所以例子可以不必理会,只是对消息的一种说明而已
我们只需要知道对应消息的变化即可,因为我们可以通过这个变化,而知道有什么需求要这样
修改手动消息确认:
channel.basicConsume("queue1",false,defaultConsumer);
结果如下:

其中Unacked:未确认,表示该信息对于生产者来说,还没有处理,1表示未确认的数据个数,或者说等待确认删除的消息
当我们退出程序(消费者的程序),那么这个等待也就失效,因为都退出了,即就会回到准备状态,而不是未确认状态
解决问题代码(RecerByACK类):
package simplest;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class RecerByACK {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println(s);
channel.basicAck(envelope.getDeliveryTag(),false);
}
};
channel.basicConsume("queue1",false,defaultConsumer);
}
}
工作队列模式:
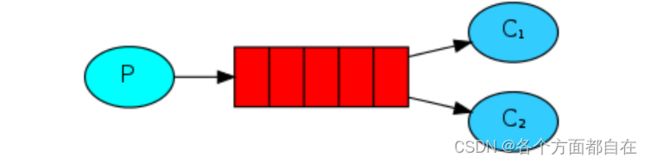
之前我们学习的简单模式,一个消费者来处理消息,如果生产者生产消息过快过多,而消费者的能力有限
就会产生消息在队列中堆积(生活中的滞销)
一个烧烤师傅,一次烤50支羊肉串,就一个人吃的话,烤好的肉串会越来越多,怎么处理:
多招揽客人进行消费即可,当我们运行许多消费者程序时,消息队列中的任务会被众多消费者共享
但其中某一个消息只会被一个消费者获取(100支肉串20个人吃,但是其中的某支肉串只能被一个人吃)
对应的目录:
生产者P:
package work;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_work_queue", false, false, false, null);
for(int i =1 ;i<=100; i++) {
String msg = "羊肉串 ==> "+ i;
channel.basicPublish("", "test_work_queue", null, msg.getBytes());
System.out.println("新鲜出炉:" + msg);
}
channel.close();
connection.close();
}
}
消费者1 :
package work;
import com.rabbitmq.client.*;
import simplest.Sender;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer1 {
private static int i = 1;
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_work_queue", false, false, false, null);
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【顾客1】吃掉" + s + "! 总共吃掉【" + i +"】串!");
i++;
try {
Thread.sleep(200);
} catch (Exception e) {
e.printStackTrace();
}
channel.basicAck(envelope.getDeliveryTag(),false);
}
};
channel.basicConsume("test_work_queue",false,defaultConsumer);
}
}
消费者2:
package work;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer2 {
private static int i = 1;
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_work_queue", false, false, false, null);
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【顾客2】吃掉" + s + "! 总共吃掉【" + i +"】串!");
i++;
try {
Thread.sleep(900);
} catch (Exception e) {
e.printStackTrace();
}
channel.basicAck(envelope.getDeliveryTag(),false);
}
};
channel.basicConsume("test_work_queue",false,defaultConsumer);
}
}
注意:我们先执行两个消费者,当我们有对应的队列时(没有队列会报错,监听那里)
那么对应的队列连接代码可以删除了(第一次放在消费者里是为了解决没有队列造成的错误),连接由生产者来操作
当然这是需要确定队列(一对一的队列),才在生产者那里进行操作的,因为需要确定队列来发送信息
当队列过多时,那么对应的队列,基本都是一对多的操作,若队列是生产者自己创建
这是是非常麻烦的,因为要创建多个队列并发送信息,且只能给一个队列,万一对应又需要一个队列
那么该生产者就又需要加上对应代码,这是非常麻烦的,虽然消费者也是可以操作多个队列,但不必要,因为一个队列即可
又由于消费者有很多,那么总不能都操作对应的一个队列,所以消费者应该有属于自己的队列
即每个消费者应该都有一个队列,那么若该队列在生产者里,很明显是不行的,因为需要实时的改变,不确定队列个数
所以队列的创建应该在消费者里,但是生产者又要发送,即需要获取队列,这就形成了一个问题
如何确定生产者发送给对应的多个队列呢:使用路由来决定
在一对多操作时,我们只要将队列绑定路由即可解决,即队列应该是对应一个消费者,那时队列的创建需要在消费者里进行
而路由需要在生产者里进行
虽然也可以在消费者里创建,但是消费者是多个,即总不能多次创建或者说执行吧
所以路由在生产者里创建,因为只有一次或者少的次数执行代码(一般是一次,因为对应的账号基本只有一次创建,且基本唯一)
不需要指定队列了,因为会发送给绑定的队列里面,这样就不用在生产者里创建多个队列了
且消费者都有自己的队列,且是他们自己创建的,这里解释了后面操作路由时
队列放在消费者里创建,路由放在生产者里创建的原因,实际上这是根据实际情况来这样编写的
我们其实也可以手动的先绑定,然后在操作,只是需要手动操作而已
但实际上也解决了消费者多次操作获取队列代码的执行,降低了执行代码
但是也只是一个初始化的操作,真正的队列创建还需要是消费者才可(即有创建队列的配置文件)
比如后面的spring的整合,但是不能够随时的读取配置文件,只是将写死在程序里,变成了在配置文件里了(初始化操作)
可以更好扩展(虽然不会随时读取)
我们可以发现,结果是平均分配的,为什么要说平均分配,因为他是数量的平均,与运行速度无关,且对应的信息编号是有顺序的
这是因为排队效应,或者说监听效应,在这之前,我们可以看看如下解释,如下:
注意:若先启动生产者,后启动消费者,由于确定还在,那么接下来的消息
基本上就是全部给第一个启动的消费者了(因为只确定一次,或者说每次的队列创建都会进行确定),所以消费者一般先启动
所以先启动时,那么就一定是确定我们后启动的消费者了
但是由于队列已经确定了,那么中途进入的,不会发送,因为只有一次确定
若这时再次发送信息,那么中途进入的也就会获得分发的信息了
但是上面有一个问题:当我们先运行2个消费者,排队等候消费(取餐),再运行生产者开始生产消息(烤肉串)时
虽然两个消费者的消费速度不一致(线程休眠时间),但是由于分发
导致消费者各自的数量基本是一致的(基本只能差一个没有分发到),如这里100就是各消费50个消息
若是99,那么第一个就是50个消息,第二个就是49个消息
例如:工作中,A同学编码速率高,B同学编码速率低,两个人同时开发一个项目,A10天完
成,B30天完成,A完成自己的编码部分,就无所事事了,等着B完成就可以了,这样是不可以的
应该遵循"能者多劳"效率高的多干点(当然工资肯定高点,需要赚钱吗,总不能少赚点),效率低的少干点
看下面官网是如何给出解决思路的:


channel.basicQos(1);
能者多劳必须要配合手动的ACK机制才生效,因为只有手动确认时
他才会去抢消息或者说告诉队列给他发消息(简称为抢),用来确定他被操作了
防止对应的消息没有进行操作,更加安全,这是规定的,否则不会去抢,这样他就会根据平均的分发得到平均分发的消息
所以我们其实也会看到,谁先执行,那么谁就是操作第一个消息
与执行速度没有关系(第一个,因为刚刚开始还是平均分发的,并不是抢)
之后再进行抢夺(这里就是不会按照平均分发来得到消息了,被无视)
如何避免消息堆积:
workqueue,多个消费者监听同一个队列
或者用线程代替多个消费者,即接收到消息后,通过线程池或者线程,异步消费
也就相当于多个消费者监听同一个队列了,只是在一个程序里面
本质上都是增加消费者来访问同一个队列来避免消息堆积
发布订阅模式 :
看官网:
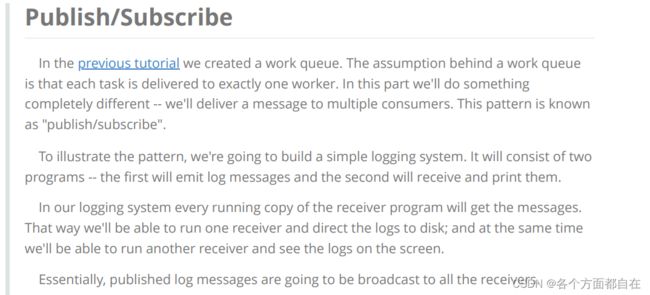

生活中的案例:就是玩抖音快手,众多粉丝关注一个视频主,视频主发布视频
所有粉丝都可以得到视频通知(消息,监听的队列,每个消费者应该都有一个队列对应)

上图中,X就是视频主账号或者说视频主,红色的队列就是粉丝,binding是绑定的意思(关注)
P生产者发送信息给X路由,X将信息转发给绑定X的队列

X队列将信息通过信道发送给消费者,从而进行消费
整个过程,必须先创建路由
路由在生产者程序中创建
因为路由没有存储消息的能力,当生产者将信息发送给路由后,消费者还没有运行,所以没有队列,路由并不知道将信息发送给谁
运行程序的顺序:
先运行生产者(发送者),在运行消费者(接收者)
因为需要路由,然后再执行生产者(发送者)发送信息,这是所有绑定的队列得到信息,消费者又监听到
这时消费者们都有信息了,而第一次由于没有队列的绑定,所有第一次的信息,相当于发送空的
且没有保存下来,被删掉了,或者说发送后,就会删除掉
那么信息的存在就在队列中了,没有队列自然该信息就没有了
可能会是一个判断,是否有无绑定,然后发送信息(这就是保存了),没有自然没有发送(没有保存)
但是最后都会删除路由的信息(虽然路由可以在一定时间类处理多个信息的保存),但只是内存的存留
对应的目录:
生产者:
package ps;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("test_exchange_fanout","fanout");
String msg = "hello,哈哈哈";
channel.basicPublish("test_exchange_fanout", "", null, msg.getBytes());
System.out.println("生产者:" + msg);
channel.close();
connection.close();
}
}
消费者1:
package ps;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_fanout_queue_1", false, false, false, null);
channel.queueBind("test_exchange_fanout_queue_1","test_exchange_fanout","");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者1】 = " +s);
}
};
channel.basicConsume("test_exchange_fanout_queue_1",true,defaultConsumer);
}
}
消费者2(实际上就是修改队列名称和打印的信息,基本就是将信息对应的1修改成2):
package ps;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_fanout_queue_2", false, false, false, null);
channel.queueBind("test_exchange_fanout_queue_2","test_exchange_fanout","");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者2】 = " +s);
}
};
channel.basicConsume("test_exchange_fanout_queue_2",true,defaultConsumer);
}
}
注意:上面有些地方的参数是"",那么因为null是不能够写的,但写上就会报错
问题:路由给多个队列有没有先后顺序,答:没有,就如多线程一样,都是抢占资源(资源可以认为是cpu资源)来确定的,基本是随机,没有顺序
路由模式:
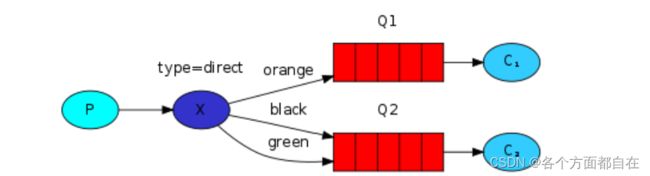
路由会根据类型进行定向分发消息给不同的队列,如图所示
可以理解为是快递公司的分拣中心,整个小区,东面的楼小张送货,西面的楼小王送货
对应的目录:
生产者:
package direct;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("test_exchange_direct","direct");
String msg = "用户注册,【userid=S101】";
channel.basicPublish("test_exchange_direct", "insert", null, msg.getBytes());
System.out.println("[用户系统]:" + msg);
channel.close();
connection.close();
}
}
消费者1:
package direct;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_direct_queue_1", false, false, false, null);
channel.queueBind("test_exchange_direct_queue_1","test_exchange_direct","insert");
channel.queueBind("test_exchange_direct_queue_1","test_exchange_direct","update");
channel.queueBind("test_exchange_direct_queue_1","test_exchange_direct","delete");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者1】 = " +s);
}
};
channel.basicConsume("test_exchange_direct_queue_1",true,defaultConsumer);
}
}
消费者2:
package direct;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_direct_queue_2", false, false, false, null);
channel.queueBind("test_exchange_direct_queue_2","test_exchange_direct","select");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者2】 = " +s);
}
};
channel.basicConsume("test_exchange_direct_queue_2",true,defaultConsumer);
}
}
记住运行程序的顺序,先运行一次Sender(创建路由器)
有了路由器之后,在创建两个Recer1和Recer2,进行队列绑定
再次运行Sender,发出消息
通配符模式:
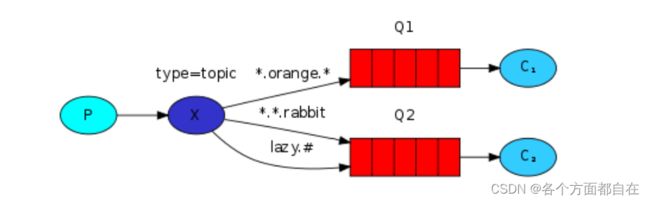
和路由模式90%是一样的
唯独的区别就是路由键支持模糊匹配
匹配符号
*:只能匹配一个词(正好一个词,多一个不行,少一个也不行)
#:匹配0个或更多个词
看一下官网案例:
quick.orange.rabbit
lazy.orange.elephant
quick.orange.fox
lazy.brown.fox
lazy.pink.rabbit
quick.brown.fox
orange
quick.orange.male.rabbit
mysql中模糊查询,可以使用转义来跳过模糊的符号,如 %,因为转义的基本不参加对应的操作,这是mysql的操作
而java的转义,并没有单独自身的转义(js有),除非特殊的符号,如 \n
否则其他的符号不可以,如 \d ,报错,即不会得到d(单独自身的转义)
而其他的特殊的转义(如在字符串里的 \u0023 ,代表#,会参加对应的操作),所有java对应的特殊转义,是没必要的
即下面若出现了生产者路由键有#或者*来判断对应队列时,基本是避免不了的
或者说这是一个不可避免的问题(但通常不会这样写),因为这是java的语法问题
对应的目录:
生产者:
package topic;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("test_exchange_topic","topic");
String msg = "用户注册,【userid=S102】";
channel.basicPublish("test_exchange_topic", "user.register", null, msg.getBytes());
System.out.println("[用户系统]:" + msg);
channel.close();
connection.close();
}
}
消费者1 :
package topic;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_topic_queue_1", false, false, false, null);
channel.queueBind("test_exchange_topic_queue_1","test_exchange_topic","user.#");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者1】 = " +s);
}
};
channel.basicConsume("test_exchange_topic_queue_1",true,defaultConsumer);
}
}
消费者2 :
package topic;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_topic_queue_2", false, false, false, null);
channel.queueBind("test_exchange_topic_queue_2","test_exchange_topic","product.#");
channel.queueBind("test_exchange_topic_queue_2","test_exchange_topic","order.#");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者2】 = " +s);
}
};
channel.basicConsume("test_exchange_topic_queue_2",true,defaultConsumer);
}
}
最后我要说明一下:我们的绑定并不会因为我们程序退出而解除,也就是说,我们绑定过的操作,是会保留的
如上面的模糊匹配的路由键 user.# ,当我们退出,并删掉这个时,启动该消费者,生产者启动
那么也会出现监听的信息,因为原来的绑定还在,而那个绑定操作了信息,即发送的信息给这个消费者了,所有会有信息打印出来
持久化 :
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何避免消息丢失:
消费者的ACK确认机制,可以防止消费者丢失消息
万一在消费者消费之前,RabbitMQ服务器宕机了
对应的RabbitMq服务关闭会删除所有的队列(包括消息)和路由,当然重启自然也包含了关闭操作,那么消息也会丢失
想要将消息持久化,那么 路由和队列都要持久化 才可以,消息也要
否则路由和队列持久化了,但消息没有持久化,也就无意义了,实际上路由可以不持久(针对信息而言)
但队列需要,因为队列不持久化,那么相对应的消息也就不存在的(总体都删掉的,那么也就相当于消息被删掉了,也可以认为是保留元数据,我们通过元数据来操作消息数据的,即认为消息数据在其他位置)
路由但不持久的话,就需要重新运行生产者,相当于抖音服务器停机,若没有持久化,那么你的视频账号就要重新创建了的意思
所有为了方便,我们通常也将路由也进行持久化
注意:若我们消费方一直在监听的话,这时若删除对应的队列
即重启服务器,并不会报错,只有第一次没有队列时才会,这时他也会重新的创建对应的队列(需要时间)
基本上所有的框架要想要永久的保留信息,基本上都要进行存盘,也就是我们说的专业名词:持久化的操作
在上面的模糊匹配中代码进行改动
生产者:
package topic;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.MessageProperties;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("test_exchange_topic","topic",true);
String msg = "用户注册,【userid=S102】";
channel.basicPublish("test_exchange_topic", "user.register",
MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());
System.out.println("[用户系统]:" + msg);
channel.close();
connection.close();
}
}
消费者1(消费者2就不改变了):
package topic;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_exchange_topic_queue_1", true, false, false, null);
channel.queueBind("test_exchange_topic_queue_1","test_exchange_topic","user.#");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者1】 = " +s);
}
};
channel.basicConsume("test_exchange_topic_queue_1",true,defaultConsumer);
}
}
自己进行测试,可以反复的重启RabbitMq服务,命令如下:
systemctl restart rabbitmq-server.service
Spring整合RabbitMQ :
五种消息模型,在企业中应用最广泛的就是最后一种:定向匹配topic(因为最灵活)
一对多也可以操作一对一的,且他是一对多中基本上是最好的一个模式
Spring AMQP 是基于 Spring 框架的AMQP消息解决方案,提供模板化的发送和接收消息的抽象层
提供基于消息驱动的 POJO的消息监听等,简化了我们对于RabbitMQ相关程序的开发
生产端工程:

对应的依赖:
<dependency>
<groupId>org.springframework.amqpgroupId>
<artifactId>spring-rabbitartifactId>
<version>2.0.1.RELEASEversion>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.25version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.9version>
dependency>
spring-rabbitmq-producer.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/rabbit
http://www.springframework.org/schema/rabbit/spring-rabbit.xsd">
<rabbit:connection-factory id="connectionFactory" host="192.168.164.128"
port="5672" username="laosun" password="123123" virtual-host="/lagou"/>
<rabbit:queue name="test_spring_queue_1"/>
<rabbit:admin connection-factory="connectionFactory">rabbit:admin>
<rabbit:topic-exchange name="spring_topic_exchange">
<rabbit:bindings>
<rabbit:binding pattern="msg.#" queue="test_spring_queue_1">rabbit:binding>
rabbit:bindings>
rabbit:topic-exchange>
<bean id="jsonMessageConverter"
class="org.springframework.amqp.support.converter.Jackson2JsonMessageConverter"/>
<rabbit:template id="rabbitTemplate" connection-factory="connectionFactory"
exchange="spring_topic_exchange"
message-converter="jsonMessageConverter">rabbit:template>
beans>
发消息:
package test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.HashMap;
import java.util.Map;
public class Sender {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-producer.xml");
RabbitTemplate bean = context.getBean(RabbitTemplate.class);
Map<String,String> map = new HashMap<>();
map.put("name","叶凡");
map.put("email","[email protected]");
bean.convertAndSend("msg.user",map);
context.close();
}
}
消费端工程:
依赖与生产者一致
spring-rabbitmq-consumer.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/rabbit
http://www.springframework.org/schema/rabbit/spring-rabbit.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<rabbit:connection-factory id="connectionFactory" host="192.168.164.128"
port="5672" username="laosun" password="123123" virtual-
host="/lagou"/>
<rabbit:queue name="test_spring_queue_1"/>
<rabbit:admin connection-factory="connectionFactory">rabbit:admin>
<context:component-scan base-package="listener">context:component-scan>
<rabbit:listener-container connection-factory="connectionFactory">
<rabbit:listener ref="cousumerListener" queue-names="test_spring_queue_1">rabbit:listener>
rabbit:listener-container>
beans>
消费者:
MessageListener接口用于spring容器接收到消息后处理消息
如果需要使用自己定义的类型(自己写的类) 来实现 处理消息时,必须实现该接口,并重写onMessage()方法
相当于之前的监听的对应匿名内部类的那个处理方法
当spring容器接收消息后,会自动交由onMessage()方法进行处理
package listener;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class CousumerListener implements MessageListener {
private static final ObjectMapper mapper = new ObjectMapper();
@Override
public void onMessage(Message message) {
try {
JsonNode jsonNode = mapper.readTree(message.getBody());
String name = jsonNode.get("name").asText();
String email = jsonNode.get("email").asText();
System.out.println(name);
System.out.println(email);
} catch (Exception e) {
e.printStackTrace();
}
}
}
启动项目:
package test;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestRunner {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-consumer.xml");
}
}
由此可见,我们发现将绑定和队列的创建都放在生产者里了,而消费者只进行监听
但实际上这只是初始化而已(因为配置文件的操作,使得变成这样),对应的绑定实际上也可以在消费者进行
但交换机也就执行多次了,所以后续应该需要进行创建并绑定(如rabbit:admin的配置操作,只是这里并没有操作而已)
即一开始的配置文件可以看成初始化的操作
或者你也可以自定义配置文件,来创建队列和绑定,实现实时的获取
接下来你可以启动消费者(交换机和绑定都在生产者里,所以可以先启动消费者)
再启动生产者,就看看消费者日志,发现的确有结果了
最后确认一点:无论对应的队列,交换机,绑定由谁来操作,只要按照顺序即可(先交换机,然后队列,然后绑定),而谁的操作
主要看实际情况而定,也没有必要必须是消费者操作队列和绑定,而生产者操作交换机等等,不要固定死了
只是这个的给谁操作(消费者操作队列和绑定,而生产者操作交换机),是给的一种方案而已(好的方案)
我们启动后,可以试一试将json工具类删除,我们发现,竟然是消费者发生了错误
由此看来,我们的map集合在发送的过程中进行了处理,然后消费者的解析(变成json的那个方法),也只会解析出这个处理
所以对应的消息,应该不是map集合,是处理过的消息
查看对应源码,发现返回byte数组(不同的处理返回的数据不同,如不处理)
但是都是byte数组,由此可见,的确处理了,处理成了不同的byte数组,那么应该是数据中只有一个处理过的格式才可变成json
即json的处理方式的byte数组,是可以被解析的
消息成功确认机制:
在实际场景下,有的生产者发送的消息是必须保证成功发送到消息队列中
前面解决了消费者如何保证接收的消息被操作,或者说是否被接收
那么如何保证成功投递呢:
事务机制
发布确认机制
事务机制:
AMQP协议提供的一种保证消息成功投递的方式,通过信道开启 transactional 模式
并利用信道 的三个方法来实现以事务方式 发送消息,若发送失败,通过异常处理回滚事务,确保消息成功投递
channel.txSelect(): 开启事务
channel.txCommit() :提交事务
channel.txRollback() :回滚事务
Spring已经对上面三个方法进行了封装,所以我们就直接使用原始的代码进行演示
对应的目录:
生产者:
package transaction;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.MessageProperties;
import util.ConnectionUtil;
public class Sender {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("test_transaction","topic");
channel.txSelect();
try {
channel.basicPublish("test_transaction", "product.register", null, "商品1降
价".getBytes());
System.out.println(1 / 0);
channel.basicPublish("test_transaction", "product.register", null, "商品2降
价".getBytes());
channel.txCommit();
System.out.println("生产者:消息已发送");
}catch (Exception e){
e.printStackTrace();
channel.txRollback();
}finally {
channel.close();
connection.close();
}
}
}
消费者:
package transaction;
import com.rabbitmq.client.*;
import util.ConnectionUtil;
import java.io.IOException;
public class Recer {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("test_transaction_queue_1", true, false, false, null);
channel.queueBind("test_transaction_queue_1","test_transaction","product.#");
DefaultConsumer defaultConsumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties
properties, byte[] body) throws IOException {
String s = new String(body);
System.out.println("【消费者1】 = " +s);
}
};
channel.basicConsume("test_transaction_queue_1",true,defaultConsumer);
}
}
这时我们先启动生产者,在启动消费者,然后启动生产者(具体原因,看看前面的介绍)
反正是需要先交换机,然后队列,然后绑定
注意:持久化,在测试的时候,最好不要持久化,因为即占用硬盘空间,也占用名称的命名
主要是占用硬盘空间(因为是没有实际作用的数据,只是测试而已)
Confirm发布确认机制 :
RabbitMQ为了保证消息的成功投递,采用通过AMQP协议层面为我们提供事务机制的方案
但是采用事务会大大降低消息的吞吐量(或者说消息处理能力)
因为事务开启或者操作需要时间,且要保证有回滚的操作,即不发送,或者说,拦截发送,即对应的信息被事务接手
当有提交后,才进行发送,回滚后,将他们销毁掉
一般的事务回滚操作要么是反向的操作(Mysql),要么是将原来进行提交的信息进行销毁(Redis,或者这里rabbitMQ)
在我本机SSD硬盘测试结果10w条消息未开启事务,大约8s发送完毕;而开启了事务后,需要将近310s,差了30多倍
接着翻阅官网,发现官网中已标注

那么有没有更加高效的解决方式呢:答案就是采用Confirm模式
事务效率为什么会这么低呢:
试想一下:10条消息,前9条成功,如果第10条失败,那么9条消息
要全部撤销(销毁)回滚,浪费执行时间(删除也是需要时间的),这是浪费性能的一种主要操作
而confirm模式则采用补发第10条的措施来完成10条消息的送达
即既然你第10条失败,那么我就不进行回滚,我重新在给你发送第10条,这就是补发,而不用浪费过多性能
在spring中应用:
spring-rabbitmq-producer.xml(修改或者添加部分配置):
<rabbit:connection-factory id="connectionFactory" host="192.168.164.128"
port="5672"
username="laosun"
password="123123"
virtual-host="/lagou"
publisher-confirms="true"/>
<rabbit:template id="rabbitTemplate"
connection-factory="connectionFactory"
exchange="spring_topic_exchange"
message-converter="jsonMessageConverter"
confirm-callback="messageConfirm"/>
<bean id="messageConfirm" class="confirm.MessageConfirm">bean>
消息确认处理类:
package confirm;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.support.CorrelationData;
public class MessageConfirm implements RabbitTemplate.ConfirmCallback {
@Override
public void confirm(CorrelationData correlationData, boolean b, String s) {
if(b){
System.out.println("消息确认成功");
}else{
System.out.println("消息确认失败");
System.out.println(correlationData);
System.out.println(s);
}
}
}
log4j.properties(这里加上,若觉得日志太多,可以删除):
因为我们有对应的依赖(依赖里面的类也包含对应日志信息的,如程序里面会操作日志配置文件)
但没有对应配置文件,会提示报错,虽然可以不必理会,或者删除对应依赖,这里可以叫做程序操作
因为将main方法里面全部删除执行,就没用对应的提示报错了,所以可以说是程序:
# 输出方式
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
# 表示输出信息为out级别,即输出到控制台的信息(即位置)
log4j.appender.stdout.Target=System.out
# 表示输出格式
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# 打印信息格式
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %m%n
# log4j.appender.file = 表示文件输出方式
log4j.appender.file=org.apache.log4j.FileAppender
# log4j.appender.file.File = 表示文件输出位置
log4j.appender.file.File=rebbitmq.log
# log4j.appender.file.layout = 表示输出格式
log4j.appender.file.layout=org.apache.log4j.PatternLayout
# log4j.appender.file.layout.ConversionPattern = 表示打印格式
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n
# log4j.rootLogger = 表示根日志级别
log4j.rootLogger=debug, stdout,file
发送消息:
package test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.HashMap;
import java.util.Map;
public class Sender {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-producer.xml");
RabbitTemplate bean = context.getBean(RabbitTemplate.class);
Map<String,String> map = new HashMap<>();
map.put("name","萧炎");
map.put("email","[email protected]");
bean.convertAndSend("lalala","msg.user",map);
context.close();
}
}
消费端限流:
在沙漠中行走,3天不喝水,突然喝水,如果使劲喝,容易猝死,要一口一口慢慢喝
我们 Rabbitmq 服务器积压了成千上万条未处理的消息,然后随便打开一个消费者客户端
就会出现这样的情况:巨量的消息瞬间全部喷涌推送过来,但是单个客户端无法同时处理这么多数据,就会被压垮崩溃
所以,当数据量特别大的时候,我们对生产端限流肯定是不科学的(因为只有消费者是时刻变化的)
当消费者多时,那么生产者若被限流,那么肯定会造成消费者的不满
因为有时候并发量就是特别大,有时候并发量又特别少,这是用户的行为,我们是无法约束的
所以我们直接不限流生产者,这样就都能应对了
这样看来,我们应该对消费端限流,用于保持消费端的稳定
例如:汽车企业不停的生产汽车,4S店有好多库存车卖不出去,但是也不会降价处理,就是要保证市值的稳定
如果生产多少台,就卖多少台,不管价格的话,市场就乱了,所以我们要用不变的价格来稳住消费者购车,才能平稳发展
RabbitMQ 提供了一种 Qos (Quality of Service,服务质量)服务质量保证功能:
即在非自动确认消息的前提下
如果一定数目的消息未被确认前(也就是只能限制对应数量的消费者在操作),不再进行消费新的消息
生产者使用循环发出多条消息(前面一个生产者的改变):
package test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.HashMap;
import java.util.Map;
public class Sender {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-producer.xml");
RabbitTemplate bean = context.getBean(RabbitTemplate.class);
Map<String,String> map = new HashMap<>();
map.put("name","萧炎");
map.put("email","[email protected]");
for(int i = 0;i<10;i++) {
bean.convertAndSend("msg.user", map);
System.out.println("发送成功");
}
context.close();
}
}
生产10条堆积未处理的消息:

消费者进行限流处理(修改消费者的配置文件,和修改消费者的监听的类):
<rabbit:listener-container connection-factory="connectionFactory" prefetch="3"
acknowledge="manual">
<rabbit:listener ref="cousumerListener" queue-names="test_spring_queue_1">rabbit:listener>
rabbit:listener-container>
package listener;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageListener;
import org.springframework.amqp.rabbit.listener.adapter.AbstractAdaptableMessageListener;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class CousumerListener extends AbstractAdaptableMessageListener {
private static final ObjectMapper mapper = new ObjectMapper();
@Override
public void onMessage(Message message, Channel channel) throws Exception {
try {
System.out.println(message);
JsonNode jsonNode = mapper.readTree(message.getBody());
String name = jsonNode.get("name").asText();
String email = jsonNode.get("email").asText();
System.out.println(name);
System.out.println(email);
long deliveryTag = message.getMessageProperties().getDeliveryTag();
channel.basicAck(deliveryTag,true);
Thread.sleep(3000);
System.out.println("休息3秒后,在继续接收消息");
} catch (Exception e) {
e.printStackTrace();
}
}
}
每次确认接收3条消息:

当未确认的消息为3时,后面的接收执行方法也就不执行了
过期时间TTL:
Time To Live:生存时间、还能活多久,单位毫秒
在这个周期内,消息可以被消费者正常消费,超过这个时间
则自动删除(其实是被称为dead message并投入到死信队列,无法消费该消息)
RabbitMQ可以对消息和队列设置TTL
通过队列设置,队列中所有消息都有相同的过期时间
对消息单独设置,每条消息的TTL可以不同(更颗粒化,但也更加麻烦)
设置队列TTL:
spring-rabbitmq-producer.xml(生产者的修改):
<rabbit:queue name="test_spring_queue_ttl" auto-declare="true">
<rabbit:queue-arguments>
<entry key="x-message-ttl" value="5000" value-type="long">entry>
rabbit:queue-arguments>
rabbit:queue>
启动生产者创建队列,发现,出现了TTL,即是有过期时间的队列

5秒之后,消息自动删除:

设置消息TTL:
设置某条消息的ttl,只需要在创建发送消息时指定即可
我们在生产者那里新创建一个类,目录如下:

我们修改队列名称,spring-rabbitmq-producer.xml(生产者的修改):
<rabbit:queue name="test_spring_queue_tt2">
对应代码:
package test;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.HashMap;
import java.util.Map;
public class Sender2 {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-producer.xml");
RabbitTemplate bean = context.getBean(RabbitTemplate.class);
Map<String,String> map = new HashMap<>();
MessageProperties messageProperties = new MessageProperties();
messageProperties.setExpiration("3000");
Message message = new Message("测试过期时间".getBytes(),messageProperties);
bean.convertAndSend("msg.user", message);
System.out.println("发送成功");
context.close();
}
}
如果同时设置了queue和message的TTL值,则二者中较小的才会起作用
也就是说实际上都操作的,只是已经过期了,那么多余时间的过期自然就没有作用了
所以可以理解为,他们会进行判断,使用少的过期时间,相同的,随便取谁都可,一般取队列
死信队列(前面过期时间的自动删除中提到过的死信队列是一个原因):
DLX(Dead Letter Exchanges)死信交换机 / 死信邮箱
当消息在队列中由于某些原因没有被及时消费而变成死信(dead message)后
这些消息就会被分发到DLX交换机中,而绑定DLX交换机的队列,称之为:“死信队列”
消息没有被及时消费的原因:
消息被拒绝(basic.reject/ basic.nack)并且不再重新投递 requeue=false
消息超时未消费
达到最大队列长度

实际上我们虽然说是死信队列,但具体的队列还是需要自己创建,我们可以将这个队列用来存放无用信息,或者向回收站一样
防止突然需要这些消息,而创建的后手,实际上可以是多个死信队列(无限套娃),只是这里一般只创建一个死信队列
实际上死信队列和死信交换机也只是队列和交换机而已,因为有了特殊的任务(充当回收站和中转站)
使得被称为死信队列和死信交换机了
对应的目录(生产者):

spring-rabbitmq-producer-dlx.xml(在生产者代码里,创建该配置文件):
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/rabbit
http://www.springframework.org/schema/rabbit/spring-rabbit.xsd">
<rabbit:connection-factory id="connectionFactory" host="192.168.164.128"
port="5672"
username="laosun"
password="123123"
virtual-host="/lagou"/>
<rabbit:admin connection-factory="connectionFactory"/>
<rabbit:template id="rabbitTemplate" connection-factory="connectionFactory"
exchange="my_exchange"/>
<rabbit:queue name="dlx_queue"/>
<rabbit:direct-exchange name="dlx_exchange">
<rabbit:bindings>
<rabbit:binding key="dlx_ttl" queue="dlx_queue"/>
<rabbit:binding key="dlx_max" queue="dlx_queue"/>
rabbit:bindings>
rabbit:direct-exchange>
<rabbit:queue name="test_ttl_queue">
<rabbit:queue-arguments>
<entry key="x-message-ttl" value="6000" value-type="long"/>
<entry key="x-dead-letter-exchange" value="dlx_exchange"/>
rabbit:queue-arguments>
rabbit:queue>
<rabbit:queue name="test_max_queue">
<rabbit:queue-arguments>
<entry key="x-max-length" value="2" value-type="long"/>
<entry key="x-dead-letter-exchange" value="dlx_exchange"/>
rabbit:queue-arguments>
rabbit:queue>
<rabbit:direct-exchange name="my_exchange">
<rabbit:bindings>
<rabbit:binding key="dlx_ttl" queue="test_ttl_queue"/>
<rabbit:binding key="dlx_max" queue="test_max_queue"/>
rabbit:bindings>
rabbit:direct-exchange>
beans>
发消息进行测试:
package test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.HashMap;
import java.util.Map;
public class SenderDLX {
public static void main(String[] args) {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("spring/spring-rabbitmq-producer-dlx.xml");
RabbitTemplate bean = context.getBean(RabbitTemplate.class);
bean.convertAndSend("dlx_max", "测试长度1".getBytes());
bean.convertAndSend("dlx_max", "测试长度2".getBytes());
bean.convertAndSend("dlx_max", "测试长度3".getBytes());
context.close();
}
}
对应队列长度限制的测试(先操作麻烦的):
虽然我们知道,队列是从小到大的,我们可以先发送两个信息(测试长度3不发送),查看对应信息:

点击test_max_queue,进入往下滑,找到如下:
数字2,代表查看的队列信息,若是3,那么也是查看2个信息,因为只有两个
我们可以看到测试长度1的确在上面,即是从小到大的,这时我们单独发送测试长度3
这时已经超过的设置的队列长度,一般的,我们以为是测试长度3被投递(踢出),实际上是测试长度1
那么也就是说,这个队列长度的限制优先于发送的消息,即以发送的消息为主
因为既然有消息来,那么他之间去除旧的消息,所以可以看到这个长度限制的配置使得测试长度1被踢出
踢出的消息可以在dlx_queue里进行查看,发现,的确是踢出了测试长度1,这是该配置的作用
若要删除队列,可以点击如下(下面的橙色):
往下滑,找到如下:
点击橙色的按钮,那么就可以删除该队列了,持久的也会删除
对应测试过期时间的消息(注释去掉,将测试长度的代码进行注释):
其中TTL我们知道代表过期时间标签,但我们可以根据配置文件的说明
那么就知道Lim代表着消息上限(有数量的消息或者说固定的队列长度)标签
其中DLX代表可以跳转的发送到对应交换机

首先我们在test_ttl_queue里可以看到消息,过期后,消息就到dlx-queue队列里面去了,可以自己测试
当然了,我们可以测试长度和过期时间一起操作,因为他们互不干扰
延迟队列:
延迟队列:TTL + 死信队列的合体
死信队列只是一种特殊的队列,里面的消息仍然可以消费
在电商开发部分中,都会涉及到延时关闭订单,此时延迟队列正好可以解决这个问题
生产者:
沿用上面死信队列案例的超时测试,超时时间改为订单关闭时间即可
消费者:
spring-rabbitmq-consumer.xml(修改对应的配置):
<rabbit:listener-container connection-factory="connectionFactory" prefetch="3" acknowledge="manual">
<rabbit:listener ref="cousumerListener" queue-names="dlx_queue">rabbit:listener>
rabbit:listener-container>
RabbitMQ集群:
rabbitmq有3种模式,但集群模式是2种。详细如下:
单一模式:即单机情况不做集群,就单独运行一个rabbitmq而已,前面我们一直在用的操作就是(一般只是用来进行练习时使用)
普通模式:默认模式,以两个节点(A、B)为例来进行说明
当消息进入A节点的Queue后,consumer从B节点消费时,RabbitMQ会在A和B之间创建临时通道进行消息传输
把A中的消息实体取出并经过通过交给B发送给consumer
当A故障后,B就无法取到A节点中未消费的消息实体
如果做了消息持久化,那么得等A节点恢复,然后才可被消费
如果没有持久化的话,就会产生消息丢失的现象,因为A节点恢复时,原来需要给B节点的消息不在了
我们也发送,从始至终都只是一个消息,只是生产者和消费者对应操作的队列分成了两个节点了而已
所以一般我们也不会使用这个模式,那么根据这个问题(只有一份消息)我们就有了如下模式:
镜像模式:非常经典的 mirror 镜像模式,保证 100% 数据不丢失
在数据层面:高可靠性,数据基本不会丢失,高可用,数据基本可以访问,操作他们两个的解决方案(主要操作可靠性)
在机器层面:可靠性针对机器运行时间(不易宕机),可用性针对挂机恢复时间(快速的可用)
这个镜像模式主要就是实现数据的同步保存(操作可靠性,同步基本不会使得数据丢失),一般来讲是 2 - 3 个节点实现数据同步
对于 100% 数据可靠性解决方案,一般是采用 3 个节点
在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式
还有主备模式,远程模式,多活模式等,这里(本次课程)就不作为重点,可自行查阅资料了解
集群搭建:
前置条件:准备两台linux(可以的话,可以准备三台),并安装好rabbitmq
集群步骤如下:
修改 /etc/hosts 映射文件(根据这个文件,应该知道,是配置域名)
在这之前,给你一个小技巧:
点击这里(发送键输入到所有的会话),出现勾勾后,那么你在一个会话里输入命令或者执行命令
会同步到所有的会话里,即一个会话操作,使得所有会话都操作一样的操作,自己可以进行测试
再次点击,就会取消勾勾,那么也就不起作用了
1号服务器:
127.0.0.1 A localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 A localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.164.128 A
192.168.164.129 B
2号服务器:
127.0.0.1 B localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 B localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.164.128 A
192.168.164.129 B
修改后进行重启,使得hosts文件生效
重启是为了以防万一,一般重启都会生效,而使用能生效的命令,可能不会生效,具体命令可以百度
所以,重启是最稳妥的命令:
reboot
为了使得 rabbitmq相互通信,cookie必须保持一致(对于 rabbitmq来说的cookie):
cd /var/lib/rabbitmq/
cat .erlang.cookie
该文件基本是用来同步的,即我们需要使得 rabbitmq的cookie 文件值都要一样,才可进行同步
所以我们只需要修改对应文件内容,或者复制过去即可,为了更方便的复制过去
所以我们就进行跨服务器拷贝 .erlang.cookie
[root@A opt]
注意:cp后,也进行重启服务器(使得起作用,以防万一)
命令:reboot
停止防火墙,启动rabbitmq服务:
[root@A ~]
[root@A ~]
加入集群节点:
[root@B ~]
[root@B ~]
[root@B ~]
[root@A ~]
[root@B ~]
[root@B rabbitmq]
mnesia
查看节点状态:
[root@B ~]
查看管理端
搭建集群结构之后,之前创建的交换机、队列、用户都属于单一结构,在新的集群环境中是不能用的
之所以这样说,这里解释一下:
假设如果没有搭建集群时,B服务器有一个laosun用户,lao用户,且里面有一个队列(多个用户是共享队列的,因为共享虚拟主机)
因为用户只是登录而已,主要是虚拟主机
当搭建集群后,如果操作laosun用户,那么就使用集群的laosun用户和队列,原来的相同用户隐藏了,不同用户不能访问了,且只会使用集群的队列
原来的队列不会使用,都不会显示出来(不同的会显示,只是对用户来说,但不可访问)
当离开集群(不是删除节点服务器)后
实际上很难有完全的离开集群,基本上都是半离开,完全离开基本会导致用户和虚拟主机删除
完全离开,大概需要找到对应的连接信息,而不删除对应的队列信息(可以自己尝试,实际上是很难改变的)
那么这些队列都会显示出来了(持久的看到),可以使用,不同用户也可以访问,原来相同用户显示出来也可以访问
所以在新的集群中重新手动添加用户后,由于同步,任意节点添加,所有节点共享,主要看加入对方的用户共享
比如B服务器加入A服务器,B服务器和A服务器都要laosun用户,那么使用A服务器的laosun用户,所以人共享
可以在没有laosun用户的服务器来进行登录,发现,的确可以登录
[root@A ~]
[root@A ~]
[root@A ~]
注意:当节点脱离集群还原成单一结构后,交换机,队列和用户等数据 都会重新回来
此时,集群搭建完毕,但是默认采用的模式"普通模式",我们也可以发现,当其中一个宕机后
对应的节点不同步,且基本是关闭的
因为对应的数据并不是服务器独有的,若A服务器不在了,那么对应的队列也就不在了,那个同步只是通道共享
并不是真正的完全同步数据且保存,可靠性不高,实际上我们也可以删除虚拟主机(目录)
但并不会删除他存在的持久的信息(交换机,队列,消息)
镜像模式:
将所有队列设置为镜像队列,即队列会被复制到各个节点(这是复制,而不是单纯的同步共享,而是同步复制)
对应这里的模式来说,可以看成如下:
同步共享(普通模式):你可以用我的(先同步,没有复制),并显示(界面),但我不在了,就用不到,并没有显示(界面)了
同步复制(镜像模式):你复制我的来使用(先同步,然后复制),并显示(界面)
我不在了,但你已经复制了,所以还是可以用,并显示(界面)
各个节点状态一致
语法:set_policy {name} {pattern} {definition}
name:策略名,可自定义
pattern:队列的匹配模式(正则表达式)
“^” 可以使用正则表达式,比如"^queue_ " 表示对队列名称以"queue_“开头的所有队列进行镜像,而”^"表示匹配所有的队列
definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:(High Available,高可用)模式,指明镜像队列的模式,有效值为 all,exactly,nodes
当前策略模式为 all,即复制到所有节点,包含新增节点
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
[root@A ~]
通过管理端设置镜像策略:

注意:该策略默认操作 / 的虚拟主机的队列,其他的虚拟主机不会操作
界面创建队列(在队列那个界面,往下滑可以找到):
就填写了ddddd,发现有xall标志(xall是对应的策略名),因为默认在 / 虚拟主机上
当我们关闭这一个服务器,其他服务器也是有这个的,即同步时,就复制了,而不会出现只同步,而不复制
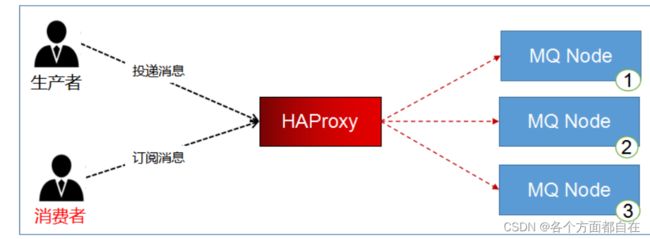
HAProxy实现镜像队列的负载均衡:
虽然我们在程序中访问A服务器,可以实现消息的同步,虽然在同步,但都是A服务器在操作消息,A太累
是否可以像Nginx一样,做负载均衡,A和B轮流接收消息(因为同步复制了,所以可以轮流操作消息),再镜像同步
HAProxy简介 :
HA(High Available,高可用),Proxy(代理)
HAProxy是一款提供高可用性,负载均衡,并且基于TCP和HTTP应用的代理软件
HAProxy完全免费
HAProxy可以支持数以万计的并发连接
HAProxy可以简单又安全的整合进架构中,同时还保护web服务器不被暴露到网络上
HAProxy与Nginx:
OSI:(Open System Interconnection):开放式系统互联
是把网络通信的工作分为7层,分别是物理层,数据链路层,网络层,传输层,会话层,表示层和应用层
Nginx的优点:
工作在OSI第7层,可以针对http应用做一些分流的策略
Nginx对网络的依赖非常小,理论上能ping通就能进行负载功能,屹立至今的绝对优势
Nginx安装和配置比较简单,测试起来比较方便
Nginx不仅仅是一款优秀的负载均衡器和反向代理软件,它同时也是功能强大的Web应用服务器
HAProxy的优点:
可以工作在网络中的第4层到第7层,支持TCP与Http协议
它仅仅就只是一款负载均衡软件,单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度
在并发处理上也是优于Nginx的
支持8种负载均衡策略 ,支持心跳检测
性能上HA胜,功能性和便利性上Nginx胜
对于Http协议,Haproxy处理效率比Nginx高,所以,没有特殊要求的时候或者一般场景,建议使用Haproxy来做Http协议负载
但如果是Web应用,那么建议使用Nginx
总之,大家可以结合各自使用场景的特点来进行合理地选择
安装和配置:
HAProxy下载:http://www.haproxy.org/download/1.8/src/haproxy-1.8.12.tar.gz
解压:
[root@localhost opt]
make(编译时,对应解压后的文件里有Makefile文件)时需要使用 TARGET 指定内核及版本:
[root@localhost opt]
3.10.0-514.6.2.el7.x86_64
根据内核版本选择编译参数:

发现对应的参数是linux2628,因为我们是3.10,即3.x
进入目录,编译和安装:
[root@localhost opt]
[root@localhost haproxy-1.8.12]
[root@localhost haproxy-1.8.12]
安装成功后,查看版本:
[root@localhost haproxy-1.8.12]
配置启动文件,复制haproxy文件到/usr/sbin下 ,复制haproxy脚本,到/etc/init.d下:
[root@localhost haproxy-1.8.12]
[root@localhost haproxy-1.8.12]
[root@localhost haproxy-1.8.12]
创建系统账号:
[root@localhost haproxy-1.8.12]
haproxy.cfg 配置文件需要自行创建:
[root@localhost haproxy-1.8.12]
[root@localhost haproxy-1.8.12]
添加配置信息到haproxy.cfg:
global
log 127.0.0.1 local0 info
chroot /usr/local/haproxy
user haproxy
group haproxy
uid 99
gid 99
daemon
maxconn 4096
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
maxconn 2000
timeout connect 5s
timeout client 30s
timeout server 15s
listen rabbitmq_cluster
bind 192.168.164.130:5672
mode tcp
balance roundrobin
server A 192.168.164.128:5672 check inter 5000 rise 2 fall 3
server B 192.168.164.129:5672 check inter 5000 rise 2 fall 3
listen monitor
bind 192.168.164.130:8100
mode http
option httplog
stats enable
stats uri /monitor
stats refresh 5s
启动HAProxy:
[root@localhost haproxy]
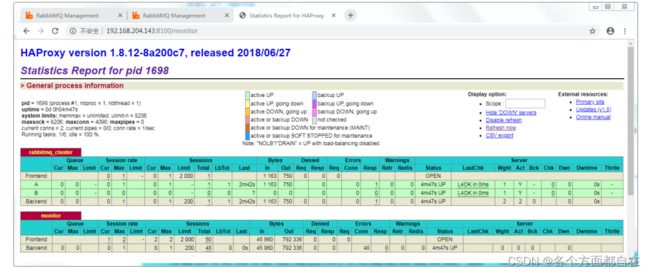
访问监控中心:http://192.168.164.130:8100/monitor
记得关闭防火墙: systemctl stop firewalld
项目发消息,只需要将服务器地址修改为130即可,其余不变
然后haproxy会根据对应的虚拟主机,用户名,密码(由于是集群,那么基本可用忽略)
以上面的规则为例(轮询)
依次轮询的操作对应服务器,无论是写入还是读取,其中可用看上图的Total,多次的发送信息和接收信息,可以发现
的确是轮询的,比如我们发送三次(从A开始,那么就是A-B-A),若这时我们在次接收三次,那么就是(B-A-B)
每次的接收和发生,都会轮询一次,注意:haproxy操作接收的监听时,他每过段时间,会要求接收的监听进行一次请求
来得到数据,一般的我们的监听只能监听一个,且一直监听,而不是每过段时间进行一次监听
而在haproxy时,是每过段时间监听,使得haproxy会根据规则(轮询)操作监听,使得每个服务器都被轮询的访问
之所以这样,是为了使得服务器被均匀的访问,而不会一直监听某个服务器
这样,无论是发生信息,还是接收信息,就都实现了负载均衡的操作
所有的请求(发生和接受)都会交给HAProxy,其负载均衡给每个rabbitmq服务器(设置的两个server,配置里可用看到)
KeepAlived搭建高可用的HAProxy集群:
在前面的nginx里,我应该说过,我们所有的请求都给一个nginx,这是非常不好的
万一他宕机了,损失就大了,所以我们可以做集群
这里也是一样的,所有的请求都给haproxy,也是需要集群
所以现在最后一个问题暴露出来了,如果HAProxy服务器宕机,rabbitmq服务器就不可用了
所以我们需要对HAProxy也要做高可用的集群,那么我们就来操作如何弄集群(这里操作haproxy集群)
注意:无论你如何的操作集群,那么一定是有某个服务器是总体的接收(一个ip),这是一定的,我们只能优化这些操作
但这时也要考虑,这个总体的接受如何防止宕机,我们使用备用机方案,下面的vrrp协议
那么为什么不直接让haproxy使用备用机方案呢:那是因为haproxy并没有操作该协议,因为术业有专攻
假设加上了这个,很明显,我们是将多个操作给一个中间件了,那么为什么不分开(使得互相可以作用)使得好维护呢
概述:
Keepalived是Linux下一个轻量级别的高可用热备解决方案
Keepalived的作用是检测服务器的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态
如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到
并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作
当服务器工作正常后Keepalived自动将服务器加入到服务器群中
这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。
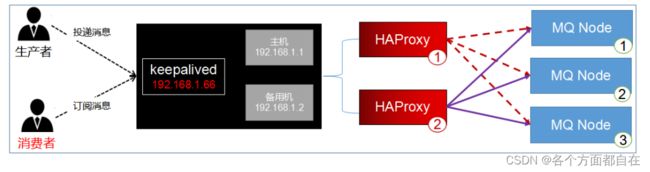
keepalived基于vrrp(Virtual Router Redundancy Protocol,虚拟路由冗余协议)协议
vrrp它是一种主备(主机和备用机)模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换
而不影响主机之间的数据通信,两台主机之间生成一个虚拟的ip,我们称漂移ip,漂移ip由主服务器承担
一但主服务器宕机,备份服务器就会抢夺漂移ip,继续工作,有效的解决了群集中的单点故障
说白了,将多台路由器设备虚拟成一个设备,对外提供统一ip(VIP)
安装KeepAlived:
修改hosts文件的地址映射:
| ip |
用途 |
主机名 |
| 192.168.164.130 |
KeepAlived 和 HAProxy |
C |
| 192.168.164.131 |
KeepAlived 和 HAProxy |
D |
安装 keepalived:
[root@C ~]
修改配置文件(内容大改,不如删掉,重新创建):
[root@C ~]
[root@C ~]
! Configuration File for keepalived
global_defs {
router_id C
}
vrrp_script chk_haproxy{
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 66
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.164.66/24
}
}
virtual_server 192.168.164.66 5672 {
delay_loop 6
lb_algo rr
lb_kind NAT
protocol TCP
real_server 192.168.164.130 5672 {
weight 1
}
}
创建执行脚本 /etc/keepalived/haproxy_check.sh:
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq 0 ];then
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
Keepalived 组之间的心跳检查并不能察觉到 HAproxy 负载是否正常,所以需要使用此脚本在 Keepalived 主机上
开启此脚本检测 HAproxy 是否正常工作,如正常工作,记录日志
如进程不存在,则尝试重启 HAproxy ,2秒后检测,如果还没有,则关掉主 Keepalived
此时备Keepalived 检测到主 Keepalived 挂掉,接管VIP,继续服务
授权,否则不能执行:
[root@C etc]
启动keepalived(两台都启动):
[root@C etc]
[root@C etc]
查看状态:
[root@C etc]
[root@C etc]
查看ip情况 ip addr 或 ip a:
[root@C etc]
发现在网卡上多出了一个地址,这里我就要说明一下虚拟ip和真实ip的一个细节:
假设虚拟ip和真实ip是一样的,那么先显示虚拟ip,这是因为虚拟ip是我们自己设置的ip
而真实ip是路由(是网络上的路由,并不是本机路由)给我们的ip,用来与网络相连接,所以虚拟ip优先
但是当你设置同一的ip时,我们进行关闭keepalived时,由于是直接关闭ip,且原来ip冲突,使得虚拟机不正常退出,且连接不了
因为这时没有ip了(可用离开Xshell后,去虚拟机使用ip a查看
那么由于连接不了(冲突),即这个ip也就访问不了了(没有冲突之前可以)
因为优先虚拟ip,但是keepalived不能使得虚拟ip和真实ip相同,所有会导致冲突
这时一般就需要重启,使得keepalived的影响消失,那么我们就可以修改回来了
此时操作完了第一台,即安装完毕,按照上面的步骤就可以安装第二台了(服务器名称和ip注意要修改)
可能操作第二台时出现的常见的网络错误:子网掩码、网关等信息要一致
这时我们访问66,也就是访问130了,相当于在本地操作时,66也代表了该主机,就如130代表该主机一样
但是这是针对于本地来说的,网络上不会看这个虚拟ip,所以虽然当前电脑可用ping通
这时因为是NAT模式(无需联网即可,没有联网只能访问内部,不能访问外部)
但是若使用网络上的操作的话,就需要看真实ip,比如浏览器的访问
我们可用进行ping通66和130,也可以使用curl进行发送请求看看是否返回AMQP使得可以连接
测试ip漂移的规则(在第二台服务器也部署完毕的情况下):
查看虚拟ip ip addr 或 ip a
目前,C节点是主机,所以虚拟ip在C节点
在这个基础上(实际上与对应的haproxy是否启动并无关系)
C节点启动keepalived,D节点启动,那么虚拟ip在C上
若C节点关闭,那么虚拟ip飘移到D节点上
若C节点开启,虚拟ip还是在D节点上
若D节点关闭,虚拟ip飘移到C节点上
若D节点启动,虚拟ip还是在C节点上
若D节点和C节点都关闭,那么谁先启动,虚拟ip就给谁
可以这样理解:只要虚拟ip的该节点,进行关闭,才会进行飘移
但是这只是针对于两个服务器来进行的操作,假如有两个以上的服务器呢:
看如下解释:
我们知道,有主机,备用机,一般的我们操作这个两个,若再次添加的话,那么就是随从备用机
随从的备用机可以说是备用的备用,他们得到飘移ip时,只要主机启动,ip就会回到主机身上,而不会像备用机一样,持续占用
而飘移规则一般是(这里是):从开启机一路到下(按照开启顺序来进行飘移,从第一个机开始)
所以相对于两个服务器来说,那么就是互相飘移
主机一般是用来抢夺随从备用机的,实际上当只有两个时,与是否是主机无关,对应ip都会飘移
测试vip+端口是否提供服务(在128,A服务器上测试)
[root@A ~]
AMQP
由次看来,我们设置的虚拟ip,使得我们只需要访问他一个,就能访问多个服务器,使得其中一个挂掉了之后
访问并不会停止,即该服务器的haproxy也就可以执行,从而实现了haproxy的高可用,到此haproxy的集群操作完毕
这里并没有使用负载均衡操作,而是使用虚拟ip来操作,操作了类似于负载均衡的操作(操作集群)
但是与负载均衡不同的是,负载均衡的那个服务器只有一个,而这里虽然也是始终只会操作一个服务器,但也防止了宕机
都是访问一个ip,实现多个服务器的访问(这一点类似于负载均衡)
最后要注意一个问题:我们知道,生产者生产消息,基本是有顺序的(因为对于他来说,他的消息必然顺序,当然,我们一般也不会操作多个生产者来破坏顺序,这是没有必要的,或者一些其他原因,具体可以看这个博客:https://blog.csdn.net/m0_37540696/article/details/128026687),但是若多个消费者来消费时,若其中一个消费者比较慢,那么这个顺序就发生改变了,比如添加,更新,删除,最后变成删除(其他两个比较慢),更新,添加,那么对于数据库来说是一个严重的问题的,或者没有删除,那么就没有更新,当然了,就算是一个消费者,他也可以操作多线程(创建子线程就行),所以根据这样的问题,我们需要思考,如何解决:
1:为了解决多个消费者,其中我们可以操作多个队列,每个消费者一个队列,那么就可以完成,虽然解决消费者多的问题,但是队列也多了,也为了可以定位到不同的队列,一般我们会操作哈希,将一组放入(可以认为有编号,也可以认为操作通配符)
2:为了解决一个消费者,消费者自己可以判断消息来进行一个队列的方式,从而进行顺序处理
当然,可能还有其他解决方式,具体可以百度