【手写数字识别】GPU训练版本
SVM
Adaboost
Bagging
完整代码 I
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
# 超参数
batch_size = 64
num_epochs = 10
# 数据集准备
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data/demo2', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data/demo2', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# SVM 模型 (在GPU上训练)
class SVMModel(torch.nn.Module):
def __init__(self):
super(SVMModel, self).__init__()
self.flatten = torch.nn.Flatten()
self.linear = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
x = self.flatten(x)
return self.linear(x)
svm_model = SVMModel().cuda()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(svm_model.parameters(), lr=0.01)
# 训练和评估
svm_train_losses = []
svm_test_accuracies = []
for epoch in range(num_epochs):
for batch_idx, (data, labels) in enumerate(train_loader):
data, labels = data.cuda(), labels.cuda()
outputs = svm_model(data)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
svm_train_losses.append(loss.item())
with torch.no_grad():
test_accuracy = 0
total = 0
for batch_idx, (data, labels) in enumerate(test_loader):
data, labels = data.cuda(), labels.cuda()
outputs = svm_model(data)
_, predicted = torch.max(outputs, 1)
test_accuracy += torch.sum(predicted == labels).item()
total += labels.size(0)
accuracy = (test_accuracy / total) * 100
svm_test_accuracies.append(accuracy)
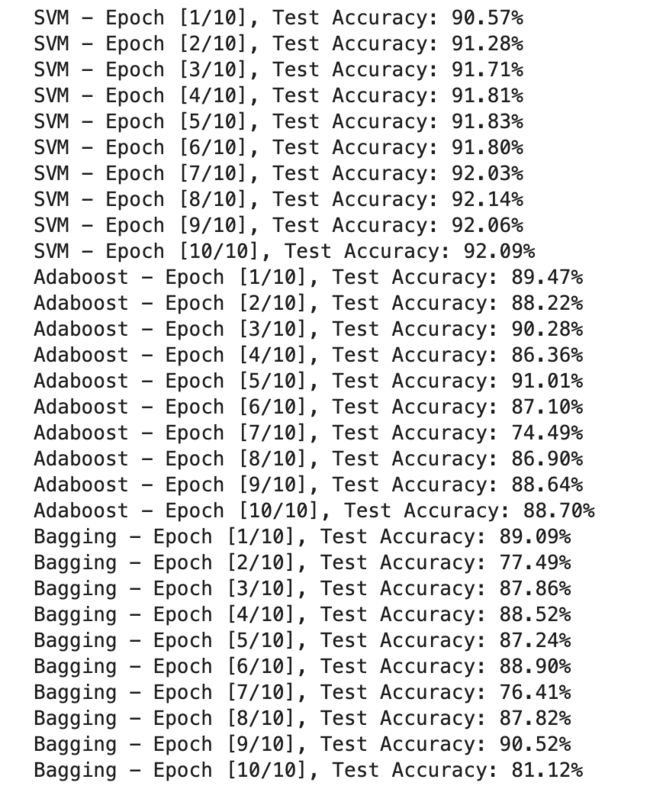
print('SVM - Epoch [{}/{}], Test Accuracy: {:.2f}%'.format(epoch + 1, num_epochs, accuracy))
# Adaboost 模型 (在GPU上训练)
class AdaboostModel(torch.nn.Module):
def __init__(self, num_estimators):
super(AdaboostModel, self).__init__()
self.num_estimators = num_estimators
self.models = torch.nn.ModuleList([SVMModel() for _ in range(num_estimators)])
def forward(self, x):
outputs = torch.zeros(x.size(0), 10).cuda()
for i in range(self.num_estimators):
outputs += self.models[i](x)
return outputs
adaboost_model = AdaboostModel(num_estimators=50).cuda()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(adaboost_model.parameters(), lr=0.01)
# 训练和评估
adaboost_train_losses = []
adaboost_test_accuracies = []
for epoch in range(num_epochs):
for batch_idx, (data, labels) in enumerate(train_loader):
data, labels = data.cuda(), labels.cuda()
outputs = adaboost_model(data)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
adaboost_train_losses.append(loss.item())
with torch.no_grad():
test_accuracy = 0
total = 0
for batch_idx, (data, labels) in enumerate(test_loader):
data, labels = data.cuda(), labels.cuda()
outputs = adaboost_model(data)
_, predicted = torch.max(outputs, 1)
test_accuracy += torch.sum(predicted == labels).item()
total += labels.size(0)
accuracy = (test_accuracy / total) * 100
adaboost_test_accuracies.append(accuracy)
print('Adaboost - Epoch [{}/{}], Test Accuracy: {:.2f}%'.format(epoch + 1, num_epochs, accuracy))
# Bagging 模型 (在GPU上训练)
class BaggingModel(torch.nn.Module):
def __init__(self, num_estimators):
super(BaggingModel, self).__init__()
self.num_estimators = num_estimators
self.models = torch.nn.ModuleList([SVMModel() for _ in range(num_estimators)])
def forward(self, x):
outputs = torch.zeros(x.size(0), 10).cuda()
for i in range(self.num_estimators):
outputs += self.models[i](x)
return outputs
bagging_model = BaggingModel(num_estimators=50).cuda()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(bagging_model.parameters(), lr=0.01)
# 训练和评估
bagging_train_losses = []
bagging_test_accuracies = []
for epoch in range(num_epochs):
for batch_idx, (data, labels) in enumerate(train_loader):
data, labels = data.cuda(), labels.cuda()
outputs = bagging_model(data)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
bagging_train_losses.append(loss.item())
with torch.no_grad():
test_accuracy = 0
total = 0
for batch_idx, (data, labels) in enumerate(test_loader):
data, labels = data.cuda(), labels.cuda()
outputs = bagging_model(data)
_, predicted = torch.max(outputs, 1)
test_accuracy += torch.sum(predicted == labels).item()
total += labels.size(0)
accuracy = (test_accuracy / total) * 100
bagging_test_accuracies.append(accuracy)
print('Bagging - Epoch [{}/{}], Test Accuracy: {:.2f}%'.format(epoch + 1, num_epochs, accuracy))
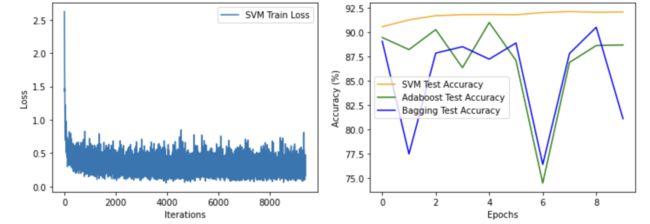
# 可视化
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(svm_train_losses, label='SVM Train Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(svm_test_accuracies, label='SVM Test Accuracy', color='orange')
plt.plot(adaboost_test_accuracies, label='Adaboost Test Accuracy', color='green')
plt.plot(bagging_test_accuracies, label='Bagging Test Accuracy', color='blue')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()
从gpu使用率看:

完整代码 II
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
# 超参数
batch_size = 64
num_epochs = 10
# 数据集准备
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data/demo2', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data/demo2', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# SVM 模型定义
class SVMModel(torch.nn.Module):
def __init__(self):
super(SVMModel, self).__init__()
self.flatten = torch.nn.Flatten()
self.linear = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
x = self.flatten(x)
return self.linear(x)
# Adaboost 模型定义
class AdaboostModel(torch.nn.Module):
def __init__(self, num_estimators):
super(AdaboostModel, self).__init__()
self.num_estimators = num_estimators
self.models = torch.nn.ModuleList([SVMModel() for _ in range(num_estimators)])
def forward(self, x):
outputs = torch.zeros(x.size(0), 10).cuda()
for i in range(self.num_estimators):
outputs += self.models[i](x)
return outputs
# Bagging 模型定义
class BaggingModel(torch.nn.Module):
def __init__(self, num_estimators):
super(BaggingModel, self).__init__()
self.num_estimators = num_estimators
self.models = torch.nn.ModuleList([SVMModel() for _ in range(num_estimators)])
def forward(self, x):
outputs = torch.zeros(x.size(0), 10).cuda()
for i in range(self.num_estimators):
outputs += self.models[i](x)
return outputs
# 训练函数
def train_model(model, train_loader, test_loader, num_epochs, optimizer, criterion):
train_losses = []
test_accuracies = []
best_accuracy = 0
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, labels) in enumerate(train_loader):
data, labels = data.cuda(), labels.cuda()
outputs = model(data)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss.item())
model.eval()
with torch.no_grad():
test_accuracy = 0
total = 0
for batch_idx, (data, labels) in enumerate(test_loader):
data, labels = data.cuda(), labels.cuda()
outputs = model(data)
_, predicted = torch.max(outputs, 1)
test_accuracy += torch.sum(predicted == labels).item()
total += labels.size(0)
accuracy = (test_accuracy / total) * 100
test_accuracies.append(accuracy)
# 更新最佳准确率和最佳模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model.state_dict()
print('Epoch [{}/{}], Test Accuracy: {:.2f}%'.format(epoch + 1, num_epochs, accuracy))
# 返回训练过程中的损失、准确率和最佳模型的状态字典
return train_losses, test_accuracies, best_model
# 创建SVM模型、Adaboost模型和Bagging模型
svm_model = SVMModel().cuda()
adaboost_model = AdaboostModel(num_estimators=50).cuda()
bagging_model = BaggingModel(num_estimators=50).cuda()
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
svm_optimizer = torch.optim.SGD(svm_model.parameters(), lr=0.01)
adaboost_optimizer = torch.optim.SGD(adaboost_model.parameters(), lr=0.01)
bagging_optimizer = torch.optim.SGD(bagging_model.parameters(), lr=0.01)
# 训练SVM模型
print('训练SVM模型:')
svm_train_losses, svm_test_accuracies, svm_best_model = train_model(svm_model, train_loader, test_loader, num_epochs,
svm_optimizer, criterion)
# 训练Adaboost模型
print('训练Adaboost模型:')
adaboost_train_losses, adaboost_test_accuracies, adaboost_best_model = train_model(adaboost_model, train_loader,
test_loader, num_epochs,
adaboost_optimizer, criterion)
# 训练Bagging模型
print('训练Bagging模型:')
bagging_train_losses, bagging_test_accuracies, bagging_best_model = train_model(bagging_model, train_loader,
test_loader, num_epochs,
bagging_optimizer, criterion)
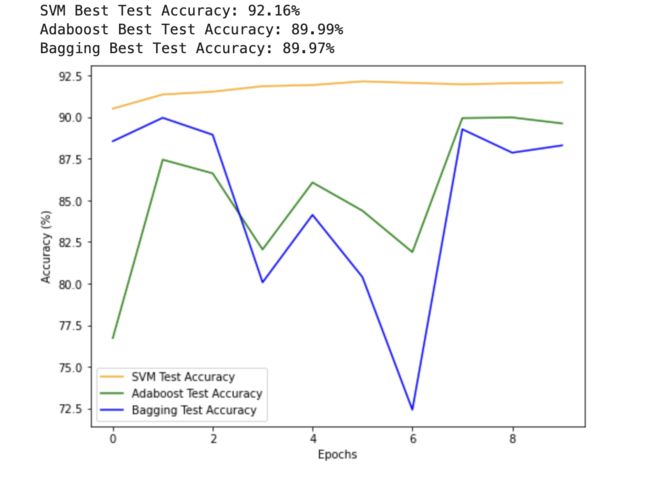
# SVM、Adaboost和Bagging三个模型在测试集上的最佳准确率
print('SVM Best Test Accuracy: {:.2f}%'.format(max(svm_test_accuracies)))
print('Adaboost Best Test Accuracy: {:.2f}%'.format(max(adaboost_test_accuracies)))
print('Bagging Best Test Accuracy: {:.2f}%'.format(max(bagging_test_accuracies)))
# 三个模型的准确率最好的放在一起进行可视化对比
plt.figure(figsize=(8, 6))
plt.plot(svm_test_accuracies, label='SVM Test Accuracy', color='orange')
plt.plot(adaboost_test_accuracies, label='Adaboost Test Accuracy', color='green')
plt.plot(bagging_test_accuracies, label='Bagging Test Accuracy', color='blue')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()