性能测试之全链路压测实战理论详解

前言
要说当下研发领域最热门的几个词,全链路压测 肯定跑不了。最近的几次大会上,也有不少关于全链路的议题。之前有朋友在面试过程中也有被问到了什么是全链路压测,如何有效的开展全链路压测。今天我们就来聊聊全链路压测,但本文不会涉及到具体的技术栈,主要讲讲全链路实践的理论问题。
其实,进行全链路压测对于整个公司技术要求还是很高的,没有一定技术沉淀的公司最好不要贸然尝试全链路压测,因为如果没做好可能会把生产环境搞宕机,所以对于没有一定科技能力的公司还是尽量不要贸然追潮流,实施全链路压测。
01为什么需要全链路压测?
先说说为什么需要全链路。随着业务的发展,技术架构从原来的单体架构发展到现在的微服务架构, 应用越来越多,给研发人员定位问题带来的困难也越来越大。在单体架构时期,只要查看一个应用的日志,就能大体知道问题出在哪里。但是在微服务架构下,基于前端返回的错误信息,你如何从那么长的应用链路中找到出错的应用?找不到具体的应用,你如何查看错误日志?
也许你熟悉业务,可以大概猜测出问题在哪里,但这毕竟存在不确定性。在这种场景下,我们就需要一个服务治理平台,来帮助我们展示业务的全链路调用关系,并能通过某个ID,查询出某个请求在业务平台中流转过程。这里提到的服务治理平台,至少要包含功能有:服务的注册与发现,服务状态的可观测以及流量管理。目前主流的服务治框架有:spring-cloud框架,dubbo框架以及service mesh框架。基于服务治理,我们就可以具体的观察到请求在不同应用之前的流转,再结合统一日志平台,我们就可以快速定位到是哪个微服务出了问题,就能针对性的去做排查,这就是全链路跟踪,也是开展全链路压测的第一个基础。
在说清楚了为什么需要全链路后,我们再谈谈不同架构下,对于性能测试的要求有哪些不同。在不同的架构阶段,对性能测试的要求也不一样,简单来说,可以分成4个不同的阶段:
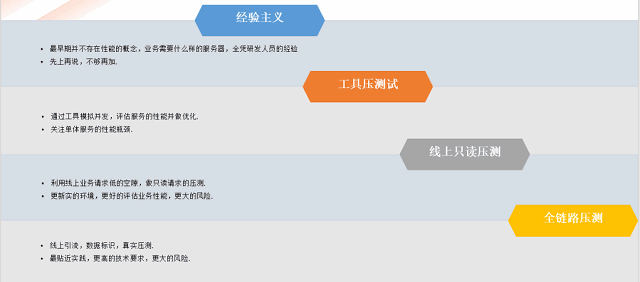
我们通常说的全链路压测,指的就是第4阶段,业务发展到这个阶段时,会面临以下几个棘手的问题:
单体业务的性能已经得到基本的保证了,但是在这么长链路上,哪个环节会出问题,并不清楚;
不同业务模块的流量并不完全相同,如何保障核心链路的资源配置,成为重点,但是这个在测试环境是无法有效模拟的;
如何找出集群的性能短板,避免因某个服务的配置问题、性能问题引起集群的性能雪崩,成为重中之重;
基于以上考量,我们引入的全链路压测的概念。
02全链路压测解决了哪些问题?
引入全链路压测试后,有助于我们解决以下几个问题:
保障重大活动的系统稳定性:引入全链路压测平台后,我们就可以有效的保障公司重大活动的系统稳定性,因为我们是以生产环境的配置为基础,真实的模拟用户行为。所以,在解决完全链路压测中发现的问题后,理论上,我们是有信心能够保障活动期间的系统稳定性
精准的容量评估:基于线上全链路的性能压测和监控,我们会清晰的看到流量洪峰来临时,每个业务的流量情况,就可以有针对性的做出容量评估,提高系统资源的利用率。
端到端的全链路巡检,第一时间发现故障并快速定位问题:基于全链路压测,我们可以做到完全的端到端检测,发现业务集群中的性能瓶颈,及时定位并解决问题,不产生遗留死角。
建立公司的性能运营体系,将运动式的性能优化演化为自发的日常性能优化:当全链路压测体系建立起来后,就可以作为常规的测试手段来进行日常测试,使性能测试常态化,规范化。
03哪些业务场景适合做
不知道大家注意到没,现在落地了全链路压测的公司,基本上都是电商公司,都存在高强度的交易和支付高并发场景。因为全链路平台的搭建是个高成本的活动,所以我们要思考哪些场景合适引入全链路测试,主要有以下几种场景:
有强并发的支付交易场景:包含各类大促场景,目前全链路压测的落地实际多出于此类头部公司,例如淘宝、有赞、滴滴、美团等。
需求正常迭代完成,并测试通过,上线后又出现各种各样的系统故障的情况,可以适当引入全链路压测。这种情况一般是由于线上线下的硬件资源配置相差较大,在线下无法正确评估性能资源的使用情况引起的。
04基础技术组件
既然全链路压测有这么多优点,我们是不是可以大力的推广落地呢?这也是很多面试官喜欢问这个问题的由来。但我们清楚,任何一种技术都不是银弹,能解决所有问题。在文章开头我们提到了,全链路压测对于整个公司技术有较高的要求,需要公司全体研发人员一起配合,才能有效的落地,否则就是空中楼阁。团队在落地全链路压测时,至少需要考虑以下几个问题:
① 如何得到业务部门的支持?
全链路压测平台不单单是测试部门,或者说测试中台的事,它基本上会涉及到公司所有的核心业务(如果不是,那也没必要做),这需要业务部门的技术配合和改造,那么,在KPI已经很紧张的情况下,如何说服业务部门配合你做改造呢?从某些方面来说,这个并不会影响他们自己部门的KPI,改造的不好,反而还会影响业务,风险较大。
② 如何做好数据隔离?
在生产环境上做压测,绝对不能对真实用户的数据造成影响,那么就需要做好数据隔离,业务侧的系统需要能够识别哪些是真实流量,哪些是压测流量。目前业内通用的做法有两种:流量标识或者影子数据库,这都需要对业务代码做改造。
③ 流量如何分发?
想要实现全链路压测,那么压力的发起就不能照搬单体性能测试那样,通过自己写脚本来发起压测。需要通过研发并发能力更强,可控性更高的方式,来发起流量。目前业内主流的方式是基于Netty框架做改造,通过NIO的方式发起流量。流量的来源一般是录制上线的真实请求并对数据加以清洗。这需要通过改造中间件来实现。
④ Mock服务能否支持
在全链路的压测过程中,必然会接触到第三方的服务(短信、支付、第三方接口等等),如何有效的拦截这些服务并返回正确的数据。而且还不能让Mock服务成为压测中的性能瓶颈,对Mock服务自身的性能要求也会很高。
⑤ 数据监控是否到位?
在全链路压测的过程中,是否能够建立起有效的、全方位的监控机制,能够第一时间发现问题?是否有分级、分层监控方案?当发现TPS上不去后,是否能够方便的定位到大致是哪里出了问题?否则全链路压测开展起来就没太大的意义。
⑥ 应急团队是否配置到位?
毕竟是在生产上做压测,如果某个服务被压跨了,是否有足够的应对方案,如果发生不可逆的故障(中间件很容易压出问题,如数据库宕机、MQ数据堆积、Redis穿透等等),运维团队是否能够有效支撑到位,快速恢复业务呢?
通过以上问题,可以看出,落地全链路测试,涉及到研发的各个部门,并不是测试人员单方面的事,甚至于可以说和测试人员没什么直接的关系。当我们想要落地全链路时,我们需要考虑清楚团队是否有足够的底层技术来支持。
05小结
全链路压测是一项综合技术要求很高的实践场景,需要整体IT团队在积累了各种前期的技术储备后,共同协作完成,并不是某个部门或者团队的事,需要有人整体的协调和统筹才能真正落地。作为测试人员,我们要了解全链路压测是在做什么,并且能大体知道是怎么做的,需要用到哪些技术能力,再结合团队的具体技术能力,分步骤、有选择的去推动和落地。而不是一味的追求直接就上全链路压测,同时,这是一项更依赖集体的活动,哪怕你技能再强,也不可能一个人完成这项工程,需要分清个人能力和公司平台哪个更重要。对于面试过程中的问题,我们可以针对的讲讲实现全链路的前因后果,理清楚技术栈和实现思路即可。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
