自学接口测试系列Python+Pandas实现Excel自动化测试用例访问

我从8月中旬开始自学接口测试进阶自动化以来关于自动化测试的第一篇正式推文,把我的学习笔记分享给大家,一起成长一起进步吼。
话不多说,学习干货都在下面啦!
一、Pandas介绍
-
Pandas简介
Pandas是一个开源的Python库,用于数据处理和数据分析。它提供了高性能、易于使用的数据结构和数据分析工具,使数据的导入、清理、处理、分析和可视化变得更加容易。Pandas的主要功能包括:
1)数据结构
- Pandas引入了两种主要的数据结构,分别是DataFrame和Series。DataFrame类似于一个二维表格,可以存储和操作各种数据类型的数据。Series则类似于一维数组或列表,是DataFrame的列。
2)数据导入和导出
- Pandas支持从各种数据源中导入数据,如CSV、Excel、SQL数据库、JSON、HTML等,同时也可以将处理后的数据导出为不同格式的文件。
3)数据清洗
- Pandas提供了强大的数据清洗工具,可以处理缺失值、重复数据、异常值等。
4)数据选择和索引
- 可以使用Pandas轻松选择和过滤数据,通过标签或位置进行索引,还可以执行各种数据选择操作。
5)数据转换和处理
- Pandas支持各种数据转换和处理操作,如排序、合并、分组、透视表、逐行/逐列应用函数等。
6)数据分析和统计
- 提供了丰富的统计分析功能,包括均值、中位数、标准差、相关性、回归分析等。
7)时间序列分析
- Pandas对于时间序列数据的处理非常强大,可以进行日期和时间的解析、频率转换、滚动统计等。
8)数据可视化
- 可以集成Matplotlib等可视化库,将数据可视化为图表、图形和图像。
9)合并和连接数据
- Pandas支持合并和连接不同数据集,包括数据库风格的合并、连接操作。
10)数据透视和重塑
- 可以根据需要对数据进行透视、堆叠和重塑,以满足分析和报告的要求。
11)数据输入和输出
- 支持将数据保存到各种文件格式中,如CSV、Excel、SQL数据库、JSON等,以及从这些格式中读取数据。
Pandas被广泛用于数据科学、数据分析、机器学习和数据处理任务,因为它提供了一种高效、方便的方式来处理和分析数据,使用户能够更容易地探索和理解数据。

-
其他数据处理和分析库
| 库名称 |
描述和特点 |
| NumPy |
NumPy是Python的一个重要库,用于高性能数值计算。它提供了多维数组(ndarray)和各种数学函数,适用于数据处理、线性代数、傅立叶变换等任务。Pandas的数据结构部分受到了NumPy的启发。 |
| Dask |
Dask是用于分布式计算的灵活库,它能够处理比内存更大的数据集。它提供了类似于Pandas的DataFrame和Series,但可以处理大规模数据,并充分利用多核处理和分布式计算。 |
| Vaex |
Vaex是一种快速、内存高效的数据分析库,专注于大规模数据集的处理。它使用延迟计算和列式存储来实现高性能的数据操作,尤其适用于数据集太大而无法装入内存的情况。 |
| Modin |
Modin是一个用于Pandas的并行化扩展,它通过利用多核CPU来加速Pandas操作。Modin的API与Pandas兼容,因此可以轻松将现有的Pandas代码迁移到Modin以获得更好的性能。 |
| Polars |
Polars是一个快速数据操作库,与Pandas和Rust语言紧密集成。它支持多线程计算,具有低内存占用,并且可以处理大规模数据集。Polars的语法类似于Pandas,易于学习和使用。 |
| Koalas (Databricks) |
Koalas是由Databricks开发的库,它为Pandas添加了分布式计算的功能,使用户可以在大数据集上使用Pandas的API。Koalas使用Apache Spark作为后端引擎,支持大规模数据处理。 |
| datatable |
datatable是用于高性能数据操作的库,它采用C++编写,具有快速的数据操作和计算能力。它的API设计类似于Pandas,适用于大规模数据和高性能需求的情况。 |
| cuDF (NVIDIA) |
cuDF是由NVIDIA开发的GPU加速数据分析库,它允许在GPU上执行Pandas操作,从而加速数据处理。适用于需要大量数据处理的机器学习和深度学习任务,特别是在GPU环境中。 |
二、Pandas安装
pandas官方说明文档:https://pandas.pydata.org/
1)打开命令行终端或命令提示符
2)运行以下命令来安装Pandas:
pip install pandas3)等待pip完成Pandas的下载和安装过程。安装完成后,可以看到相应的提示信息。

4)验证安装。在Python交互式环境中运行以下代码:
import pandas as pd如果没有出现错误消息,说明Pandas已成功安装。

成功安装Pandas后,可以在Python中使用它来进行数据处理和数据分析任务。
三、Pandas基本使用
使用Pandas进行数据处理和分析通常涉及以下基本步骤:
1)导入Pandas库
在Python脚本中,首先导入Pandas库,通常使用以下方式:
import pandas as pd这将允许您使用pd作为Pandas库的别名,使代码更具可读性。
2)数据加载
使用Pandas加载数据,可以从各种数据源中加载数据,包括CSV文件、Excel文件、SQL数据库、JSON文件等。最常用的方法是使用pd.read_*函数,例如:
-
从CSV文件加载数据
df = pd.read_csv('data.csv')-
从Excel文件加载数据
df = pd.read_excel('data.xlsx')获取文件路径的3种方式:
(1)同级目录
excel文件与py文件同级,直接获取excel文件名称即可:
sheet1_data = pd.read_excel("MMSX接口测试用例.xlsx")
(2)相对路径(最常用)
若excel文件在py文件的上一级,则excel文件的路径获取需要进行如下调整:
sheet1_data = pd.read_excel("../MMSX接口测试用例.xlsx")print(sheet1_data)(3)绝对路径:
直接复制根目录文件路径,并使用反斜杠\

-
从SQL数据库加载数据
import sqlite3conn = sqlite3.connect('database.db')df = pd.read_sql_query('SELECT * FROM table_name', conn)-
数据探索:
一旦数据加载完成,可以使用各种Pandas函数来探索数据,包括:
-
df.head():查看数据的前几行。df.tail():查看数据的最后几行。df.info():获取数据的基本信息,包括列名、非空值数量等。df.describe():生成数值列的统计摘要。df.shape:获取数据的行数和列数。df.columns:获取数据的列名。df['column_name']:选择特定列的数据。df.iloc[row_index, col_index]:通过索引选择特定数据。
-
数据清洗和预处理
数据通常需要清洗和预处理,包括处理缺失值、重复数据、异常值,以及进行数据类型转换等。Pandas提供了各种方法来进行这些操作,如:
-
df.dropna():删除包含缺失值的行或列。df.fillna(value):用指定的值填充缺失值。df.drop_duplicates():删除重复的行。df.astype(data_type):更改列的数据类型。df.replace(old_value, new_value):替换特定值。
-
数据分析和操作
使用Pandas进行数据分析和操作,包括排序、过滤、分组、聚合等。示例操作包括:
-
df.sort_values(by='column_name'):按列值排序数据。df[df['column_name'] > threshold]:根据条件过滤数据。df.groupby('column_name').agg({'column_name': 'function'}):按列进行分组和聚合操作。
-
数据可视化
使用Pandas结合可视化库(如Matplotlib、Seaborn)来绘制图表和图形,以便更好地理解数据。示例图表包括散点图、直方图、折线图等。
-
数据保存
完成数据处理和分析后,您可以使用Pandas将处理后的数据保存到不同的数据格式中,如CSV、Excel、SQL数据库等。使用to_*函数,例如:
-
保存数据到CSV文件:
df.to_csv('output_data.csv', index=False)-
保存数据到Excel文件:
df.to_excel('output_data.xlsx', index=False)-
保存数据到SQL数据库:
import sqlalchemyengine = sqlalchemy.create_engine('sqlite:///output_database.db')df.to_sql('table_name', engine, index=False)四、Excel数据访问
-
Sheet访问
默认访问Excel表格中的第一个sheet,如需访问第二个sheet中的数据,则代码应作如下调整:
sheet2_data = pd.read_excel("MMSX接口测试用例.xlsx",sheet_name="空sheet")print(sheet2_data)
若运行结果显示NaN,则表格数据为空。
-
pandas的数据结构
(1)DataFrame
DataFrame是Pandas库中的一个核心数据结构,它是一个二维、表格状的数据结构,类似于电子表格或SQL数据库中的表格。DataFrame以列为主的方式组织数据,每列可以包含不同的数据类型(例如整数、浮点数、字符串等),这使得DataFrame非常适合存储和处理结构化数据。

-
如何单独访问某一列的数据
print("*"*20)print(sheet1_data['用例编号'])
获取表格某一列的数据并识别其类型:
print(type(sheet1_data['用例编号'])
(2)Series
Series是Pandas库中的一种数据结构,它类似于一维数组或列表,但具有标签索引,可以包含不同的数据类型。Series是Pandas中最简单的数据结构之一,通常用于表示一列数据或一个数据集的一维数据。
-
Series对象由两个主要部分组成:
数据:Series中包含的一维数据,可以是整数、浮点数、字符串、日期时间等各种数据类型。 -
索引:每个数据点都关联有一个标签索引,它可以是自动创建的默认整数索引(0、1、2、...)或用户自定义的标签。索引用于访问、选择和操作Series中的数据。
-
如何访问两列数据
print("*"*10 + "访问2列数据" + "*"*10)print(sheet1_data[['用例编号',"用例标题"]])
-
单独访问某一列的某一行数据----->使用索引
print("*"*10 + "单独访问1列数据" + "*"*10)print(sheet1_data['用例编号'][0])
-
访问多列&多行的数据
print(sheet1_data[['用例编号',"用例标题"]][1:4])
-
单独访问行的数据
print(sheet1_data.iloc[[1]])
-
访问行数据后再访问指定多列
print(sheet1_data.iloc[[1,2,3],[1,2]])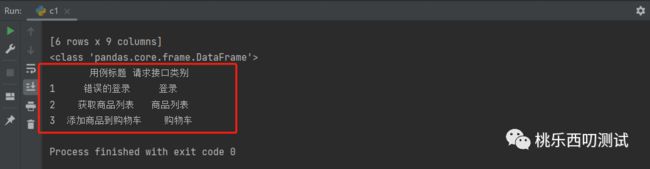
另一种写法:
print(sheet1_data.iloc[0:2,0:4])
五、Excel数据行与列遍历访问
-
把所有列的值依次取出来
for i in sheet1_data: print(i) print(sheet1_data[i])-
把所有行的值依次取出来
for i in sheet1_data.index: print(i) print(sheet1_data.iloc[[i]])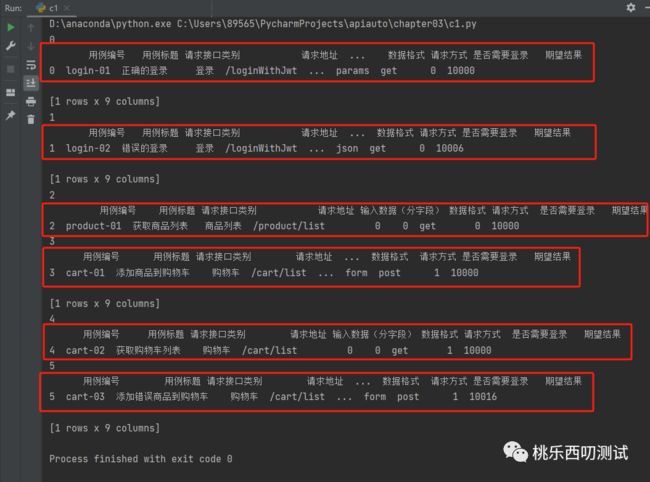
-
访问Excel中每一个单元格中的数据
for i in sheet1_data.index: for j in sheet1_data.iloc[[i]]: print(sheet1_data[j][i])
六、Excel数据筛选访问和解析
场景:只访问所有”接口请求类别中为登录“的用例
-
数据的筛选访问
login_case_type = sheet1_data[sheet1_data["请求接口类别"]=="登录"]print(login_case_type)
-
json(字典)数据解析
-
第一步:访问单元格内的json值
login_case_data = login_case_type['输入数据'][0]print(login_case_data)print(type(login_case_data))
-
第二步:将字符串类型转换为json字典
import jsonlogin_case_data_dict = json.loads(login_case_data)print(login_case_data_dict)print(type(login_case_data_dict))
-
第三步:分别获取json字典中的键值对
username = login_case_data_dict['userName']password = login_case_data_dict['password']print(username)print(password)
如果你也和小编一样,都是功能测试新手,不想被淘汰计划测试进阶学习的,欢迎加我获取接口自动化测试学习计划表~
最后:下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。