对一个变速器原理的分析
背景
原本是朋友在调试一个看起来比较新的变速器驱动,整体来说支持两种变速模式,一种是进程级,这种用了HOOK,中规中矩的实现,原理网上都有。另一种是”系统级内核全局变速“,这个模式初步看了下有些特殊,已知的关键点没被修改,也没hook。比较好奇是怎么实现的,花了几天时间分析,也有一些有意思的地方,发个文章记录一下。
一,KeQueryPerformanceCounter
写了个简单的驱动,直接调用KeQueryPerformanceCounter会被加速,那么从这里入手应当没问题。
KeQueryPerformanceCounter网上其他相关文章或多或少都有涉及,只写一下关键调用路径:
| 1 2 3 4 5 |
|
核心逻辑在最后一层的HvlGetReferenceTimeUsingTscPage中,主要是读__rdtsc()然后做一些运算:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
没开嵌套虚拟化,所以rdtsc肯定没被动手脚,调用链里涉及到的相关函数指针及代码确实都没修改。为了缩小范围及进一步排除,跳过前面几层,直接调用HvlGetReferenceTimeUsingTscPage,甚至把代码抠出来直接执行也是被加速,那么猫腻一定在这段代码里面,对其逻辑做一些分析简化:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
unk3固定是0,那就等价于:count = (__rdtsc() * HvlpReferenceTscPage->factor) >> 64;
排除hook以及rdtsc,剩下唯一的可能就是改变了factor(HvlpReferenceTscPage + 8)。
多次观察验证:
- 在不启动变速功能时,factor值一直不变,当开启加速后,factor会被修改,如果停止变速,factor值就会被还原;
- factor变化规律与加速倍率直接相关,如果调1.2倍,样本驱动就会把factor改为近似于原值*1.2,变速软件本身限制最高倍率1.5,但手动eq将factor改为原值的10倍后,系统整体就会表现出10倍速效果。
看起来很简单,但实际上分析才刚刚开始。
二,蓝屏
当朋友按照这个结论去测试时,发现HvlpReferenceTscPage+8根本就没法改,可以读,但只要写入就会发生WHEA_UNCORRECTABLE_ERROR(0x124)蓝屏,我最初一直认为是写内存方式不对,但是朋友最后发现了一些规律:
- 几乎所有写入方式,比如常用的mdl/MmGetPhyAddr+map,或者关WP位,包括windbg的eq无一例外全部都会导致0x124蓝屏;
- !pte检查map后的页属性没问题;
- 变速样本始终可以稳定运行,而且只要通过变速样本开启一次加速,即使停止加速后,随便怎么写都不会触发蓝屏。
- 蓝屏只在HyperV环境出现
当我也切换为HyperV,果然出现0x124蓝屏:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
从蓝屏栈可以看到是写内存时发生MCE异常,VBS没开而且也不像是VBS的表现,应当是hypervisor发现某些异常后,主动向虚拟机内注入的MCE,触发原因可能是EPT物理页属性只读。
理论上有一种简单的解决办法:不要直接改HvlpReferenceTscPage+8,而是自己分配一块内存,然后把指针替换到HvlpReferenceTscPage。但样本驱动不是这么干的,应当有它的原因,比如PG或者为了隐蔽?具体什么原因不重要,最关键同时也最让我好奇的是,如果真的是因为EPT页只读触发的蓝屏,那样本驱动是怎么让页变成可写的?
正面硬刚VMP是下策,所以首先尝试的思路是对常用内存相关函数下断点,没看出变速驱动有什么特殊操作,就是普普通通的IoAllocateMDL + Map,传的参数与自己的测试代码也是一模一样。 那么这个驱动在写内存前,必然还有其他操作在配合。此时要么直面VMP,要么调试HyperV,没找到能用的VMP插件,调HyperV现实一点。
三, Hyper-V
首先验证猜测,确认是不是因为EPT不可写而注入的MCE:
- 这里本该有图,不过写这个贴子的时候,距离分析已经有一段时间了,懒得再重新搭建调试环境,所以写一下关键思路和过程
- 通过搜索0x4402/0x6400定位HyperV的vcpu_run_loop()及vmexit_dispatch()
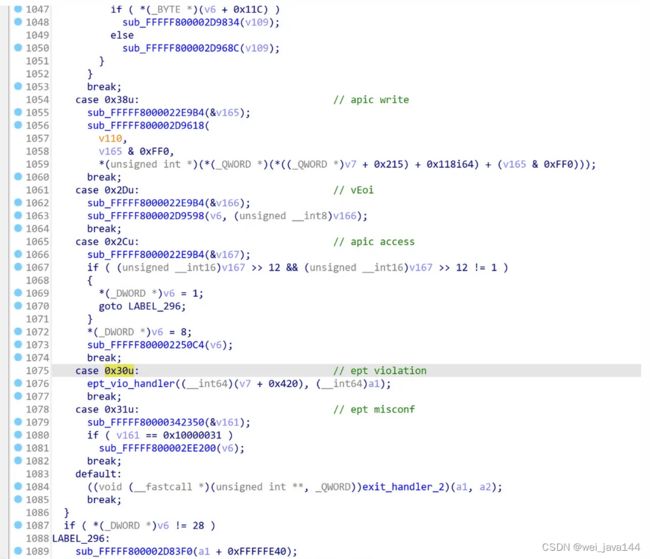
- 梳理vmexit_dispatch()内针对每种exit_reason的处理函数(重点是EPT退出)
- 在ept_vio_exit_handler内合适位置下条件断点,条件设置为vmread(0x2400h)=GPA(HvlpReferenceTscPage)
- guest内尝试写入HvlpReferenceTscPage+8;
- 断点会命中,根据vmread(0x6400)的信息或者手动转换也能发现对应页面只有读权限,再往后执行就会给子机注入MCE异常;
- 重启子机,继续下第3步的断点
- 加载变速驱动开启变速功能,断点不会命中也不会蓝屏,但对应内存已改写;随便在vcpu_run路径上下个断点,当vcpu退出命中断点,根据EPTP推一遍,会发现对应页已经是可读写;
可以证实MCE蓝屏确实是因为物理页不可写导致,接下来的关键问题是要分析变速驱动是如何让GPA从只读变成可读写的。
理论上在没有通过EFI等方式Patch hvix64.exe的情况下,要从Guest内实现改变EPTP内的GPA属性就三种方式:
- 第一种是通过vmfunc(0,)切换EPTP, 这种一般不会产生vmexit,windows内部也确实会用到,但通过断点验证可以确定当时没执行过,或者变速驱动自己调用了vmfunc(0,),通过指令搜索方式也基本上可以排除掉,VMP后vmfunc这类指令还是以原来的形式存在,在对应代码段里并不能搜索到这条指令;
- 第二种是变速驱动在guest里做了什么操作,促使hypervisor修改了对应的页面属性。这类方式首先想到的是HyperV是不是有什么VMCall,但是在VMCall的exit_handler下断点并没有什么线索;
- 第三种是bug,可能性太小。。。。
验证完自己能想到的两种方式但没有线索后,只能回到标准思路:
- 先定位HyperVisor修改页面属性的代码,然后设置条件断点判断是不是在修改HvlpReferenceTscPage所对应的GPA页属性,如果断点触发,结合host/guest当时的栈去分析。
这个思路肯定行得通,但是仔细想一下,vmfunc(0)这种唯一无VMExit的方式可以排除,那么即使想不到它具体用的什么方式,也可以确定过程中一定会产生vmexit。
所以最终我用了一个偷懒的思路,统计未开启和开启加速时的vmexit事件,对比分析差异:
- 在vcpu_run_loop()函数内,vmread(0x4402)读取到exit_reason之后的位置下断点自动trace虚拟机的vmexit信息(主要记录reason和guest_rip);
- 对比变速前后的vmexit统计信息,如果发现某些vmexit仅在变速驱动开启加速的过程中才出现,那么这些vmexit事件就很可能是突破口;
反复跑几遍,最后发现的规律是:
- 变速驱动在开启变速,改写HvlpReferenceTscPage+8之前,一定有几次rd/wrmsr,而这些msr在正常运行过中系统从不访问,并且通过vmexit时的guest_rip可以确认这些rd/wrmsr都是由变速驱动直接执行。
接下来就是具体分析这些rd/wrmsr,直接在guest_rip或者在HyperV这边的rd/wrmsr_exit_handler处下断点,再观察rd/wrmsr执行前/后VCPU ecx,edx,eax的值,就可以知道读写了哪些寄存器,以及读写的具体数据。
四, MSR 0x40000021
在HyperV的wrmsr_exit_handler处下断点,多次观察后首先发现这样一个规律:
- 开机后第一次开启加速时,变速驱动会读取MSR 0x40000021, 此时读取到的值为0xC001
- 变速驱动对这个MSR 写入0xC000(仅在第一次开启加速时才会写入)
- 后续开启加速,每次都会读但不会再写入(每次读取到的值也都是上一步中写入的0xC000);
如果只是读MSR倒也没什么,但写MSR比较可疑。搜一下MSR 0x40000021,找到这样两个相对比较有用的文档:
- https://learn.microsoft.com/en-us/virtualization/hyper-v-on-windows/tlfs/timers。
- Hyper-V Enlightenments — QEMU documentation
综合这些文档,可以知道以下关键信息:
- 0x40000021是HyperV自己定义的MSR,相当于一个接口,用于GuestOS与HyperV协商初始化Reference TSC page;
- Reference TSC page是为了给GuestOS提供一个访问时不会产生vmexit的时间戳计数器;
- MSR对应的读写数据格式为:bit 0表示是否启用Reference TSC page,bit 12-63表示GPA PageNumber,其他都是保留位;
- 默认情况下Reference TSC page功能是禁用状态,值为0,开机启动过程中由GuestOS主动写入这个MSR才能启用;
结合这些信息和上面所说的变速驱动读写0x40000021的规律,可以进一步明确其每一步的含义:
- 第一次读取rdmsr(0x40000021)返回的是0xC001:
- 解析0xC001:
- bit 0为1,那就说明此时GuestOS与HyperV已经协商并初始化Reference TSC page
- 对应GPA PageNumber为0xC,对应GPA为0xC*0x1000=0xC000
- 解析0xC001:
- 变速驱动对这个MSR写入0xC000:
- 0xC000就是0xC001清掉bit 0,其他位保持原样;bit 0表示是否启用,那么变速驱动这一步就是通过这个MSR接口,通知HyperV禁用掉Referenct TSC page;
此外还有一个最最关键的信息:
- 上面提到“0xC001对应的GPA=0xC*0x1000=0xC000”,这个0xC000其实就是HvlpReferenceTscPage的GPA,并且也正是发生EPT写入异常最终导致MCE蓝屏的GPA
结合推测,变速驱动禁用reference tsc page的目的,很有可能是禁用后HyperV就会在EPT中将对应Page的从只读变为读写。
调整测试代码,在修改内存前也加上这个操作,终于可以顺利写入HvlpReferenceTscPage;同时也在HyperV这边进行验证:
- 在wrmsr_exit_handler_0x40000021处下断点,断点触发时,确认0xC这个页面在EPT中属性为只读,随后step out,让HyperV处理完这次wrmsr,当再次中断到Windbg时,0xC页面就变为了可读写。此时尚未执行VMResume,虚拟机又是单核,VCPU退出后下一次VMResume前等同于是停转状态,这期间GuestOS不可能再有任何操作,也不可能再有其他vmexit,因此可以断定GPA从只读变为可写,100%是由wrmsr(0x40000021,0xc000)触发。
五,系统假死
解决这个页面写入问题之后,再次遇到新的问题:
- 如果将factor改为原来的10倍,虚拟机会假死,而通过变速样本驱动进行10倍加速后系统依旧正常运行
原因是GuestOS内确实变速了,但Hypervisor这边没变,而GuestOS是将时钟设备配置为OneShot模式,在这种模式下,写到时钟设备的“到期时间”是一个绝对时间,这个绝对到期时间的计算方法是:HalpHvCounterQueryCounter() + ClockInterval,这里的HalpHvCounterQueryCounter其实等同于调用KeQueryPerfCounter(),所获取到的Counter值是10倍加速后的结果,而时钟设备是由Hypervisor模拟,Hypervisor这边的时间是以正常速度流逝,所以最终时钟到期时间会越来越晚,对于GuestOS来说就是时钟中断被大幅延迟,最终DPC/线程调度全部跟着延迟,分时系统遇到这种情况必然假死。
这个结论的分析和验证过程如下:
- Hook SwapContext:发现调用次数相比正常时少了很多,线程切换调度肯定出了问题,看看DPC是否有问题
- 创建一个DPC Timer:实际执行时机相比预期时间被延迟而不是被加速,DPC Timer也有问题,那么继续看时钟中断是否有问题
- Hook HalpTimerClockInterrupt/KeClockInterruptNotify/KeUpdateRuntime:调用次数明显少于正常情况,再往下就是Hypervisor了,但不一定是Hypervisor导致,有可能是GuestOS配置的时钟周期有问题
- 结合IDA/Windbg,顺着时钟中断一路分析,发现在需要配置时钟中断到期时间时,最终都会经过以下路径:
- HalpTimerClockArm->HalpSetTimer->HalpClockTimer+0x80()->HalpHvTimerArm()
- 在HalpHvTimerArm中,就会执行上面说的HalpHvCounterQueryCounter() + ClockInterval计算绝对到期时间,并配置到时钟设备,问题是这个时间是被加速后的
- 尝试Hook HalpHvTimerArm,将其从HalpHvCounterQueryCounter()获取到的值,重新还原回加速前的正常值,再写到时钟设备,假死问题消失
HOOK HalpClockTimer+0x80指向的HalpHvTimerArm确实也是一种解决办法,但样本驱动用了另一种方案:通过两个MSR接口,额外启动另一个时钟设备,并配置为period模式,周期为1ms。怎么发现的这两个MSR,绕了一圈最后还是通过VMEXIT统计对比发现的差异,变速样本驱动在写了0x40000021之后,会继续写0x400000B2/B3这两个MSR,只是VM运行过程中vmexit本身就比较频繁,这两个WRMSR退出事件和0x40000021中间还有一大堆其他vmexit,导致最初没注意到。
六,MSR 0x400000B2/B3
这两个MSR也是HyperV自己定义的,在前面的文档中一样有描述。主要用途其实跟LAPIC Timer差不多:
- 0x400000B2 用于配置时钟模式,类似于LAPIC的LVTT(0x320)
- 关键bit:
- bit 0: Enable;是否启用;
- bit 1: Period;是否为周期性时钟;
- bit 3: AutoEnable;写入B3时是否自动启用Timer;
- bit 4:11: Vector;时钟到期时,向GuestOS注入的中断Vector;
- bit 12: DirectMode;如果为1, 时钟到期后通过标准的APIC向Guest注入中断通知子机,如果为0,则通过HyperV的SynIC注入中断通知子机;
- 关键bit:
- 0x400000B3 用于配置时钟周期/到期事件,类似于LAPIC的TMICT(0x380)
变速驱动主要是执行wrmsr(0x400000B2,0x1D1A);wrmsr(0x400000B3,0x2710),其中0x1D1A表示周期性模式+自动启用+Vector D1+DirectMode,Vector D1对应Windows的HalpTimerClockInterrupt,0x2710=1ms。这样的话即使Win自己配置到时钟设备的绝对时间是加速后的,但是变速驱动额外启动了1ms周期性时钟用于给OS维持稳定的心跳,最终就不会卡死。
至此就知道关键流程:
- 对40000021 的bit 0清零,即禁用TSCRefPage,从而使HyperV将对应GPA从只读变为读写属性;
- 通过400000B2/B3提前配置好时钟,避免变速后系统假死;
- 改写factor实现变速;
按照这个逻辑,就可以复刻变速驱动的“全局系统级变速”模式。
七,其他
-
有心人可能会对0x40000021这个接口感兴趣,简单看了下应当不太好利用,因为当写入值bit 0为0时,wrmsr_handler_0x40000021其实并不是加上”W“权限,而是直接”恢复”原来的页映射。在HyperV里叫Overlay Page,简单理解就是贴一张新的A4纸到原来的纸上,如果要禁用,那就把贴上去的A4纸撕下来,将原来的A4纸原样“显示”出来,纸上的内容还是原来的样子。另外,虽然看起来可以通过0x40000021将任一Page贴到另一个Page之上,但是新Page权限以及Page中数据是由Hypervisor强制填充,即使自己先写好也会被清零。当然我没有深究,如果感兴趣的可以自己再调一下看看。
-
最后看一下(__rdtsc() * HvlpReferenceTscPage->factor) >> 64这个运算的意义及变速原理,Windows对factor的计算逻辑是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
unsigned __int64 unk(__int64 a1, unsigned __int64 a2, unsigned __int64 a3, __int64*a4){__int64 v7;//rdi__int64 v8;//rcx__int64 v9;//r9__int64 v10;//rdx__int64 v11;//rbxv7=64i64;do{v8=2*a2;v9=(2*a1) | (a2 >>63);v10=a1 >>63;a1=v9-a3;v11=2*a2;if( (v10 | (unsigned __int64)v9) < a3 )a1=v9;a2=v11 |1;if( (v10 | (unsigned __int64)v9) < a3 )a2=v8;--v7;}while( v7 );if( a4 )*a4=a1;returna2;}传的参数是:
unk(10000000i64, 0i64, 3.19xxxx, 0i64);其中10000000是代码逻辑中写死的QPC频率;3.19xxxx是tsc频率;
这几行代码里面混着大数乘除法+定点浮点数,看着可能有点迷糊,但其实等价于:
- factor = 2^64 * qpc_freq / tsc_freq
我的机器tsc频率是3.2GHZ,按公式计算得到0xcccccccccccccc,有点怪,看到一串0xcc多少有点怀疑是不是哪搞错了,其次这个值与Win算出来的确实有点差异。
实际上是正确的,运算结果只是恰好等于0xcccccccccccccc而已,然后Win并不会通过CPUID/MSR去获取CPU的标称tsc频率,而是在启动时候用一个很短的时间去动态测算CPU的真实tsc频率,算出来的频率会是3.19xxxxxxxxGHZ,而不是标称3.2G,那么最终多少会有点误差。
这个运算的目的则是在CPU的tsc频率与Win的QPC频率之间算一个系数,用于频率转换,因为QPC在新一点的机器上一般都是建立在TSC基础之上(CPU要支持iTSC),在支持iTSC的情况下,QPC频率是代码写死的固定10MHZ,TSC频率却取决于CPU,tsc频率肯定不会等于10Mhz,那么必然要在中间做一层转换。至于为什么还要乘以2^64,因为如果不这么干,那就不可避免要涉及到浮点数运算有性能代价,不想用浮点数,又想保留小数点确保精度,最终就引入了定点数。VMX的tsc scaling也一样,只不过用的是2^48,微软直接用了2^64。
按照2^64 * qpc_freq / tsc_freq计算出factor之后,就可以通过逆运算__rdtsc()*factor>>64得到以10MHZ为基准的QPC计数值。将Factor调大,自然也就可以实现倍速,本质上跟以前的修改kuser_data差不多,都是干扰参与计算的数据,最终改变计算结果,只是修改的位置不同;
3. 以上MSR仅在虚拟机模式才有,但变速驱动在物理机上用的也是类似的方式,只是改了KeQueryPerfCounter所使用的另一个page中的factor,与虚拟机场景有一些差异,但基本也是一样的rdtsc*factor>>64运算逻辑,而且更简单,因为看了下我的物理机上本身时钟模式就是Period,实测物理机上似乎也并不会出现假死问题;
4. 至于检测,本地检测最简单的方式就是按照公式结合tsc频率,计算出原始值然后对比,但要注意的是Windows是动态计算出的tsc频率,理论上原始factor值本身就有一定误差,所以如果仅仅只进行极低倍率的变速,有可能会误判;
5. 如果直接用IDA F5去看HyperV的vcpu_run_loop函数,在某些版本的HyperV上可能看不到正确逻辑,因为紧跟VMResume和VMLanuch的一条跳转指令对IDA F5有一定干扰;
6. vcpu_run_loop与vmexit_dispatch:
搜索0x4402常量定位vcpu循环线程: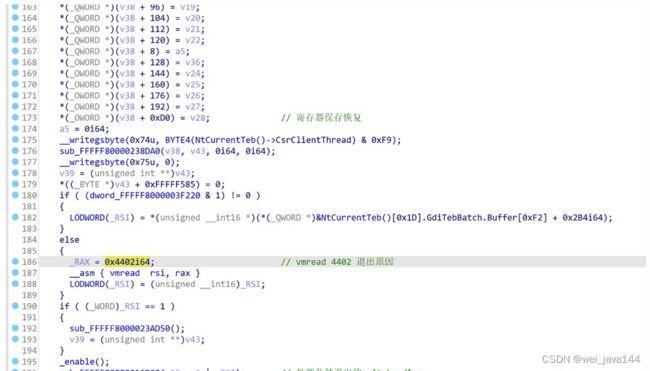
vmeixt_dispatch内针对各种vmexit的处理,根据switch_case定位各种exit的处理函数: