论文阅读 Self-Mimic Learning for Small-scale Pedestrian Detection
Self-Mimic Learning for Small-scale Pedestrian Detection
ABSTRACT
检测小尺度行人是行人检测中最具挑战性的问题之一。由于缺乏视觉细节,小尺度行人的 representations 往往难以与背景杂乱物区分开。本文深入分析了小尺度行人检测问题,揭示了小尺度行人 representations 较弱是分类器漏检的主要原因。为解决这一问题,我们提出了一种新颖的自我模仿学习(Self-Mimic Learning,简称SML)方法,以提高小尺度行人的检测性能。我们通过模仿大尺度行人的丰富 representations 来增强小尺度行人的 representations 。具体而言,我们设计了一种 mimic loss,强制小尺度行人的特征 representations 接近大尺度行人的特征representations。所提出的SML是一个通用组件,可以轻松集成到单阶段和两阶段检测器中,无需额外的网络层,并且在推断过程中不会增加额外的计算成本。在CityPersons和Caltech数据集上的大量实验证明,使用模仿损失训练的检测器对小尺度行人检测非常有效,并在CityPersons和Caltech数据集上取得了最先进的结果。
1 INTRODUCTION
行人检测在许多视觉应用中至关重要,如自动驾驶、机器人技术和视频监控。近年来,卷积神经网络(CNN)和物体检测方面的进展显著提高了行人检测的性能。当前的检测器在大尺度行人上表现良好,但在小尺度行人上的准确率有限,这是由于低分辨率图像和降采样操作导致的。事实上,许多行人检测场景中经常出现小尺度行人。例如,在Caltech数据集中,69%的行人高度在30-80像素之间,15%的行人高度低于30像素。因此,对于各种应用场景来说,检测远距离的小尺度行人至关重要。例如,自动驾驶汽车前方远处的行人应该能够被及时检测到,以便控制系统能够可靠而平稳地避免任何碰撞的可能性。
最近,一些研究工作试图通过利用大尺度对象的丰富representations 来解决小尺度目标检测问题。Li等人提出了感知生成对抗网络(Perceptual GAN),用于生成小尺度目标的超分辨率representations。尽管这种方法增强了小尺度目标的representations能力,但感知GAN中使用的生成器在推理过程中引入了相对较高的计算开销。为了减少不同尺度对象之间的特征差异,Kim等人提出了一个Scale Aware Network(SAN),将来自不同尺度的卷积特征映射到尺度不变子空间。然而,SAN仅仅对小对象的图像块进行上采样,这可能导致图像块模糊。在本文中,我们旨在设计一种简单有效的方法,以在推理过程中最小化计算开销的情况下增强小尺度行人的特征representations。
受到模型acceleration 和compression 中使用的模仿技术的启发,我们利用一种模仿方法来增强小尺度行人的representations。目标检测中的模仿学习的本质是,一个小模型可以通过模仿来自大模型的特征来学习更好的representations。基于这一观点,我们提出了一种自我模仿学习方法,它将模仿技术扩展到一个单一模型中,以在大尺度行人的帮助下学习小尺度行人的超分辨率representations,从而实现了模型的自我模仿学习。具体而言,我们通过一种模仿损失训练深度卷积神经网络(CNN),该损失旨在强制小尺度行人的特征分布近似模仿来自相同网络结构的大尺度行人的特征分布。
我们基于实例级别的特征实现了我们的模仿方法。如图1所示,大尺度行人的RoI特征(由RoI Align输出)通常保留比小尺度行人更多的有用信息。因此,我们将它们用作参考,帮助小尺度行人近似学习大尺度行人的特征分布。通过强制小尺度行人的特征接近大尺度行人的特征,可以为小尺度行人检测带来两方面好处。首先,小尺度行人的遗漏细节在特征空间中得到了补偿,从而增强了小尺度行人的representations。其次,行人特征的内部类间差异减小,使分类器更容易将小尺度行人与背景区分开来。

我们所提出的SML是一个通用组件,可以轻松集成到具有任何骨干网络的一阶段和二阶段检测器中。它仅通过模仿损失将大尺度行人的监督引入小尺度行人,而无需添加任何网络层。因此,在推理过程中不会产生任何额外的计算成本。为了验证SML的有效性,我们在Caltech和CityPersons行人检测数据集上使用ResNet-18和ResNet-50进行了全面的实验。SML有效地提高了小尺度行人的性能,并实现了最先进的检测性能。
2 RELATED WORK
略过
3 ANALYSIS OF SMALL-SCALE PEDESTRIAN DETECTION
Dataset 在现实世界的场景中,小尺度行人经常出现。我们对CityPersons数据集进行了分析,该数据集包含5,000张图像,包含35,000个行人和13,000个被忽略的区域注释。Reasonable subset 是用于评估行人检测器综合性能的常见设置,其中行人的身高要大于50像素,不遮挡超过35%。其中,小尺度行人仍然占很大比例。例如,身高在[50, 75]之间的行人的比例为24.3%,而原始图像的分辨率为1,024×2,048像素。
Missed Detection。我们以两阶段检测器为例,分析小尺度行人的误分类问题。在两阶段检测器中,例如Faster R-CNN ,检测一个对象有两个阶段。第一阶段是生成proposals 并使用它们提取RoI特征。在第二阶段,这些RoI特征被输入到头网络进行分类和边界框回归。为了覆盖不同尺度的对象,区域建议网络(RPN)在第一阶段生成大量proposals。然而,即使有大量proposals,检测器在第二阶段仍然倾向于错过小尺度行人。
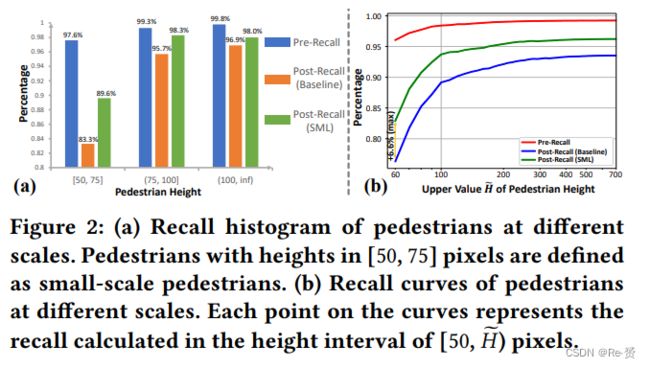
为了深入研究小尺度行人的漏检问题,我们计算了两种类型的召回率,Pre-Recall和Post-Recall,用于不同尺度的行人。我们将Pre-Recall定义为与至少一个proposals 相关联的 groundtruth示例的百分比,将Post-Recall定义为与至少一个被正确分类的proposals 相关联的groundtruth示例的百分比(即分类得分≥0.5)。我们在本次实验中使用了基于Faster R-CNN的基线检测器(在第4.1节中描述),其中从RPN中生成了1,000个proposals 。如图2(a)所示,不同尺度的行人的Pre-Recalls接近,达到了95%以上的高值。然而,对于小尺度行人,基线的召回率从97.6%(Pre-Recall)下降到了83.3%(Post-Recall),而对于大尺度行人,从Pre-Recall到Post-Recall的下降仅为3.6%和2.9%。从图2(b)中还可以看出,在H小于100像素时,Pre-Recall和Post-Recall之间存在很大差距。图2的结果表明,尽管RPN检测到了大多数小尺度行人,但由于特征representations 较弱,许多小尺度行人在第二阶段没有被正确分类。
为了更好地理解小尺度行人的漏检问题,图3中可视化了一些漏检示例。我们观察到小尺度行人被RPN生成的准确proposals 所定位。然而,它们被头网络视为具有低于0.5的分类得分的背景区域。本节的分析表明,误分类主要导致小尺度行人的性能不佳。

4 SELF-MIMIC LEARNING
在本节中,我们首先概述基于两阶段检测器的方法,然后介绍模仿损失函数。随后,我们将介绍SML的实现方案。此外,我们还在补充材料中介绍了如何将我们的方法扩展到一阶段检测器。
4.1 Overview
Baseline Detector 在本文中,我们将Faster R-CNN 作为基准检测器,并使用ResNet-18或ResNet-50作为骨干网络,配合特征金字塔网络(Feature Pyramid Network,FPN)和可变形卷积(Deformable Convolution)来实现它。
Self-Mimic Learning 在先前的研究中,mimicking 技术主要用于模型加速和压缩。我们将模仿思想扩展到了来自同一神经网络数据样本的特征空间,使小尺度行人的特征分布接近于大尺度行人。
根据第3节的分析,大多数小尺度行人的区域可以通过RPN生成的 proposals 很好地定位。考虑到大尺度行人通常具有更丰富的特征representations,强制小尺度行人的特征分布模仿RoI特征空间中的大尺度行人是一个合理的想法,从而增强了小尺度行人的representations,概念上以更多的视觉细节编码,就像具有更高分辨率的行人一样。在SML中,身高在(0, HS ] 像素范围内的行人被定义为小尺度行人,而身高在 (HS , HL] 像素范围内的行人被视为大尺度行人。我们不考虑超大尺度行人,其身高高于HL像素,因为超大尺度和小尺度行人之间的representations 之间存在很大差距。
图4(a)展示了我们方法的框架。首先,将输入图像传入特征金字塔网络(FPN)以提取多尺度特征图。然后,RPN建立在这些特征图之上,生成具有不同大小的proposals。RoI Align操作将proposals和特征图作为输入,并输出维度为7×7×256的RoI特征。在这些RoI特征中,小尺度行人的特征模仿大尺度行人的特征。通过优化模仿损失(在第4.2节中定义),不仅小尺度行人从大尺度行人那里学到了超分辨率representations,而且类内方差也得到了减少。随后,具有更丰富和一致representations 的小尺度行人的RoI特征被送入头网络,以便进行更容易的分类和回归。

4.2 Mimic Loss
对于检测任务,特征图对于确定分类和定位的准确性都至关重要。我们在小尺度和大尺度行人的RoI特征上实现了所提出的模仿方法。SML的总损失函数定义如下:
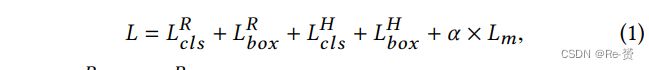
在上述损失函数中,LRcls和LRbox 分别是RPN的分类损失和边界框回归损失,LHcls和LHbox 分别是头网络的分类损失和边界框回归损失。对于分类损失LRcls和LHcls,我们使用两个类别(行人和背景)的交叉熵损失。对于回归损失LRbox和 LHbox,我们使用平滑L1损失函数。Lm表示由α加权的模仿损失。
我们用FL ∈ Rd表示大尺度行人(HS < height ≤ HL)的RoI特征,用FS ∈ Rd表示小尺度行人(0 < height ≤ HS)的RoI特征,d = 7 × 7 × 256是特征的维度。请注意,这里行人指的是与训练图像中至少一个 ground-truth行人示例具有IoU ≥ 0.5的proposal。在训练数据中,我们用L = {F1L, …, FNL}表示N个大尺度行人的RoI特征,用S = {F1S, …, FMS}表示M个小尺度行人的RoI特征。
理想情况下,我们的目标是强制S中的特征模仿L中的特征,使S和L在特征空间中具有类似的概率分布,即p(FS) ≈ p(FL)。然而,鉴于有限的训练样本,直接优化高维分布是困难的。通常情况下,行人特征的分布是多模态的,因此我们选择通过将S中每个小尺度行人的特征推向L中大尺度行人的特征的local centroids之一来近似实现模仿学习目标。因此,我们将模仿损失Lm定义为:
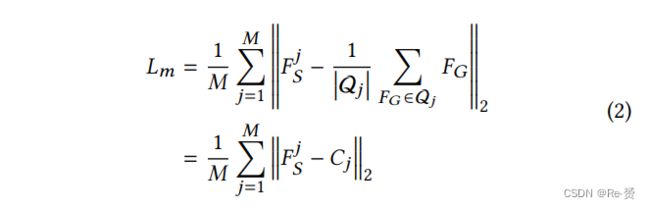
对于每个小尺度行人特征FjS,Qj ⊆ L是它在L中的模仿特征的集合。当Qj ⊂ L时,Qj可以被视为训练集中所有大尺度行人样本的一个子模态,而Cj是L中的 local centroid 。相反,当Qj = L时,Cj成为L中大尺度行人的全局均值特征。图4(b)说明了公式2的思想。我们将在下一节介绍如何为每个FjS选择本地中心Cj。
4.3 Implementation
我们介绍了两种选择每个小尺度行人样本的 local centroid Cj 的实现方案,如下所示:
Offline self-mimic learning 在此方案中,我们首先在数据集上训练一个基准检测器作为 reference detector,并收集所有大尺度行人的RoI特征。然后,我们使用 k-means 将这些RoI特征聚类成K个簇。我们计算每个小尺度行人FjS的RoI特征与每个簇的中心之间的距离。我们选择最近的簇中心作为FjS的Cj。离线SML是一种直接的方法,用于划分大尺度行人的特征空间,并利用它们的中心来引导小尺度行人的特征学习。
Online self-mimic learning 在这种方案中,我们仅训练网络一次,而不训练额外的 reference detector。对于每个FjS,我们将本地中心Cj 定义为在获得FjS 的同一图像中的大尺度行人的RoI特征的平均值。在训练过程中,我们不会反向传播大尺度行人的模仿损失的梯度,因为大尺度行人仅用作小尺度行人学习超分辨率representations 的参考。根据行人检测数据集的统计信息,超过75%的图像同时包含小尺度和大尺度的行人示例。因此,在线SML是高效且易于实现模仿学习的端到端方式。
离线SML考虑了所有大尺度行人样本的视觉特征的不同模态。而在线SML更关注图像上下文的模态(例如,光照和天气条件)。我们将在第6.2节中讨论并比较这两种方案。
5 DISCUSSION
SML带来了两个好处:1) 增强了小尺度行人的 representations,2) 减少了类内方差,共同促进了对小尺度行人的性能改善以及对所有尺度的整体性能改善。
1) Representation enhancement for small-scale pedestrians:
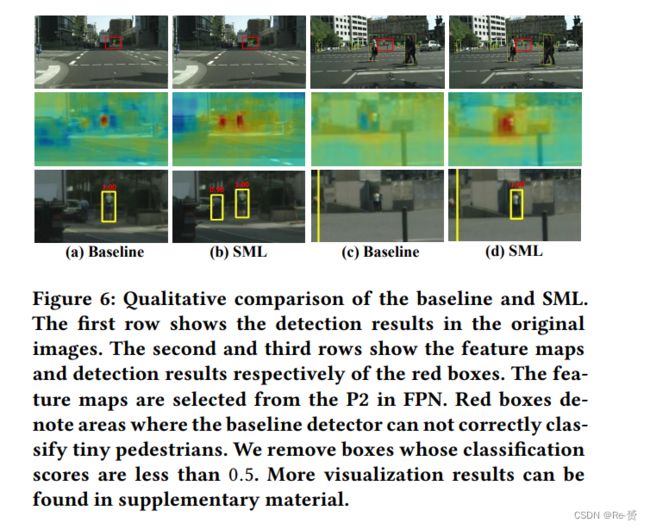
模仿损失迫使小尺度行人的特征接近大尺度行人的 local feature centroids,从而在特征空间中在一定程度上补偿了它们缺失的细节。这有效增强了小尺度行人的特征representations,因此提高了对小尺度行人的检测性能。为了验证这一点,我们使用与基准检测器相同的proposals集,并计算SML的Post-Recall。如图2 (1)所示,SML在小尺度行人的Post-Recall上表现优于基准检测器,小尺度行人的Post-Recall有显著提高,提高了小尺度行人的分类性能。在图2 (b)中,SML在不同高度范围内一致提高了基准检测器的Post-Recall,最大增益出现在[50, 60]的高度区间,增益为6.6%。图6显示了基准检测器和SML之间的定性比较。我们可以看到,使用SML后,特征图中的小尺度行人区域更具有区分性,响应更高,这是由于SML的特征补偿效果。这些定量和定性分析验证了SML增强小尺度行人特征表示的效果。
2) Intra-class variance reduction
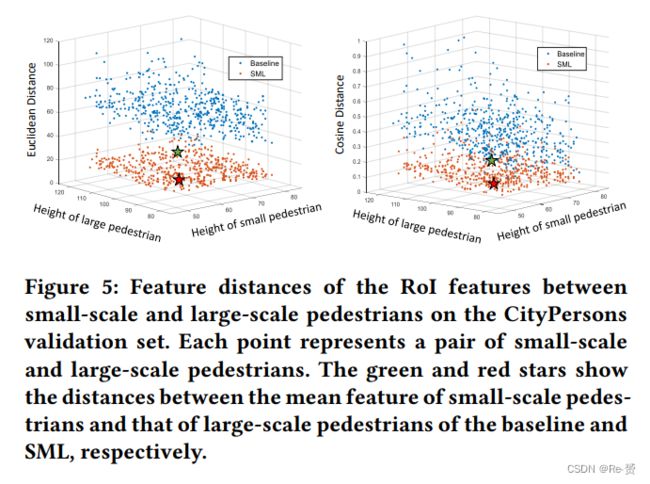
我们计算了小尺度和大尺度行人之间的特征距离。我们使用了两种类型的distance metrics:欧氏距离和余弦距离。欧氏距离定义为DEuclidean = ∥FL − FS ∥2,描述了两个实例之间RoI特征的空间距离。余弦距离计算为Dcosine = 1 − FL ·FS / (∥FL ∥ ∥FS ∥),描述了两个实例之间RoI特征的方向相似度。如图5所示,SML显著减小了特征空间中小尺度和大尺度行人之间的欧氏距离和余弦距离。因此,减小了类内方差,使头网络更容易分类行人和背景。这也有助于大尺度行人的检测,如图2所示。
6 EXPERIMENTS
略过
7 CONCLUSION
In this paper, we analyze the low recall and limited detection performance of small-scale pedestrian and reveal that the main cause is misclassification of small instances. Based on the analysis, we propose a Self-Mimic Learning method to enhance the representations for small-scale pedestrians and reduce intra-class feature variance by mimicking rich representations from large-scale pedestrians. To achieve this, we enforce the feature representations of small-scale pedestrians to approach those of large-scale pedestrians by making the RoI features of small-scale pedestrians mimic the local average RoI features of large-scale pedestrians. Our approach is a general component which can be efficiently applied to both one-stage and two-stage detectors with any backbone network to improve the feature representations of small-scale pedestrians. Exhaustive experiments on both Caltech and CityPersons datasets validate the effectiveness and superiority of our approach.