常见的应用级算法(上)
常见的应用级算法
- 1.算法思想
-
- 1.分而治之
- 2.动态规划
- 3.贪心算法
- 4.回溯算法
- 5.分支限界
- 2.失效算法与应用
-
- 1.先来先淘汰 ---- FIFO
- 2.最久未用淘汰 ---- LRU
- 3.最近最少使用 ---- LFU
- 4.应用案例
- 3.限流算法与应用
-
- 1.计数器
- 2.漏桶算法
- 3,令牌桶
- 4 滑动窗口
- 4.调度算法与应用
-
- 1.先来先服务(FCFS)
- 2.短作业优先 (SJF)
- 3.时间片轮转(RR)
- 4.应用案例
- 5.定时算法与应用
-
- 1.最小堆
- 2.时间轮
1.算法思想
1.分而治之
把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到最后子问题小到可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换),大数据中的MR,现实中如汉诺塔游戏
分治法对问题有一定的要求:
- 该问题缩小到一定程度后,就可以轻松解决
- 问题具有可拆解性,不是一团无法拆分的乱麻
- 拆解后的答案具有可合并性。能组装成最终结果
- 拆解的子问题要相互独立,互相之间不存在或者很少有依赖关系
2.动态规划
基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他。依次解决各子问题,最后一个子问题就是初始问题的解
与分治法最大的不同在于,分治法的思想是并发,动态规划的思想是分步。该方法经分解后得到的子问题往往不是互相独立的,其下一个子阶段的求解往往是建立在上一个子阶段的解的基础上。动态规划算法同样有一定的适用性场景要求:
- 最优化解:拆解后的子阶段具备最优化解,且该最优化解与追踪答案方向一致
- 流程向前,无后效性:上一阶段的解决方案一旦确定,状态就确定,只会影响下一步,而不会反向影响
- 阶段关联:上下阶段不是独立的,上一阶段会对下一阶段的行动提供决策性指导。这不是必须的,但是如果具备该特征,动态规划算法的意义才能更大的得到体现
3.贪心算法
同样对问题要求作出拆解,但是每一步,以当前局部为目标,求得该局部的最优解。那么最终问题解决时,得到完整的最优解。也就是说,在对问题求解时,总是做出在当前看来是最好的选择,而不去从整体最优上加以考虑。从这一角度来讲,该算法具有一定的场景局限性
- 要求问题可拆解,并且拆解后每一步的状态无后效性(与动态规划算法类似)
- 要求问题每一步的局部最优,与整体最优解方向一致。至少会导向正确的主方向
4.回溯算法
回溯算法实际上是一个类似枚举的搜索尝试过程,在每一步的问题下,列举可能的解决方式。选择某个方案往深度探究,寻找问题的解,当发现已不满足求解条件,或深度达到一定数量时,就返回,尝试别的路径。回溯法一般适用于比较复杂的,规模较大的问题。有“通用解题法”之称
- 问题的解决方案具备可列举性,数量有限
- 界定回溯点的深度。达到一定程度后,折返
5.分支限界
与回溯法类似,也是一种在空间上枚举寻找最优解的方式。但是回溯法策略为深度优先。分支法为广度优先。分支法一般找到所有相邻结点,先采取淘汰策略,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从存活表中选择一个结点作为下一个操作对象
2.失效算法与应用
失效算法常见于缓存系统中。因为缓存往往占据大量内存,而内存空间是相对昂贵,且空间有限的,那么针对一部分值,就要依据相应的算法进行失效或移除操作
1.先来先淘汰 ---- FIFO
1.概述: 先来先淘汰。这种算法在每一次新数据插入时,如果队列已满,则将最早插入的数据移除
2.FIFO代码实现:
package com.andy.failure;
import java.util.LinkedList;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-14 16:47
*/
public class FIFO {
LinkedList<Integer> fifo = new LinkedList<Integer>();
int size = 3;
//添加元素
public void add(int i){
fifo.addFirst(i);
if (fifo.size() > size){
fifo.removeLast();
}
print();
}
//缓存命中
public void read(int i){
for (int j : fifo) {
if (i == j) {
System.out.println("--Andy--有元素--");
print();
return;
}
}
System.out.println("--Andy--没有元素--");
print();
}
//打印缓存
public void print(){
System.out.println(this.fifo);
}
}
3.FIFO测试代码:
package com.andy.failure;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-14 16:48
*/
public class FIFO_MAIN {
public static void main(String[] args) {
FIFO fifo = new FIFO();
System.out.println("添加 1-3:");
fifo.add(1);
fifo.add(2);
fifo.add(3);
System.out.println("添加 4:");
fifo.add(4);
System.out.println("读取 2:");
fifo.read(2);
System.out.println("读取 100:");
fifo.read(100);
System.out.println("添加 5:");
fifo.add(5);
}
}
3.运行结果:

4.结果分析
- 1-3按顺序放入,没有问题
- 4放入,那么1最早放入,被挤掉
- 读取2,读到,但是不会影响队列顺序(2依然是时间最老的)
- 读取100,读不到,也不会产生任何影响
- 5加入,踢掉了2,而不管2之前有没有被使用(不够理性)
2.最久未用淘汰 ---- LRU
1.概述:淘汰最后一次使用时间最久远的数值。FIFO非常的粗暴,不管有没有用到,直接踢掉时间久的元素。而LRU认为,最近频繁使用过的数据,将来也很大程度上会被频繁用到,故而淘汰那些懒惰的数据。LinkedHashMap,数组,链表均可实现LRU
2.LRU代码实现:
package com.andy.failure.lru;
import java.util.Iterator;
import java.util.LinkedList;
public class LRU {
LinkedList<Integer> lru = new LinkedList<Integer>();
int size = 3;
// 添加元素
public void add(int i){
lru.addFirst(i);
if (lru.size() > size){
lru.removeLast();
}
print();
}
// 缓存命中
public void read(int i){
Iterator<Integer> iterator = lru.iterator();
int index = 0;
while (iterator.hasNext()){
int j = iterator.next();
if (i == j){
System.out.println("find it!");
lru.remove(index);
lru.addFirst(j);
print();
return ;
}
index++;
}
System.out.println("not found!");
print();
}
// 打印缓存
public void print(){
System.out.println(this.lru);
}
}
3.LFU测试代码
package com.andy.failure.lru;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-14 17:28
*/
public class LRU_MAIN {
public static void main(String[] args) {
LRU lru = new LRU();
System.out.println("添加 1-3:");
lru.add(1);
lru.add(2);
lru.add(3);
System.out.println("添加 4:");
lru.add(4);
System.out.println("获取 2:");
lru.read(2);
System.out.println("获取 100:");
lru.read(100);
System.out.println("添加 5:");
lru.add(5);
}
}
4.运行结果:

5.运行分析;
- 1-3加入,没有问题
- 4加入,踢掉1,没问题
- 读取2,读到,注意,2被移到了队首!
- 读取100,读不到,没影响
- 5加入,因为2之前被用到,不会被剔除,3和4都没人用,但是3更久,被剔除
3.最近最少使用 ---- LFU
1.概述:它要淘汰的是最近一段时间内,使用次数最少的值。可以认为比LRU多了一重判断。LFU需要时间和次数两个维度的参考指标。需要注意的是,两个维度就可能涉及到同一时间段内,访问次数相同的情况,就必须内置一个计数器和一个队列,计数器算数,队列放置相同计数时的访问时间
2.lfu代码实现:
package com.andy.failure.lfu;
public class Dto implements Comparable<Dto> {
private Integer key;
private int count;
private long lastTime;
public Dto(Integer key, int count, long lastTime) {
this.key = key;
this.count = count;
this.lastTime = lastTime;
}
@Override
public int compareTo(Dto o) {
int compare = Integer.compare(this.count, o.count);
return compare == 0 ? Long.compare(this.lastTime, o.lastTime) : compare;
}
@Override
public String toString() {
return String.format("[key=%s,count=%s,lastTime=%s]",key,count,lastTime);
}
public Integer getKey() {
return key;
}
public void setKey(Integer key) {
this.key = key;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public long getLastTime() {
return lastTime;
}
public void setLastTime(long lastTime) {
this.lastTime = lastTime;
}
}
package com.andy.failure.lfu;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class LFU {
private final Map<Integer,Integer> cache = new HashMap<>();
private final Map<Integer, Dto> count = new HashMap<>();
// 投放
public void put(Integer key, Integer value) {
Integer v = cache.get(key);
if (v == null) {
int size = 3;
if (cache.size() == size) {
removeElement();
}
count.put(key, new Dto(key, 1, System.currentTimeMillis()));
} else {
addCount(key);
}
cache.put(key, value);
}
// 读取
public Integer get(Integer key) {
Integer value = cache.get(key);
if (value != null) {
addCount(key);
return value;
}
return null;
}
// 淘汰元素
private void removeElement() {
Dto dto = Collections.min(count.values());
cache.remove(dto.getKey());
count.remove(dto.getKey());
}
// 更新计数器
private void addCount(Integer key) {
Dto Dto = count.get(key);
Dto.setCount(Dto.getCount()+1);
Dto.setLastTime(System.currentTimeMillis());
}
// 打印缓存结构和计数器结构
public void print(){
System.out.println("缓存 = " + cache);
System.out.println("统计 = " + count);
}
}
3.lfu测试代码:
package com.andy.failure.lfu;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-14 17:18
*/
public class LFU_MAIN {
public static void main(String[] args) {
LFU lfu = new LFU();
// 前3个容量没满,1,2,3均加入
System.out.println("添加 1-3:");
lfu.put(1, 1);
lfu.put(2, 2);
lfu.put(3, 3);
lfu.print();
// 1,2有访问,3没有,加入4,淘汰3
System.out.println("获取 1,2");
lfu.get(1);
lfu.get(2);
lfu.print();
System.out.println("添加 4:");
lfu.put(4, 4);
lfu.print();
// 2=3次,1,4=2次,但是4加入较晚,再加入5时淘汰1
System.out.println("添加 2,4");
lfu.get(2);
lfu.get(4);
lfu.print();
System.out.println("添加 5:");
lfu.put(5, 5);
lfu.print();
}
}
4.运行结果:
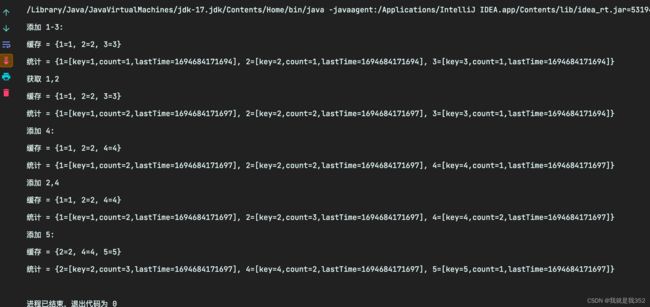
5.结果分析:
- 1-3加入,没问题,计数器为1次
- 访问1,2,使用次数计数器上升为2次,3没有访问,仍然为1
- 4加入,3的访问次数最少(1次),所以踢掉3,剩下124
- 访问2,4,计数器上升,2=3次,1,4=2次,但是1时间久
- 5加入,踢掉1,最后剩下2,4,5
4.应用案例
redis属于缓存失效的典型应用场景,常见策略如下:
- noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息( 比较危险)。
- allkeys-lru:对所有key,优先删除最近最少使用的 key (LRU)。
- allkeys-random: 对所有key, 随机删除一部分(听起来毫无道理)。
- volatile-lru:只限于设置了 expire 的key,优先删除最近最少使用的key (LRU)。
- volatile-random:只限于设置了 expire 的key,随机删除一部分。
- volatile-ttl:只限于设置了 expire 的key,优先删除剩余时间(TTL) 短的key。
3.限流算法与应用
限流是对系统的一种保护措施。即限制流量请求的频率(每秒处理多少个请求)。一般来说,当请求流量超过系统的瓶颈,则丢弃掉多余的请求流量,保证系统的可用性。即要么不放进来,放进来的就保证提供服务
1.计数器
1.概述:计数器采用简单的计数操作,到一段时间节点后自动清零
2.代码实现
package com.andy.current;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 13:59
* 计数器
*/
public class Counter {
public static void main(String[] args) {
//计数器,这里用信号量实现
final Semaphore semaphore = new Semaphore(3);
//定时器,到点清零
ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
semaphore.release(3);
}
},3000,3000, TimeUnit.MILLISECONDS);
//模拟无数个请求从天而降
while (true) {
try {
//判断计数器
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
//如果准许响应,打印一个ok
System.out.println("ok");
}
}
}
3.结果分析:3个ok一组呈现,到下一个计数周期之前被阻断
4.优缺点:
- 实现起来非常简单
- 控制力度太过于简略,假如1s内限制3次,那么如果3次在前100ms内已经用完,后面的900ms将只能处于阻塞状态,白白浪费掉
5.应用:使用计数器限流的场景较少,因为它的处理逻辑不够灵活。最常见的可能在web的登录密码验证,输入错误次数冻结一段时间的场景。如果网站请求使用计数器,那么恶意攻击者前100ms吃掉流量计数,使得后续正常的请求被全部阻断,整个服务很容易被搞垮
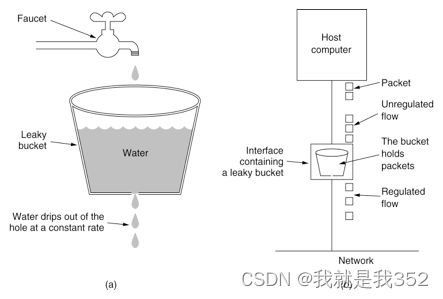
2.漏桶算法
1.概述:漏桶算法将请求缓存在桶中,服务流程匀速处理。超出桶容量的部分丢弃。漏桶算法主要用于保护内部的处理业务,保障其稳定有节奏的处理请求,但是无法根据流量的波动弹性调整响应能力。现实中,类似容纳人数有限的服务大厅开启了固定的服务窗
2.实现:
package com.andy.current;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 14:20
* 漏桶算法
*/
public class Barrel {
public static void main(String[] args) {
// 桶,用阻塞队列实现,容量为3
final LinkedBlockingQueue<Integer> que = new LinkedBlockingQueue(3);
// 定时器,相当于服务的窗口,2s处理一个
ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
int v = que.poll();
System.out.println("处理:" + v);
}
}, 2000, 2000, TimeUnit.MILLISECONDS);
// 无数个请求,i 可以理解为请求的编号
int i = 0;
while (true) {
i++;
try {
System.out.println("put:" + i);
// 如果是put,会一直等待桶中有空闲位置,不会丢弃
// que.put(i);
// 等待1s如果进不了桶,就溢出丢弃
que.offer(i, 1000, TimeUnit.MILLISECONDS);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
3.优缺点
- 有效的挡住了外部的请求,保护了内部的服务不会过载
- 内部服务匀速执行,无法应对流量洪峰,无法做到弹性处理突发任务
- 任务超时溢出时被丢弃。现实中可能需要缓存队列辅助保持一段时间
4.应用:nginx中的限流是漏桶算法的典型应用,配置案例如下:
http {
#$binary_remote_addr 表示通过remote_addr这个标识来做key,也就是限制同一客户端ip地址。
#zone=one:10m 表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息。
#rate=1r/s 表示允许相同标识的客户端每秒1次访问
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /limited/ {
#zone=one 与上面limit_req_zone 里的name对应。
#burst=5 缓冲区,超过了访问频次限制的请求可以先放到这个缓冲区内,类似代码中的队列长度。
#nodelay 如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回503,如果没有设置,则所有请求会等待排队,类似代码中的put还是offer。
limit_req zone=one burst=5 nodelay;
}
}
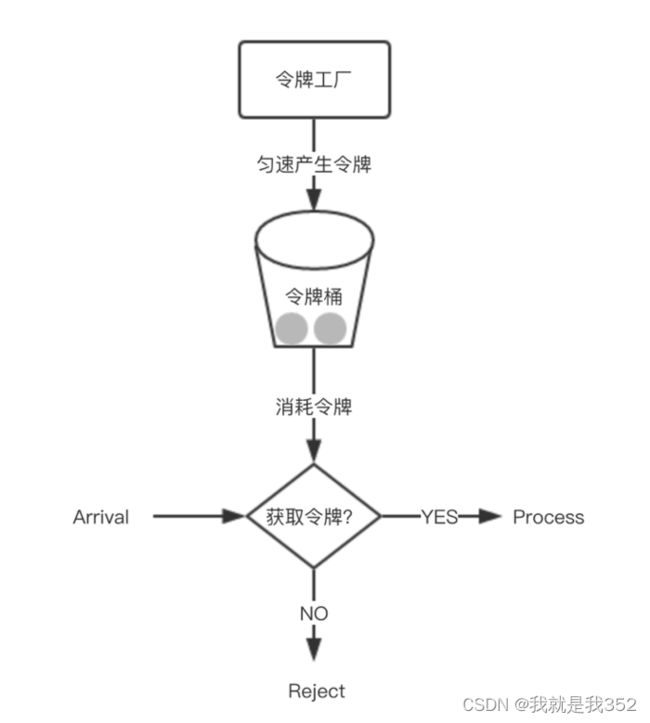
3,令牌桶
1.概述:令牌桶算法可以认为是漏桶算法的一种升级,它不但可以将流量做一步限制,还可以解决漏桶中无法弹性伸缩处理请求的问题。体现在现实中,类似服务大厅的门口设置门禁卡发放。发放是匀速的,请求较少时,令牌可以缓存起来,供流量爆发时一次性批量获取使用。而内部服务窗口不设限
2.实现
package com.andy.current;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 14:38
* 令牌桶
*/
public class Token {
public static void main(String[] args) throws InterruptedException {
// 令牌桶,信号量实现,容量为3
final Semaphore semaphore = new Semaphore(3);
// 定时器,1s一个,匀速颁发令牌
ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
if (semaphore.availablePermits() < 3) {
semaphore.release();
}
// System.out.println("令牌数:"+semaphore.availablePermits());
}
}, 1000, 1000, TimeUnit.MILLISECONDS);
// 等待,等候令牌桶储存
Thread.sleep(5);
// 模拟洪峰5个请求,前3个迅速响应,后两个排队
for (int i = 0; i < 5; i++) {
semaphore.acquire();
System.out.println("洪峰:" + i);
}
// 模拟日常请求,2s一个
for (int i = 0; i < 3; i++) {
Thread.sleep(1000);
semaphore.acquire();
System.out.println("日常:" + i);
Thread.sleep(1000);
}
// 再次洪峰
for (int i = 0; i < 5; i++) {
semaphore.acquire();
System.out.println("洪峰:" + i);
}
// 检查令牌桶的数量
for (int i = 0; i < 5; i++) {
Thread.sleep(2000);
System.out.println("令牌剩余:" + semaphore.availablePermits());
}
}
}
3.结果分析
- 洪峰0-2迅速被执行,说明桶中暂存了3个令牌,有效应对了洪峰
- 洪峰3,4被间隔性执行,得到了有效的限流
- 日常请求被匀速执行,间隔均匀
- 第二波洪峰来临,和第一次一样
- 请求过去后,令牌最终被均匀颁发,积累到3个后不再上升
4.应用
springcloud中gateway可以配置令牌桶实现限流控制,案例如下:
cloud:
gateway:
routes:
- id: limit_route
uri: http://localhost:8080/test
filters:
- name: RequestRateLimiter
args:
#限流的key,ipKeyResolver为spring中托管的Bean,需要扩展KeyResolver接口
key-resolver: '#{@ipResolver}'
#令牌桶每秒填充平均速率,相当于代码中的发放频率
redis-rate-limiter.replenishRate: 1
#令牌桶总容量,相当于代码中,信号量的容量
redis-rate-limiter.burstCapacity: 3
4 滑动窗口
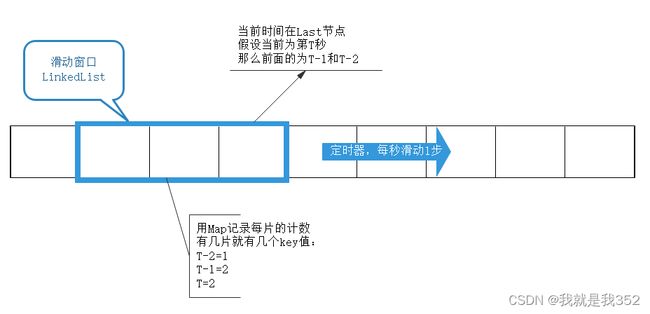
1.概述:滑动窗口可以理解为细分之后的计数器,计数器粗暴的限定1分钟内的访问次数,而滑动窗口限流将1分钟拆为多个段,不但要求整个1分钟内请求数小于上限,而且要求每个片段请求数也要小于上限。相当于将原来的计数周期做了多个片段拆分。更为精细

2.实现
package com.andy.current;
import java.util.LinkedList;
import java.util.Map;
import java.util.TreeMap;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 14:43
* 滑动
*/
public class Window {
// 整个窗口的流量上限,超出会被限流
final int totalMax = 5;
// 每片的流量上限,超出同样会被拒绝,可以设置不同的值
final int sliceMax = 5;
// 分多少片
final int slice = 3;
// 窗口,分3段,每段1s,也就是总长度3s
final LinkedList<Long> linkedList = new LinkedList<>();
// 计数器,每片一个key,可以使用HashMap,这里为了控制台保持有序性和可读性,采用TreeMap
Map<Long, AtomicInteger> map = new TreeMap();
// 心跳,每1s跳动1次,滑动窗口向前滑动一步,实际业务中可能需要手动控制滑动窗口的时机。
ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
// 获取key值,这里即是时间戳(秒)
private Long getKey() {
return System.currentTimeMillis() / 1000;
}
public Window() {
// 初始化窗口,当前时间指向的是最末端,前两片其实是过去的2s
Long key = getKey();
for (int i = 0; i < slice; i++) {
linkedList.addFirst(key - i);
map.put(key - i, new AtomicInteger(0));
}
// 启动心跳任务,窗口根据时间,自动向前滑动,每秒1步
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
Long key = getKey();
// 队尾添加最新的片
linkedList.addLast(key);
map.put(key, new AtomicInteger());
// 将最老的片移除
map.remove(linkedList.getFirst());
linkedList.removeFirst();
System.out.println("step:" + key + ":" + map);
;
}
}, 1000, 1000, TimeUnit.MILLISECONDS);
}
// 检查当前时间所在的片是否达到上限
public boolean checkCurrentSlice() {
long key = getKey();
AtomicInteger integer = map.get(key);
if (integer != null) {
return integer.get() < sliceMax;
}
// 默认允许访问
return true;
}
// 检查整个窗口所有片的计数之和是否达到上限
public boolean checkAllCount() {
return map.values().stream().mapToInt(value -> value.get()).sum() < totalMax;
}
// 请求来临....
public void req() {
Long key = getKey();
// 如果时间窗口未到达当前时间片,稍微等待一下
// 其实是一个保护措施,放置心跳对滑动窗口的推动滞后于当前请求
while (linkedList.getLast() < key) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 开始检查,如果未达到上限,返回ok,计数器增加1
// 如果任意一项达到上限,拒绝请求,达到限流的目的
// 这里是直接拒绝。现实中可能会设置缓冲池,将请求放入缓冲队列暂存
if (checkCurrentSlice() && checkAllCount()) {
map.get(key).incrementAndGet();
System.out.println(key + "=ok:" + map);
} else {
System.out.println(key + "=reject:" + map);
}
}
public static void main(String[] args) throws InterruptedException {
Window window = new Window();
// 模拟10个离散的请求,相对之间有200ms间隔。会造成总数达到上限而被限流
for (int i = 0; i < 10; i++) {
Thread.sleep(200);
window.req();
}
// 等待一下窗口滑动,让各个片的计数器都置零
Thread.sleep(3000);
// 模拟突发请求,单个片的计数器达到上限而被限流
System.out.println("---------------------------");
for (int i = 0; i < 10; i++) {
window.req();
}
}
}
3.运行结果:
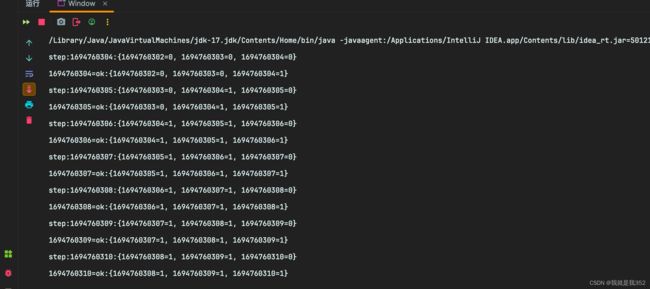
4.应用:滑动窗口算法,在tcp协议发包过程中被使用。在web现实场景中,可以将流量控制做更细化处理,解决计数器模型控制力度太粗暴的问题
4.调度算法与应用
调度算法常见于操作系统中,因为系统资源有限,当有多个进程(或多个进程发出的请求)要使用这些资源时,就必须按照一定的原则选择进程(请求)来占用资源。这就是所谓的调度。在现实生活中也是一样,比如会议室的占用
1.先来先服务(FCFS)
1.概述:先来先服务,很好理解,就是按照服务提交申请的顺序,依次执行。讲究先来后到
2.实现:
package com.andy.dispatch;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 14:53
* 先来先服务 -- 任务类
*/
public class Task {
// 任务名称
private String name;
// 任务提交的时间
private Long addTime;
// 任务的执行时间长短
private int servTime;
public Task(String name, int servTime) {
this.name = name;
this.servTime = servTime;
this.addTime = System.currentTimeMillis();
}
public void execute() {
try {
// !重点:执行时睡眠,表示该任务耗时servTime毫秒
Thread.currentThread().sleep(servTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("execute:name=%s,addTime=%s,servTime=%s", name, addTime, servTime));
}
}
package com.andy.dispatch;
import java.util.Random;
import java.util.concurrent.LinkedBlockingQueue;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 14:54
* 先来先服务
*/
public class FCFS {
public static void main(String[] args) throws InterruptedException {
// 阻塞队列,FCFS的基础
final LinkedBlockingQueue<Task> queue = new LinkedBlockingQueue(5);
// 服务线程,任务由该线程获取和执行
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
queue.take().execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}).start();
// 向队列中放入一个任务
for (int i = 0; i < 5; i++) {
System.out.println("add task:" + i);
queue.put(new Task("task" + i, new Random().nextInt(1000)));
}
}
}
3.结果分析
- add按顺序放入,时间有序
- execute也按时间顺序执行,而不管后面的servTime,也就是不管执行任务长短,先来先执行
4.优缺点
- 多应用于cpu密集型任务场景,对io密集型的不利。
- 时间相对均衡的业务可以排队处理,比如现实中排队打卡进站。
- 如果业务需要依赖大量的外部因素,执行时间片长短不一,FCFS算法不利于任务的整体处理进度,可能会因为一个长时间业务的阻塞而造成大量等待
2.短作业优先 (SJF)
1.概念:执行时间短的优先得到资源。即执行前申报一个我需要占据cpu的时间,根据时间长短,短的优先被调度。我不占时间所以我先来。
2.实现:
package com.andy.dispatch;
import java.util.Map;
import java.util.Random;
import java.util.TreeMap;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 15:01
* 短作业优先
*/
public class SJF {
public static void main(String[] args) throws InterruptedException {
// 有序Map,将服务时间作为key排序
final TreeMap<Integer, Task> treeMap = new TreeMap();
// 向队列中放入5个任务
for (int i = 0; i < 5; i++) {
System.out.println("add task:" + i);
int servTime = new Random().nextInt(1000);
// 注意,key是servTime,即执行预估时间
treeMap.put(servTime, new Task("task" + i, servTime));
}
// 服务线程,任务由该线程获取和执行
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
// 有序Map中,服务时间短的,置于顶部,那么自然就会优先被取出
Map.Entry<Integer, Task> entry = treeMap.pollFirstEntry();
if (entry == null) {
Thread.currentThread().sleep(100);
} else {
entry.getValue().execute();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}).start();
}
}
3.结果分析:add任务有序,确实按照从前往后顺序提交的
4.优缺点
- 适用于任务时间差别较大的场景,仍然以进站为例,拿出公交卡的优先刷卡,还没办卡的让一让。
- 解决了整体处理时间长的问题,降低平均等待时间,提高了系统吞吐量。
- 未考虑作业的紧迫程度,因而不能保证紧迫性作业(进程)的及时处理
- 对长作业的不利,可能等待很久而得不到执行
- 时间基于预估和申报,主观性因素在内,无法做到100%的精准
3.时间片轮转(RR)
1.概念:时间片逐个扫描轮询,轮到谁谁执行。大家公平裁决来者有份,谁也别插队。像是棋牌游戏中的发牌操作,做到了时间和机会上的平均性
2.实现:
package com.andy.dispatch;
import java.util.Random;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 15:07
* 时间轮
*/
public class RR {
// 定义数组作为插槽,每个插槽中可以放入任务
Integer[] integers;
// length插槽的个数
public RR(int length) {
integers = new Integer[length];
}
// 将任务放入插槽
public void addTask(int value) {
int slot = 0;
// 不停查找空的插槽
while (true) {
// 发现空位,将当前任务放入
if (integers[slot] == null) {
integers[slot] = value;
System.out.println(String.format("------------------------->add task index=%s,value=%s", slot, value));
break;
}
// 如果当前位置有任务占用,看下一个位置
slot++;
// 如果插槽遍历完还是没有空位置,那么从头开始再找,继续下一个轮回
if (slot == integers.length) {
slot = 0;
}
}
}
// 执行任务。轮询的策略就在这里
public void execute() {
// 开启一个线程处理任务。在现实中可能有多个消费者来处理
new Thread(new Runnable() {
@Override
public void run() {
int index = 0;
while (true) {
// 指针轮询,如果到达尾部,下一步重新转向开头
// 数据物理结构是一个数组,逻辑上是一个环
if (index == integers.length) {
index = 0;
}
// 如果当前位置没有任务,轮询到下一个插槽
if (integers[index] == null) {
index++;
continue;
} else {
// 随机等待,表示模拟当前任务有一个执行时间
try {
Thread.currentThread().sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
// 模拟任务执行的内容,也就是打印一下当前插槽和里面的值
System.out.println(String.format("execute index=%s,value=%s", index, integers[index]));
// 执行完,将当前插槽清空,腾出位置来给后续任务使用
integers[index] = null;
}
}
}
}).start();
}
public static void main(String[] args) {
// 测试开始,定义3个插槽
RR rr = new RR(3);
// 唤起执行者线程,开始轮询
rr.execute();
// 放置10个任务
for (int i = 0; i < 10; i++) {
rr.addTask(i);
}
}
}
3.结果分析:
- add任务index无序,value有序,说明是按顺序提交的,但是插槽无序,哪里有空放哪里
- execute执行index有序value无序,说明任务是轮询执行的,每个插槽里的任务不一定是谁
4.优缺点
- 做到了机会的相对平均,不会因为某个任务执行时间超长而永远得不到执行
- 缺乏任务主次的处理。重要的任务无法得到优先执行,必须等到时间片轮到自己,着急也没用
4.应用案例
- CPU资源调度
- 云计算资源调度
- 容器化Docker编排与调度
5.定时算法与应用
系统或者项目中难免会遇到各种需要自动去执行的任务,实现这些任务的手段也多种多样,如操作系统的crontab,spring框架的quartz,java的Timer和ScheduledThreadPool都是定时任务中的典型手段
1.最小堆
1.概述:Timer是java中最典型的基于优先级队列+最小堆实现的定时器,内部维护一个存放定时任务的优先级队列,该优先级队列使用了最小堆排序。当我们调用schedule方法的时候,一个新的任务被加入queue,堆重排,始终保持堆顶是执行时间最小(即最近马上要执行)的。同时,内部相当于起了一个线程不断扫描队列,从队列中依次获取堆顶元素执行,任务得到调度
2.以Timer为例,介绍优先级队列+最小堆算法的实现原理
package com.andy.heap;
import java.util.Timer;
import java.util.TimerTask;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 15:19
*/
class Task extends TimerTask {
@Override
public void run() {
System.out.println("running...");
}
}
class TimerDemo {
public static void main(String[] args) {
Timer t = new Timer();
// 在1秒后执行,以后每2秒跑一次
t.schedule(new Task(), 1000, 2000);
}
}
3.源码分析
新加任务时,t.schedule方法会add到队列
void add(TimerTask task) {
// Grow backing store if necessary
if (size + 1 == queue.length)
queue = Arrays.copyOf(queue, 2*queue.length);
queue[++size] = task;
fixUp(size);
}
add实现了容量维护,不足时扩容,同时将新任务追加到队列队尾,触发堆排序,始终保持堆顶元素最小
//最小堆排序
private void fixUp(int k) {
while (k > 1) {
//k指针指向当前新加入的节点,也就是队列的末尾节点,j为其父节点
int j = k >> 1;
//如果新加入的执行时间比父节点晚,那不需要动
if (queue[j].nextExecutionTime <= queue[k].nextExecutionTime)
break;
//如果大于其父节点,父子交换
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
//交换后,当前指针继续指向新加入的节点,继续循环,知道堆重排合格
k = j;
}
}
线程调度中的run,主要调用内部mainLoop()方法,使用while循环
private void mainLoop() {
while (true) {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
//...
// Queue nonempty; look at first evt and do the right thing
long currentTime, executionTime;
task = queue.getMin();
synchronized(task.lock) {
//...
//当前时间
currentTime = System.currentTimeMillis();
//要执行的时间
executionTime = task.nextExecutionTime;
//判断是否到了执行时间
if (taskFired = (executionTime<=currentTime)) {
//判断下一次执行时间,单次的执行完移除
//循环的修改下次执行时间
if (task.period == 0) { // Non-repeating, remove
queue.removeMin();
task.state = TimerTask.EXECUTED;
} else { // Repeating task, reschedule
//下次时间的计算有两种策略
//1.period是负数,那下一次的执行时间就是当前时间-period
//2.period是正数,那下一次就是该任务本次的执行时间+period
//注意!这两种策略大不相同。因为Timer是单线程的
//如果是1,那么currentTime是当前时间,就受任务执行长短影响
//如果是2,那么executionTime是绝对时间戳,与任务长短无关
queue.rescheduleMin(
task.period<0 ? currentTime - task.period
: executionTime + task.period);
}
}
}
//不到执行时间,等待
if (!taskFired) // Task hasn't yet fired; wait
queue.wait(executionTime - currentTime);
}
//到达执行时间,run!
if (taskFired) // Task fired; run it, holding no locks
task.run();
} catch(InterruptedException e) {
}
}
}
4.应用:
- 使用Timer为了介绍算法原理,但是Timer已过时,实际应用中推荐使用ScheduledThreadPoolExecutor(同样内部使用DelayedWorkQueue和最小堆排序)
- Timer是单线程,一旦一个失败或出现异常,将打断全部任务队列,线程池不会
- Timer在jdk1.3+,而线程池需要jdk1.5+
2.时间轮
1.概述:时间轮是一种更为常见的定时调度算法,各种操作系统的定时任务调度,linux crontab,基于java的通信框架Netty等。其灵感来源于我们生活中的时钟。轮盘实际上是一个头尾相接的环状数组,数组的个数即是插槽数,每个插槽中可以放置任务。以1天为例,将任务的执行时间%12,根据得到的数值,放置在时间轮上,小时指针沿着轮盘扫描,扫到的点取出任务执行
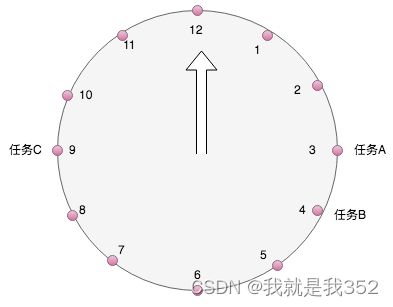
-
问题:比如3点钟,有多个任务执行怎么办?
-
答案:在每个槽上设置一个队列,队列可以无限追加,解决时间点冲突问题(类似HashMap结构)

-
问题:每个轮盘的时间有限,比如1个月后的第3天的5点怎么办?
-
方案一:加长时间刻度,扩充到1年
-
优缺点:简单,占据大量内存,即使插槽没有任务也要空轮询,白白的资源浪费,时间、空间复杂度都高
-
方案二:每个任务记录一个计数器,表示转多少圈后才会执行。没当指针过来后,计数器减1,减到0的再执行
-
优缺点:每到一个指针都需要取出链表遍历判断,时间复杂度高,但是空间复杂度低
-
方案三:设置多个时间轮,年轮,月轮,天轮。1天内的放入天轮,1年后的则放入年轮,当年轮指针读到后,将任务取出,放入下一级的月轮对应的插槽,月轮再到天轮,直到最小精度取到,任务被执行。
-
优缺点:不需要额外的遍历时间,但是占据了多个轮的空间。空间复杂度升高,但是时间复杂度降低
2.java实现
定义Task类
package com.andy.heap;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 15:27
* Task类
*/
public class RoundTask {
// 延迟多少秒后执行
int delay;
// 加入的序列号,只是标记一下加入的顺序
int index;
public RoundTask(int index, int delay) {
this.index = index;
this.delay = delay;
}
void run() {
System.out.println("task " + index + " start , delay = " + delay);
}
@Override
public String toString() {
return String.valueOf(index + "=" + delay);
}
}
时间轮算法:
package com.andy.heap;
import java.util.LinkedList;
import java.util.Random;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author Andy
* @version 0.0.1
* @since 2023-09-15 15:30
* 时间轮算法
*/
public class RoundDemo {
// 小轮槽数
int size1 = 10;
// 大轮槽数
int size2 = 5;
// 小轮,数组,每个元素是一个链表
LinkedList<RoundTask>[] t1 = new LinkedList[size1];
// 大轮
LinkedList<RoundTask>[] t2 = new LinkedList[size2];
// 小轮计数器,指针跳动的格数,每秒加1
final AtomicInteger flag1 = new AtomicInteger(0);
// 大轮计数器,指针跳动个格数,即每10s加1
final AtomicInteger flag2 = new AtomicInteger(0);
// 调度器,拖动指针跳动
ScheduledExecutorService service = Executors.newScheduledThreadPool(2);
public RoundDemo() {
// 初始化时间轮
for (int i = 0; i < size1; i++) {
t1[i] = new LinkedList<>();
}
for (int i = 0; i < size2; i++) {
t2[i] = new LinkedList<>();
}
}
// 打印时间轮的结构,数组+链表
void print() {
System.out.println("t1:");
for (int i = 0; i < t1.length; i++) {
System.out.println(t1[i]);
}
System.out.println("t2:");
for (int i = 0; i < t2.length; i++) {
System.out.println(t2[i]);
}
}
// 添加任务到时间轮
void add(RoundTask task) {
int delay = task.delay;
if (delay < size1) {
// 10以内的,在小轮
t1[delay].addLast(task);
} else {
// 超过小轮的放入大轮,槽除以小轮的长度
t2[delay / size1].addLast(task);
}
}
void startT1() {
// 每秒执行一次,推动时间轮旋转,取到任务立马执行
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
int point = flag1.getAndIncrement() % size1;
System.out.println("t1 -----> slot " + point);
LinkedList<RoundTask> list = t1[point];
if (!list.isEmpty()) {
// 如果当前槽内有任务,取出来,依次执行,执行完移除
while (list.size() != 0) {
list.getFirst().run();
list.removeFirst();
}
}
}
}, 0, 1, TimeUnit.SECONDS);
}
void startT2() {
// 每10秒执行一次,推动时间轮旋转,取到任务下方到t1
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
int point = flag2.getAndIncrement() % size2;
System.out.println("t2 =====> slot " + point);
LinkedList<RoundTask> list = t2[point];
if (!list.isEmpty()) {
// 如果当前槽内有任务,取出,放到定义的小轮
while (list.size() != 0) {
RoundTask task = list.getFirst();
// 放入小轮哪个槽呢?小轮的槽按10取余数
t1[task.delay % size1].addLast(task);
// 从大轮中移除
list.removeFirst();
}
}
}
}, 0, 10, TimeUnit.SECONDS);
}
public static void main(String[] args) {
RoundDemo roundDemo = new RoundDemo();
// 生成100个任务,每个任务的延迟时间随机
for (int i = 0; i < 100; i++) {
roundDemo.add(new RoundTask(i, new Random().nextInt(50)));
}
// 打印,查看时间轮任务布局
roundDemo.print();
// 启动大轮
roundDemo.startT2();
// 小轮启动
roundDemo.startT1();
}
}
3.结果分析:
- 输出结果严格按delay顺序执行,而不管index是何时被提交的
- t1为小轮,10个槽,每个1s,10s一轮回
- t2为大轮,5个槽,每个10s,50s一轮回
- t1循环到每个槽时,打印槽内的任务数据,如 t1–>slot9 , 打印了3个9s执行的数据
- t2循环到每个槽时,将槽内的任务delay时间取余10后,放入对应的t1槽中,如 + t2==>slot1
- 那么t1旋转对应的圈数后,可以取到t2下放过来的任务并执行,如10,11…