LeetCode 5. 最长回文子串(暴力+动态规划+中心开花+马拉车)+ follow up 647. 516
文章目录
-
-
- 题目描述
- 题解
-
- 暴力
- 动态规划
- 中心开花
- 马拉车
- 扩展
-
- 647.回文子串数量
- 516.最长回文子序列
-
题目描述
给定一个字符串s,找出s中最长的回文子串
题解
暴力
先想一个最直观最简单的:遍历全部子串,依次判断是否是回文,然后取其中最长的作为答案。
class Solution {
public String longestPalindrome(String s) {
int n = s.length();
int begin = 0, end = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
// 当前子串是回文, 且长度大于最大长度, 则更新起点和终点
if (isPalindrome(s, i, j) && j - i > end - begin) {
begin = i;
end = j;
}
}
}
return s.substring(begin, end + 1);
}
// 判断 [l, r] 区间的子串是否是回文串
private boolean isPalindrome(String s, int l, int r) {
while (l < r && s.charAt(l) == s.charAt(r)) {
l++;
r--;
}
return l >= r;
}
}
枚举全部子串的复杂度为 O ( n 2 ) O(n^2) O(n2),而判断每个子串是否是回文的复杂度为 O ( n ) O(n) O(n),所以整体的时间复杂度是 O ( n 3 ) O(n^3) O(n3)
判断每个子串是否是回文的复杂度为 O ( n ) O(n) O(n),可以理解为子串的平均长度是 O ( n ) O(n) O(n),而判断回文的复杂度和子串长度是呈线性相关的。
推导:全部子串的个数是: n + ( n − 1 ) + ( n − 2 ) + . . . . + 1 = ( n + 1 ) n 2 n + (n-1) + (n-2) + .... + 1 = \frac{(n+1)n}{2} n+(n−1)+(n−2)+....+1=2(n+1)n
所有子串的总长度是:
1 + 2 + 3 + . . . + n = ( n + 1 ) n 2 1 + 2 + 3 + ... + n = \frac{(n+1)n}{2} 1+2+3+...+n=2(n+1)n 加上
1 + 2 + 3 + . . . + ( n − 1 ) = n ( n − 1 ) 2 1 + 2 + 3 + ... + (n - 1) = \frac{n(n-1)}{2} 1+2+3+...+(n−1)=2n(n−1) 加上
1 + 2 + 3 + . . . + ( n − 2 ) = ( n − 1 ) ( n − 2 ) 2 1 + 2 + 3 + ... + (n-2) = \frac{(n-1)(n-2)}{2} 1+2+3+...+(n−2)=2(n−1)(n−2) 加到 … 1 1 1
结果就是 ( n + 1 ) n + n ( n − 1 ) + ( n − 1 ) ( n − 2 ) + . . . + 1 × 2 2 \frac{(n+1)n + n(n-1) + (n-1)(n-2)+... + 1 × 2}{2} 2(n+1)n+n(n−1)+(n−1)(n−2)+...+1×2
把分子部分展开,得 1 × 2 + 2 × 3 + 3 × 4 + . . . + n × ( n + 1 ) = ( 1 2 + 1 ) + ( 2 2 + 2 ) + ( 3 2 + 3 ) + . . . + ( n 2 + n ) 1 × 2 + 2 × 3 + 3 × 4 + ... + n × (n+1) = (1^2 + 1) + (2^2 + 2) + (3^2 + 3) + ... + (n^2 + n) 1×2+2×3+3×4+...+n×(n+1)=(12+1)+(22+2)+(32+3)+...+(n2+n)
得 ( 1 2 + 2 2 + 3 2 + . . . + n 2 ) + ( 1 + 2 + 3 + . . . + n ) (1^2+2^2+3^2+...+n^2) + (1+2+3+...+n) (12+22+32+...+n2)+(1+2+3+...+n)
前半部分根据公式,求得为 n ( n + 1 ) ( 2 n + 1 ) 6 \frac{n(n+1)(2n + 1)}{6} 6n(n+1)(2n+1),是 O ( n 3 ) O(n^3) O(n3) 的,用子串总长度( O ( n 3 ) O(n^3) O(n3))除以子串总数( O ( n 2 ) O(n^2) O(n2)),得到子串的平均长度是 O ( n ) O(n) O(n) 的。
暴力法的时间复杂度太高,提交会报超时。

动态规划
暴力法的过程中,其实做了很多重复的计算。我们设 F ( i , j ) F(i,j) F(i,j) 来表示子串 [ i , j ] [i,j] [i,j] 是否为回文串,若是,则 F ( i , j ) F(i,j) F(i,j)为true,否则为false。
那么 F ( i , j ) F(i,j) F(i,j) 的取值,只取决于 F ( i + 1 , j − 1 ) F(i+1,j-1) F(i+1,j−1) 。所以我们可以利用先前计算过的结果,来减少重复计算。
注意循环的顺序,我们需要确保在计算 F ( i , j ) F(i,j) F(i,j) 时,对于 [ i , j ] [i,j] [i,j]区间内的所有 F F F 都已经计算完毕。
于是,我们按照子串的长度,从小到大递增,来进行循环。
动规的边界条件是,长度为1或2的子串,这些子串的 F F F 状态我们可以预处理出来。
class Solution {
public String longestPalindrome(String s) {
int n = s.length();
boolean[][] f = new boolean[n][n];
int begin = 0, end = 0; // 确保至少能取到长度为1的子串
// 预处理长度为1或2的子串
for (int i = 0; i < n; i++) {
f[i][i] = true;
if (i > 0 && s.charAt(i) == s.charAt(i - 1)) {
f[i - 1][i] = true;
begin = i - 1;
end = i;
}
}
// 从大小为3的长度开始枚举
// 不能从2开始枚举, 因为求解[i,i+1]时, 会使用[i+1,i]这样的无效状态
for (int len = 3; len <= n; len++) {
for (int i = 0; i + len - 1 < n; i++) {
int j = i + len - 1;
if (f[i + 1][j - 1] && s.charAt(i) == s.charAt(j)) {
f[i][j] = true;
begin = i;
end = j; // 由于枚举的子串长度是递增的, 则每次更新总是没错的
}
}
}
return s.substring(begin, end + 1);
}
}
动规,需要计算的全部状态,也就是全部子串,为 O ( n 2 ) O(n^2) O(n2),计算每个状态需要 O ( 1 ) O(1) O(1),所以动规的时间复杂度是 O ( n 2 ) O(n^2) O(n2)

中心开花
动规求解子串的状态是自顶向下的,即从两边往中间缩拢。我们也可以自底向上求解,以每个位置为中心,尝试向左右两边扩散开去,找到以当前位置为中心的最长回文子串。然后将每个位置作为中心能得到的最长子串,再取一个最值即可。
class Solution {
public String longestPalindrome(String s) {
int n = s.length();
int begin = 0, end = 0;
for (int i = 0; i < n; i++) {
// 注意需要处理回文串为奇数和为偶数的情况
int len = expand(s, i, i + 1); // 偶数
if (2 * len > end - begin + 1) {
begin = i - len + 1;
end = i + len;
}
len = expand(s, i - 1, i + 1); // 奇数
if (2 * len + 1 > end - begin + 1) {
begin = i - len;
end = i + len;
}
}
return s.substring(begin, end + 1);
}
// return 向两边扩散的最长半径
private int expand(String s, int l, int r) {
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l--;
r++;
}
// 若是偶数回文串, 如 abba, 则返回2
// 若是奇数回文串, 如 abcba, 则返回2
return (r - l - 1) / 2;
}
}

中心开花的时间复杂度也是 O ( n 2 ) O(n^2) O(n2),枚举每个位置作为中心,复杂度为 O ( n ) O(n) O(n),对每个位置往两边扩散,复杂度也为 O ( n ) O(n) O(n),所以总的时间复杂度是 O ( n 2 ) O(n^2) O(n2)。
然而中心开花的方法,比动态规划要快,因为这种方式省掉了一些不可能作为答案的子串的状态计算。比如以i为中心,向两边扩散,当扩散到半径为2时,发现已经不是回文了,则对于以i为中心,半径大于2的那些子串,不需要再做计算了。也就是说它少计算了一些子串的状态。而动态规划是把所有子串都计算了一遍。
马拉车
Manacher算法,是在中心开花法上面的优化,能够将时间复杂度降低为线性的 O ( n ) O(n) O(n)。它主要是利用了先前计算的结果,通过回文镜像对称的特点,来减少重复的状态判断。具体思路如下:
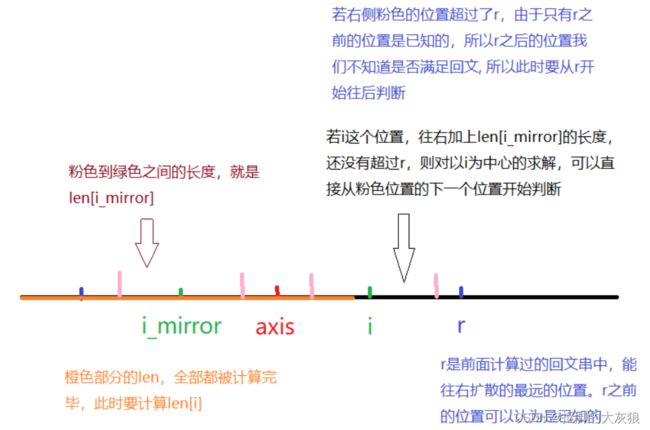
我们先只考虑回文串为奇数长度的情况。我们从左往右枚举每个位置作为中心点时,都能够得到以这个点为中心,最大的回文子串。我们将以i为中心,往两边扩散,能够达到的最远的半径,记为臂长len[i]。
比如字符串 abcocnpncoccd,下标为6的位置是p,其往两边扩散,能达到的最长半径为4(我们只考虑回文串长度为奇数,且中心点不纳入半径计算),即以p为中心的最长回文子串是cocnpncoc,则len[6] = 4。则以下标6为中心的回文子串,其扩散出来,能够覆盖到下标10(6+4)。假设对于下标小于6为中心,扩散出来的回文子串,都没法达到下标10的位置,则我们称10为此时能够覆盖到的最远的位置,记为r。
当我们对于i > 6,需要计算len[i]时,可以利用前面的结果。当r > i时,说明位置i已经被之前的某个中心点的最长回文子串所覆盖。假设我们此时要计算的是位置9,即i = 9。此时r = 10,且这个r是由中心点6所维护,我们设维护r的中心点的下标为axis。
由于以axis为中心的最长回文子串,覆盖了i这个位置,且回文具有对称的特性。那么我们可以找到i关于axis对称的位置,称其为i_mirror。容易得知i_mirror = 2 * axis - i。计算的过程可以这样想,假设axis到i的距离是x,则axis + x = i,那么对称点i_mirror = axis - x,将两式相加,得2 * axis = i + i_mirror。
由于i_mirror位于axis之前,则len[i_mirror]已经是被计算过的。
马拉车的核心思想就是利用这个len[i_mirror]。
上面考虑的只是对于回文串长度为奇数这一种情况。对于偶数,我们可以先将其变成奇数。方法是,在每个字符之间插入一个符号(随便什么符号皆可,不会影响原有字符的回文判断),假设加入#。
#b#c#b#b#d#b#,则原来的奇数长度的回文串,如bcb,仍然是奇数长度回文串,#b#c#b#。
原来的偶数长度的回文串,如bb,变成了奇数长度回文串,#b#b#。
写成代码如下
class Solution {
public String longestPalindrome(String s) {
// 添加分隔符, 转化为奇数长度的字符串
StringBuilder sb = new StringBuilder("#");
for (int i = 0; i < s.length(); i++) {
sb.append(s.charAt(i)).append("#");
}
s = sb.toString();
int n = s.length();
int[] len = new int[n]; // 以每个点为中心, 能够扩展出来的最长半径
int axis = -1, r = -1; // r是回文串能覆盖到的最远的右端点, axis是对应的中心
int max_len = 0, max_axis = 0; // 记录答案
for (int i = 0; i < n; i++) {
int i_len = 0;
if (r > i) { // 当i被r覆盖住
int i_mirror = 2 * axis - i;
int i_min_len = Math.min(r - i, len[i_mirror]); // i 的最小半径
i_len = expand(s, i - i_min_len - 1, i + i_min_len + 1); // 从最小半径往外扩散
} else { // 否则按照朴素的中心开花进行扩散
i_len = expand(s, i - 1, i + 1);
}
if (i + i_len > r) {
// 更新 r 和 axis
r = i + i_len;
axis = i;
}
len[i] = i_len;
if (i_len > max_len) {
// 更新答案
max_len = i_len;
max_axis = i;
}
}
// 还原, 得到结果
int begin = max_axis - max_len, end = max_axis + max_len;
StringBuilder res = new StringBuilder();
for (int i = begin; i <= end; i++) {
if (s.charAt(i) != '#') res.append(s.charAt(i));
}
return res.toString();
}
private int expand(String s, int left, int right) {
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
return (right - left - 2) / 2;
}
}

上面的描述其实不是特别准确。准确说,当我们需要计算len[i]时,有3种情况
i + len[i_mirror] < r,此时len[i]其实不用算了,len[i]就等于len[i_mirror]i + len[i_mirror] > r,此时len[i]也不用算了,len[i]就等于r - i(最远的回文扩散到r)i + len[i_mirror] = r,此时才需要计算,右侧端点从r + 1的位置,左侧端点从对应位置,开始往两边扩散
所以,这里就能看到马拉车算法的优秀之处了。只要r足够大,能够覆盖到足够远的位置,则覆盖范围内的i的计算,很多时候都可以不劳而获,仅仅在i + len[i_mirror] = r时,才需要往两边扩散。而往两边扩散,又使得r会被更大的值更新。
这样写成代码应该如下(只改动了r > i这个分支下面的部分)
class Solution {
public String longestPalindrome(String s) {
// 添加分隔符, 转化为奇数长度的字符串
StringBuilder sb = new StringBuilder("#");
for (int i = 0; i < s.length(); i++) {
sb.append(s.charAt(i)).append("#");
}
s = sb.toString();
int n = s.length();
int[] len = new int[n]; // 以每个点为中心, 能够扩展出来的最长半径
int axis = -1, r = -1; // r是回文串能覆盖到的最远的右端点, axis是对应的中心
int max_len = 0, max_axis = 0; // 记录答案
for (int i = 0; i < n; i++) {
int i_len = 0;
if (r > i) { // 当i被r覆盖住
int i_mirror = 2 * axis - i;
if (i + len[i_mirror] < r) i_len = len[i_mirror];
else if (i + len[i_mirror] > r) i_len = r - i;
else {
int i_min_len = len[i_mirror];
i_len = expand(s, i - i_min_len - 1, i + i_min_len + 1);
}
} else { // 否则按照朴素的中心开花进行扩散
i_len = expand(s, i - 1, i + 1);
}
if (i + i_len > r) {
// 更新 r 和 axis
r = i + i_len;
axis = i;
}
len[i] = i_len;
if (i_len > max_len) {
// 更新答案
max_len = i_len;
max_axis = i;
}
}
// 还原, 得到结果
int begin = max_axis - max_len, end = max_axis + max_len;
StringBuilder res = new StringBuilder();
for (int i = begin; i <= end; i++) {
if (s.charAt(i) != '#') res.append(s.charAt(i));
}
return res.toString();
}
private int expand(String s, int left, int right) {
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
return (right - left - 2) / 2;
}
}

其实效果相差不大,在前面那种写法下,在<或者>时,只会多进行了一次比较,但前面的写法更简洁一些。
马拉车的时间复杂度为 O ( n ) O(n) O(n),可以理解为每个位置的字符最多会被比较一次。
参考详解马拉车算法——原理、实现与练习
扩展
647.回文子串数量
求解回文子串的数量。
中心开花法,从中心往两边扩展时,每扩展一个位置,数量+1即可。
class Solution {
public int countSubstrings(String s) {
int num = 0;
for (int i = 0; i < s.length(); i++) {
num++; // 长度为1的也算一个回文串
int l = i, r = i + 1;
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l--;
r++;
num++;
}
l = i - 1;
r = i + 1;
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l--;
r++;
num++;
}
}
return num;
}
}
马拉车:对于位置i,若s[i] == ‘#’,则len[i]一定是偶数,且len[i]的长度就是该回文串的长度(偶数回文串),此时回文串数量为 len[i] / 2;当s[i] != '#',则len[i]一定是奇数,此时len[i]的长度也是该回文串的长度(奇数回文串),回文串数量为len[i] / 2 + 1(中心位置的字符单独拿出来也可以作为一个回文串)。
class Solution {
public int countSubstrings(String s) {
StringBuilder sb = new StringBuilder("#");
for (int i = 0; i < s.length(); i++) {
sb.append(s.charAt(i));
sb.append("#");
}
s = sb.toString();
int n = s.length();
int[] len = new int[n];
int axis = -1, r = -1;
int ans = 0;
for (int i = 0; i < n; i++) {
int i_len = 0;
if (r > i) {
int i_mirror = 2 * axis - i;
int i_min_len = Math.min(r - i, len[i_mirror]);
i_len = expand(s, i - i_min_len - 1, i + i_min_len + 1);
} else {
i_len = expand(s, i - 1, i + 1);
}
if (i + i_len > r) {
r = i + i_len;
axis = i;
}
len[i] = i_len;
// 计算当前这个节点有多少个回文串
if (s.charAt(i) == '#') ans += i_len / 2;
else ans += i_len / 2 + 1;
}
return ans;
}
private int expand(String s, int l, int r) {
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l--;
r++;
}
return (r - l - 2) / 2;
}
}
516.最长回文子序列
给定一个字符串s,求其最长回文子序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
这道题跟回文就没有太大关系了,因为求解的是回文子序列。子序列的问题,通常考虑用动态规划来做。
我们设状态f[i][j] 表示,下标范围为[i,j]内的最长回文子序列的长度。由于回文的特性,当去掉一个回文串两端各一个字符时,仍然会保持回文,这个特性可以用来设计状态转移方程。
动规的边界条件为,f[i][i] = 1,所有单个字符自己能形成一个长度为1的回文子序列。
求解f[i][j]时,我们考虑字符串s在位置i,j是否相等。
- 若
s[i] == s[j],则i,j都可以被纳入回文子序列,f[i][j] = f[i + 1][j - 1] + 2 - 若
s[i] != s[j],则i,j至多只有其一能被纳入回文子序列,f[i][j] = max(f[i + 1][j] , f[i][j - 1])
我们最终的答案即是 f[0][n - 1]
class Solution {
public int longestPalindromeSubseq(String s) {
int n = s.length();
int[][] f = new int[n][n];
for (int i = 0; i < n; i++) f[i][i] = 1;
for (int len = 2; len <= n; len++) {
for (int i = 0; i + len - 1 < n; i++) {
int j = i + len - 1;
if (s.charAt(i) == s.charAt(j)) f[i][j] = f[i + 1][j - 1] + 2;
else {
f[i][j] = Math.max(f[i + 1][j], f[i][j - 1]);
}
}
}
return f[0][n - 1];
}
}
滚动数组优化:可以将二维的空间复杂度,降低为一维。
我们观察状态转移方程,f[i][j]只和 f[i + 1][j] , f[i][j - 1], f[i + 1][j - 1] 这三个值有关。我们将二维的状态画出来。i为行,j为列。如下

容易得知,每个f[i][j]的值,都只和其左侧(f[i][j - 1]),其下侧(f[i + 1][j]),其左下角(f[i + 1][j - 1])这三个值有关系。
所以我们只需要从左往右,从下往上,进行状态的计算,即可将空间优化为一维。但左下角的值,我们需要用一个额外的变量来存储。
另外注意,由于f[i][j]的含义是区间[i,j]内的最长回文子序列的长度,所以i <= j。
class Solution {
public int longestPalindromeSubseq(String s) {
int n = s.length();
int[] f = new int[n];
for (int i = n - 1; i >= 0; i--) {
// 从下往上计算
f[i] = 1; // 当前这个位置的最长回文子序列, 至少是其本身, 长度为1, 即 f[i][i] 至少为1
int temp = 0, old = 0; // 存储左下角
for (int j = i + 1; j < n; j++) {
// j 从 i 后面一个位置开始
// 从左往右计算
temp = f[j]; // 当前这个值是下一次循环的左下角
if (s.charAt(i) == s.charAt(j)) f[j] = old + 2; // 左下角 + 2
else f[j] = Math.max(f[j - 1], f[j]); // f[j - 1]是左, f[j]是当前行, 下
old = temp; // 下一次循环时的左下角
}
}
return f[n - 1];
}
}
